
百度面试官问:Claude Code 的 Skills 越加越多,为什么不能全塞进上下文?
agent 会的本事越多,全写进系统提示就越贵越乱。这课拆 Claude Code 的技能与命令机制——核心就一个词:按需加载(渐进式披露)。
先把术语翻成人话
渐进式披露 progressive disclosure :先只摆出能力名片,用到才加载完整内容
Skill 技能 :一组按需加载的领域知识或流程
斜杠命令 slash command :用户主动触发的 prompt 模板或动作
能力名片 :技能的名字 + 一句话用途,常驻上下文
一、面试现场
面试官提问
“Claude Code 的 Skills 越加越多,为什么不能全塞进上下文?”
百度 Agent 应用面,题就摆在上面。候选人想都没想:「全塞进去不就行了?把每个技能写清楚,模型自己会挑着用。」
面试官追一句:这 50 个里这次只用 1 个,另外 49 个不就白占地方?——这题看似问扩展,实考你能不能区分「知道有这个能力」和「加载这个能力的细节」:前者廉价、可以常驻;后者昂贵、用到才加载。全塞进上下文,既吃爆预算(第 4 课)又稀释注意力。
**直接回答:**能力名片常驻、细节按需加载,用到哪个才读进来。

二、大多数人怎么答的
典型翻车回答
“把所有技能、所有规则都写进系统提示/CLAUDE.md,写得越全 agent 越能干。”
这答法在能力少时其实没错——三五个技能写进 CLAUDE.md,写得越全确实越顺手。问题是它不扩展:上下文是有限预算(第 4 课),能力堆到几十个,没用上的那些每一轮都在白烧 token、还分散模型对当前任务的注意力。
更别说能力一多,规则之间还会互相打架(第 8 课讲过 advisory 的死穴)。我认为扩展只有一条路:按需加载,而不是全摊开。具体怎么做,下一节拆。
三、渐进式披露怎么让能力扩到几十个还不爆
Skills 的核心机制是渐进式披露。把它拆开,关键是「名片常驻、正文按需」这一层解耦,以及工具、Skill、命令三个概念别混。
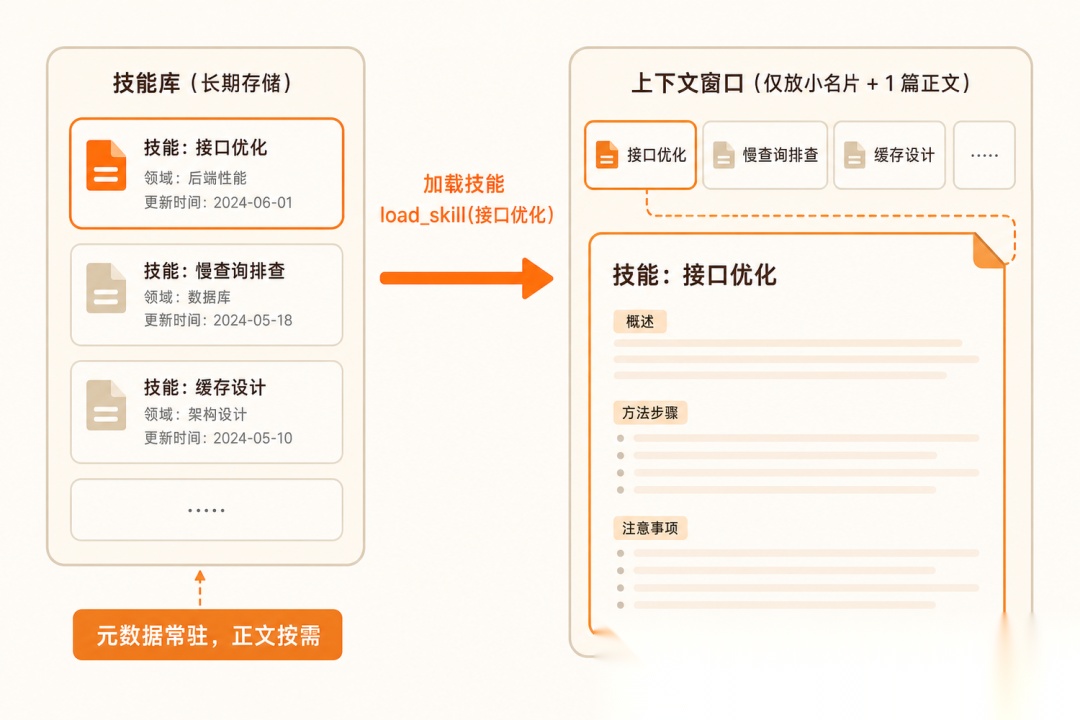
① 解耦:知道有它 vs 加载它的细节
上下文里只常驻每个能力的名片(名字 + 一句话用途),体积极小。模型判断需要时,再通过一次加载把该能力的完整说明/脚本读进来。等于给 agent 一个可检索的能力库,而不是一本全摊开的大书。关键在于:常驻的是名片,按需取的才是正文。
**违反后果:**把每个能力的完整正文都常驻,每加一个能力上下文就胖一圈,50 个全摊开迟早把窗口挤爆。
② 工具、Skill、命令:三个概念别混
三者分工(截至 2026-06):工具是 agent 的原子动作(第 3 课,schema 化、可被反复精确调用);Skill 是一组按需加载的领域知识/流程(渐进式披露);斜杠命令是用户主动触发的 prompt 模板/动作快捷入口。Skill 偏「模型按需取知识」,命令偏「用户主动触发流程」。
**违反后果:**把领域知识硬做成几十个工具挂上去,工具列表本身就把上下文撑爆了——大段流程知识该做成按需加载的 Skill,不是常驻工具。
③ 名片质量决定该触发的触发不触发
解耦解决了「装得下」,但能不能选得中,全看名片描述的质量——这是技能库的可发现性。模型只凭名片决定加载谁:名片写不清,它要么漏掉该用的、要么抓错不相关的。名片具体怎么写、几十个怎么治,是下面追问环节的重头。
