
AI大模型从零开始系列教程(八)LangChain学习与实战(5) 基于RAG开发问答机器人
RAG是一种用额外数据增强大模型知识的技术,俗称“RAG”(Retrieval-Augmented Generation),中文叫检索增强生成。
前面几篇学习LangChain,基本上完成对 LangChain从开发到上线有一个整体的了解,那么接下来我们就要开始实战了,我们将会使用LangChain开发一个问答机器人,这个问答机器人将会使用到RAG模型,那么接下来我们开始学习RAG。
RAG是什么
RAG是一种用额外数据增强大模型知识的技术,俗称“RAG”(Retrieval-Augmented Generation),中文叫检索增强生成。
RAG是LangChain中一个重要的应用场景,它能够将检索和生成结合起来,从而生成更加精准的答案。
RAG模型由两个部分组成:Retriever和Generator。
- •
Generator生成索引向量,根据文档中问题和答案生成索引向量数据库。 - •
Retriever检索对比类似,根据用户的问题,从生成的知识库中检索召回最相关的问题和答案。
RAG技术是通过检索和生成相结合的方式找最相关的知识内容, 加入到大模型的提示语中,通过大模型推理得到用户问题在知识库中最合适的答案。
下面是我个人依据网上相关资料整理的通用RAG模型架构图:
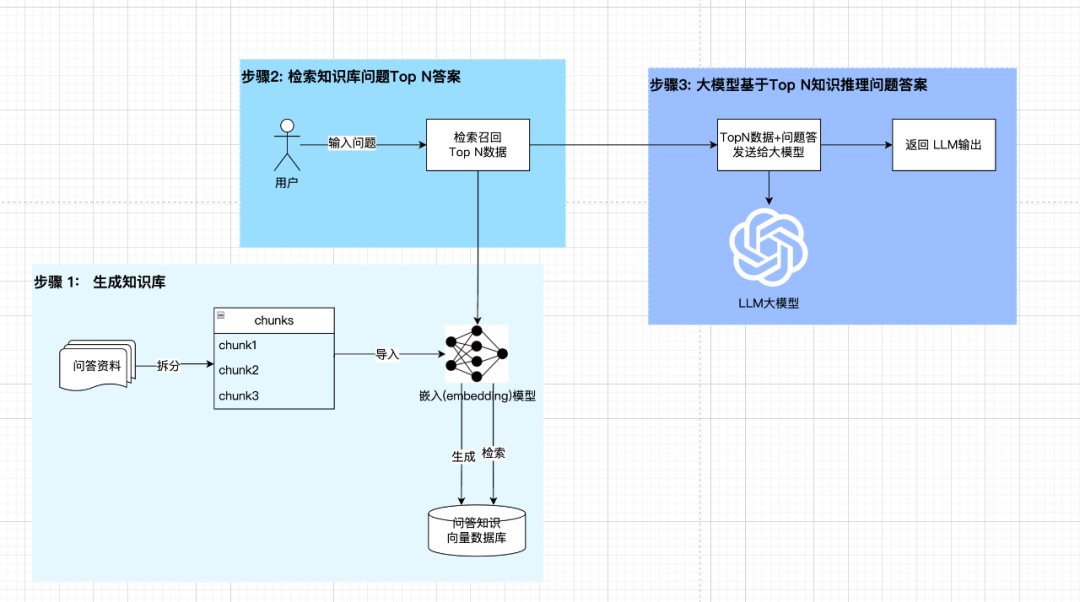
生成向量索引(Indexing)
生成向量索引有三个步骤,分别如下:
-
- 加载(load),加载所需数据,LangChain中提供各种加载器,如:PDFLoader、TextLoader、ImageLoader等。
-
- 分割(Split),将加载的数据进行分割成一个个块,LangChain中提供各种分割器,如:TextSplitter、ImageSplitter等。
-
- 存储(Store),得到分割的Chunks,需要将Chunk转成向量索引并存储,这里我们会依赖
Embeddings模型进行生成索引,然后存储到向量数据库VectorStore。
- 存储(Store),得到分割的Chunks,需要将Chunk转成向量索引并存储,这里我们会依赖
Embeddings嵌入模型
RAG模型使用Embeddings模型将问题和答案进行编码,生成向量数据,这里我们必不可免需要对Embeddings模型进行初步了解。
Embeddings模型,也叫嵌入模型,是一种将高维度的数据,如:自然语言、图片、视频等,转换成低维度的向量数据,如:多维矩阵数组等,方便后续进行相似度对比。
或者我们可以更加直观的理解,Embeddings模型可以把我们人类能够理解的内容,转换成计算机能够计算理解的数据,从而实现更多的算法对比逻辑。
检索和生成
-
- 检索:通过用户输入的内容,使用检索器将内容转换为向量,然后从向量数据库中检索最相关的向量数据。
-
- 生成:通过检索器检索到的向量数据,使用生成器生成新的向量数据,然后存储到向量数据库中。
这两个步骤一般都是同时进行,一般也是 通过Embeddings嵌入模型去转换搜索内容为向量,然后通过检索到最后生成内容。
实战:做一个问答机器人
实现过程
-
- 用户上传问题知识内容上传文件
-
- 服务端对上传文件进行解析,拆分chunk
-
- 将 chunk 传给 Embeddings模型,生成向量索引
-
- 将 向量索引存储到向量数据库中
-
- 用户输入问题,通过检索器检索到最相关的向量数据
-
- 然后将最相关向量数据传给对话大模型,组织推理得到答案,返回给用户
准备工作
Ollama安装模型:
# 对话大模型
ollama install deepseek-r1:7b
# embeddings模型
ollama install shaw/dmeta-embedding-zh:latest
LangChain和 Streamlit安装
# python环境 3.12.4
# streamlit 1.39.0
# toml
pip install langchain
pip install streamlit
