
大模型离你不远:从概念到日常,一篇读懂 AI 新工具
摘要: 大模型是基于Transformer架构、参数量达千亿级的深度学习系统,通过海量数据预训练实现跨任务泛化。其核心优势在于:1)架构革新,采用自注意力机制捕捉长距离语义关联;2)训练范式,通过“预训练+微调”适配多种任务;3)规模效应,千亿参数和万亿级数据赋予零样本学习能力。技术特点包括:参数稀疏激活(如MoE架构)、涌现能力(量变到质变)、分布式训练(Megatron-LM/DeepSpee

你或许在项目中接触过 AI 接口 —— 比如调用 API 生成文本,或用工具做图像识别。但这些 “表层应用” 背后,大模型的核心技术逻辑的是什么?它的参数规模为何能决定能力上限?今天,我们从技术视角拆解大模型:从底层架构到训练流程,从核心特点到落地场景,结合代码示例与示意图,帮你建立更直观的技术认知。
一、大模型是什么?
大模型是基于深度学习框架(如 PyTorch/TensorFlow),采用 Transformer 架构,参数量达数十亿至千亿级,通过大规模数据预训练实现跨任务泛化的神经网络系统。
它与传统 “小模型” 的核心差异
-
架构革新:采用Self-Attention机制,突破RNN的序列限制,能捕捉长距离语义关联
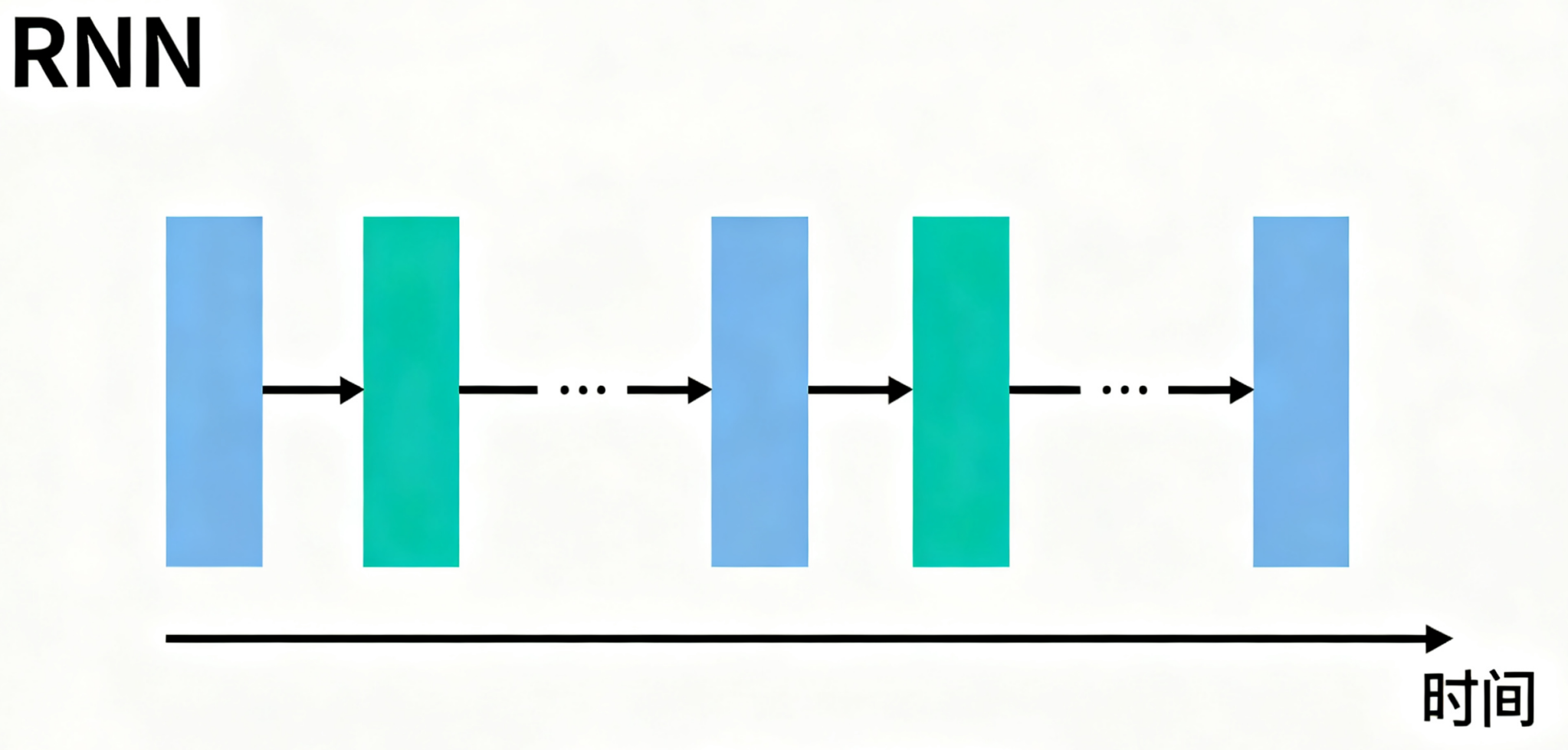
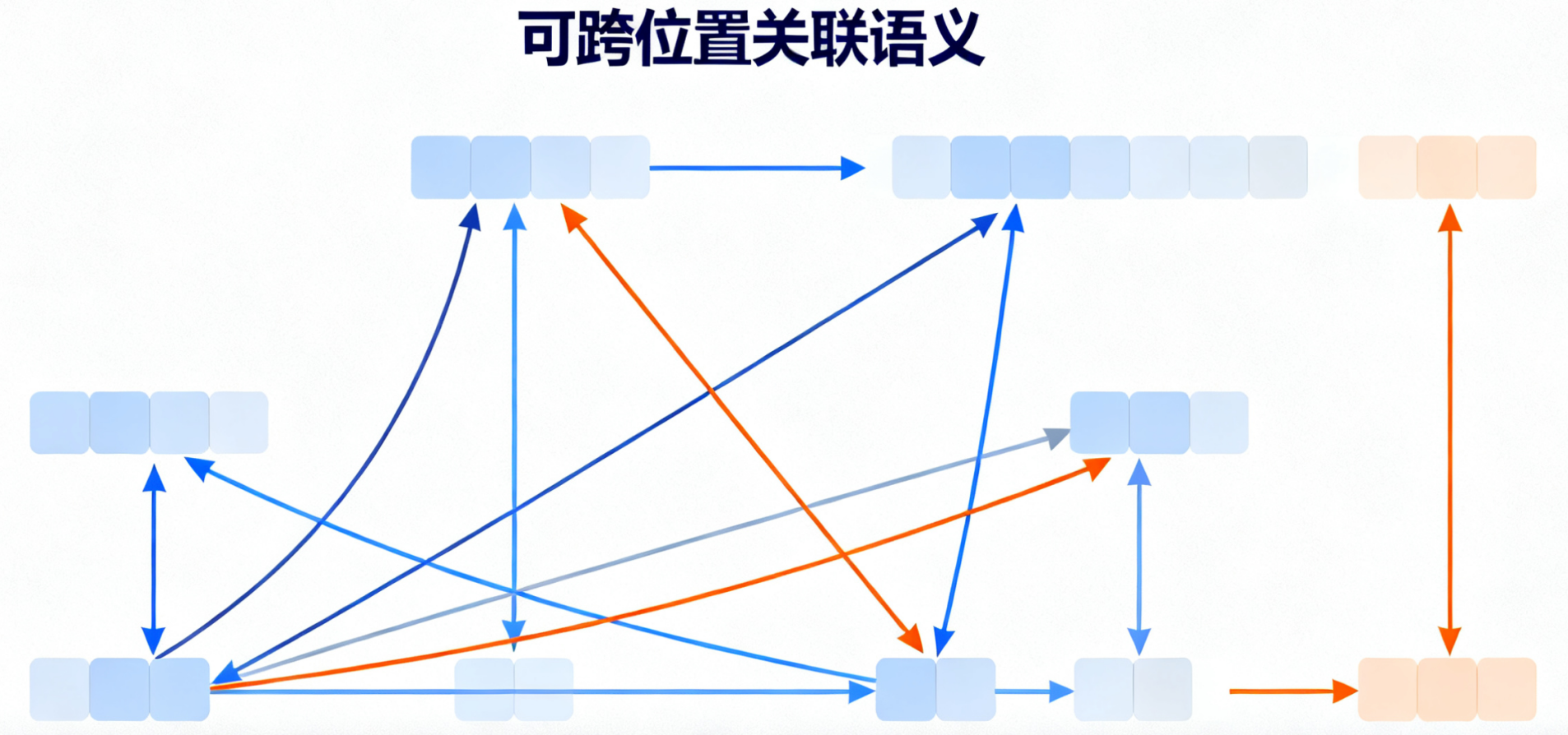
传统模型多采用 CNN(图像)、RNN(文本)架构;
而大模型统一使用 Transformer—— 通过 “自注意力机制”(Self-Attention)捕捉文本 / 图像中远距离的语义关联,比如分析 “用户购买手机后咨询保修” 时,能关联 “商品类型 - 售后服务” 的逻辑,这是 RNN 的时序依赖无法实现的。
-
训练范式:"预训练+微调"模式,一套基础模型适配多种任
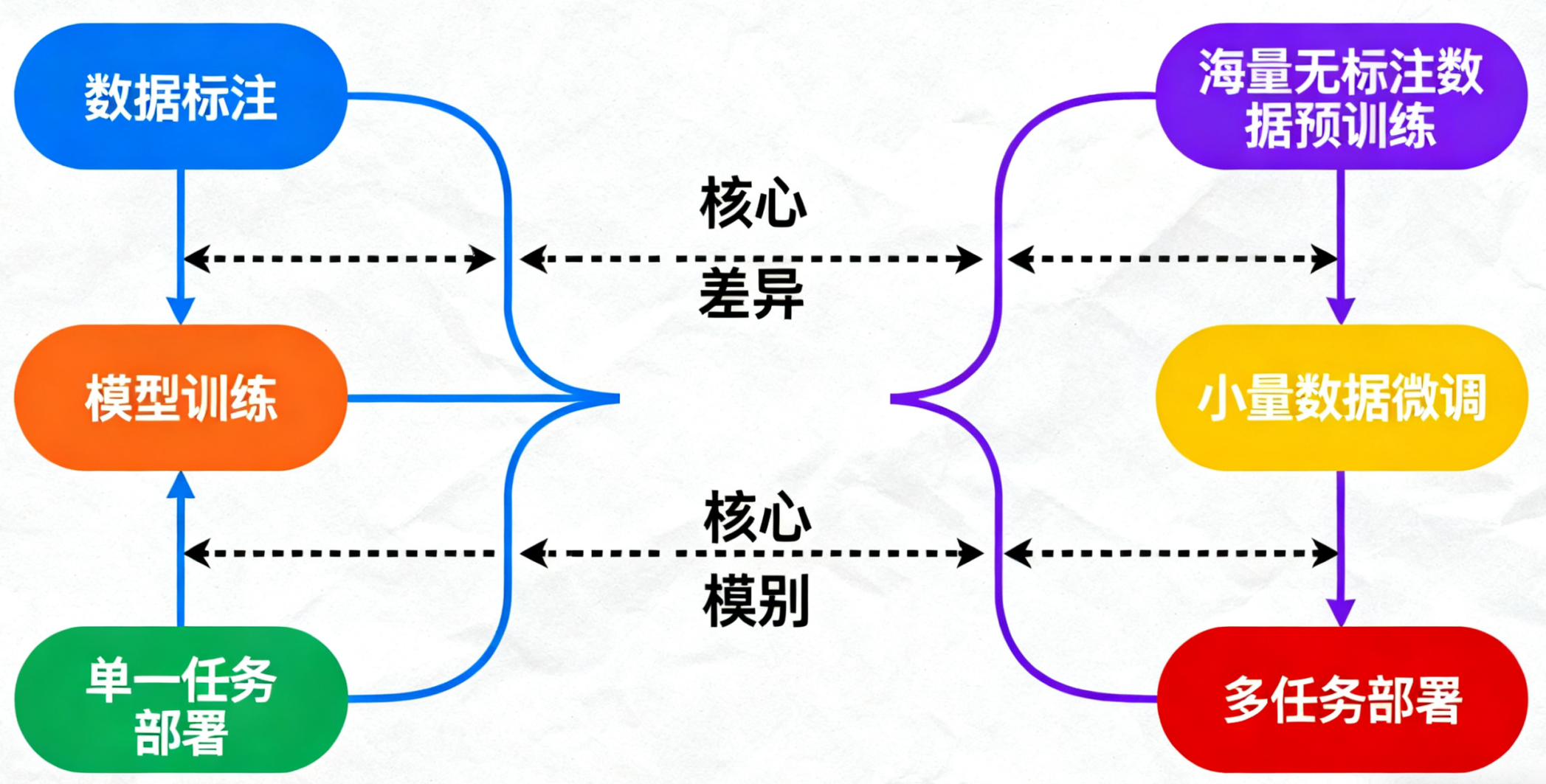
传统模型是 “任务特定训练”—— 比如做文本分类,需用标注好的分类数据从头训练;
而大模型是 “预训练 + 微调” 模式:先在无标注的海量数据(如全网文本、开源图像库)上完成预训练,再用少量任务数据微调,即可适配分类、生成、翻译等多种任务。
-
能力边界:千亿参数+万亿Token训练数据,实现零样本/少样本学习
传统模型的能力受限于训练数据量(通常百万级样本)和参数量(百万至千万级),只能处理单一任务;
而大模型凭借千亿级参数和万亿级训练 Token(文本单位),能覆盖 NLP、CV(计算机视觉)甚至多模态任务,具备 “零样本 / 少样本学习” 能力 —— 比如给模型一句 “用 Python 写一个读取 MySQL 数据的脚本”,无需训练代码生成数据,就能输出可运行的基础代码。
