
大模型预训练评估指标
关于大模型的量化指标,较为普遍的有 [PPL],[BPC]等,可以简单理解为在生成结果和目标文本之间的 Cross Entropy Loss 上做了一些处理,这种方式可以用来评估模型对「语言模板」的拟合程度即给定一段话,预测后面可能出现哪些合法的、通顺的字词。
模型效果评测
关于 Language Modeling 的量化指标,较为普遍的有 [PPL],[BPC]等,可以简单理解为在生成结果和目标文本之间的 Cross Entropy Loss 上做了一些处理,这种方式可以用来评估模型对「语言模板」的拟合程度即给定一段话,预测后面可能出现哪些合法的、通顺的字词。
PPL与BPC
在大语言模型的训练和评估过程中,我们需要客观的指标来衡量模型的性能。其中,困惑度(Perplexity, PPL)和每字符比特数(Bits Per Character, BPC)是两个最重要的评估指标。本文将通俗易懂地介绍这两个指标的含义、计算方法和实际应用。
PPL(困惑度)详解
什么是困惑度?
困惑度(Perplexity)是衡量语言模型预测能力的核心指标。可以简单理解为:模型在预测下一个词时的“困惑程度”。
直观理解
想象你在玩一个猜词游戏:
- 低困惑度:模型很“确定”下一个词是什么,就像看到“今天天气很_”时,模型很确定是“好”
- 高困惑度:模型很“困惑”,不知道下一个词可能是什么,就像看到“这个_”时,可能是任何词
数学定义
PPL = 2^(-1/N * Σlog₂P(wᵢ))
其中:
- N是文本总长度
- P(wᵢ)是模型预测第i个词的概率
- log₂是以2为底的对数
通俗解释
- 模型预测每个词的概率:模型看到前面的文字,预测下一个词出现的概率
- 计算平均不确定性:用信息论中的熵来衡量模型的不确定性
- 转换为困惑度:通过指数运算得到最终的困惑度值
PPL的特点
| 特点 | 说明 |
|---|---|
| 数值范围 | [1,+∞),PPL=1是完美模型,PPL越大越差 |
| 实际范围 | 通常在10-1000之间,GPT-3: ~20,随机模型:~10000 |
| 语言相关 | 中文和英文的PPL不能直接比较 |
实际应用示例
# 伪代码示例
sentence = "今天天气很好"
probabilities = model.predict_probs(sentence)
# [0.8, 0.7, 0.9, 0.6] #每个词的预测概率
# 计算困惑度
import math
log_sum = sum(math.log2(p) for p in probabilities)
ppl = 2 ** (-log_sum / len(probabilities))
print(f"困惑度:{ppl}") # 输出:困惑度:2.1
BPC(每字符比特数)详解
什么是BPC?
每字符比特数(Bits Per Character)是从信息压缩角度衡量模型性能的指标。它回答了一个问题:平均每个字符需要多少比特来编码?
直观理解
把语言模型想象成一个智能压缩器:
- 低BPC:模型能很好地“压缩”文本,说明它理解了语言的规律
- 高BPC:模型压缩效果差,说明它没有很好地掌握语言模式
数学定义
BPC = -1/N * Σlog₂P(cᵢ)
其中:
- N是字符总数
- P(cᵢ)是模型预测第i个字符的概率
- log₂是以2为底的对数
PPL与BPC的关系
- BPC = log₂(PPL)
- PPL = 2^BPC
这意味着它们本质上是同一个指标的不同表示形式!
BPC的优势
| 优势 | 说明 |
|---|---|
| 跨语言比较 | 可以在不同语言间进行比较 |
| 直观理解 | 直接对应信息论中的熵概念 |
| 压缩视角 | 从数据压缩角度理解模型性能 |
实际应用示例
# 计算BPC
import math
text = "Hello world!"
