
大模型落地全攻略:从技术路径到企业实践(附代码、流程图与案例)
大模型技术落地的四大路径:1)微调技术实现专业领域适配,包括LoRA等高效微调方法;2)提示词工程降低使用门槛,通过结构化设计和思维链技术提升效果;3)多模态应用突破数据边界,在工业质检等领域创造价值;4)企业级解决方案构建完整技术体系,涵盖模型管理、部署和安全合规。文章提供了详细的技术对比、代码实现和可视化流程图,为企业落地大模型提供可复用的方法论框架。
大模型技术正从实验室走向产业界,成为驱动企业数字化转型的核心引擎。然而,大模型落地并非简单的 "拿来主义",需要结合业务场景选择合适的技术路径 ——微调(Fine-tuning) 解决专业领域适配问题,提示词工程(Prompt Engineering) 降低模型使用门槛,多模态应用拓展交互边界,企业级解决方案则实现规模化价值。本文将系统拆解四大落地路径,配套完整代码实现、可视化流程图与实战案例,为大模型落地提供可复用的技术框架与方法论。
一、大模型微调:让通用模型适配专业场景
大模型微调是通过在特定领域数据上继续训练,使通用模型具备专业能力的核心技术。相较于提示词工程,微调能更深度地融合领域知识,尤其适用于数据隐私要求高、任务复杂度高、推理效率要求高的场景。
1.1 微调技术路径对比
不同微调方案在效果、成本、复杂度上存在显著差异,需根据业务需求选择合适方案。
| 微调方案 | 原理 | 数据量需求 | 计算成本 | 适用场景 |
|---|---|---|---|---|
| 全参数微调(Full Fine-tuning) | 更新模型所有参数 | 10 万 + 条 | 极高(需多卡 GPU) | 领域数据充足、追求极致效果 |
| 冻结微调(Frozen Tuning) | 冻结底层参数,仅更新顶层 | 1 万 - 10 万条 | 中高 | 数据中等、需平衡效果与成本 |
| LoRA(Low-Rank Adaptation) | 插入低秩矩阵,仅训练少量参数 | 1 千 - 1 万条 | 低(单卡可完成) | 数据稀缺、成本敏感场景 |
| P-Tuning v2 | 通过可学习 prompt 嵌入层引导模型 | 500-5 千条 | 中低 | 自然语言理解任务、小样本场景 |
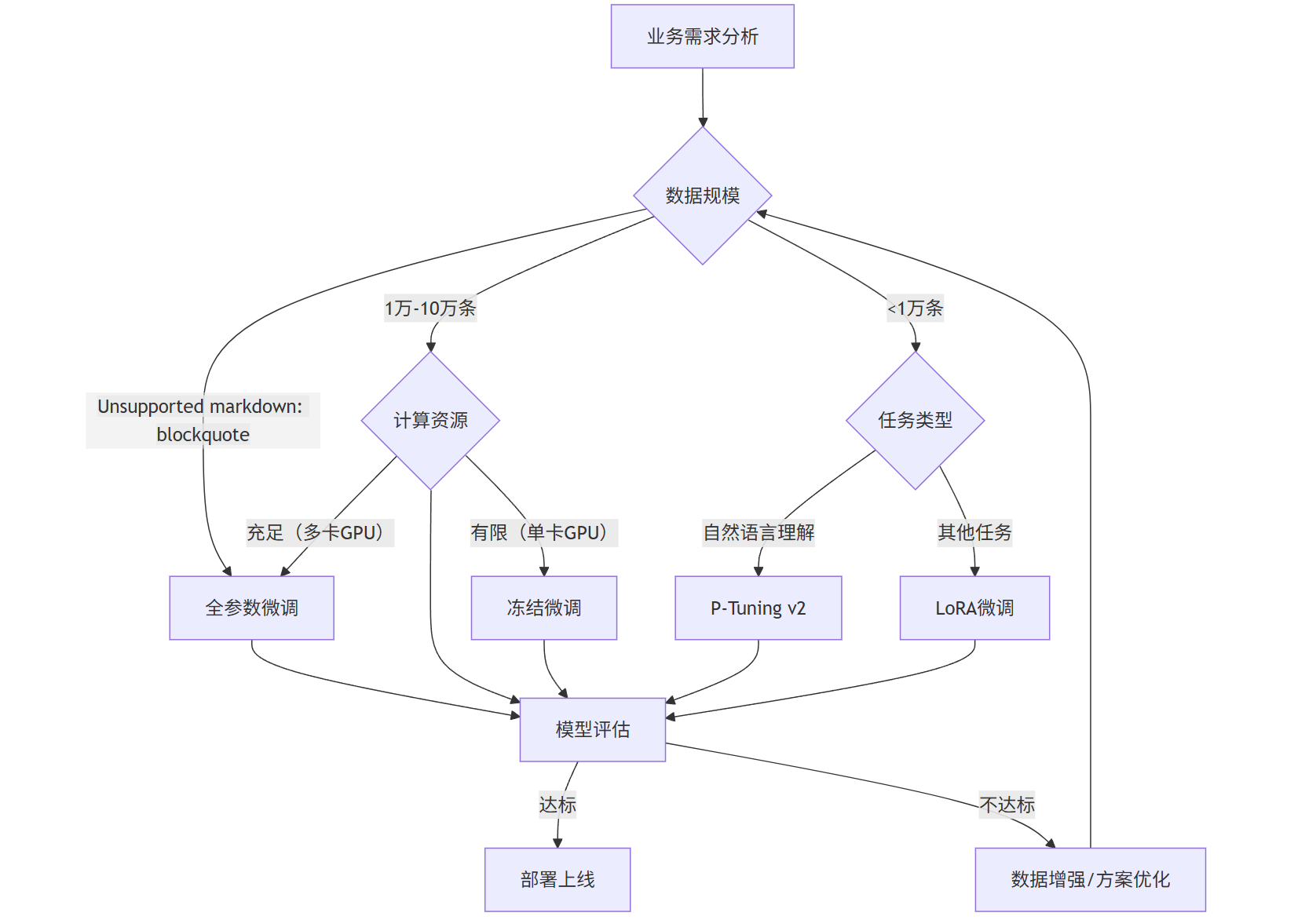
mermaid 流程图:大模型微调方案选择流程
flowchart TD
A[业务需求分析] --> B{数据规模}
B -->|>10万条| C[全参数微调]
B -->|1万-10万条| D{计算资源}
B -->|<1万条| E{任务类型}
D -->|充足(多卡GPU)| C
D -->|有限(单卡GPU)| F[冻结微调]
E -->|自然语言理解| G[P-Tuning v2]
E -->|其他任务| H[LoRA微调]
C & D & F & G & H --> I[模型评估]
I -->|达标| J[部署上线]
I -->|不达标| K[数据增强/方案优化]
K --> B
1.2 LoRA 微调实战(以 LLaMA 2 为例)
LoRA 是当前企业落地中最常用的微调方案,仅训练 0.1%-1% 的参数即可实现接近全量微调的效果,以下是基于 PyTorch 和 peft 库的完整实现。
1.2.1 环境准备
bash
# 安装依赖库
pip install torch transformers datasets peft accelerate evaluate sentencepiece
1.2.2 数据加载与预处理
以医疗问答数据集为例,展示数据处理流程:
python
运行
from datasets import load_dataset
from transformers import AutoTokenizer
# 加载医疗问答数据集(可替换为企业私有数据)
dataset = load_dataset("json", data_files={"train": "medical_qa_train.json", "validation": "medical_qa_val.json"})
# 加载LLaMA 2分词器
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-2-7b-hf",
padding_side="right",
use_fast=False,
)
tokenizer.pad_token = tokenizer.eos_token
# 数据预处理函数
def preprocess_function(examples):
# 构建指令格式:适应大模型指令跟随能力
inputs = [f"### 问题:{q}\n### 回答:" for q in examples["question"]]
targets = examples["answer"]
# 分词处理
model_inputs = tokenizer(
inputs,
max_length=512,
truncation=True,
padding="max_length",
return_tensors="pt"
)
# 处理标签(仅计算回答部分的损失)
labels = tokenizer(
targets,
max_length=512,
