




- @qq_40767468
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
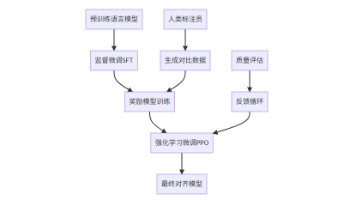
本文深入解析了基于人类反馈的强化学习(RLHF)技术原理及其在大型语言模型中的应用。RLHF通过三阶段训练流程实现模型与人类价值观的对齐:1)监督微调(SFT)使用高质量标注数据优化预训练模型;2)奖励模型训练学习人类偏好,构建响应质量评估体系;3)近端策略优化(PPO)基于奖励反馈微调模型。该技术有效解决了语言模型在价值观对齐、意图理解和安全性等方面的关键问题,已成为ChatGPT等先进模型的核
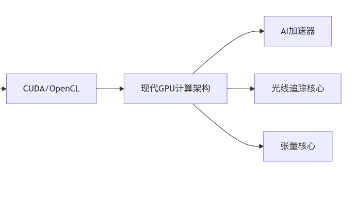
GPU从专用图形处理器到通用计算引擎的演进历程可以分为四个阶段:1)1990年代固定功能图形管线;2)2000年代初可编程着色器;3)2006年统一着色器架构;4)CUDA/OpenCL开启的通用计算时代。关键技术突破包括可编程着色器、统一架构和并行计算API。现代GPU已发展为集图形渲染、通用计算和AI加速于一体的异构处理器,广泛应用于科学计算、人工智能等领域。
本文详细介绍了在Linux系统上安装NVIDIA GPU驱动和CUDA工具包的完整流程。主要内容包括:1)安装前的系统环境检查与硬件要求;2)通过系统包管理器或官方安装程序安装GPU驱动的详细步骤;3)CUDA工具包的版本选择、安装流程及环境配置;4)cuDNN的安装与验证方法。文章提供了多种安装方式的比较,包含代码示例和命令操作,适用于开发者配置深度学习开发环境。

NVIDIA发布革命性Blackwell Ultra GB300 GPU,开启AI计算新纪元。这款采用双芯片架构的GPU基于台积电4NP工艺,集成2080亿晶体管,配备288GB HBM3e内存和8TB/s带宽,计算性能达15-20 PetaFLOPS。其创新之处包括:10TB/s芯片间互联的NV-HBI技术、第四代TensorCore支持多种精度计算、NVLink 5.0实现1.8TB/s互连带

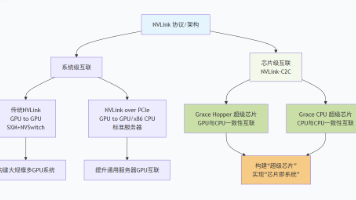
摘要:NVLink技术从系统级高速互联演进至芯片级集成,NVLink-C2C实现了革命性突破。传统NVLink通过专用布线或PCIe物理层连接GPU,解决多GPU系统通信瓶颈;而NVLink-C2C采用先进封装技术,在毫米级距离实现芯片间超高带宽(900GB/s)和内存一致性,形成统一地址空间。这项技术支撑了GraceHopper超级芯片等产品,使CPU/GPU深度融合,为AI大模型训练提供超大内
本文探讨了大型语言模型中的缩放定律,揭示了计算资源、训练数据和模型规模与性能间的数学关系。主要内容包括:1)缩放定律的起源与发展,展示了模型性能随规模增长遵循幂律关系;2)计算量缩放定律(Kaplan定律),分析了计算资源与模型损失的数学关系及最优分配策略;3)数据量缩放定律,研究了训练数据量对性能的影响规律。研究通过Python代码模拟了这些关系,为AI模型的规模规划提供了量化依据,表明在合理范

NVIDIA Tesla A系列专业计算卡的高昂价格源于其先进技术架构与独特定位。采用7nm工艺的A100集成了542亿晶体管,配备HBM2e内存和ECC校验,支持7x24小时高负载运行。研发投入超20亿美元,包含完整的CUDA软件生态。面向AI训练、科学计算等专业领域,其性能可达消费级显卡的2.5倍以上。尽管单价高达数万美元,但通过提升计算效率、降低人力成本,企业用户通常在数月内收回投资。专业计

摘要: ROCm是AMD推出的开源GPU计算平台,旨在挑战NVIDIA CUDA在高性能计算领域的地位。其核心组件包括支持Radeon和Instinct GPU的硬件层、ROCr运行时及HIP工具,后者可实现CUDA代码向ROCm的移植。ROCm还提供对标CUDA的数学库(如rocBLAS、MIOpen),优化HPC和AI任务。尽管开源策略带来透明度和社区优势,但ROCm仍面临生态系统成熟度、性能

本文详细介绍了在Linux系统上安装NVIDIA GPU驱动和CUDA工具包的完整流程。主要内容包括:1)安装前的系统环境检查与硬件要求;2)通过系统包管理器或官方安装程序安装GPU驱动的详细步骤;3)CUDA工具包的版本选择、安装流程及环境配置;4)cuDNN的安装与验证方法。文章提供了多种安装方式的比较,包含代码示例和命令操作,适用于开发者配置深度学习开发环境。
本文深入解析了Transformer中前馈神经网络(FFN)的关键作用。FFN采用两层全连接结构,通常隐藏层维度是输入维度的4倍,在Transformer块中承担了约2/3的参数。通过激活函数,FFN实现了非线性变换能力,在自注意力机制后进一步处理特征。实验分析表明,FFN的内存占用和计算复杂度与输入序列长度线性相关,是Transformer模型性能的重要决定因素。
