
我在一线大厂做了一些 Skills,观察到的 12 个 Skills 误区
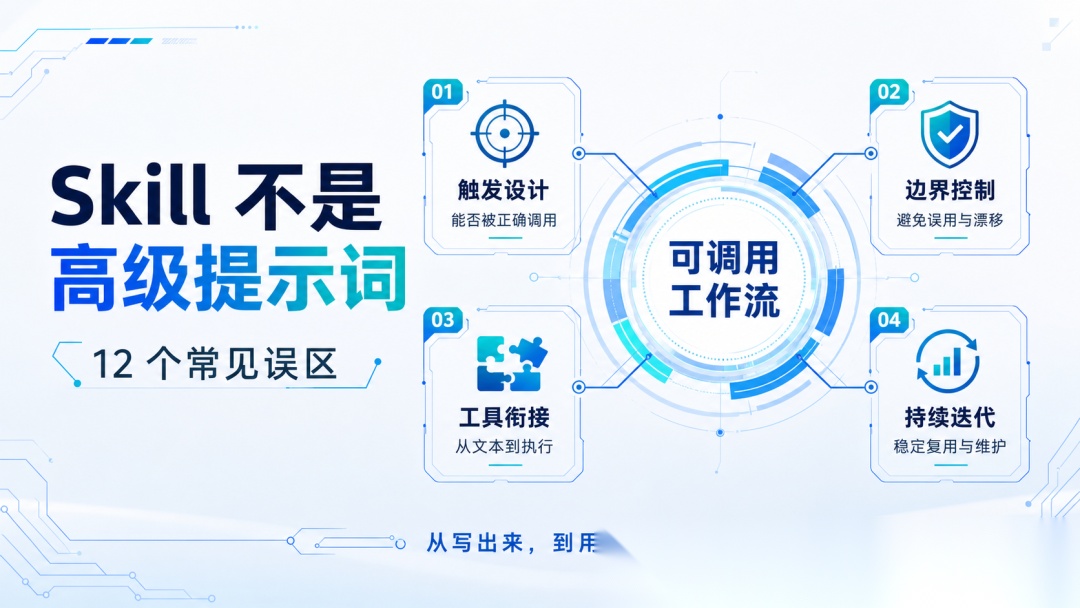
很多人第一次接触 Skills,容易把它理解成“高级提示词”:写几句规则,塞一点经验,模型就会稳定执行。
但真正做起来会发现,Skill 更像一套可调用的工作流。它不只考验会不会写 Markdown,更考验触发设计、边界控制、工具衔接和后续维护。
我自己在一线大厂做了一些 Skills 后,感受很深:很多坑不在“能不能写出来”,而在“能不能被正确调用、稳定复用、持续迭代”。
这篇文章整理了 12 个常见误区,希望对大家有帮助。
误区 1:Skills 很简单,随便找个员工搞一下就行?
很多人认为 Skill 很简单,张张嘴就能创建出来,所以觉得交给一个熟悉业务的同事顺手写一下就行。
但真正要做出稳定可用的 Skill,门槛并不低。
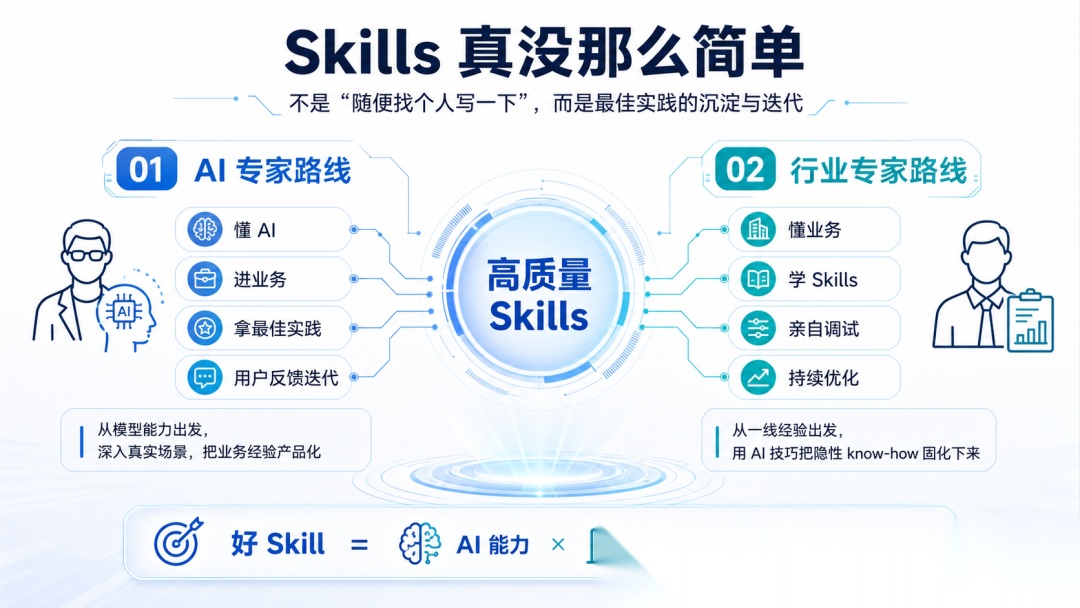
根据我在一线大厂的实践和观察,我觉得高质量 Skills 通常有两种来源。
一种是由一个特别懂 AI 的人,深入了解业务,拿到真实场景里的“最佳实践”,再根据用户反馈持续优化出来。
另一种是由一个特别懂业务的行业专家,学会一些 Skills 技巧之后,一边使用一边调试出来。