truncation=True,
padding="max_length",
return_tensors="pt"
).input_ids
# 将padding部分的标签设为-100(PyTorch忽略-100的损失计算)
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
# 应用预处理函数
tokenized_dataset = dataset.map(
preprocess_function,
batched=True,
remove_columns=dataset["train"].column_names
)
# 构建数据加载器
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_dataset["train"],
batch_size=4,
shuffle=True
)
val_dataloader = DataLoader(
tokenized_dataset["validation"],
batch_size=4,
shuffle=False
)
1.2.3 LoRA 微调配置与训练
python
运行
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments
from peft import LoraConfig, get_peft_model
import torch
# 4-bit量化配置(降低显存占用)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=bnb_config,
device_map="auto", # 自动分配设备
trust_remote_code=True
)
# LoRA配置
lora_config = LoraConfig(
r=8, # 低秩矩阵维度
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标注意力层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM" # 因果语言模型任务
)
# 注入LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数比例(约0.1%)
# 训练参数配置
training_args = TrainingArguments(
output_dir="./llama2-medical-lora",
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=4, # 梯度累积(模拟大batch)
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=10,
evaluation_strategy="epoch", # 每个epoch评估一次
save_strategy="epoch",
fp16=True, # 混合精度训练
push_to_hub=False # 不推送到Hugging Face Hub
)
# 训练器构建与训练
from transformers import Trainer, DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
data_collator=data_collator
)
# 开始训练
trainer.train()
# 保存LoRA权重
model.save_pretrained("./llama2-medical-lora-final")
1.2.4 微调模型推理与评估
python
运行
from peft import PeftModel, PeftConfig
# 加载LoRA配置与基础模型
peft_config = PeftConfig.from_pretrained("./llama2-medical-lora-final")
base_model = AutoModelForCausalLM.from_pretrained(
peft_config.base_model_name_or_path,
quantization_config=bnb_config,
device_map="auto"
)
# 合并基础模型与LoRA权重(推理时可选)
model = PeftModel.from_pretrained(base_model, "./llama2-medical-lora-final")
# 推理函数
def generate_answer(question, max_new_tokens=200):
prompt = f"### 问题:{question}\n### 回答:"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=0.7, # 温度参数(控制随机性)
top_p=0.9,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True).split("### 回答:")[-1]
# 测试推理效果
test_question = "高血压患者日常饮食需要注意什么?"