二、四大技术特点深度解析
1、参数规模:质量优于数量
大模型的 “参数” 并非简单的数值堆积,而是由 “权重矩阵” 和 “偏置项” 构成的可学习参数,核心作用是拟合数据中的复杂模式。
-
参数本质:权重矩阵和偏置项,存储知识和规则
-
规模意义:千亿参数能记忆复杂领域知识(如医学术语、代码规范)
-
稀疏激活:MoE架构动态激活部分参数,提升计算效率
# MoE门控网络示例
class MoELayer(nn.Module):
def __init__(self, input_dim, num_experts, top_k=2):
super().__init__()
self.experts = nn.ModuleList([nn.Linear(input_dim, input_dim) for _ in range(num_experts)])
self.gate = nn.Linear(input_dim, num_experts)
self.top_k = top_k
def forward(self, x):
gate_scores = self.gate(x)
top_k_scores, top_k_indices = torch.topk(gate_scores, self.top_k, dim=-1)
expert_weights = torch.softmax(top_k_scores, dim=-1)
# 仅激活Top-k专家,加权求和输出主流大模型(如 GPT-4 参数量约 1.8 万亿,LLaMA 3 约 7000 亿)的参数,本质是 “模型记忆知识、学习规律的容量单位”—— 参数量越大,能存储的 “语义规则”“图像特征” 越多。比如处理 “医学论文摘要生成” 时,千亿级参数能记住不同疾病的病理术语、论文的结构化格式(目的 - 方法 - 结果),而百亿级参数可能出现术语混淆。
训练千亿级模型需依托分布式训练框架(如 Megatron-LM、DeepSpeed),将模型拆分到数百张 GPU(如 A100、H100)上,通过梯度同步实现并行训练。以 GPT-3 为例,若用单张 V100 GPU,需耗时约 355 年,而通过 1024 张 A100 GPU 并行,可将时间压缩至数月。
2、通用能力:预训练任务设计
大模型的 “一专多能”,并非天生具备,而是由预训练阶段的 “任务设计” 决定的。
-
核心任务:MLM(掩码预测)和CLM(因果预测)
-
语言大模型的核心预训练任务是 “掩码语言建模”(MLM,如 BERT)和 “因果语言建模”(CLM,如 GPT)。MLM 通过随机掩盖文本中的部分 token(如将 “大模型是 AI 的重要方向” 改为 “大 [MASK] 是 AI 的 [MASK] 方向”),让模型预测被掩盖的内容,从而学习语义逻辑;CLM 则让模型根据前文预测下一个 token(如根据 “大模型的核心架构是” 预测 “Transformer”),从而掌握文本生成能力。