误区 2:Skills 装得越多越好

很多人看到视频或公众号里推荐一堆“好用的” Skills,会忍不住马上装上。
结果发现,很多 Skills 和自己的实际工作场景关联度很差。
有些 Skill 明明不想调用,它却被触发了,效果反而更差。
有时候想调用一个 Skill,又发现怎么都匹配不上。
如果 Skills 装得太多,它们的元信息也会被加载到上下文里,造成不必要的 Tokens 消耗。
所以不要只看这个 Skill 下载量高不高,或者是不是被哪位大咖推荐;更要看它和你的场景是否高度相关,是否真的需要安装。
“小而美、少而精”,通常是更稳的选择。
Skills 的进阶之路,有时候就是“先做加法,再做减法”的过程。
误区 3:description 不重要,随便写写就行
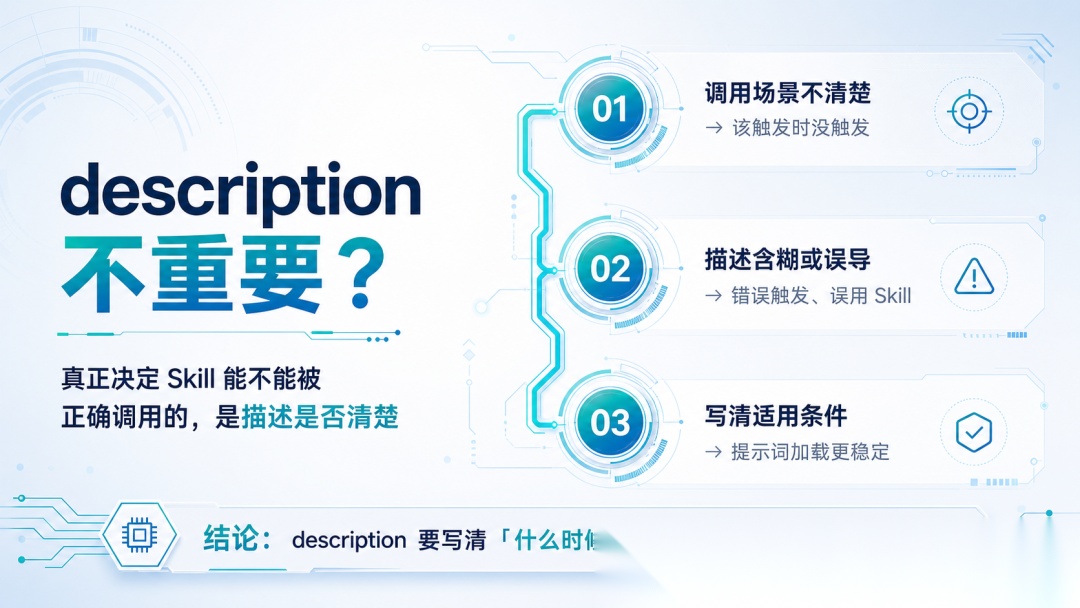
现在很多人用自然语言写 Skills,description 往往也写得很随意,只说“这是一个什么工具”,没有说清楚“什么情况下该调用”。
描述不清楚,就很容易出现两类问题:该调用的时候没调用,不该调用的时候被误触发。
如果 description 里还有错误或误导,问题会更明显。
所以 description 不是装饰,它决定了模型第一步能不能选对入口。