requirements.txt文件内容如下:
streamlit==1.39.0
langchain==0.3.21
langchain-chroma==0.2.2
langchain-community==0.3.20
langchain-ollama==0.2.3
streamlit是构建和共享数据应用程序的更快方法, 几分钟内将您的数据脚本转换为可共享的网络应用程序,全部采用纯 Python 编写,无需前端经验。
官方文档:https://docs.streamlit.io/get-started/installation
代码实现
新建一个文件bot_chat.py, 分步骤实现。
1. stremlit页面搭建
代码参考如下:
import streamlit as st
# 设置 st 的标题和布局
st.set_page_config(page_title="RAG测试问答", layout="wide")
# 设置应用标题
st.title("RAG测试问答")
# 支持上传 txt 文件
upload_file = st.sidebar.file_uploader(label="上传文件", type=["txt"])
ifnot upload_file:
st.info("请上传 txt 文件")
st.stop()
执行效果如下:

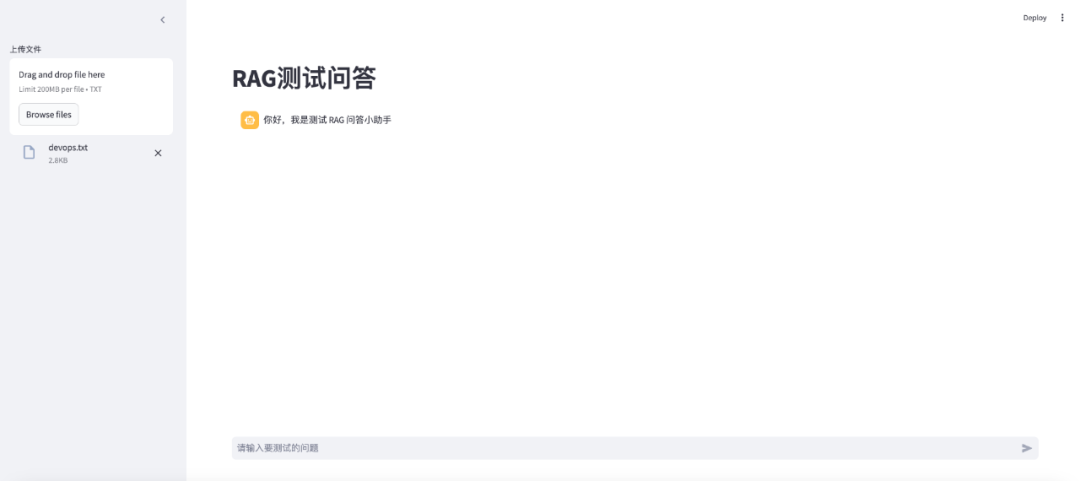
2. 解析文档并生成知识库检索器
import streamlit as st
import tempfile
import os
from langchain.memory import ConversationBufferMemory # 会话记录到内存
from langchain_community.chat_message_histories import StreamlitChatMessageHistory # Streamlit聊天记录存储
from langchain_community.document_loaders import TextLoader # 文本加载器
from langchain_ollama.embeddings import OllamaEmbeddings # Ollama Eembeddings 语言模型
from langchain_chroma import Chroma # Chroma 向量数据库
from langchain_text_splitters import RecursiveCharacterTextSplitter # 文本分割器
# 设置 st 的标题和布局
st.set_page_config(page_title="RAG测试问答", layout="wide")
# 设置应用标题
st.title("RAG测试问答")
# 支持上传 txt 文件
upload_file = st.sidebar.file_uploader(label="上传文件", type=["txt"])
ifnot upload_file:
st.info("请上传 txt 文件")
st.stop()
# step1 实现知识库生成
@st.cache_resource(ttl="1h")
defget_knowledge_base(uploaded_file):
# 读取上传的文档
docs = []
# 将 uploaded_file 存到 /tmp
temp_dir = tempfile.TemporaryDirectory(dir=r"/tmp")
tempfilepath = os.path.join(temp_dir.name, uploaded_file.name)
withopen(tempfilepath, "wb") as f:
f.write(uploaded_file.getvalue())
# 使用 TextLoader 加载文档
docs = TextLoader(tempfilepath, encoding="utf-8").load()