-
-
跨任务适配:通过提示工程或少量微调快速适应新任务
-
当模型完成预训练后,只需通过 “提示工程”(Prompt Engineering)或 “少量样本微调”(Few-Shot Fine-Tuning),就能适配新任务。比如做 “情感分析” 时,无需重新训练,只需给模型输入 “文本:我很喜欢这个产品。情感:正面。文本:这个产品很差劲。情感:?”,模型就能基于预训练的语义理解,输出 “负面” 结果。
-
# 情感分析微调示例
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./sentiment-model",
per_device_train_batch_size=4,
num_train_epochs=3,
learning_rate=2e-5, # 小学习率微调
fp16=True # 混合精度节省显存
)
# 少量样本即可微调适配新任务3、涌现能力:量变到质变
“涌现能力” 是大模型最特殊的技术现象,其本质是 “当模型参数量和训练数据量突破某一阈值时,模型突然具备未被显式训练的能力”。
-
临界点:参数量突破100-200亿时出现能力跃升
-
语言大模型的涌现能力通常在参数量达到 100 亿 - 1000 亿时出现。比如参数量低于 100 亿的模型,无法准确完成 “逻辑推理题”(如 “甲比乙大,乙比丙大,甲和丙谁大”);而当参数量突破 200 亿后,模型的推理准确率从 30% 跃升至 80% 以上。
-
-
典型表现:数学计算、代码调试、多步推理等复杂任务
-
数学计算(如“1234×5678”)、代码调试(如识别 Python 代码中的 “索引越界错误” 并给出修改方案)、多步推理(如 “根据用户需求设计数据库表结构”)。这些能力并非来自专门的训练数据,而是模型通过学习海量文本中的 “逻辑规则”(如数学公式、代码语法),自主总结出的解题方法。
-
-
技术原理:参数规模允许模型存储和组合更多子任务规则
4、训练数据:知识边界决定因素
-
数据规模:万亿级Token(网页60%、书籍20%、论文10%、代码10%)
-
通过混合海量且多样化的数据源(如网页、书籍、代码)来构建万亿级Token的训练语料。
-
-
预处理流程:清洗→去重→分词→编码
-
对原始数据执行一套标准化的清洗、去重、分词和编码流程,以提升数据质量。
-
-
质量关键:数据多样性决定模型泛化能力
-
数据的质量和多样性直接决定了模型知识库的广度与泛化能力的上限。
-