print(f"问题:{test_question}")
print(f"回答:{generate_answer(test_question)}")
# 模型评估(使用BLEU分数)
import evaluate
bleu = evaluate.load("bleu")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
# 将预测和标签从token ID转换为文本
pred_texts = tokenizer.batch_decode(predictions, skip_special_tokens=True)
label_texts = tokenizer.batch_decode(labels, skip_special_tokens=True)
# 计算BLEU分数
results = bleu.compute(
predictions=pred_texts,
references=label_texts,
max_order=4
)
return {"bleu": results["bleu"]}
# 执行评估
eval_results = trainer.evaluate(metric_key_prefix="eval")
print(f"评估结果:{eval_results}")
1.3 微调关键注意事项
- 数据质量优先:微调效果的上限由数据质量决定,需确保数据标注准确、格式统一、覆盖核心场景,建议进行去重、清洗、脱敏处理。
- 参数高效微调优先:除非有充足的数据和计算资源,否则优先选择 LoRA、P-Tuning 等参数高效微调方案,降低成本与训练风险。
- 增量训练策略:对于持续更新的业务数据,可采用增量微调(Incremental Fine-tuning),避免模型遗忘旧知识(Catastrophic Forgetting)。
- 安全对齐:微调后需进行安全评估,防止模型产生有害输出,可通过加入安全样本、设置输出过滤规则实现。
二、提示词工程:零代码解锁大模型能力
提示词工程(Prompt Engineering)是通过设计高质量的输入指令,在不修改模型参数的情况下引导大模型产生期望输出的技术。其核心价值在于降低大模型使用门槛、快速验证业务场景、灵活适配动态需求,是大模型落地的 "轻骑兵"。
2.1 提示词工程核心原则与方法论
有效的提示词设计需遵循四大核心原则,结合具体任务类型调整结构与内容。
2.1.1 四大核心原则
- 明确性(Specificity):清晰定义任务目标、输出格式、约束条件,避免模糊表述。
- 结构化(Structure):采用分步骤、分模块的指令结构,帮助模型理解任务逻辑。
- 示例引导(Demonstration):通过少量示例(Few-shot Learning)展示期望输出,降低模型理解成本。
- 迭代优化(Iteration):基于模型输出反馈调整提示词,逐步优化效果。
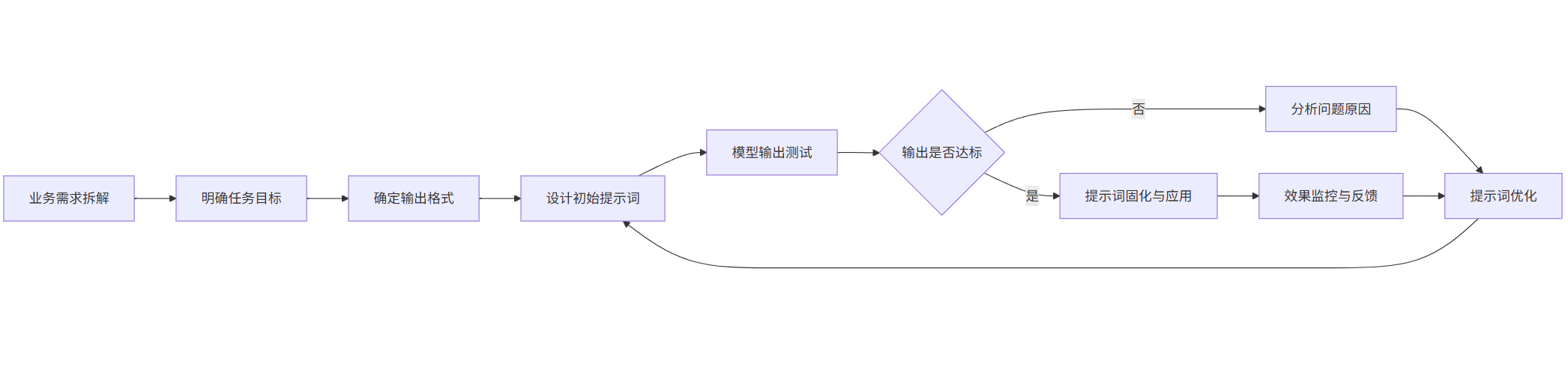
mermaid 流程图:提示词设计与优化流程
flowchart LR
A[业务需求拆解] --> B[明确任务目标]
B --> C[确定输出格式]
C --> D[设计初始提示词]
D --> E[模型输出测试]
E --> F{输出是否达标}
F -->|是| G[提示词固化与应用]
F -->|否| H[分析问题原因]
H --> I[提示词优化]
I --> D
G --> J[效果监控与反馈]
J --> I
2.1.2 常见任务提示词模板
不同任务类型的提示词结构存在差异,以下为三大核心任务的通用模板与示例。
| 任务类型 | 提示词模板 | 实战示例 |
|---|---|---|
| 文本分类 | 1. 定义分类标准2. 提供分类示例3. 输入待分类文本4. 要求输出类别 | Prompt:“请将客户反馈分为以下三类:1. 产品质量问题2. 服务体验问题3. 功能需求建议示例 1:反馈内容:"APP 经常闪退" → 类别:产品质量问题示例 2:反馈内容:"客服响应太慢" → 类别:服务体验问题请分类以下反馈:"希望增加数据导出功能" → 类别:” |
| 信息提取 | 1. 定义提取字段2. 说明字段含义3. 提供提取示例4. 输入待提取文本5. 要求按格式输出 | Prompt:“请从合同文本中提取以下信息,输出格式为 JSON:字段说明:- contract_id:合同编号(格式:HT-XXXX)- party_a:甲方名称- party_b:乙方名称- sign_date:签署日期(格式:YYYY-MM-DD)示例:合同文本:"合同编号 HT-2024001,甲方:XX 科技公司,乙方:XX 制造公司,于 2024 年 03 月 15 日签署。" →{"contract_id": "HT-2024001","party_a": "XX 科技公司","party_b": "XX 制造公司","sign_date": "2024-03-15"}请提取以下合同文本信息:[合同文本内容]” |
| 内容生成 | 1. 定义生成目标2. 明确风格要求3. 设定内容结构4. 提供参考示例5. 要求生成内容 | Prompt:“请为某智能家居品牌撰写产品宣传文案,要求如下:1. 目标人群:25-35 岁年轻家庭2. 风格:简洁、科技感、温馨3. 结构:标题 + 3 个核心卖点 + 结尾呼吁示例:标题:XX 智能灯:点亮你的智慧生活卖点 1:语音控制,解放双手卖点 2:自动调光,适配场景卖点 3:联动全屋,智能协同结尾:立即选购,开启智能家居新体验!请为 "智能扫地机器人" 撰写宣传文案:” |
2.2 进阶提示词技术:思维链(Chain of Thought)
思维链(CoT)是针对复杂推理任务(如数学计算、逻辑分析)的高级提示词技术,通过引导模型 "逐步思考" 提升推理准确性。其核心思想是将复杂问题拆解为多个子问题,让模型显式展示推理过程。
2.2.1 CoT 提示词示例(数学应用题)
基础 Prompt(无 CoT):
plaintext
小明有5个苹果,妈妈又买了3个,爸爸拿走2个,小明现在有几个苹果?