char_probs = model.predict_char_probs(text)
# [0.1, 0.2, 0.15, ...] # 每个字符的预测概率
bpc = -sum(math.log2(p) for p in char_probs) / len(text)
print(f"BPC: {bpc:.2f}") # 输出: BPC: 2.34
# 对应的PPL
ppl = 2 ** bpc
print(f"对应PPL: {ppl:.2f}") # 输出: 对应PPL: 5.07
性能基准对比
不同模型的典型表现
| 模型类型 | PPL范围 | BPC范围 | 说明 |
|---|---|---|---|
| 随机模型 | ~10000 | ~13.3 | 完全随机预测 |
| N-gram模型 | 100-500 | 6.6-8.9 | 传统统计模型 |
| LSTM/GRU | 50-150 | 5.6-7.2 | 早期神经网络 |
| Transformer小 | 20-50 | 4.3-5.6 | 现代架构 |
| 大型LLM | 10-25 | 3.3-4.6 | GPT-3/4级别 |
| 理论最优 | ~1 | ~0 | 完美模型 |
实际案例分析
模型A训练进度
- Epoch 1: PPL=156.2, BPC=7.28
- Epoch 5: PPL=67.4, BPC=6.07 ← 性能提升
- Epoch 10: PPL=23.8, BPC=4.57 ← 继续改善
- Epoch 15: PPL=19.2, BPC=4.26 ← 趋于收敛
实用指南
何时使用PPL vs BPC?
| 场景 | 推荐指标 | 原因 |
|---|---|---|
| 单语言模型比较 | PPL | 更直观,业界常用 |
| 跨语言比较 | BPC | 消除语言差异影响 |
| 学术论文 | 两者都报告 | 方便不同读者理解 |
| 模型调试 | PPL | 更容易解释变化 |
优化建议:如何降低PPL/BPC?
- 增加模型容量:更多层数→更强表达能力→更低困惑度
- 改进训练数据:高质量数据→更好语言模式→更准确预测
- 优化训练策略:合适学习率→充分收敛→更低损失
- 使用预训练模型:知识迁移→更好初始化→更快收敛
注意事项
- 不要过度拟合
- 训练集PPL很低,但验证集PPL很高
- 需要关注泛化能力
- 数据预处理的影响
- 分词方式会影响PPL计算
- 确保比较模型使用相同预处理
- 计算精度问题
- 概率值可能非常小,注意数值稳定性
- 通常在对数空间计算
模型效果评测
[PPL]、[BPC]这种方式可以用来评估模型对「语言模板」的拟合程度,即给定一段话,预测后面可能出现哪些合法的、通顺的字词。但仅仅是「生成通顺句子」的能力现在已经很难满足现在人们的需求,大部分 LLM 都具备生成流畅和通顺语句能力,很难比较哪个好,哪个更好。
为此,我们需要能够评估另外一个大模型的重要能力——知识蕴含能力。
C-Eval
一个很好的中文知识能力测试数据集是 [C-Eval],涵盖1.4w 道选择题,共52 个学科。
覆盖学科如下:

由于是选择题的形式,我们可以通过将题目写进 prompt 中,并让模型续写1个 token,判断这个续写 token 的答案是不是正确答案即可。但大部分没有精调过的预训练模型可能无法续写出「A B C D」这样的选项答案,因此,官方推荐使用 5-shot 的方式来让模型知道如何输出答案:
以下是中国会计考试的单项选择题,请选出其中的正确答案。下列关于税法基本原则的表述中,不正确的是___
A.税收法定原则包括税收要件法定原则和税务合法性原则
B.税收公平原则源于法律上的平等性原则
C.税收效率原则包含经济效率和行政效率两个方面
D. 税务机关按法定程序依法征税,可以自由做出减征、停征或免征税款的决定
答案:D
甲公司是国内一家领先的新媒体、通信及移动增值服务公司,由于遭受世界金融危机,甲公司经济利润严重下滑,经营面临困境,但为了稳定职工队伍,公司并未进行裁员,而是实行高层管理人员减薪措施。甲公司此举采用的收缩战略方式是____。
A.转向战略
B.放弃战略
C.紧缩与集中战略
D.稳定战略
答案:C...