三、实战应用:从原理到落地
1、代码修复示例
# 输入错误代码
error_code = """
def get_user_names(users):
for i in range(len(users) + 1): # 索引越界
names.append(users[i]["name"])
"""
# 模型自动修复
fixed_code = """
def get_user_names(users):
for i in range(len(users)): # 修正索引范围
names.append(users[i]["name"])
"""2、代码自动补全
# 输入自然语言描述,生成可执行代码
prompt = """
创建一个Python函数,实现以下功能:
- 输入:Pandas DataFrame,包含'price'和'quantity'列
- 输出:新增'total_value'列,计算price * quantity
- 添加数据验证,确保数值列没有负值
"""
# 模型生成代码示例
def calculate_total_value(df):
# 数据验证
if (df['price'] < 0).any() or (df['quantity'] < 0).any():
raise ValueError("价格和数量不能为负值")
df['total_value'] = df['price'] * df['quantity']
return df3、自然语言查询数据
import pandas as pd
from transformers import pipeline
# 初始化分析管道
analyst = pipeline("text2sql", model="gpt-4")
# 自然语言转SQL查询
query = "显示2023年每个季度的销售额前3的产品类别"
sql = analyst(query)
# 输出: "SELECT category, QUARTER(sale_date) as quarter, SUM(amount) as total_sales
# FROM sales WHERE YEAR(sale_date) = 2023
# GROUP BY category, quarter ORDER BY total_sales DESC LIMIT 3"4、智能问答系统
class TechnicalQASystem:
def __init__(self, knowledge_base):
self.knowledge_base = knowledge_base # 技术文档集合
self.retriever = initialize_retriever(knowledge_base)