模型可能输出错误答案(如 6 个)
CoT Prompt:
plaintext
请解决以下数学题,要求先列出解题步骤,再给出最终答案:
题目:小明有5个苹果,妈妈又买了3个,爸爸拿走2个,小明现在有几个苹果?
解题步骤:
1. 第一步:计算妈妈买苹果后小明拥有的数量
2. 第二步:计算爸爸拿走苹果后小明拥有的数量
3. 第三步:得出最终结果
答案:
模型正确输出:
plaintext
解题步骤:
1. 第一步:计算妈妈买苹果后小明拥有的数量 → 初始5个 + 妈妈买的3个 = 8个
2. 第二步:计算爸爸拿走苹果后小明拥有的数量 → 8个 - 爸爸拿走的2个 = 6个
3. 第三步:得出最终结果 → 小明现在有6个苹果
答案:6个
2.2.2 CoT 代码实现(基于 LangChain)
LangChain 是简化提示词工程与大模型集成的工具库,以下为 CoT 推理的代码实现:
python
运行
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 初始化LLM(可替换为开源模型如LLaMA 2、Qwen等)
llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0)
# 定义CoT提示词模板
cot_template = """
请解决以下问题,要求先列出解题步骤,再给出最终答案:问题:{question}
解题步骤:
- 第一步:
- 第二步:
- 第三步:
答案:"""
创建提示词模板
prompt = PromptTemplate(input_variables=["question"],template=cot_template)
创建 LLM 链
chain = LLMChain(llm=llm, prompt=prompt)
测试复杂推理问题
question = "一个商店有 3 种笔记本,单价分别为 5 元、8 元和 12 元。小明带了 50 元,想买 6 本笔记本,且每种笔记本至少买 1 本,有多少种不同的购买方案?"
执行推理
result = chain.run(question)print(result)
plaintext
执行结果:
解题步骤:
- 第一步:设三种笔记本分别购买 x、y、z 本,根据题意列出方程:x + y + z = 6(总数量)和 5x + 8y + 12z = 50(总金额),且 x、y、z ≥ 1(每种至少 1 本)
- 第二步:将 x = 6 - y - z 代入金额方程,化简得 3y + 7z = 20,其中 y ≥ 1,z ≥ 1,且 y + z ≤ 5(因为 x ≥ 1)
- 第三步:枚举 z 的可能取值(1 或 2,因为 7*3=21>20),当 z=1 时,3y=13(无整数解);当 z=2 时,3y=6 → y=2,此时 x=3,为唯一有效解
答案:1 种
plaintext
### 2.3 企业级提示词管理系统设计
随着业务场景增多,提示词需要系统化管理以实现版本控制、效果追踪与复用。以下是一个轻量级提示词管理系统的设计方案。
#### 2.3.1 系统架构(mermaid流程图)
```mermaid
flowchart TB
A[用户层] -->|创建/查询/使用| B[API网关]
B --> C[提示词管理服务]
C --> D[版本控制模块]
C --> E[效果评估模块]
C --> F[权限管理模块]
C --> G[模板库]
D --> H[数据库]
E --> H
G --> H
C --> I[大模型服务集成]
I --> J[模型调用记录]
J --> H
2.3.2 核心功能实现(Python Flask)
python
运行
from flask import Flask, request, jsonify
from flask_sqlalchemy import SQLAlchemy
from datetime import datetime
import uuid
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///prompt_management.db'
db = SQLAlchemy(app)
# 提示词模板模型
class PromptTemplate(db.Model):
id = db.Column(db.String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
name = db.Column(db.String(100), nullable=False)
description = db.Column(db.Text)
content = db.Column(db.Text, nullable=False) # 提示词内容(支持变量占位符)
task_type = db.Column(db.String(50)) # 任务类型:分类/提取/生成等
created_at = db.Column(db.DateTime, default=datetime.utcnow)
updated_at = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
created_by = db.Column(db.String(50))
# 提示词版本模型
class PromptVersion(db.Model):
id = db.Column(db.String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
prompt_id = db.Column(db.String(36), db.ForeignKey('prompt_template.id'), nullable=False)
version = db.Column(db.String(20), nullable=False) # 版本号:v1.0.0
content = db.Column(db.Text, nullable=False) # 该版本的提示词内容
change_log = db.Column(db.Text) # 变更日志
created_at = db.Column(db.DateTime, default=datetime.utcnow)
created_by = db.Column(db.String(50))
# 提示词调用记录模型
class PromptInvocation(db.Model):
id = db.Column(db.String(36), primary_key=True, default=lambda: str(uuid.uuid4()))
prompt_id = db.Column(db.String(36), db.ForeignKey('prompt_template.id'))
version = db.Column(db.String(20))
input_params = db.Column(db.Text) # 输入参数(JSON字符串)
model_output = db.Column(db.Text) # 模型输出
evaluation_score = db.Column(db.Float) # 效果评分(1-10)
invoked_at = db.Column(db.DateTime, default=datetime.utcnow)
invoked_by = db.Column(db.String(50))
