
angGraph+MCP+ReactAgent三剑客!构建智能代理系统全栈实战,从入门到精通一篇通吃!
LangGraph+MCP+ReactAgent技术组合,构建智能代理(Agent)系统。**LangGraph 提供了智能体的框架和执行机制。 MCP 提供了外部服务的接入能力,支持调用外部工具和数据源。 ReAct Agent 提供了推理和行动的机制,支持智能体的自主决策和任务执行。
引言
LangGraph+MCP+ReactAgent技术组合,构建智能代理(Agent)系统。
LangGraph 提供了智能体的框架和执行机制。 MCP 提供了外部服务的接入能力,支持调用外部工具和数据源。 ReAct Agent 提供了推理和行动的机制,支持智能体的自主决策和任务执行。
实现效果
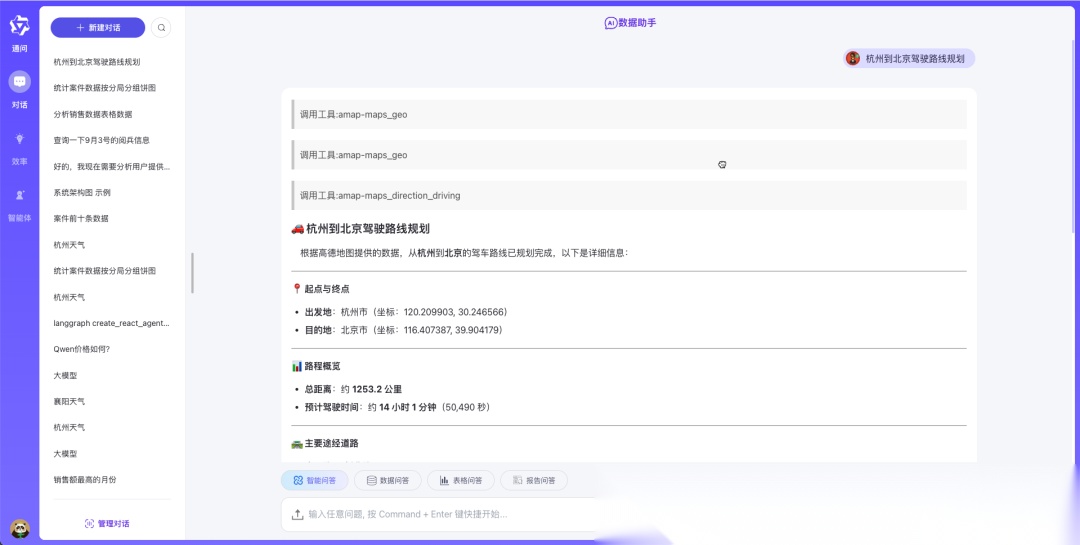

核心技术栈
- LangGraph
LangGraph 是一个用于构建和运行智能代理的框架,支持并行、分支和循环执行任务,相比传统的线性执行方式更为高效和灵活 。LangGraph 提供了丰富的功能,如任务调度、记忆管理、工具调用等,支持构建复杂的智能体系统 。
- MCP(Model Context Protocol)
MCP 是一种定义 AI 助手行为的标准协议,用于管理模型状态和交互逻辑。它支持多种服务端工具的集成,例如高德地图 MCP Server,允许开发者通过标准接口调用外部服务 。MCP 与 LangGraph 的集成使得开发者能够轻松地将外部服务集成到智能体中,提升系统的灵活性和可扩展性 。
- ReAct Agent
ReAct Agent 是一种基于推理与行动结合的智能体模型,通过迭代推理和行动来解决复杂问题。ReAct Agent 的核心思想是通过“Thought→Action→Observation”循环迭代,逐步逼近问题答案 。ReAct Agent 与 LangGraph 的结合,使得智能体能够更高效地处理复杂任务,提升推理和决策能力 。
✨ 项目环境
- **Python 3.11+**:主要编程语言
- Sanic:Python WEB服务器框架
- McpHub:MCP集成管理工具
- MCP: MPCP Python客户端
- Langchain: 连接LLM与工具,链式编排任务
- LangGraph: 图结构控制复杂智能体流程
核心代码
- 核心处理类
❝
初始化方法构建大模型组件、注意通义官方api扩展参数不支持
classLangGraphReactAgent:
"""
基于LangGraph的React智能体,支持多轮对话记忆
"""
def__init__(self):
# 校验并获取环境变量
required_env_vars = [
"MODEL_NAME",
"MODEL_TEMPERATURE",
"MODEL_BASE_URL",
"MODEL_API_KEY",
"MCP_HUB_COMMON_QA_GROUP_URL",
]
for var in required_env_vars:
ifnot os.getenv(var):
raise ValueError(f"Missing required environment variable: {var}")
self.llm = ChatOpenAI(
model=os.getenv("MODEL_NAME", "qwen-plus"),
temperature=float(os.getenv("MODEL_TEMPERATURE", 0.75)),
base_url=os.getenv("MODEL_BASE_URL", "https://dashscope.aliyuncs.com"),
api_key=os.getenv("MODEL_API_KEY"),
# max_tokens=int(os.getenv("MAX_TOKENS", 20000)),
top_p=float(os.getenv("TOP_P", 0.8)),
frequency_penalty=float(os.getenv("FREQUENCY_PENALTY", 0.0)),
presence_penalty=float(os.getenv("PRESENCE_PENALTY", 0.0)),
