
全民AI:RocketMQ 已接入 AI
一、RocketMQ为什么要“接入AI”?
RocketMQ确实可以“把消息发给AI模型”,但RocketMQ for AI做的事情,远不止“发消息”这么简单。
我们先看一个真实的场景:
你做了一个Multi-Agent(多智能体)系统——用户提一个问题,Supervisor Agent把问题拆解成3个子任务,分别发给3个专业的子Agent去处理,最后汇总结果返回给用户。
如果用同步调用的方式:
用户请求 → Supervisor Agent → 阻塞等待Agent1 → 阻塞等待Agent2 → 阻塞等待Agent3 → 汇总返回
每个Agent处理可能需要3-5秒,3个Agent串行下来,用户要等10-15秒才能看到结果。
而且这期间,处理线程一直被占用着,系统并发能力急剧下降。
如果用RocketMQ异步通信的方式:
用户请求 → Supervisor Agent → 发消息到Topic1/Topic2/Topic3 → 立即返回
Agent1/Agent2/Agent3各自消费消息 → 处理完成后发结果到Response Topic → Supervisor Agent汇总 → 推送用户
整个过程非阻塞,系统吞吐量可以提升好几个数量级。
这就是RocketMQ接入AI的核心价值——把长耗时的AI任务调用,从同步阻塞模式,变成异步非阻塞模式。
RocketMQ 5.5.0版本引入的面向AI工作负载的战略升级,正是为了解决这一系列AI应用中的核心痛点。
二、核心技术:LiteTopic
它是为AI场景而生的轻量主题。
传统消息队列的Topic,创建和管理都需要一定的资源开销。
如果你要为每一个AI会话、每一个Agent任务都创建一个独立的Topic,传统Topic根本扛不住。
RocketMQ 5.x专门为AI场景设计了LiteTopic(轻量主题) 。
2.1 LiteTopic的五大核心特性
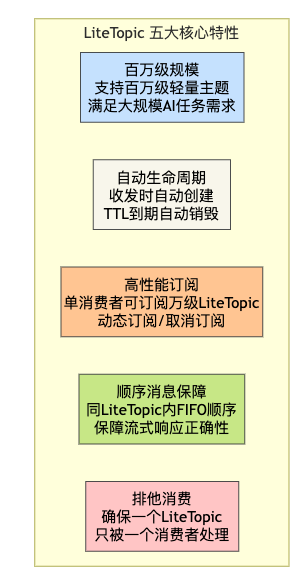
2.2 LiteTopic vs 传统Topic
|
对比维度 |
传统Topic |
LiteTopic |
|---|---|---|
| 创建方式 |
手动创建,配置复杂 |
自动创建,按需生成 |
| 数量上限 |
有限 |
百万级 |
| 生命周期 |
永久存在 |
TTL自动过期删除 |
| 资源开销 |
较高 |
极低 |
| 适用场景 |
固定业务消息 |
AI会话、Agent任务 |
LiteTopic的核心设计理念就是一句话:把每个AI会话、每个Agent任务,都映射成一个独立的轻量Topic。
三、Multi-Agent异步通信实战
我们通过一个完整的Multi-Agent异步通信系统,看看RocketMQ是怎么解决实际问题的。
3.1 系统架构图
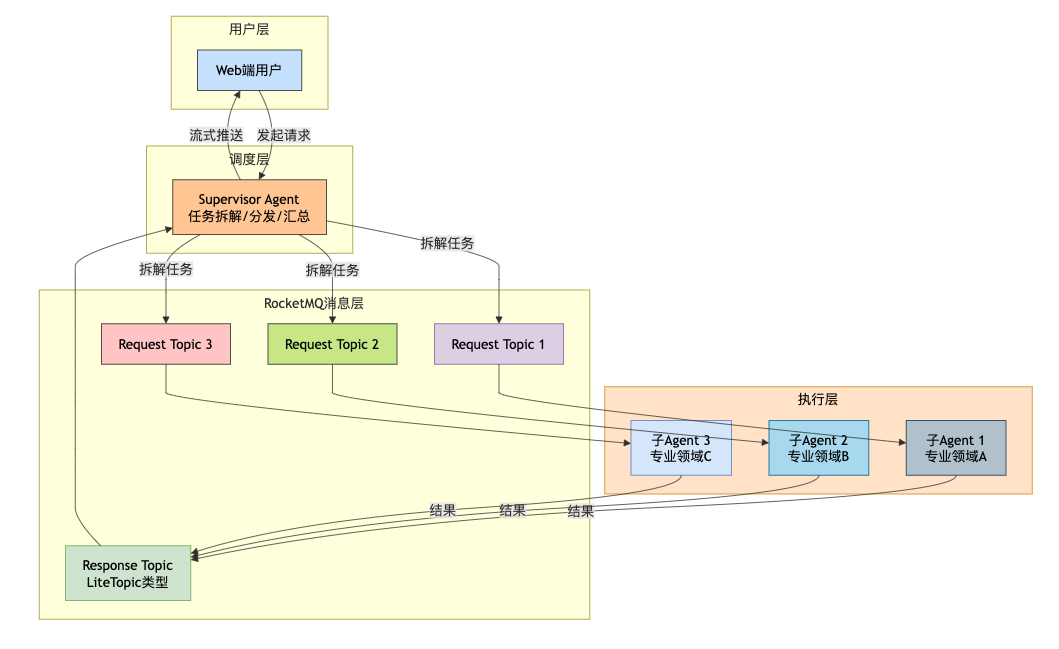
3.2 通信流程详解
整个流程分为请求阶段和响应阶段:
请求阶段:
-
Supervisor Agent收到用户请求后,将复杂任务拆解成多个子任务
-
为每个子任务创建独立的请求消息,发送到对应的Request Topic
-
各个子Agent订阅自己负责的Request Topic,一旦有新消息立即开始处理
响应阶段:
-