误区 4:用 Skills 就更省 Tokens

很多人想当然地认为,“用 Skills 更省 Tokens”。这句话只说对了一半。
Skill 的优势在于渐进式加载,但如果装得太多,启动时也会把很多用不到的 Skills 元信息带进上下文。
模型具备很强的世界知识,有些功能可能并不需要用到 Skills,说一句话就能处理得很好。
但有些人会把大模型本来就知道的内容,也塞进 SKILL.md 或参考文档里,反而造成不必要的 Token 消耗。
还有一种常见误区:为了省 Tokens,就把 Skills 写得特别短。
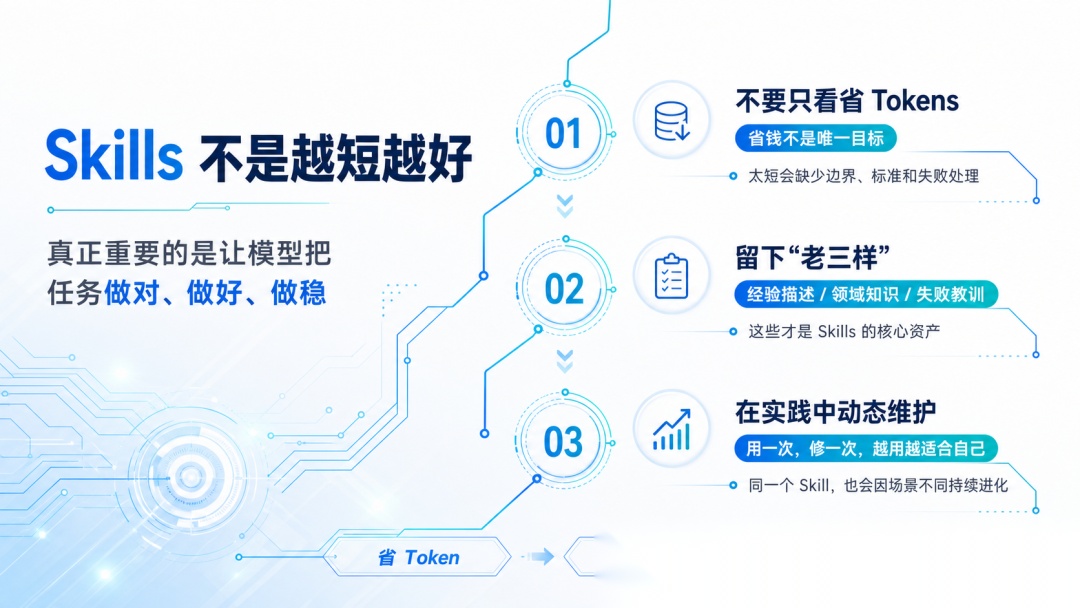
很多人只盯着怎么省钱,却忽视了写 Skills 的真正目的:更好地完成任务,拿到更稳定的结果。
太短可能缺少执行边界、完成标准和失败处理,导致模型“看懂了但做歪了”。
正如腾讯研究院《AI 原生工作报告》中提到的:Skills 该合并的合并,该清理的清理。最终留下“老三样”:
- 经验描述
- 不可替代的领域知识
- 从失败中学到的教训
内容应该在实践中动态维护。每个人的场景都不一样,即使下载的是同一个 Skill,也需要在使用过程中不断精进,最终长成更适合自己的版本。
误区 5:知识都应该放在 Skill 中