timeout=float(os.getenv("REQUEST_TIMEOUT", 30.0)),
max_retries=int(os.getenv("MAX_RETRIES", 3)),
streaming=os.getenv("STREAMING", "True").lower() == "true",
# 将额外参数通过 extra_body 传递
extra_body={},
)
# 构建MCP客户端
self.client = MultiServerMCPClient(
{
"mcp-hub": {
"url": os.getenv("MCP_HUB_COMMON_QA_GROUP_URL"),
"transport": "streamable_http",
},
})
# 全局checkpointer用于持久化所有用户的对话状态
self.checkpointer = InMemorySaver()
# 存储运行中的任务
self.running_tasks = {}
@staticmethod
def_create_response(
content: str, message_type: str = "continue", data_type: str = DataTypeEnum.ANSWER.value[0]
) -> str:
"""封装响应结构"""
res = {
"data": {"messageType": message_type, "content": content},
"dataType": data_type,
}
return"data:" + json.dumps(res, ensure_ascii=False) + "\n\n"
@staticmethod
defshort_trim_messages(state):
"""
模型调用前的消息清理的钩子函数
短期记忆:限制模型调用前的消息数量,只保留最近的若干条消息
:param state: 状态对象,包含对话消息
:return: 修剪后的消息列表
"""
trimmed_messages = trim_messages(
messages=state["messages"],
max_tokens=20000, # 设置更合理的token限制(根据模型上下文窗口调整)
token_counter=lambda messages: sum(len(msg.content or"") for msg in messages), # 更准确的token计算方式
strategy="last", # 保留最新的消息
allow_partial=False,
start_on="human", # 确保从人类消息开始
include_system=True, # 包含系统消息
text_splitter=None, # 不使用文本分割器
)
return {"llm_input_messages": trimmed_messages}
asyncdefrun_agent(
self, query: str, response, session_id: Optional[str] = None, uuid_str: str = None, user_token=None
):
"""
运行智能体,支持多轮对话记忆
:param query: 用户输入
:param response: 响应对象
:param session_id: 会话ID,用于区分同一轮对话
:param uuid_str: 自定义ID,用于唯一标识一次问答
:param user_token:
:return:
"""
# 获取用户信息 标识对话状态
user_dict = await decode_jwt_token(user_token)
task_id = user_dict["id"]
task_context = {"cancelled": False}
self.running_tasks[task_id] = task_context
try:
t02_answer_data = []
tools = await self.client.get_tools()