Supervisor Agent创建一个Response Topic(LiteTopic类型),并订阅它
-
每个子Agent处理完成后,将结果发送到Response Topic中对应的LiteTopic(用TaskID或SessionID命名)
-
Supervisor Agent实时接收各个子Agent返回的结果,汇总后通过HTTP流式推送给用户
3.3 核心代码示例
下面我们用Java代码演示一下关键环节。
Supervisor Agent - 发送任务到多个子Agent:
@Service
publicclass SupervisorAgent {
@Autowired
private RocketMQTemplate rocketMQTemplate;
public void dispatchTask(String sessionId, List<SubTask> subTasks) {
// 为每个子任务创建独立的LiteTopic
for (SubTask task : subTasks) {
String topicName = "request_" + task.getAgentType() + "_" + sessionId;
// 发送任务消息
Message<String> msg = MessageBuilder
.withPayload(JSON.toJSONString(task))
.setHeader("taskId", task.getId())
.build();
// 发送到对应的Request Topic
rocketMQTemplate.syncSend(topicName, msg);
}
}
}
子Agent - 消费消息并处理任务:
@Component
@RocketMQMessageListener(
topic = "request_agent1_*", // 通配符订阅
consumerGroup = "agent1-group",
selectorExpression = "*"
)
publicclass SubAgent1 implements RocketMQListener<MessageExt> {
@Autowired
private RocketMQTemplate rocketMQTemplate;
@Override
public void onMessage(MessageExt message) {
// 1. 解析任务
String taskJson = new String(message.getBody());
SubTask task = JSON.parseObject(taskJson, SubTask.class);
// 2. 执行业务逻辑(AI推理,可能耗时数秒)
String result = executeAIInference(task);
// 3. 将结果发送到Response LiteTopic
String responseTopic = "response_" + task.getSessionId();
rocketMQTemplate.syncSend(responseTopic, result);
}
}
Supervisor Agent - 汇总子Agent结果:
@Component