# 使用 RecursiveCharacterTextSplitter 分割文档
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = splitter.split_documents(docs)
# 使用 OllamaEmbeddings 生成文档向量
embeddings = OllamaEmbeddings(base_url="http://127.0.0.1:11434", model="shaw/dmeta-embedding-zh")
# 使用 Chroma 向量数据库存储文档向量
chroma_db = Chroma.from_documents(splits, embeddings)
# 创建文档检索器 约等于 知识库
retriever = chroma_db.as_retriever()
return retriever
retriever = get_knowledge_base(upload_file)
上文件后, 执行效果如下:

3. 初始化聊天消息界面
聊天功能主要几点:
- • 记录聊天内容
- • 显示聊天内容
- • 用户输入框
具体实现代码如下:
# step2 初始化聊天消息界面
# 如果用户输入"清空聊天记录",则重新初始化界面
if"messages"notin st.session_state or st.sidebar.button("清空聊天记录"):
st.session_state["messages"] = [{
"role": "你好",
"content": "我是测试 RAG 问答小助手"
}]
# 显示历史聊天记录
for msg in st.session_state["messages"]:
st.chat_message(msg["role"], msg["content"]) #
# 创建历史聊天记录
msgs = StreamlitChatMessageHistory()
# 创建对话缓存
memory = ConversationBufferMemory(
chat_memory=msgs,
return_messages=True,
memory_key="chat_history",
output_key="out"
)
# 创建 UI 输入框
user_query = st.chat_input(placeholder="请输入要测试的问题")
4. 创建LLM 检索 agent执行
这里实现一个Agent, 过程是 去调用一个检索工具,支持模板和用户输入,调用大模型进行检索,然后返回结果。
具体代码如下:
# step3 创建检索 agent
from langchain.tools.retriever import create_retriever_tool
# step3-1 用于创建文档检索的工具
tool = create_retriever_tool(
retriever=retriever,
name="文档检索",
description="根据输入的关键词,检索相关文档",
)
tools = [tool]
# step3-2 创建 LLM对话模型
# 创建指令 Prompt
instruction = """你是一个设计用于查询文档回答问题的代理
您可以使用文档检索工具,并基于检索内容来回答问题。
可能你不查询文档就知道答案,但是仍然要去查询文档来获得答案。
如果从文档找不到任何信息和答案来回答问题,则需要返回“非常抱歉,这个问题暂时没有录入到知识库中。”作为答案。
"""
base_template = """
{instruction}
TOOLS:
----------
你可以使用以下工具:
{tools}
使用工具中,你可以参考这样子:
ZWJ```
思考:我是否需要使用工具? 是的
动作:我需要使用工具:[{tool_names}]
动作:输入:{input}
动作执行后: 返回动作执行后的结果
ZWJ```
当你需要返回一个答案,且这个答案不需要使用工具时,你可以参考这样子:
ZWJ```
思考:我是否需要使用工具? 不是
答案: [你的答案]
ZWJ```
开始!