# 创建数据库表
with app.app_context():
db.create_all()
# 创建提示词模板API
@app.route('/api/prompts', methods=['POST'])
def create_prompt():
data = request.json
new_prompt = PromptTemplate(
name=data['name'],
description=data.get('description', ''),
content=data['content'],
task_type=data.get('task_type', ''),
created_by=data.get('created_by', 'system')
)
db.session.add(new_prompt)
db.session.commit()
# 自动创建初始版本
initial_version = PromptVersion(
prompt_id=new_prompt.id,
version='v1.0.0',
content=data['content'],
change_log='Initial version',
created_by=data.get('created_by', 'system')
)
db.session.add(initial_version)
db.session.commit()
return jsonify({'id': new_prompt.id, 'name': new_prompt.name}), 201
# 获取提示词模板API
@app.route('/api/prompts/<prompt_id>', methods=['GET'])
def get_prompt(prompt_id):
prompt = PromptTemplate.query.get(prompt_id)
if not prompt:
return jsonify({'error': 'Prompt not found'}), 404
versions = PromptVersion.query.filter_by(prompt_id=prompt_id).all()
return jsonify({
'id': prompt.id,
'name': prompt.name,
'description': prompt.description,
'content': prompt.content,
'task_type': prompt.task_type,
'versions': [{'version': v.version, 'created_at': v.created_at} for v in versions]
})
# 调用提示词API(集成大模型)
@app.route('/api/prompts/<prompt_id>/invoke', methods=['POST'])
def invoke_prompt(prompt_id):
data = request.json
prompt = PromptTemplate.query.get(prompt_id)
if not prompt:
return jsonify({'error': 'Prompt not found'}), 404
# 替换提示词中的变量
try:
filled_content = prompt.content.format(**data['params'])
except KeyError as e:
return jsonify({'error': f'Missing parameter: {str(e)}'}), 400
# 调用大模型(此处为示例,实际需替换为真实模型调用)
model_output = f"模拟大模型输出:{filled_content}" # 实际应用中替换为API调用
# 记录调用日志
invocation = PromptInvocation(
prompt_id=prompt_id,
version='v1.0.0', # 实际应用中应支持指定版本
input_params=str(data['params']),
model_output=model_output,
invoked_by=data.get('invoked_by', 'system')
)
db.session.add(invocation)
db.session.commit()
return jsonify({
'output': model_output,
'invocation_id': invocation.id
})
if __name__ == '__main__':
app.run(debug=True)
该系统实现了提示词的全生命周期管理,支持版本控制、调用记录追踪与效果评估,可直接集成到企业现有系统中。
三、多模态应用:打破数据类型边界的智能交互
多模态大模型(如 GPT-4V、Gemini、LLaVA)能同时处理文本、图像、音频等多种数据类型,极大拓展了大模型的应用边界。企业级多模态应用正从单一模态交互向跨模态理解与生成演进,在零售、医疗、制造等领域展现出巨大价值。
3.1 多模态技术架构与应用场景
多模态系统的核心在于模态对齐(将不同类型数据映射到统一语义空间)与跨模态推理(基于多源信息进行决策)。
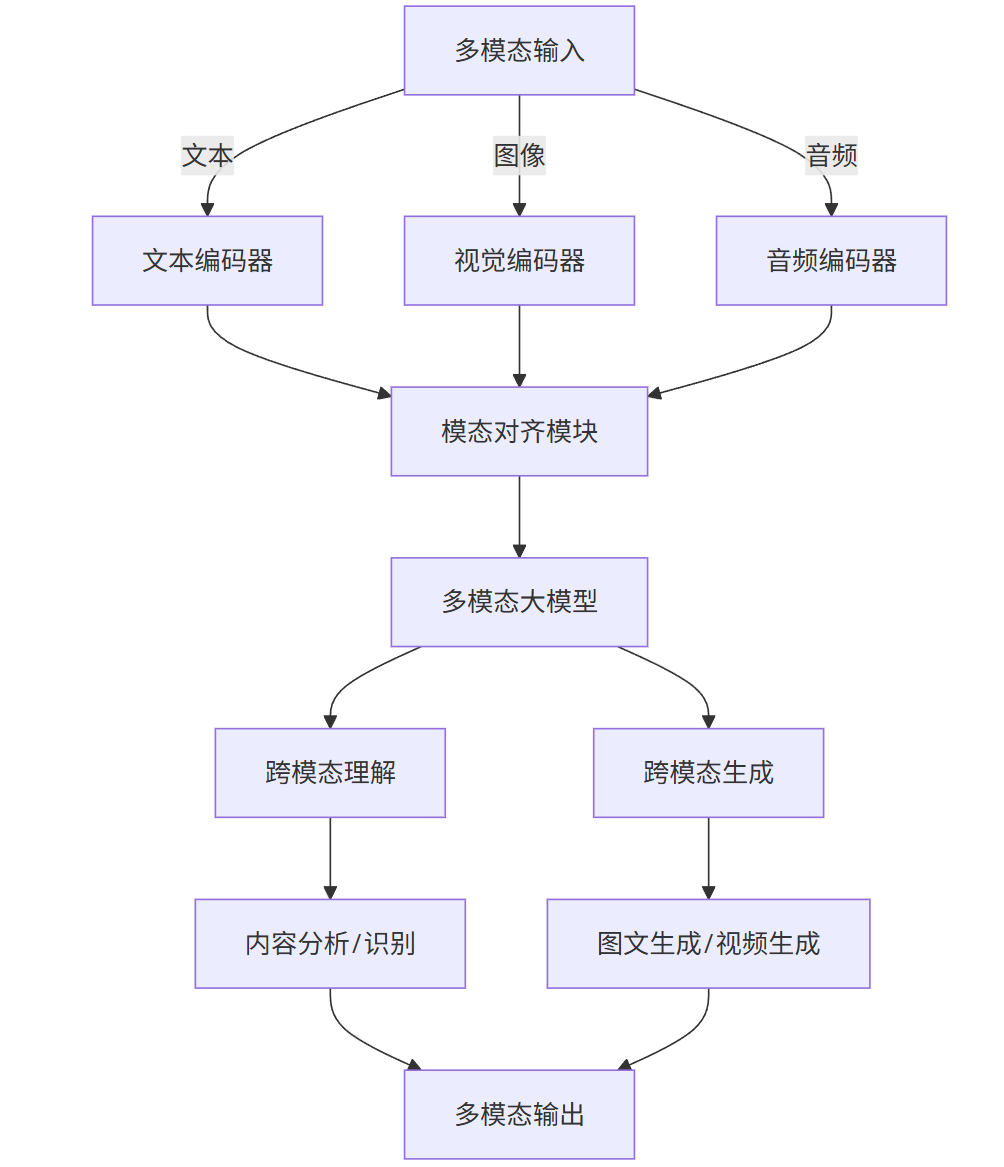
3.1.1 技术架构(mermaid 流程图)
flowchart TB
A[多模态输入] -->|文本| B[文本编码器]
A -->|图像| C[视觉编码器]
A -->|音频| D[音频编码器]
B & C & D --> E[模态对齐模块]
E --> F[多模态大模型]
F --> G[跨模态理解]
F --> H[跨模态生成]
G --> I[内容分析/识别]
H --> J[图文生成/视频生成]
I & J --> K[多模态输出]
3.1.2 核心应用场景与价值
| 行业 | 应用场景 | 技术实现 | 业务价值 |
|---|---|---|---|
| 零售电商 | 商品图文检索 | 图像特征提取 + 文本嵌入 + 向量匹配 | 提升商品搜索准确率 30%+ |
| 智能制造 | 工业质检 | 缺陷图像识别 + 异常描述生成 | 检测效率提升 5 倍,漏检率降低 90% |
| 医疗健康 | 医学影像诊断 | CT/MRI 图像分析 + 诊断报告生成 | 辅助医生诊断,减少误诊率 |
| 教育培训 | 交互式学习 | 图文问答 + 实时讲解生成 | 学习体验提升,知识吸收效率提高 |
| 内容创作 | 视频自动剪辑 | 音频转文本 + 关键帧识别 + 字幕生成 | 内容生产效率提升 60%+ |
3.2 多模态应用实战:工业质检系统
以下是一个基于开源多模态模型 LLaVA 的工业质检系统实现,可自动识别产品缺陷并生成结构化检测报告。
3.2.1 环境准备
bash
# 安装依赖
pip install torch transformers accelerate bitsandbytes pillow gradio
3.2.2 模型加载与推理
python
运行
from transformers import AutoProcessor, LlavaForConditionalGeneration
from PIL import Image
import torch
# 加载LLaVA模型和处理器
model_id = "llava-hf/llava-1.5-7b-hf"