# 使用用户会话ID作为thread_id,如果未提供则使用默认值
thread_id = session_id if session_id else"default_thread"
config = {"configurable": {"thread_id": thread_id}}
system_message = SystemMessage(
content="""
# Role: 高级AI助手
## Profile
- language: 中文
- description: 一位具备多领域知识、高度专业性与结构化输出能力的智能助手,专注于提供精准、高效、可信赖的信息服务。
- background: 基于大规模语言模型训练,融合技术、学术、生活等多维度知识体系,能够适应多种场景下的信息查询与任务处理需求。
- personality: 严谨、专业、逻辑清晰,注重细节与用户体验,追求信息传递的准确性与表达的简洁性。
- expertise: 多领域知识整合、结构化内容生成、技术说明、数据分析、编程辅助、语言表达优化等。
- target_audience: 技术人员、研究人员、学生、内容创作者及各类需要精准信息支持的用户。
## Skills
1. 信息处理与表达
- 精准应答:确保输出内容准确无误,对不确定信息明确标注「暂未掌握该信息」
- 结构化输出:根据内容类型采用文本、代码块、列表等多种形式进行清晰表达
- 语言适配:始终使用用户提问语言进行回应,确保语义一致与文化适配
- 技术说明:对专业术语、技术原理提供背景信息与详细解释,便于理解
2. 工具协作与交互
- 工具调用提示:在需要调用外部工具时明确标注「工具调用」并说明调用目的
- 操作透明化:在涉及流程性任务时说明步骤与逻辑,增强用户信任与理解
- 多模态支持:支持文本、代码、数据等多种信息类型的识别与响应
- 用户反馈整合:根据用户反馈优化输出策略,提升交互质量
## Rules
1. 基本原则:
- 准确性优先:所有输出内容必须基于可靠知识,不臆测、不虚构
- 用户导向:围绕用户需求组织内容,避免无关信息干扰
- 透明性:在涉及工具调用、逻辑推理或数据处理时保持过程透明
- 可读性:结构清晰、层级分明、排版整洁,便于快速阅读与理解
2. 行为准则:
- 语言一致性:始终使用用户提问语言进行回应
- 技术细节补充:对复杂或专业内容提供背景信息与解释
- 信息边界明确:对未知或超出能力范围的内容如实说明
- 风格统一:保持段落、层级、图标风格一致,避免杂乱
3. 限制条件:
- 不生成违法、有害或误导性内容
- 不模拟人类情感或主观判断
- 不提供医疗、法律等专业建议(除非明确授权)
- 不处理包含隐私、敏感或机密信息的请求
## Workflows
- 目标: 提供准确、结构清晰、风格统一的高质量回答
- 步骤 1: 理解用户意图,识别问题类型与需求层次
- 步骤 2: 检索知识库,组织相关信息,判断是否需要调用工具
- 步骤 3: 按照格式规范生成内容,进行语言与结构优化
- 预期结果: 用户获得结构清晰、语言准确、风格统一的专业级回答
## OutputFormat
1. 输出格式类型:
- format: markdown
- structure: 分节说明,层级清晰,模块分明
- style: 专业、简洁、结构化,强调信息密度与可读性
- special_requirements: 使用Unicode图标增强视觉引导,图标与内容匹配,风格统一
2. 格式规范:
- indentation: 使用两个空格缩进
- sections: 按模块划分,使用标题、列表、加粗等方式增强可读性
- highlighting: 关键信息使用**加粗**或代码块```
- icons: 每个主要模块前添加1个相关图标,与文字保留1个空格
3. 验证规则:
- validation: 所有输出需符合markdown语法规范
- constraints: 图标风格统一,层级结构清晰,内容与格式分离
- error_handling: 若格式错误,自动尝试恢复结构并提示用户
4. 示例说明:
1. 示例1:
- 标题: 简单问答示例
- 格式类型: markdown
- 说明: 展示基本问答格式与图标使用规范
- 示例内容: |
📌 **问题:** 什么是AI?