#第3,4,5道样例题
下列各项中,不能增加企业核心竞争力的是___
A.产品差异化
B.购买生产专利权
C.创新生产技术
D.聘用生产外包商
答案:
通过前面的样例后,模型能够知道在「答案:」后面应该输出选项字母。于是,我们获得模型续写后的第一个 token 的概率分布 (logits),并取出A、B、C、D这4个字母的概率,通过 softmax 进行归一化:
C-Eval 通过这种方式测出了许多模型在中文知识上的效果,由于是4 选项问题,所以基线(随机选择) 的正确率是25%。C-Eval 也再一次证明了 GPT-4 是个多么强大的知识模型。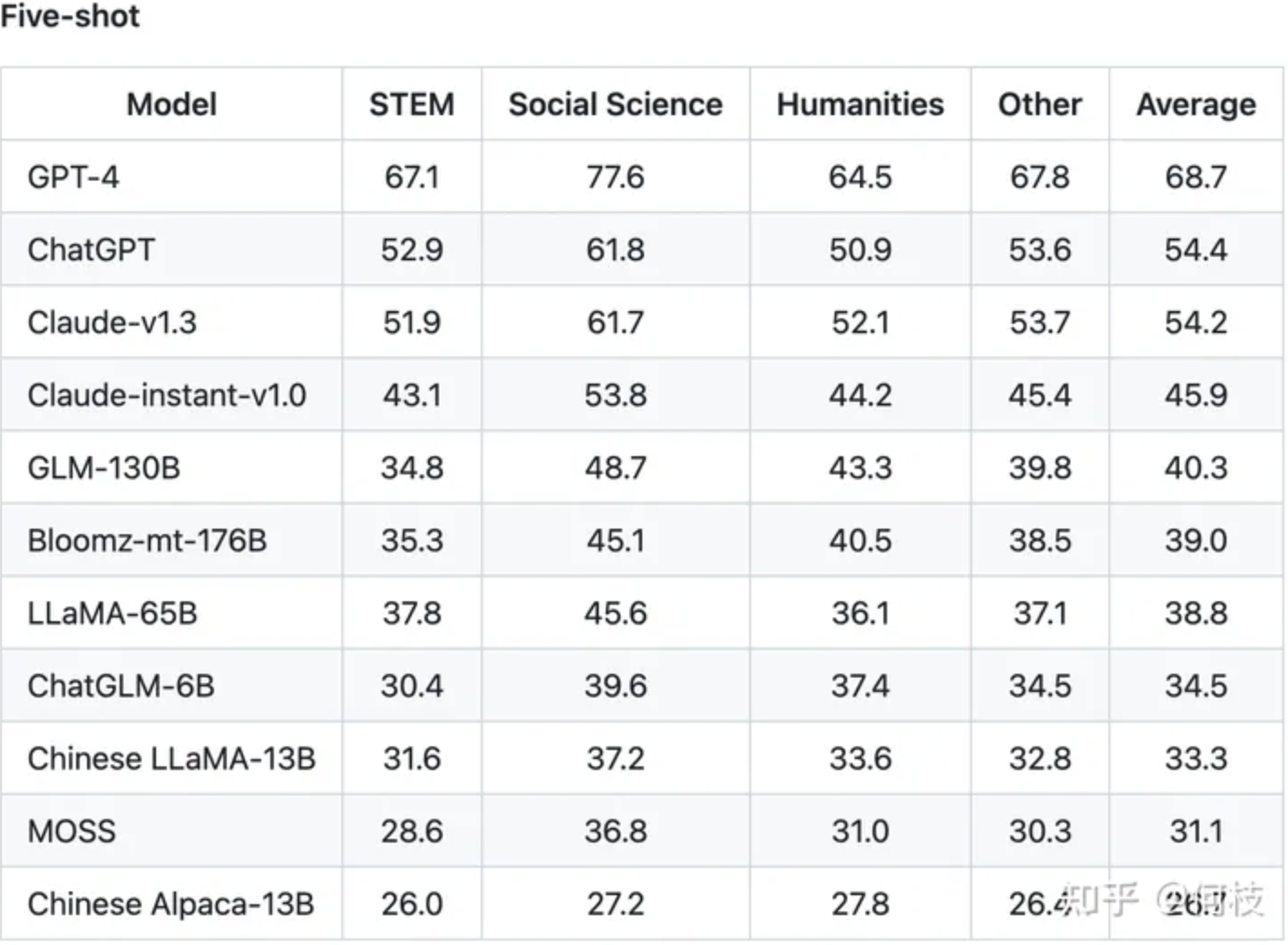
MMLU (Massive Multitask Language Understanding)
基本介绍
MMLU 是目前最权威的大模型综合能力评估基准之一,由加州大学伯克利分校等机构开发。
数据集构成
- 总题目数:15,908道选择题
- 学科领域:57个不同学科
- 题目类型:四选一的多项选择题
- 难度层次:从小学到专业研究生水平
具体学科分类
| 学科类别 | 具体学科 | 示例 |
|---|---|---|
| STEM | 数学、物理、化学、生物 | 微积分、量子力学、有机化学 |
| 人文学科 | 历史、哲学、文学 | 世界历史、道德哲学、英美文学 |
| 社会科学 | 心理学、社会学、政治学 | 发展心理学、社会学研究方法 |
| 其他 | 法律、医学、商业 | 职业法律、临床知识、管理学 |
评估方法
# MMLU评估流程
def evaluate_mmlu (model, question, choices):
"""
问题示例:
Q:以下哪个不是细胞膜的主要成分?
