
多语种、抗噪音、秒识别!讯飞实时语音转写大模型上线
2008-2015年之间,讯飞先后在语音合成、语音评测、语音识别等领域首次超过人类或人类专家水平,此后在机器翻译、机器阅读理解和常识推理等方向上持续突破,并且承担了语音及语言信息处理国家工程研究中心、国家新一代人工智能开放创新平台、认知智能全国重点实验室等平台,这些为讯飞在大模型时代进行语音技术探索奠定了坚实的基础。不仅在支持语种和方言数上业界领先,相比于传统“能转写”的方案,它还把“快、准、稳”
从全球协作,到国际交流,再到知识普惠,实时语音转写已经成为信息传递的重要工具。它让跨越时空的交流更顺畅,让内容的获取更高效。
近期,讯飞实时语音转写大模型上线讯飞开放平台,面向向开发者和企业开放调用。不仅在支持语种和方言数上业界领先,相比于传统“能转写”的方案,它还把“快、准、稳”做到了新高度,堪称语音转写领域的“全能选手”。
语种覆盖广:支持37个语种、202种方言(全国地级市方言全覆盖)免切识别,可满足复杂的多样化语言场景需求;
识别准确率高:抗噪、抗口音干扰效果大幅提升,极大提高了语音识别准确度,转写准确率超98%;
角色分离准:对角色盲分效果重点提升,同时支持基于声纹分离发音人角色,效果突出;
响应速度快:对于音频流实现毫秒级识别,并返回带有时间戳的文字流,便于二次开发;
01
传统转写的“能力天花板”
科幻经典《银河系漫游指南》中,有一种能放进耳朵里、实现宇宙间万物生灵实时翻译的神奇生物——“巴别鱼”。如果说“巴别鱼”寄托了人类跨越语言鸿沟、实现无缝沟通的梦想,那么实时语音转写则让沟通更清晰、更高效。它像一个“隐形速记员”,把每一句对话即时定格为文字,让信息不再流失。
从最初的人工手动转写到如今的智能化、全流程自动化,实时语音转写技术虽在不断革新、应用的场景日益拓展,但人们在使用时常常遇到不少“麻烦”:
大型体育赛事转播中,受背景噪音干扰,观众看到的字幕可能是“模糊、断句不全”的结果;
跨国会议上,因未能及时手动切换翻译模式,在不同语种夹杂的自然表达中,关键信息就此丢失;
团队讨论时,实时语音转写技术虽然能转写出文字,但往往分不清是谁说的,复盘观点无异于一场“考古工作”;
在线教育场景里,如果老师带有浓重口音或方言,字幕往往出现明显延迟甚至错误,学习体验瞬间被打断;
对追求高效的现代企业而言,如何在“实时性、稳定性与多语言覆盖”之间找到平衡,始终是一道难题。
02
大模型赋能,让转写从‘能用’到‘好用
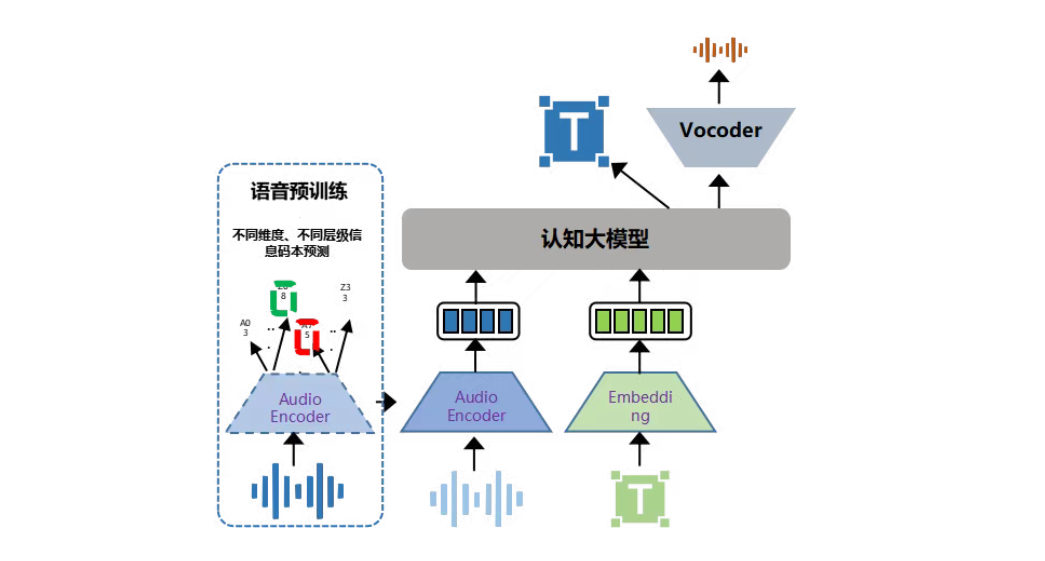
大模型技术的浪潮给语音带来了新的机会,在语音识别方面,提升了语言模型覆盖能力和上下文相关词识别效果,突破复杂场景效果上限;在多语种方面,提升了语料稀缺语种识别效果,以及跨语言声音复刻能力。实时语音转写,也得以有了一次彻彻底底的“进化升级”。
讯飞开放平台上线的实时语音转写大模型,不仅解决了“能识别”的问题,更解决了“识别得够快、够准、够普适”的问题。

37个语种、202种方言免切识别
从需要用户“迁就”机器,变成了机器主动“理解”用户。用户无需任何手动操作,日语、韩语、俄语、法语、希腊语、西班牙语、孟加拉语等语种及四川话、粤语、客家话、闽南话、上海话等方言,模型都能实时、无缝地精准转写,告别因模式切换带来的信息丢失。
在与竞品的实际测试中,讯飞实时语音转写大模型效果优势明显。与传统实时转写相比,中文通用场景中,会议场景的转写准确率提升15%-20%。
角色分离,精准识人