processor = AutoProcessor.from_pretrained(model_id)
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto"
)
# 工业质检提示词模板
def get_quality_check_prompt():
return """
请分析以下工业产品图像,完成质量检测任务:
1. 识别是否存在缺陷(是/否)
2. 若存在缺陷,指出缺陷类型(如裂缝、变形、划痕、污渍等)
3. 描述缺陷位置和严重程度(轻微/中等/严重)
4. 生成检测结论和处理建议
输出格式:
缺陷检测结果:{是/否}
缺陷类型:{类型}
缺陷位置:{位置描述}
严重程度:{程度}
检测结论:{结论}
处理建议:{建议}
"""
# 多模态推理函数
def detect_quality(image_path):
# 加载图像
image = Image.open(image_path).convert('RGB')
# 构建提示
prompt = f"USER: {get_quality_check_prompt()}\nASSISTANT:"
# 预处理输入
inputs = processor(prompt, image, return_tensors="pt").to("cuda")
# 生成检测结果
outputs = model.generate(
**inputs,
max_new_tokens=500,
temperature=0.1, # 降低随机性,提高确定性
do_sample=False
)
# 解码输出
response = processor.decode(outputs[0], skip_special_tokens=True).split("ASSISTANT:")[-1]
return response
# 测试函数
if __name__ == "__main__":
# 测试有缺陷的产品图像
defective_result = detect_quality("defective_product.jpg")
print("有缺陷产品检测结果:")
print(defective_result)
# 测试无缺陷的产品图像
normal_result = detect_quality("normal_product.jpg")
print("\n无缺陷产品检测结果:")
print(normal_result)
3.2.3 可视化交互界面(基于 Gradio)
python
运行
import gradio as gr
# 创建Gradio界面
def create_interface():
with gr.Blocks(title="工业产品质量检测系统") as demo:
gr.Markdown("# 工业产品质量检测系统")
gr.Markdown("上传产品图像,系统将自动检测是否存在缺陷并生成检测报告")
with gr.Row():
with gr.Column(scale=1):
image_input = gr.Image(type="filepath", label="上传产品图像")
detect_btn = gr.Button("开始检测", variant="primary")
with gr.Column(scale=2):
result_output = gr.Textbox(label="检测报告", lines=10)
# 设置按钮点击事件
detect_btn.click(
fn=detect_quality,
inputs=image_input,
outputs=result_output
)
return demo
# 启动界面
if __name__ == "__main__":
demo = create_interface()
demo.launch(server_name="0.0.0.0", server_port=7860)
该系统实现了从图像输入到结构化检测报告输出的全流程自动化,可直接部署在工厂质检环节,大幅提升检测效率与一致性。
3.3 多模态应用落地挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 模态数据不平衡 | 采用对比学习(Contrastive Learning)平衡不同模态数据贡献;对稀缺模态进行数据增强 |
| 推理延迟高 | 模型量化压缩(INT4/INT8);部署优化(TensorRT 加速);关键路径缓存 |
| 小样本场景适配 | 采用提示词工程引导模型;结合领域数据进行轻量微调;使用模型蒸馏技术 |
| 结果解释性差 | 引入注意力可视化;生成推理过程说明;结合领域知识图谱增强解释能力 |
四、企业级解决方案:从技术验证到规模化落地
大模型在企业的规模化落地需要系统化解决方案,涵盖数据治理、模型管理、应用开发、安全合规四大支柱,解决从技术验证(POC)到生产部署(Production)的全流程挑战。
4.1 企业级大模型架构设计
一个稳健的企业级大模型平台应具备模块化、可扩展、安全可控的特点,典型架构如下:
flowchart TB
subgraph 基础设施层
A[GPU集群]
B[容器编排(K8s)]
C[存储系统]
D[监控告警]
end
subgraph 模型层
E[模型仓库]
F[微调框架]
G[推理引擎]
H[模型评估工具]
end
subgraph 应用层
I[提示词工程平台]
J[多模态交互服务]
K[业务集成API]
L[低代码开发平台]
end
subgraph 安全层
M[数据脱敏]
N[访问控制]
O[内容过滤]
P[审计日志]
end
A & B & C & D --> E & F & G & H
E & F & G & H --> I & J & K & L
M & N & O & P --> I & J & K & L
I & J & K & L --> Q[业务系统集成]
4.2 核心组件实现:企业级模型服务平台
以下是一个企业级大模型服务平台的核心组件实现,包含模型管理、部署与监控功能。
4.2.1 模型注册与版本管理
python
运行
# model_registry.py
import os
import json
import shutil
from datetime import datetime
from typing import Dict, List, Optional
class ModelRegistry:
def __init__(self, registry_path: str = "./model_registry"):
self.registry_path = registry_path
self.models_dir = os.path.join(registry_path, "models")
self.metadata_dir = os.path.join(registry_path, "metadata")
# 创建目录
os.makedirs(self.models_dir, exist_ok=True)
os.makedirs(self.metadata_dir, exist_ok=True)
def register_model(
self,
model_name: str,
model_path: str,
version: Optional[str] = None,
description: str = "",
metadata: Optional[Dict] = None