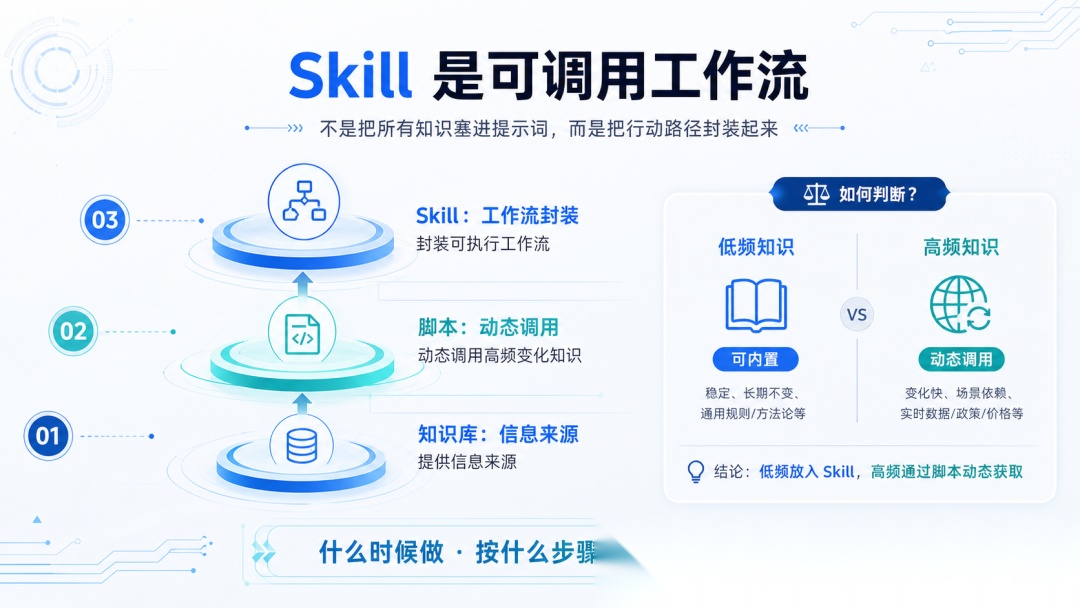
变化不频繁的知识,确实可以用 Skills 承载。
频繁变化的知识,不建议直接写死在 SKILL.md 里,更适合通过脚本动态调用。
所以我更建议把 Skill 当成流程封装:什么时候做、按什么步骤做、做到什么程度。知识库只是完成任务时调用的信息来源。
误区 6:Skill 只是一个 Markdown 文件
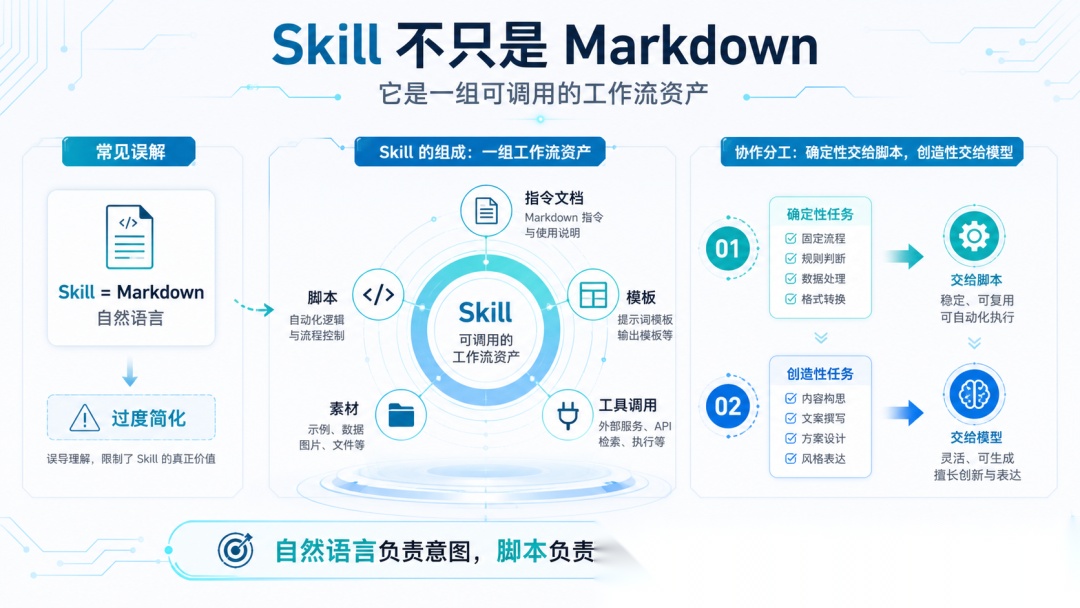
很多人说“Skills 就是 Markdown 格式的自然语言”,这个说法容易误导新手。
Skill 可以带脚本、模板、素材,不只是 Markdown。
好 Skill 不一定全靠自然语言,可以把确定性部分交给脚本,把创造性部分交给模型。
误区 7:Skill 拆得太粗或太细
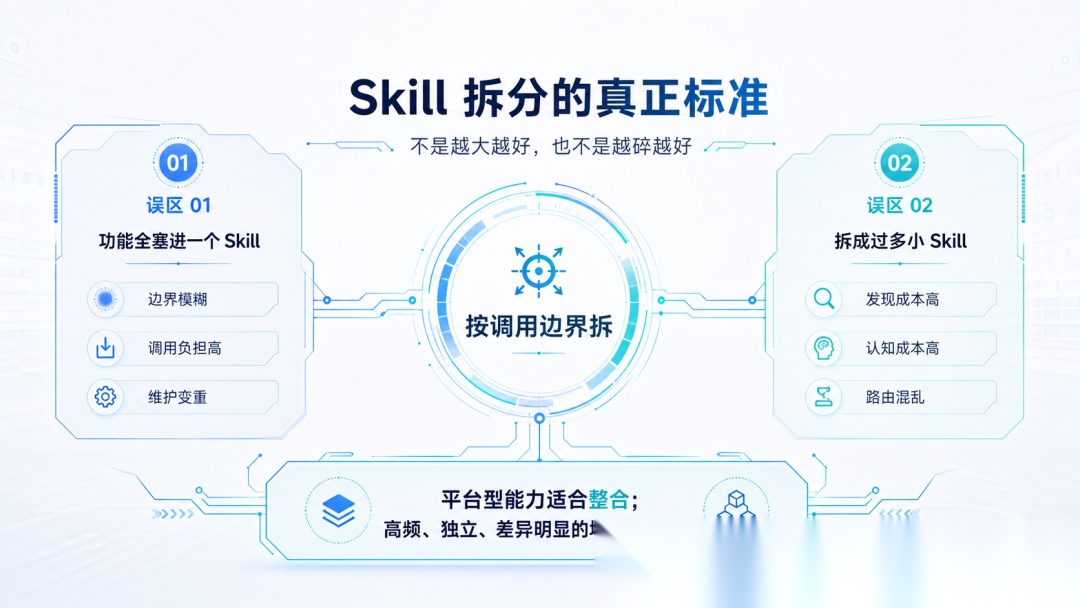
我看到很多人做 Skills 时,容易走向两个极端:
- 把很多功能都塞到同一个 Skill 里
- 把一个功能拆成特别琐碎的小 Skill
通常来说,平台型 Skill 更适合整合到一起,拆太碎会增加发现成本、认知成本,也容易造成路由混乱。
但如果一个功能本身存在多个高频、独立、差异明显的调用场景,就应该拆得更细一点,让每个 Skill 的触发边界更清楚。