A.磷脂
B.蛋白质
C.胆固醇
D.纤维素
"""
# 构建prompt
prompt = f"Question: {question}\n"
for i, choice in enumerate(['A','B','C','D']):
prompt += f"{choice}. {choices[i]}\n"
prompt += "Answer:"
#获取模型预测
prediction = model.generate(prompt)
return extract_choice(prediction) # 提取A/B/C/D]
性能基准
| 模型类别 | 说明 | MMLU得分 |
|---|---|---|
| 完全随机猜测的基线 | 随机选择 | 25% |
| 人类平均 | 各学科专家的平均表现 | 89.80% |
| 早期大模型表现 | GPT-3.5 | 70.00% |
| 接近人类专家水平 | GPT-4 | 86.40% |
| 顶级模型性能 | Claude-3 | 86.80% |
评估意义
- 知识广度:测试模型在不同领域的知识储备
- 理解能力:评估阅读理解和逻辑推理
- 多任务能力:一个指标涵盖多个学科
- 局限性:主要测试记忆性知识,创造性较少
HellaSwag
基本介绍
HellaSwag 专门评估模型的常识推理能力,通过"情境续写"任务测试模型对日常生活的理解。
数据集特点
- 任务类型:情境续写选择题
- 数据来源:WikiHow和ActivityNet
- 题目数量: 约70,000个样本
- 选项设计:人工筛选的高质量干扰项
典型题目示例
情境:一个人正在厨房准备做饭
开头: 他打开冰箱,拿出了一些蔬菜…
选项:
A.然后他把蔬菜放在烤箱里烤制
B. 他开始清洗蔬菜并切成小块√
C.他把蔬菜直接扔进垃圾桶
D.他用蔬菜来装饰房间
评估维度
| 能力维度 | 说明 | 示例场景 |
|---|---|---|
| 物理常识 | 对物理世界的基本理解 | 重力、时间序列等 |
| 社会常识 | 人际互动和社会规范 | 礼貌用语、社交场合 |
| 因果推理 | 理解行为的原因和结果 | 动作的合理后续 |
| 时间逻辑 | 事件的先后顺序 | 做饭的步骤顺序 |
性能表现
| 模型 | 说明 | HellaSwag得分 |
|---|---|---|
| 随机选择 | 基线表现 | 25% |
| 人类表现 | 人类基准 | 95.60% |
| BERT-Large | 早期预训练模型 | 78.10% |
| GPT-3 | 大模型突破 | 78.90% |
| GPT-4 | 接近人类水平 | 95.30% |
评估代码示例
def evaluate_hellaswag (model, context, endings):
"""
HellaSwag评估示例
"""
scores =[]
for ending in endings:
#计算每个结尾的概率
full_text = context + ending
score = model.calculate_probability (full_text)
scores.append(score)
# 选择概率最高的结尾
predicted_idx = np.argmax(scores)
return predicted_idx
HumanEval
基本介绍
HumanEval 是由OpenAl开发的代码生成能力评估基准,专门测试模型编写Python代码的能力。
数据集构成
- 题目数量:164个编程问题
- 语言:Python
- 难度:入门到中等水平
- 评估方式:单元测试验证
题目特点
| 特点 | 说明 | 示例 |
|---|---|---|
| 函数签名 | 给定函数名和参数 | def is_palindrome(s: str) -> bool: |
| 文档字符串 | 详细的功能描述 | 判断字符串是否为回文 |
| 测试用例 | 隐藏的单元测试 | 各种边界情况测试 |
| 自包含 | 不需要外部依赖 | 每个问题独立解决 |
典型题目示例
def has_close_elements (numbers: List [float], threshold: float) -> bool:
"""
检查列表中是否有两个数字的距离小于给定阈值
>>> has_close_elements([1.0, 2.0, 3.0], 0.5)
False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
True
"""
# 模型需要在这里生成代码
评估指标
