
企业私有知识库搭建:从爬虫清洗到 RAG 入库全流程
在企业 AI Agent 落地过程中,私有知识库是决定成败的地基工程。再强大的大模型,如果缺少高质量的企业专属知识输入,也只能输出泛泛而谈的内容,无法真正解决业务痛点。
我见过太多项目,花几十万甚至几百万在优化 Prompt、切换更贵的大模型上,却在知识库建设上投入严重不足,最后上线后 AI 回答全是幻觉,业务部门根本不用,项目直接宣告失败。
本文分享我为不同行业(制造、有色、传统零售)企业落地私有知识库后的系统性总结,句句来自真实项目中的经验与教训。
一、核心理念:知识库是企业的「第二大脑」
私有知识库绝不是简单把文档丢进向量库,而是要构建企业专属的知识中枢系统。它必须同时满足以下五点,缺一不可:
- 真实性与权威性:知识必须100%来自企业内部官方数据,绝不能混入外部错误信息。
- 时效性与动态性:企业制度、产品、流程更新频繁,知识库必须能快速感知并增量更新。
- 可控性与安全性:企业要完全掌控“哪些知识可被检索”“谁能检索”“结果如何排序”。
- 语义完整性:切分后的知识块既要小(便于精确匹配),又要保留足够上下文。
- 持续进化:知识库不是一次性项目,上线只是开始,后续必须持续优化。
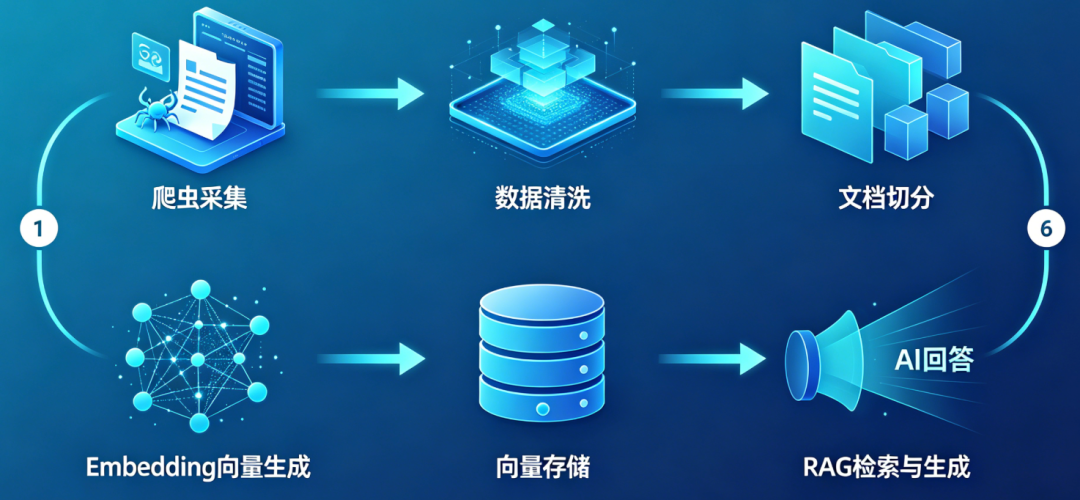
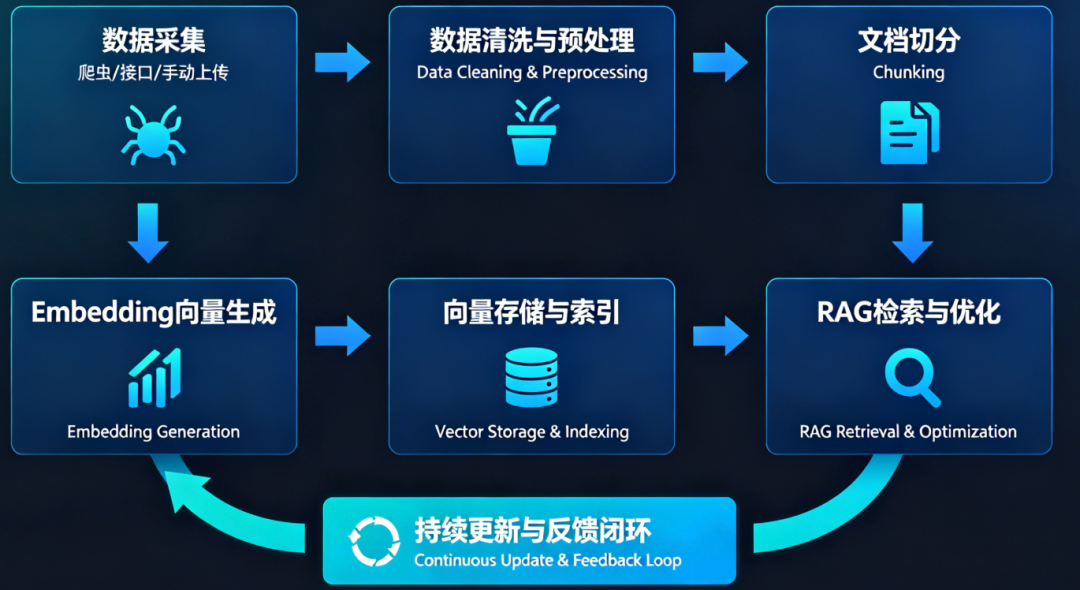
二、整体流程:从爬虫到 RAG 的6阶段闭环
企业私有知识库搭建是一个完整的闭环工程,我将其总结为6个核心阶段:
-
爬虫采集与多源接入: 通过爬虫和API采集企业内部高价值数据,为知识库提供原料。
-
数据清洗与预处理: 去除噪声、去重、脱敏、完善元数据,保证数据质量。
-
文档切分(Chunking): 将文档切分成语义完整的知识块,平衡精度与上下文。
-
Embedding 向量生成: 将文本转为向量表示,为后续语义检索提供基础。
-
向量存储与索引: 选择合适向量数据库,建立高效索引和元数据管理。
-
RAG 检索与持续优化: 通过多阶段检索和用户反馈,持续提升答案质量。
核心认知:前置环节决定上限,后置环节决定下限。
爬虫采集和数据清洗两个阶段,共同决定了整个知识库的质量天花板。