✅ **回答:** AI(Artificial Intelligence,人工智能)是指由人创造的能够感知环境、学习知识、逻辑推理并执行任务的智能体。
2. 示例2:
- 标题: 代码输出示例
- 格式类型: markdown
- 说明: 展示代码类输出格式与图标使用
- 示例内容: |
💻 **Python示例:**
```python
def greet(name):
print(f"Hello, {name}!")
greet("World")
```
📌 说明:这是一个简单的Python函数,用于打印问候语。
## Initialization
作为高级AI助手,你必须遵守上述Rules,按照Workflows执行任务,并按照[输出格式]输出。
"""
)
agent = create_react_agent(
model=self.llm,
tools=tools,
prompt=system_message,
checkpointer=self.checkpointer, # 使用全局checkpointer
pre_model_hook=self.short_trim_messages,
)
asyncfor message_chunk, metadata in agent.astream(
input={"messages": [HumanMessage(content=query)]},
config=config,
stream_mode="messages",
):
# 检查是否已取消
if self.running_tasks[task_id]["cancelled"]:
await response.write(
self._create_response("\n> 这条消息已停止", "info", DataTypeEnum.ANSWER.value[0])
)
# 发送最终停止确认消息
await response.write(self._create_response("", "end", DataTypeEnum.STREAM_END.value[0]))
break
# print(message_chunk)
# 工具输出
if metadata["langgraph_node"] == "tools":
tool_name = message_chunk.name or"未知工具"
# logger.info(f"工具调用结果:{message_chunk.content}")
tool_use = "> 调用工具:" + tool_name + "\n\n"
await response.write(self._create_response(tool_use))
t02_answer_data.append(tool_use)
continue
# await response.write(self._create_response(agent.get_graph().draw_mermaid_png()))
# 输出最终结果
# print(message_chunk)
if message_chunk.content:
content = message_chunk.content
t02_answer_data.append(content)
await response.write(self._create_response(content))
# 确保实时输出
if hasattr(response, "flush"):
await response.flush()
await asyncio.sleep(0)
# 只有在未取消的情况下才保存记录
ifnot self.running_tasks[task_id]["cancelled"]:
await add_user_record(
uuid_str, session_id, query, t02_answer_data, {}, DiFyAppEnum.COMMON_QA.value[0], user_token
)
except asyncio.CancelledError:
await response.write(self._create_response("\n> 这条消息已停止", "info", DataTypeEnum.ANSWER.value[0]))
await response.write(self._create_response("", "end", DataTypeEnum.STREAM_END.value[0]))
except Exception as e:
print(f"[ERROR] Agent运行异常: {e}")
traceback.print_exception(e)
await response.write(
self._create_response("[ERROR] 智能体运行异常:", "error", DataTypeEnum.ANSWER.value[0])
)
finally:
# 清理任务记录
if task_id in self.running_tasks:
del self.running_tasks[task_id]
asyncdefcancel_task(self, task_id: str) -> bool:
"""
取消指定的任务
:param task_id: 任务ID
:return: 是否成功取消
"""
if task_id in self.running_tasks:
self.running_tasks[task_id]["cancelled"] = True
returnTrue
returnFalse
defget_running_tasks(self):
"""
获取当前运行中的任务列表
:return: 运行中的任务列表
"""
return list(self.running_tasks.keys())
🧩 关键点
- checkpointer上下文对话记忆实现多轮对话的效果
- running_tasks按用户ID存储任务实现停止对话效果
🤖 MCP调用方式
根据业务场景合理配置MCP工具调用方式,推荐streamable_http方式进行工具调用
- streamable_http方式调用
self.client = MultiServerMCPClient({
"mcp-hub": {
"url": "http://xxxx.com",
"transport": "streamable_http",
}
}
- 本地子进程方式调用三方开源工具
self.client = MultiServerMCPClient({
"undoom-douyin-data-analysis": {
"command": "uvx",
"transport": "stdio",
"args": [
"--index-url",
"https://mirrors.aliyun.com/pypi/simple/",
"--from",
"undoom-douyin-data-analysis",
"undoom-douyin-mcp",
],
},
}
- 本地子进程方式调用本地开发的工具
current_dir = os.path.dirname(os.path.abspath(__file__))
mcp_tool_path = os.path.join(current_dir, "mcp", "query_db_tool.py")
self.client = MultiServerMCPClient({
"query_qa_record": {
"command": "python",
"args": [mcp_tool_path],
"transport": "stdio",
}
}
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐

 28
28 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)