- Pass@k:在k次尝试中至少有一次通过所有测试用例的比例
- Pass@1:第一次尝试就成功的比例(最常用)
- Pass@10:10次尝试中成功的比例
- Pass@100:100次尝试中成功的比例
性能基准
| 模型 | Pass@1 | Pass@10 | Pass@100 |
|---|---|---|---|
| GPT-3 (175B) | 0% | 2.50% | 5.00% |
| Codex (12B) | 28.80% | 46.80% | 72.30% |
| GPT-3.5 | 48.10% | 66.80% | 77.70% |
| GPT-4 | 67.00% | 82.00% | 87.20% |
| Claude-3 | 71.20% | 84.90% | 89.00% |
评估流程
def evaluate_humaneval (model, problem) :
"""
HumanEval评估流程
"""
# 1.构建prompt
prompt = f"""
{problem['prompt']}
#请完成上述函数
"""
# 2.生成代码
generated_code = model.generate(prompt)
#3.执行测试
try:
exec(generated_code)# 执行生成的代码
# 运行隐藏测试用例
test_results = run_test_cases(problem['test_cases'])
return all(test_results)#所有测试通过返回True
except Exception as e:
return False #代码错误返回False]
GSM8K (Grade School Math 8K)
基本介绍
GSM8K 专门评估模型的数学推理能力,通过小学水平的数学应用题测试逻辑推理。
数据集特点
- 题目数量:8,500个数学应用题
- 难度水平:小学生水平(2-8年级)
- 题目类型:多步骤推理题
- 答案格式:需要推理过程和最终数值答案
典型题目示例
题目:
1
2 Janet养鸭子。她的鸭子每天下16个蛋。她每天早餐吃3个,
3 下午为朋友烤蛋糕用4个。她每天在农贸市场以每个2美元的价格出售剩余的鸡蛋。
4 她每天赚多少钱?
5 推理过程:
6 1.总蛋数:16个
7
8 2.早餐消耗:3个
9 3.烤蛋糕消耗:4个
10 4.出售蛋数:16 -3-4=9个
11 5.每日收入:9 ×2=18美元
12
13 答案:18
评估维度
| 能力 | 说明 | 示例 |
|---|---|---|
| 算术运算 | 基本的加减乘除 | 计算总价、找零 |
| 多步推理 | 逻辑链条推理 | 先算中间结果,再算最终答案 |
| 文字理解 | 理解题目描述 | 提取关键数字和关系 |
| 应用场景 | 实际生活应用 | 购物、时间、距离等 |
性能表现
| 模型 | 说明 | GSM8K得分 |
|---|---|---|
| GPT-3 (175B) | 早期大模型表现较差 | 14.6% |
| PaLM (540B) | 大参数量提升明显 | 56.5% |
| GPT-3.5 | 专门优化推理能力 | 57.1% |
| GPT-4 | 接近人类学生水平 | 92.0% |
| Claude-3 | 优秀的推理表现 | 88.0% |
其他重要评估指标
PIQA (Physical Interaction QA)
- 用途:物理常识推理
- 题目:关于日常物理交互的问题
- 示例:如何最好地清洁眼镜?
WinoGrande
- 用途:代词消歧任务
- 题目:判断代词指代关系
- 特点:需要深度理解和推理
分数解读指南
| 得分范围 | 说明 | 性能等级 |
|---|---|---|
| 90%+ | 接近人类专家水平 | 优秀 |
| 80-90% | 实用性较高 | 良好 |
| 70-80% | 基本可用 | 中等 |
| 60-70% | 需要改进 | 较差 |
| <60% | 不建议使用 | 很差 |
选择评估指标的建议
| 应用场景 | 推荐指标 | 原因 |
|---|---|---|
| 通用AI助手 | MMLU + HellaSwag | 需要广泛知识和常识 |
| 代码生成 | HumanEval + MBPP | 专门评估编程能力 |
| 数学AI | GSM8K + MATH | 重点评估推理能力 |
| 中文应用 | C-Eval + CLUEWSC | 针对中文优化 |
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)