@RocketMQMessageListener(
topic = "response_*", // 通配符订阅所有响应
consumerGroup = "supervisor-group"
)
publicclass ResultCollector implements RocketMQListener<String> {
privatefinal Map<String, List<String>> sessionResults = new ConcurrentHashMap<>();
@Override
public void onMessage(String result) {
// 解析SessionID,将结果存入对应的会话中
// 当所有子Agent的结果都返回后,汇总并推送给用户
}
}
关键代码解读:
-
通配符订阅:
"request_agent1_*"和"response_*"利用了LiteTopic的动态特性,一个消费者可以订阅海量的LiteTopic -
LiteTopic自动创建:发送消息时Topic不存在会自动创建,无需预先配置
-
会话隔离:每个SessionID对应独立的LiteTopic,不同会话的消息不会互相干扰
这种架构把长耗时的AI任务调用从同步阻塞变成了异步非阻塞,系统吞吐量大幅提升。
四、分布式会话状态管理
在做AI应用的时候,一定遇到过这个问题:用户用WebSocket或者SSE跟AI对话,网络稍微波动一下,连接断了。用户重新连上之后,之前的对话上下文全丢了,只能从头开始,白白浪费了已经花掉的GPU算力。
RocketMQ的LiteTopic正好可以解决这个问题。
4.1 传统方案的痛点
在传统架构中,会话状态往往绑定在特定的应用服务节点上。一旦用户的长连接断开并重连到另一个节点,新的节点无法获取之前的会话状态,导致对话中断。
而且,AI任务的每一次执行都消耗昂贵的GPU资源。如果因为网络波动导致任务作废,将造成巨大的资源浪费。
4.2 RocketMQ解决方案
核心思路是:把应用服务节点做成无状态的,会话状态全部托管在RocketMQ中。
会话建立流程:
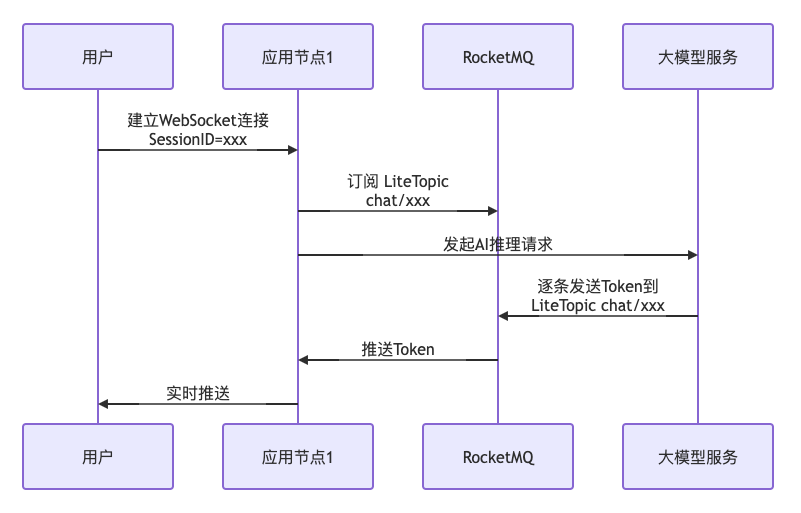
断线重连流程:
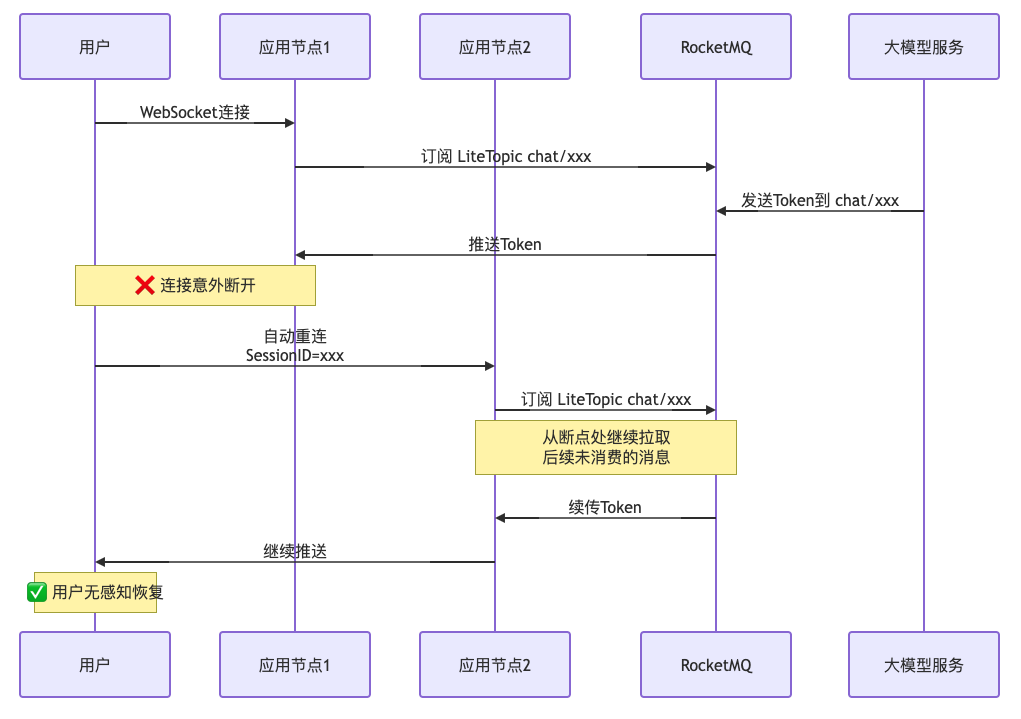
代码示例:
@Service
publicclass SessionManager {
@Autowired
private RocketMQTemplate rocketMQTemplate;
// 创建会话
public void createSession(String sessionId, WebSocketSession wsSession) {
String topic = "chat/" + sessionId;
// 订阅该会话对应的LiteTopic
rocketMQTemplate.getDefaultMQPushConsumer().subscribe(topic, "*");
// 启动一个消费者监听该Topic
// 收到消息后通过WebSocket推送给用户
}
// 发送AI响应到会话
public void sendToken(String sessionId, String token) {