self.generator = pipeline("text-generation")
def answer_question(self, question, context_size=3):
# 1. 检索相关文档片段
relevant_docs = self.retriever.retrieve(question, k=context_size)
# 2. 构建提示
prompt = f"""
基于以下技术文档内容,回答用户问题:
相关文档:
{relevant_docs}
问题: {question}
要求:
- 答案基于提供的文档内容
- 如果文档中没有相关信息,明确说明
- 提供代码示例如果适用
- 保持专业准确
"""
return self.generator(prompt)
# 使用示例
qa_system = TechnicalQASystem(project_documents)
answer = qa_system.answer_question("如何在我们的系统中实现JWT认证?")5、自动生成分析报告
def generate_analysis_report(df, business_question):
prompt = f"""
基于以下数据概况和业务问题,生成详细分析报告:
数据概况:
- 形状: {df.shape}
- 列名: {list(df.columns)}
- 时间范围: {df['date'].min()} 到 {df['date'].max()}
业务问题: {business_question}
请包括:
1. 关键趋势分析
2. 异常值检测
3. actionable建议
"""
return model.generate(prompt)
# 使用示例
report = generate_analysis_report(sales_df, "找出销售下滑的原因和改进建议")6、分布式训练核心
当模型规模超越单张GPU的内存极限时,分布式训练技术成为唯一的解决方案。这不仅是一个理论研究课题,更是工程师必须掌握的实战技能。
框架支持:Megatron-LM、DeepSpeed
-
Megatron-LM (NVIDIA): 专为Transformer模型设计,高效实现模型并行,能将单个大模型的层或注意力头拆分到不同GPU上。
-
DeepSpeed (Microsoft): 提供ZeRO (Zero Redundancy Optimizer) 等优化器状态、梯度、参数的分区技术,与PyTorch深度集成,极大提升数据并行效率。两者常结合使用,构成训练超大模型的“黄金组合”。
并行策略:数据并行 + 模型并行
-
数据并行:最基础策略。将训练数据批次拆分到多个GPU上,每个GPU持有完整的模型副本,独立计算梯度后同步平均。适用于模型能放入单卡的情况。