关键是按调用边界拆,别只盯着文件大小。
误区 8:Skills 自己能打通各种平台
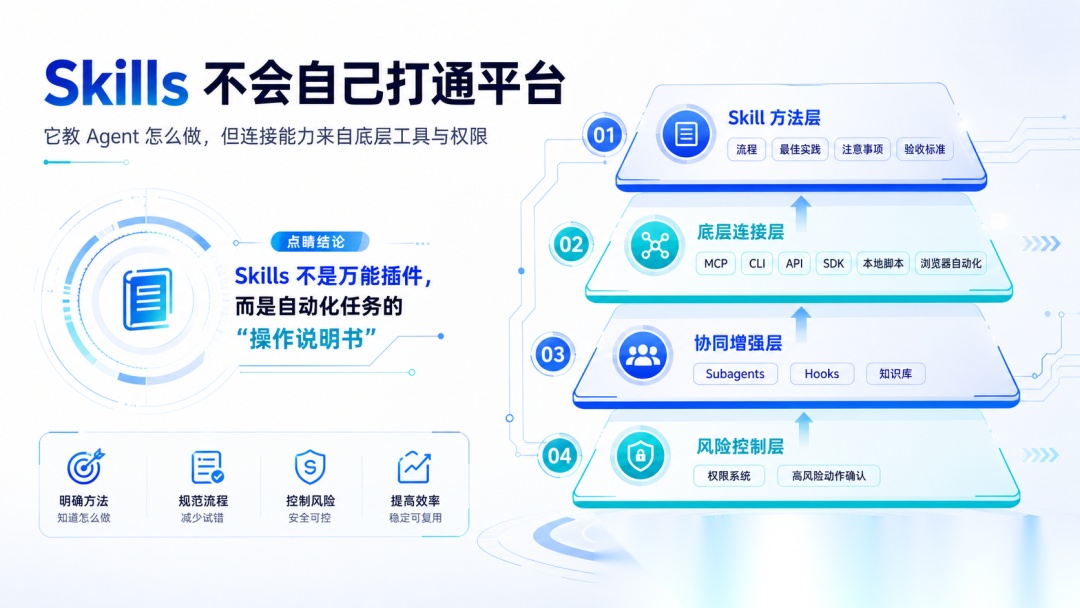
很多人以为装了 Skill,就等于自动打通了各种平台。
其实没有这么简单。
Skill 通常负责封装标准流程、最佳实践、注意事项和验收标准。它告诉 Agent:什么时候用、先做什么、用哪个工具、失败后怎么处理。
真正连接外部系统,通常还是要靠 MCP、CLI、API、SDK、本地脚本或浏览器自动化。
比如你想让 Agent 操作 Notion、Sentry、GitHub、飞书、数据库,Skill 可以教它“怎么完成这类任务”,但前提是底层已经有可用的连接方式和权限。
所以 Skills 不能替代底层连接能力。复杂自动化长任务,往往还要配合 Subagents 做上下文隔离,配合 Hooks 做事件触发,配合知识库提供背景信息,配合权限系统控制高风险动作。
误区 9:Skill 声明了工具范围就一定不会万无一失
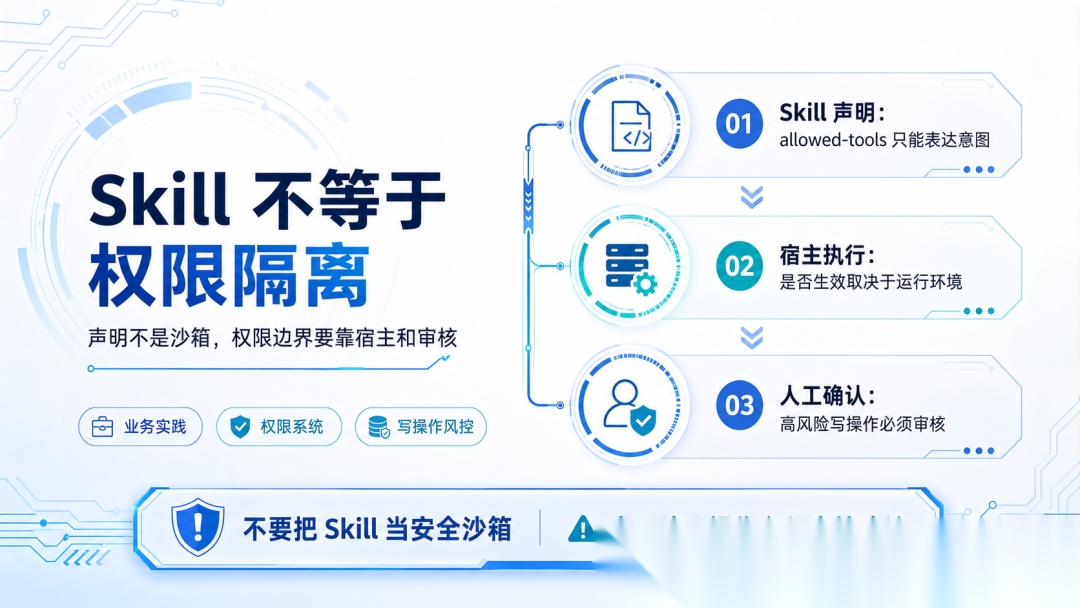
即使 Skill 写了 allowed-tools 或类似字段,也要看宿主是否执行。
不要把 Skill 当安全沙箱。真正高风险的操作,仍然要靠权限系统和人工确认。