在我做的项目中,凡是这两个环节投入占比超过50%的,最终 RAG 效果都远好于把预算砸在大模型上的。
三、各阶段核心实操理念
- 爬虫采集与多源接入:精准而非贪多
===================
核心理念:先做减法,再做加法。
不是爬得越多越好,而是精准采集高价值数据。
企业知识60%以上存在于内部网页化系统中(Confluence、语雀、飞书 OA、Jira 等),这部分必须通过爬虫解决。
企业级爬虫的核心是内部系统数据连接器。
推荐四级采集体系(按优先级):
💡 实操建议:
- 第一期建议控制在3000-8000份核心文档,聚焦客服、产品、流程等高频领域。
- 建立数据源地图和责任人机制,每个重要系统都要明确知识维护负责人。
- 公网数据只作为极少量补充,且必须满足“内部严重缺失 + 公开商用 + 标注来源”三个条件。
- 数据清洗与预处理:决定知识库下限
===================
核心理念:垃圾进,垃圾出。
80%的 RAG 效果差,根源都在清洗环节做得不够彻底。
必须重点解决的问题:
- 噪声去除(页眉页脚、导航、广告、乱码)
- 版本去重(只保留最新有效版本)
- 敏感信息识别与脱敏
- 元数据完善(标题、时间、部门、版本、权限等级)
💡 生产经验:
这个阶段至少要投入40%的精力。重要知识建议人工抽检,不合格就调整规则,宁愿进度慢一点,也绝不放低质量标准。
- 文档切分(Chunking):最考验功力的环节
==========================
核心理念:切分的本质是保证语义完整性,而不是机械按字数分割。
固定长度切分是最大杀手,它会把完整流程、条款、步骤拆得七零八落,导致大模型拿到“断章取义”的碎片。
推荐方法论(优先级从高到低):
- 第一层:利用文档天然结构(标题层级、段落、列表、表格)
- 第二层:按语义边界切分(句号、转折词、因果词等)
- 第三层:按文档类型定制规则(制度、流程、FAQ、合同等)
- 第四层:多粒度混合切分(小块检索 + 大块生成)
💡 实操原则:宁长勿短,宁可知识块稍大,也绝不破坏语义完整性。
- Embedding 与向量存储
==================