String topic = "chat/" + sessionId;
rocketMQTemplate.syncSend(topic, token);
}
// 断线重连 - 从断点续传
public void resumeSession(String sessionId, WebSocketSession newSession) {
String topic = "chat/" + sessionId;
// 新节点订阅同一个LiteTopic
// RocketMQ会根据消费进度(Offset)从断点处继续拉取
rocketMQTemplate.getDefaultMQPushConsumer().subscribe(topic, "*");
}
}
这套方案的核心优势:
-
会话连续性:无论重连到哪个节点,都能通过同一个LiteTopic无缝续传,用户无感知
-
资源保护:连接中断不会导致后台大模型任务停止,避免算力浪费
-
弹性伸缩:应用服务端完全无状态,可以随意扩缩容
五、智能调度
AI算力是稀缺资源。
如何让有限的GPU发挥最大价值?RocketMQ提供了三个关键能力:
① 流量整形(削峰填谷)
业务请求天然存在波峰波谷。RocketMQ作为前端请求与后端算力服务之间的缓冲层,平滑请求洪峰,避免算力服务被瞬间流量冲垮。
② 消息优先级
当消息堆积时,RocketMQ会按照优先级由高到低的顺序将消息投递给消费者。高价值任务(比如付费用户的请求)优先获得算力资源。
③ 定速消费(消费者限流)
通过控制消费速率,保护后端关键算力资源不被过度消耗。限流力度可以精细到单个LiteTopic级别。
// 示例:通过RocketMQ实现智能调度
@Configuration
publicclass RocketMQConsumerConfig {
@Bean
public DefaultMQPushConsumer defaultConsumer() throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("ai-consumer-group");
// 设置消费限流 - 每秒最多消费10条消息
consumer.setConsumeMessageBatchMaxSize(10);
consumer.setPullInterval(100); // 100ms拉取一次
// 订阅所有AI推理请求
consumer.subscribe("ai-inference-*", "*");
// 注册消息监听器
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
// 处理AI推理任务
handleAIInference(msg);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
return consumer;
}
}
六、一张图看懂RocketMQ for AI全景
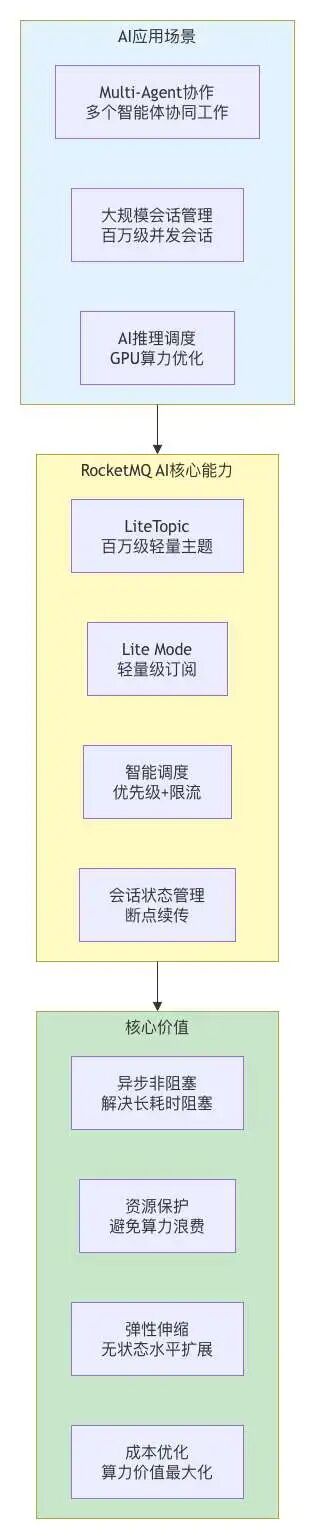
七、优缺点
优点
1. 专为AI场景设计的LiteTopic百万级轻量主题,自动创建和销毁,每个AI会话可以映射为独立Topic。这是RocketMQ for AI最核心的竞争力。