尤其是在业务实践中,写操作要格外慎重。可以不让 AI 执行;如果确实需要执行,也必须加上人工审核和确认。
误区 10:同一个 Skill,在不同 Agent 里的调用规则都一样
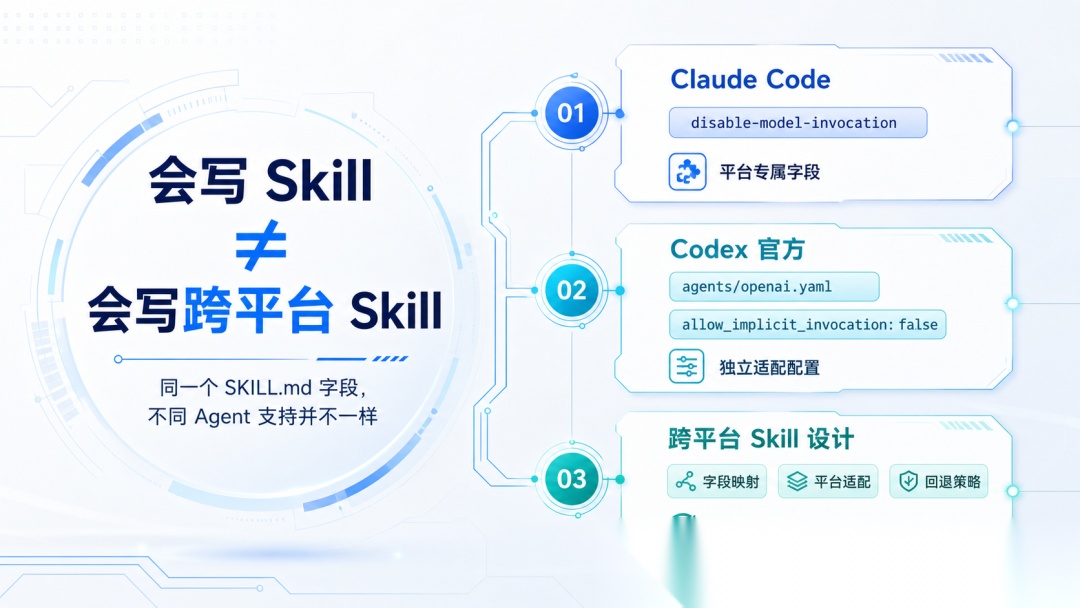
“会写 Skill”和“会写跨平台 Skill”是两件事。Claude Code 和 Codex 支持的自动调用配置项并不一样。
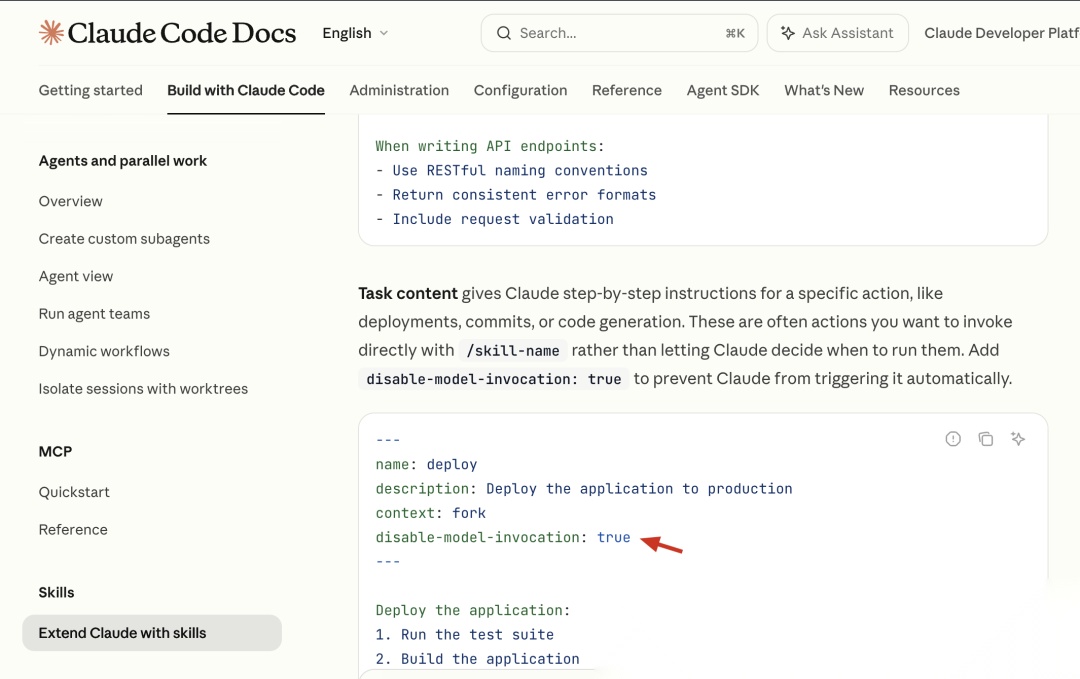
比如 Claude Code 认 disable-model-invocation。
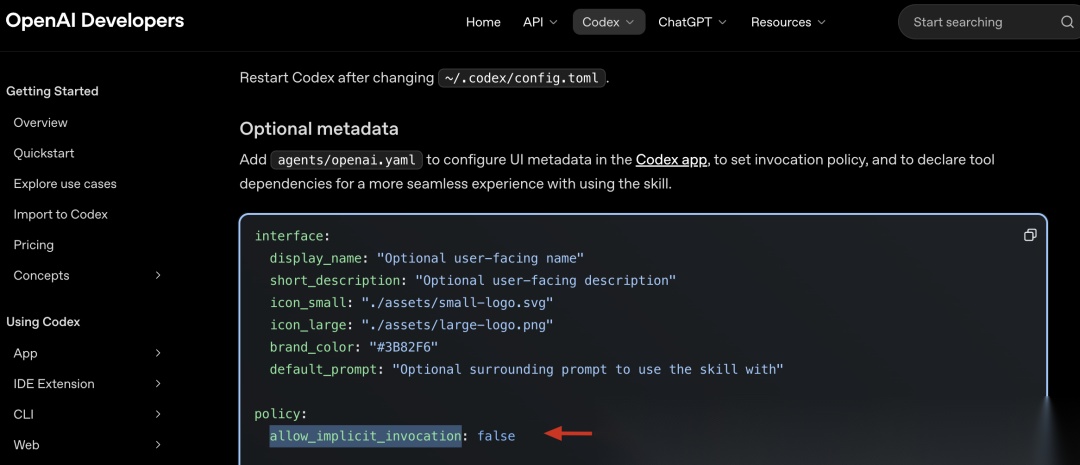
Codex 官方对应的是 agents/openai.yaml 里的 allow_implicit_invocation: false。
所以设计 Skill 时,不能只写一个 SKILL.md 就完事,还要想清楚它应该怎么被调用。
有些 Skill 就应该只让人手动触发,比如部署、发帖、提交、删除、迁移数据。
有些 Skill 适合让模型自动调用,比如 debug、TDD、代码审查。
设计 Skill 时,要想清楚:哪些必须手动触发,哪些可以让模型自动调用。