-
模型并行:当模型过大时采用。将模型本身的不同部分分布到多个GPU上。例如,将Transformer的不同层放置在不同GPU上(流水线并行),或将一层的大矩阵运算进行切分(张量并行)。
-
混合并行:实战中的主流策略。例如,使用张量并行在节点内的多张GPU间拆分单个模型,同时在多个节点间使用数据并行进行扩展。
算力需求:千亿模型需数百张A100/H100 GPU集群
-
内存瓶颈:千亿参数模型仅参数以FP16精度存储就需约200GB显存,加上训练所需的优化器状态、梯度和激活值,总需求轻松超过1TB。
-
集群规模:以训练LLaMA系列模型为例,需使用超过1000张A100 GPU连续训练数周。这要求工程师不仅要懂算法,还需掌握集群调度、网络通信优化和故障恢复等工程能力。
# 简化的DeepSpeed配置示例,展示如何通过配置文件启动分布式训练
# ds_config.json
{
"train_batch_size": 4096,
"train_micro_batch_size_per_gpu": 16,
"gradient_accumulation_steps": 4,
"zero_optimization": {
"stage": 3, # 使用ZeRO阶段3,将优化器状态、梯度、参数进行分区
"offload_param": {
"device": "cpu" # 显存不足时,将参数卸载到CPU内存
}
},
"fp16": {
"enabled": true # 使用混合精度训练加速计算、节省显存
},
"communication_data_type": "fp16"
}
# 启动命令
# deepspeed --num_gpus=64 train.py --deepspeed_config ds_config.json四、技术趋势洞察
当前大模型技术发展呈现四大核心趋势:
-
架构优化:MoE(混合专家)模型通过稀疏激活机制,在保持参数量级的同时大幅提升计算效率,成为下一代模型的主流架构选择。
-
多模态融合:视觉-语言跨模态对齐技术趋于成熟,统一的Transformer架构能够实现图文、音视频等多模态内容的深度语义理解与生成。
-
推理优化:量化、剪枝、知识蒸馏等模型压缩技术快速发展,推动大模型从云端向边缘设备迁移,显著降低部署成本。
-
安全对齐:RLHF(人类反馈强化学习)等对齐技术持续进化,在提升模型输出安全性和可控性的同时,平衡创造性与伦理约束。
这四大趋势共同推动大模型向更高效、更通用、更易用、更安全的方向演进。
更多推荐

 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)