) -> str:
"""注册新模型或新版本"""
# 创建模型目录
model_dir = os.path.join(self.models_dir, model_name)
os.makedirs(model_dir, exist_ok=True)
# 生成版本号
if not version:
versions = self.list_versions(model_name)
version = f"v{len(versions) + 1}.0.0"
# 版本路径
version_dir = os.path.join(model_dir, version)
if os.path.exists(version_dir):
raise ValueError(f"Version {version} of model {model_name} already exists")
# 复制模型文件
shutil.copytree(model_path, version_dir)
# 保存元数据
metadata = metadata or {}
metadata.update({
"model_name": model_name,
"version": version,
"description": description,
"registered_at": datetime.now().isoformat(),
"model_size": self._get_directory_size(version_dir),
"framework": metadata.get("framework", "unknown")
})
metadata_path = os.path.join(self.metadata_dir, f"{model_name}-{version}.json")
with open(metadata_path, "w") as f:
json.dump(metadata, f, indent=2)
return version
def list_models(self) -> List[str]:
"""列出所有模型"""
return [d for d in os.listdir(self.models_dir)
if os.path.isdir(os.path.join(self.models_dir, d))]
def list_versions(self, model_name: str) -> List[str]:
"""列出模型的所有版本"""
model_dir = os.path.join(self.models_dir, model_name)
if not os.path.exists(model_dir):
return []
return [d for d in os.listdir(model_dir)
if os.path.isdir(os.path.join(model_dir, d))]
def get_model_path(self, model_name: str, version: str) -> str:
"""获取模型文件路径"""
model_path = os.path.join(self.models_dir, model_name, version)
if not os.path.exists(model_path):
raise ValueError(f"Model {model_name} version {version} not found")
return model_path
def get_metadata(self, model_name: str, version: str) -> Dict:
"""获取模型元数据"""
metadata_path = os.path.join(self.metadata_dir, f"{model_name}-{version}.json")
if not os.path.exists(metadata_path):
raise ValueError(f"Metadata for {model_name} version {version} not found")
with open(metadata_path, "r") as f:
return json.load(f)
def _get_directory_size(self, path: str) -> str:
"""计算目录大小(人类可读格式)"""
total = 0
for dirpath, _, filenames in os.walk(path):
for f in filenames:
fp = os.path.join(dirpath, f)
total += os.path.getsize(fp)
# 转换为MB/GB
for unit in ['B', 'KB', 'MB', 'GB']:
if total < 1024.0:
return f"{total:.2f} {unit}"
total /= 1024.0
return f"{total:.2f} TB"
# 使用示例
if __name__ == "__main__":
registry = ModelRegistry()
# 注册模型
version = registry.register_model(
model_name="medical-llama2",
model_path="./llama2-medical-lora-final",
description="医疗领域微调的LLaMA 2模型",
metadata={"framework": "PyTorch", "base_model": "Llama-2-7b", "task": "医疗问答"}
)
print(f"Registered model with version: {version}")
# 列出模型
print("All models:", registry.list_models())
# 获取元数据
metadata = registry.get_metadata("medical-llama2", version)
print("Model metadata:", metadata)
4.2.2 模型部署与负载均衡
python
运行
# model_deployer.py
import os
import subprocess
import json
import time
from typing import Dict, List
import requests
from model_registry import ModelRegistry
class ModelDeployer:
def __init__(self, registry: ModelRegistry, base_port: int = 8000):
self.registry = registry
self.base_port = base_port
self.deployments = {} # 格式: {model_version: {port, pid, status}}
self._load_deployments()
def _load_deployments(self):
"""加载已部署的模型信息"""
if os.path.exists("deployments.json"):
with open("deployments.json", "r") as f:
self.deployments = json.load(f)
def _save_deployments(self):
"""保存部署信息"""
with open("deployments.json", "w") as f:
json.dump(self.deployments, f, indent=2)
def deploy_model(
self,
model_name: str,
version: str,
replicas: int = 1,
max_batch_size: int = 8
) -> List[int]:
"""部署模型,返回端口列表"""
model_key = f"{model_name}:{version}"
if model_key in self.deployments:
raise ValueError(f"Model {model_name} version {version} is already deployed")
# 获取模型路径
model_path = self.registry.get_model_path(model_name, version)
# 分配端口
ports = []
for i in range(replicas):
port = self.base_port + len(self.deployments) * 10 + i
ports.append(port)
# 启动模型服务(使用FastAPI+Uvicorn)
cmd = [
"uvicorn",
"model_server:app",
f"--host=0.0.0.0",
f"--port={port}",
f"--workers=1"
]
# 设置环境变量
env = os.environ.copy()
env["MODEL_PATH"] = model_path
env["MAX_BATCH_SIZE"] = str(max_batch_size)
# 启动进程
process = subprocess.Popen(cmd, env=env)
# 记录部署信息
self.deployments[f"{model_key}:{port}"] = {
"model_name": model_name,
"version": version,
"port": port,
"pid": process.pid,
"status": "running",
"replicas": replicas,
"max_batch_size": max_batch_size,
"deployed_at": time.time()
}
self._save_deployments()
return ports
def get_endpoints(self, model_name: str, version: str) -> List[str]:
"""获取模型的所有端点"""
model_key = f"{model_name}:{version}"
endpoints = []
for key, deployment in self.deployments.items():
if key.startswith(model_key) and deployment["status"] == "running":
endpoints.append(f"http://localhost:{deployment['port']}/generate")
return endpoints
def stop_deployment(self, model_name: str, version: str) -> bool:
"""停止模型部署"""
model_key = f"{model_name}:{version}"
to_remove = []
for key, deployment in self.deployments.items():
if key.startswith(model_key):
# 终止进程
try:
os.kill(deployment["pid"], 9)
to_remove.append(key)
except OSError:
pass
# 移除部署记录
for key in to_remove:
del self.deployments[key]
self._save_deployments()
return len(to_remove) > 0
def get_load_balanced_endpoint(self, model_name: str, version: str) -> str:
"""获取负载均衡的端点(简单轮询)"""
endpoints = self.get_endpoints(model_name, version)
if not endpoints:
raise ValueError(f"No running endpoints for {model_name}:{version}")
# 简单轮询策略
# 实际应用中可根据负载情况动态选择
current_time = time.time()
min_load = float('inf')
best_endpoint = endpoints[0]
for endpoint in endpoints:
try:
response = requests.get(f"{endpoint.replace('generate', 'health')}")
if response.status_code == 200:
load = response.json().get('current_batch_size', 0)
if load < min_load:
min_load = load
best_endpoint = endpoint
except:
continue
return best_endpoint
# 模型服务(model_server.py)
# 该文件需要单独创建,实现模型推理的API接口
4.3 企业级落地关键成功因素
- 场景优先级排序:选择 ROI 最高的场景优先落地(如客服对话、文档处理),快速验证价值并获取反馈。
- 数据战略先行:建立企业级知识库与数据治理体系,确保模型训练与推理有高质量数据支撑。
- 混合部署策略:核心敏感场景采用私有部署,通用场景采用 API 调用,平衡安全与成本。
- 人机协同设计:明确大模型与人类的协作边界,在复杂决策环节保留人工审核机制。
- 持续迭代机制:建立模型效果监控与优化流程,根据业务反馈不断调整模型与应用。
五、总结与展望
大模型落地正进入 "深水区",从技术探索走向价值创造。微调技术解决专业领域适配问题,提示词工程降低应用门槛,多模态能力拓展交互边界,企业级平台支撑规模化落地 —— 这四大支柱共同构成了大模型产业落地的完整技术体系。
未来,随着模型效率提升(如 MoE 架构)、部署成本降低(如边缘计算)、安全可控性增强(如联邦学习),大模型将在更多垂直领域实现深度渗透,从辅助工具进化为核心生产力引擎。企业需要建立 "技术 + 业务 + 组织" 三位一体的落地能力,才能在 AI 驱动的产业变革中把握先机。
本文提供的技术框架、代码实现与最佳实践,可为不同规模企业的大模型落地提供参考,关键在于结合自身业务特点选择合适路径,通过快速迭代实现从 0 到 1、从 1 到 N 的持续突破。
更多推荐

 57
57 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)