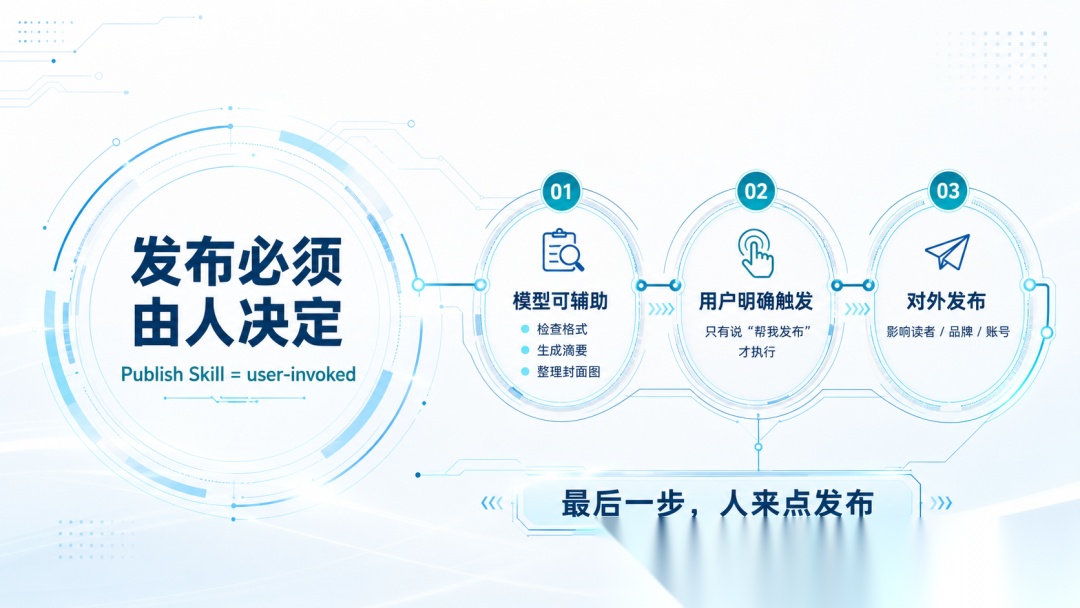
比如有一个「发布公众号文章」Skill,它会把草稿转成公众号格式、上传配图、插入二维码,最后发布到公众号。
这个 Skill 不适合让模型自动调用。
因为“发布”是一个对外动作,一旦发出去,就会影响读者、品牌和账号。模型可以帮我检查格式、生成摘要、整理封面图,但最后是否发布,应该由人来决定。
所以这个 Skill 应该设计成 user-invoked:只有用户明确说“帮我发布这篇文章”时,模型才可以执行。
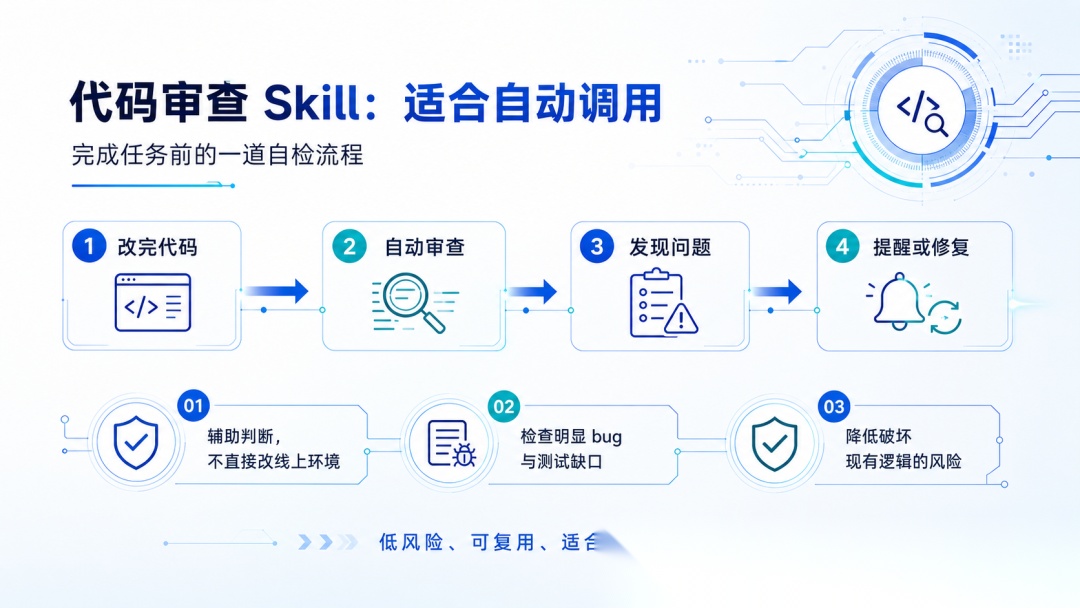
再比如有一个「代码审查」Skill,它会在我改完代码后,自动检查有没有明显 bug、测试是否缺失、有没有破坏现有逻辑。
这个 Skill 很适合让模型自动调用。
因为代码审查本质上是辅助判断,不会直接改线上环境,也不会对外发布内容。它更像是模型在完成任务前的一道自检流程:发现问题就提醒我,或者继续修复。
误区 11:Skill 的中不考虑验收标准
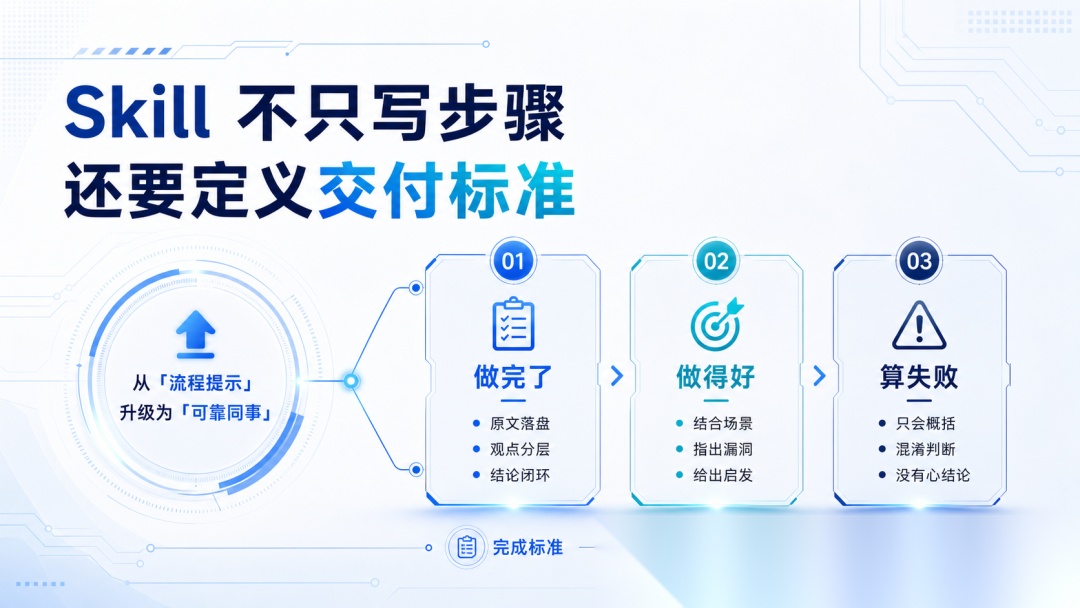
很多 Skill 写得像 SOP:第一步做什么,第二步做什么,第三步做什么。
这当然有用,但还不够。
真正让 Skill 稳定变强的,是你告诉模型:什么叫“做完了”,什么叫“做得好”,什么情况算失败。
比如一个文章解读 Skill,如果只写“总结文章观点”,发挥就不稳定。
但如果写清楚:
- 必须抓取原文并落盘
- 必须区分作者观点和模型判断
- 必须结合我的岗位特点和研究方向(具体省略)给出特定的启发
- 必须指出文章可能存在的漏洞或错误
- 最后要给核心结论
模型才会更像一个靠谱同事,而不是每次都靠临场发挥。
所以写 Skill 时,除了写“怎么做”,还要写“做到什么程度才算交付”。
误区 12:Skill “试一次好用”就算成功

某个 Skill 看起来好用,可能只是因为刚好在某个任务里跑通了。
一个 Skill 真正有没有价值,应该做 with-skill / without-skill 对比。同一个任务,有 Skill 跑一次,没有 Skill 跑一次,看输出质量、耗时、Token 消耗和稳定性。
更进一步,还可以准备几组真实用户问题,检查它该触发时有没有触发,不该触发时有没有误触发。
所以 Skill 写完还不算结束,它也应该有 eval、有断言、有迭代记录。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 0
0 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)