**违反后果:**名片含糊,该用的技能没加载、模型硬着头皮瞎答;名片互相重叠,又会拉一堆不相关的进来,白烧一轮。
**我的优先顺序:**先把「名片常驻、正文按需」这层解耦立住(决定能不能扩展),再打磨名片的触发描述(决定该触发的能不能触发)。能力少(三五个)时,直接写进系统提示更简单——别为了渐进式披露而渐进式披露。
四、面试官追问链
追问 1
“技能的名片该写多细?太短选不中,太长又占地,怎么平衡?”
名片只写两样:名字 + 什么场景下该用我,正文留到加载时。判断标准是「模型读完这张名片,能不能准确判断这次任务归不归它管」。选不中,几乎都是触发场景没写清(写成了「这是个很强的工具」而不是「当用户要做 X 时用我」)。名片是路标,不是说明书。
追问 2
“Skill 和工具到底怎么分?什么时候做成工具、什么时候做成 Skill?”
看「原子动作」还是「一套流程/知识」。可被反复精确调用的原子动作(读文件、查数据库)做成工具,schema 紧、结果结构化;一整套领域流程或大段知识(怎么走发布流程、某框架的最佳实践)做成 Skill 按需加载。我认为一个信号是:如果你想把一大段说明塞进工具的 description,它其实该是个 Skill。
追问 3
“加了 30 个 Skill,模型老加载错,怎么治?”
治名片的可发现性:描述去重、触发条件互斥(别让两个技能的「该用我」场景重叠)、必要时分层分目录让范围更窄。这和第 3 课「工具职责重叠模型乱选」是同一个病——选错的根因几乎都是边界没划清。技能库越大,越要像整理目录一样维护这些名片。
五、给你的 agent 加按需加载的技能
把上面的机制落到自己的 agent 上,最小实现就四步。
STEP 1 · 把能力抽成带名片的包
每个能力 = 一张名片(名字 + 触发场景)+ 一份完整正文/脚本,分开存。
↳ 关键:名片小、正文全,两者解耦。
STEP 2 · 名片常驻上下文
只把所有能力的名片列表放进系统提示,正文不进。
↳ 关键:常驻的是目录,不是正文。
STEP 3 · 提供 load 动作
给模型一个加载动作(或工具),它判断需要时按名字把对应正文读进窗口。
↳ 关键:要用才取,取来就留在当前上下文里。
STEP 4 · 触发条件写清、互斥
每张名片写明什么时候用我、和别的技能怎么区分,防选错。
↳ 关键:选不中几乎都是触发描述没写清。
**↳ 一句话验收:**判断扩展机制对不对,问一句——**给 agent 加到第 50 个能力时,上下文有没有跟着涨 50 倍?**没有(只多 50 张名片),就对了;跟着涨,说明你在「全摊开」,迟早撑爆。
六、本课总结
一句话总结
agent 的能力不能全塞进上下文——那既吃爆预算又稀释注意力。正解是渐进式披露:能力名片常驻、完整正文按需加载;工具是原子动作、Skill 是按需知识、命令是用户触发,三者别混。
面试锦囊
**先说:**先立原则:上下文是有限预算,能力全摊开又贵又分散注意力。扩展靠按需加载,把「知道有它」和「加载它的细节」解耦。
**再说:**渐进式披露:名片(名字+触发场景)常驻、正文按需加载。工具=原子动作、Skill=按需知识/流程、命令=用户触发,三个概念分清。
**最后补:**关键在于:名片质量决定该触发的触发不触发;技能多了要像整理目录一样治理(描述去重、触发互斥);能力很少时直接写进系统提示更简单。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 2
2 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)