2. 解决AI长耗时阻塞问题将同步调用转为异步非阻塞,系统吞吐量大幅提升。
3. 分布式会话状态管理通过LiteTopic实现会话状态外置,应用节点无状态化,断线可续传。
4. 智能算力调度流量整形、消息优先级、定速消费三重机制,让GPU算力用在刀刃上。
5. 生态完善原生支持MCP(Model Context Protocol)和A2A(Agent-to-Agent)协议,与LangChain、CrewAI、AutoGen、Dify等主流AI框架无缝集成。
6. 万亿级消息规模验证在阿里内部经过万亿级消息规模的实战检验。
缺点
1. LiteTopic目前主要在云上版本虽然会逐步贡献到Apache RocketMQ开源社区,但目前完整的AI能力在开源版本中还在逐步落地中。
2. 学习曲线LiteTopic、Lite Mode等新概念需要一定学习成本。
3. 需要重新设计架构从同步调用改为异步消息驱动,需要对现有系统架构进行调整。
八、适用场景
|
场景 |
推荐程度 |
理由 |
|---|---|---|
| Multi-Agent协作系统 |
✅✅✅ 强烈推荐 |
LiteTopic天然适配Agent间异步通信 |
| AI流式对话/流式响应 |
✅✅✅ 强烈推荐 |
LiteTopic顺序保障 + 断点续传 |
| 大规模AI会话管理 |
✅✅✅ 强烈推荐 |
百万级LiteTopic支撑海量会话 |
| AI推理任务调度 |
✅✅ 推荐 |
优先级+限流,优化算力利用 |
| 传统微服务异步解耦 |
✅✅ 推荐 |
RocketMQ原有能力依然强大 |
| 极低延迟场景(<10ms) |
⚠️ 一般 |
消息队列本身有网络开销 |
九、写在最后
回到最初的问题:RocketMQ接入AI,到底接了什么?
RocketMQ没有变成一个大模型,也没有变成一个AI推理引擎。它做的是把自己变成AI应用最可靠的消息底座。
-
LiteTopic让每个AI会话都有了独立的“消息通道”
-
异步通信让Multi-Agent协作不再被长耗时阻塞
-
会话状态管理让断线重连不再丢失上下文
-
智能调度让每一分GPU算力都用在刀刃上
在AI应用从“单机玩具”走向“企业级系统”的今天,RocketMQ正在成为那个连接AI Agent、调度AI任务、管理AI会话的关键基础设施。
如果你正在构建AI应用,尤其是Multi-Agent系统,建议认真评估RocketMQ 5.5.0的LiteTopic能力。
它可能正是你解决“AI长耗时阻塞”和“大规模会话管理”这两个核心痛点的答案。
开源地址与官方资源:
-
Apache RocketMQ官网:https://rocketmq.apache.org/
-
RocketMQ GitHub:https://github.com/apache/rocketmq
-
RocketMQ 5.5.0 Release Notes:https://rocketmq.apache.org/zh/docs/
-
Multi-Agent示例源码:https://github.com/apache/rocketmq-a2a/tree/main/example/rocketmq-multiagent-base-adk

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)