核心理念:向量是目前最好的语义表示方式,但不是万能的。
- Embedding 模型:中文场景优先考虑 bge-m3 或通义 Embedding 系列
- 向量存储:中小型企业首选 PGVector,中大型企业推荐商用向量服务
💡 关键提醒:元数据(部门、版本、时间、权限)往往比向量本身更重要
- RAG 检索优化:多阶段迭代
=================
核心理念:检索不是一次完成,而是多阶段优化过程。
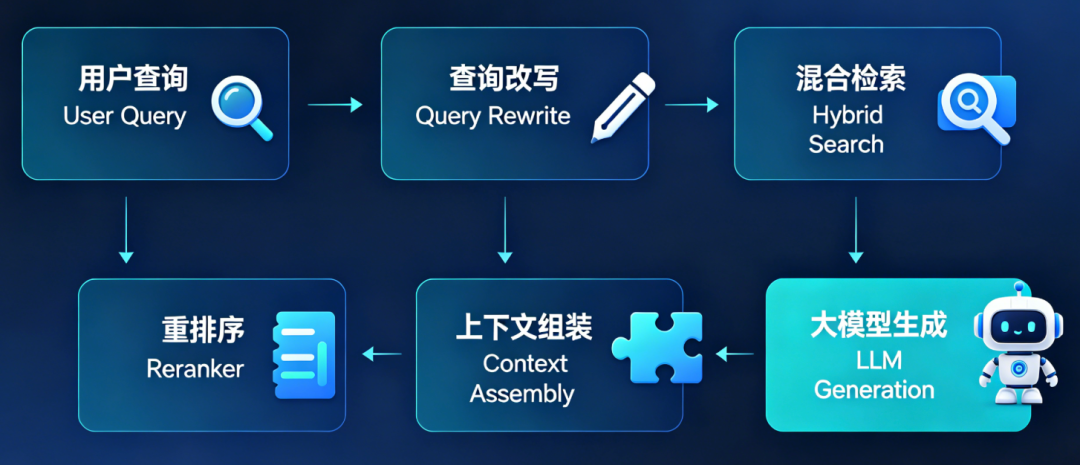
- 基础向量检索:通过向量相似度匹配最相关的知识块,作为检索基础。
- Query Rewrite(查询改写):对用户原始问题进行改写,提升与知识库的匹配度。
- Hybrid Search(混合检索):结合向量搜索与全文关键词检索,提高整体召回率。
- 重排序模型(Reranker):对初步检索结果重新排序,选出最相关的前几位。
- Context 智能组装:按相关性、时效性、权威性对检索内容进行排序和组装。
- 用户反馈闭环:收集点赞/点踩数据,持续优化检索策略和知识库内容。
四、生产级知识库的运营理念
技术做好只是开始,运营才是决定成败的关键:
- 增量更新机制:建立变更检测系统,实现“文档修改 → 自动更新知识库”。
- 质量闭环:定期评估召回率、相关性、用户满意度,并持续迭代。
- 权限分级:实现知识的部门/角色可见性控制。
- 版本管理:支持知识回滚,应对错误信息入库的情况。
- 多模态演进:未来逐步支持图片、表格、流程图等非文本知识。
五、总结
企业私有知识库建设没有捷径,核心在于理念正确 + 持续迭代。它不是一个单纯的技术项目,而是一个技术驱动 + 业务参与 + 运营保障的系统工程。
只有把知识库真正建设好,后续的智能客服、DeepResearch、DataAgent 等 AI 应用才能发挥出最大价值。建议从核心业务领域开始,追求小而精,跑通闭环后再逐步扩大规模。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 2
2 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)