上一次历史对话内容如下:
{chat_history}
新的问题是:{input}
{agent_scratchpad}"""
# agent_scratchpad 是 agent 的 scratchpad,用于存储 agent 的状态
# 基础模板
base_prompt = PromptTemplate.from_template(base_template)
# 填充基础模板
prompt = base_prompt.partial(instruction=instruction)
# 创建 LLM 模型
llm = OllamaLLM(base_url="http://127.0.0.1:11434", model="deepseek-r1:7b")
# step3-3 创建 agent
agent = create_react_agent(llm=llm, prompt=prompt, tools=tools)
agent_excutor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
handle_parsing_errors="从知识库没找到对应内容或者答案"
)
5. 用户输入与 Agent返回
这一步基本上就是解决用户输入显示与 Agent返回结果,同时通过 streamlit的 callbank函数去 展示 Agent的执行过程,具体如下:
# step5 用户输入查询与返回
if user_query:
# 添加到 session 历史记录
st.session_state["messages"].append({"role": "user", "content": user_query})
# 显示用户信息
st.chat_message("user").write(user_query)
with st.chat_message("assistant"):
# 创建回调
callback = StreamlitCallbackHandler(st.container())
# 将 agent执行过程 显示在 streamlit中,如:思考、选择工具、执行查询等等
config = {"callbacks": [callback]}
# agent 执行
response = agent_excutor.invoke({"input": user_query}, config=config)
# 保存agent 执行结果到聊天记录
st.session_state["messages"].append({"role": "assistant", "content": response["output"]})
# 显示在 streamlit中
st.write(response["output"])
最终运行
streamlit run bot_chat.py
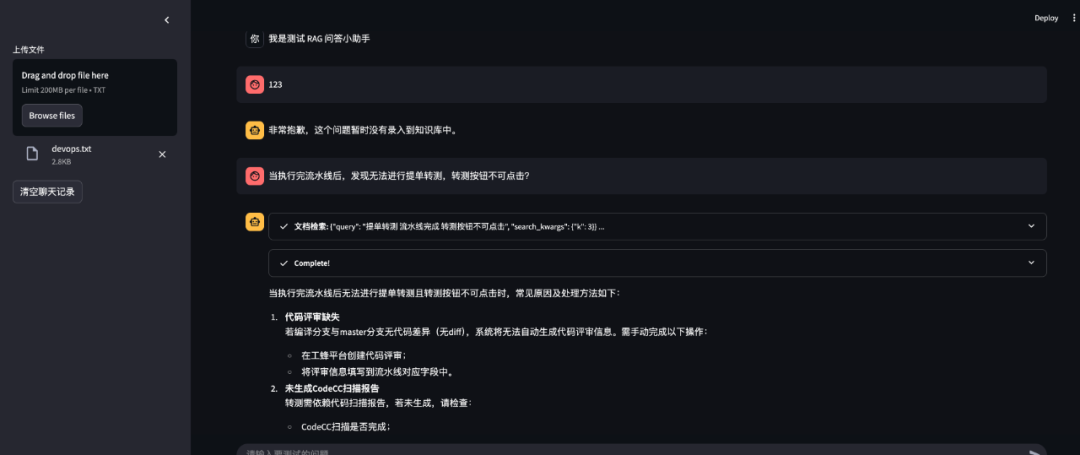
执行效果如下:
对话中:

返回答案:
总结
本文我们主要学习了LangChain的去实现一个RAG智能问答客服,通过Streamlit框架快速搭建一个UI界面,上传知识库文件,利用RAG技术加强大模型的企业内部特有的知识。回顾一下,我们主要学习了以下内容:
- • RAG技术原理,加载(load)、训练(train)、推理(inference)三个步骤
- • Embeddings嵌入模型的具体作用,将文本、图片转换为向量
- • 利用LangChain+Streamlit+Chroma(向量数据库)快速搭建一个企业内部的智能客服问答系统
学习完了,可以玩个游戏放松一下大脑。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取
更多推荐

 6
6 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)