角色盲分效果进行了重点提升,即便在多人自由讨论、无任何预设的场景,也可实时将不同发言人标记为“发言人1”“发言人2”“发言人3”......会议纪要从此告别混乱,每一条观点都能清晰溯源;同时,支持基于声纹注册来分离发音人角色。只需提前录入关键参会人员的声纹,模型在转写时就能直接输出他们的真实姓名或身份。
高识别率,高准确率
实时转写的应用场景(如会议、户外、车载)常存在噪声、回声、远场、多说话人等干扰,基于讯飞提出的声纹与空间信息双重解耦的说话人分离技术、语音识别大模型声学与语言自适应方案,实时语音转写大模型在复杂声学环境下的抗噪、抗口音干扰效果大幅提升,在真实多变的场景中确保语音识别的准确率。
早在2024年,讯飞就已突破了多人混叠场景下的极复杂场景语音转写技术,即使在三人混叠说话的场景也能实现86%的语音识别准确率。
03
多元化场景应用,沟通效率转化为生产力
任何一项技术的价值,都要通过具体的场景落地来验证。当实时语音转写大模型被应用到真实的业务流程时,会发生怎样的化学反应?
- 全球化协作,再无障碍
无论是远程跨国会议,还是线下交流,团队成员可以自由地使用母语或夹杂外语进行讨论。会后,一份自动区分发言人的结构化纪要即刻生成,沟通效率呈指数级提升。
- 智能客服,洞察入微
面对多语种客户,系统不仅能准确记录通话内容,更支持自动质检、情绪分析及客户画像生成,可以更好地提升客户满意度,挖掘服务短板与销售商机。
- 内容创作,拥抱世界
为视频、直播一键生成多语言字幕,内容出海的成本大大降低。一个精彩的创意,可以瞬间触达全球观众。
04
二十余年技术沉淀,产品背后的硬实力
要将场景价值从“承诺”兑现为稳定可靠的“产品能力”,背后需要有扎实的技术作为支撑。深耕语音领域二十余年,讯飞已推出了多项相关的能力和解决方案,并有了大规模的落地实践。
2008-2015年之间,讯飞先后在语音合成、语音评测、语音识别等领域首次超过人类或人类专家水平,此后在机器翻译、机器阅读理解和常识推理等方向上持续突破,并且承担了语音及语言信息处理国家工程研究中心、国家新一代人工智能开放创新平台、认知智能全国重点实验室等平台,这些为讯飞在大模型时代进行语音技术探索奠定了坚实的基础。
2024年1月,星火语音大模型正式推出,首批37个主流语种的语音识别效果超过OpenAI Whisper V3。
6月,凭借“多语种智能语音关键技术及产业化”项目荣获国家科学技术进步奖一等奖,讯飞成为过去十年人工智能领域首个一等奖获得者。
9月,讯飞在国际权威赛事、语音领域公认“最难语音识别任务”——CHiME-8中夺冠,有效解决了人数估计、语音重叠、远场混响、人员移动及对话风格随意等难题。
10月,星火语音大模型的多语种多方言免切换语音识别能力,首次全部覆盖了全国地级市共202种方言。
目前,讯飞的实时语音转写技术已在讯飞翻译机、办公本、讯飞听见等多款智能软硬件产品中搭载,同时服务于2025世界人形机器人运动会、成都大运会等重要赛事。在AI技术生态建设方面,讯飞开放平台已形成了包括实时语音转写大模型在内,以语音为核心的大模型矩阵,覆盖多种场景,面向海内外开发者开放调用。
未来,讯飞将持续优化语种覆盖、准确率与低延迟表现,携手开发者与企业,构建一个信息沟通高效、无障碍的世界。
此外,录音文件转写大模型也已上线讯飞开放平台,可满足用户的非实时音频处理的需求,适用于语音质检、会议访谈等场景。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)