
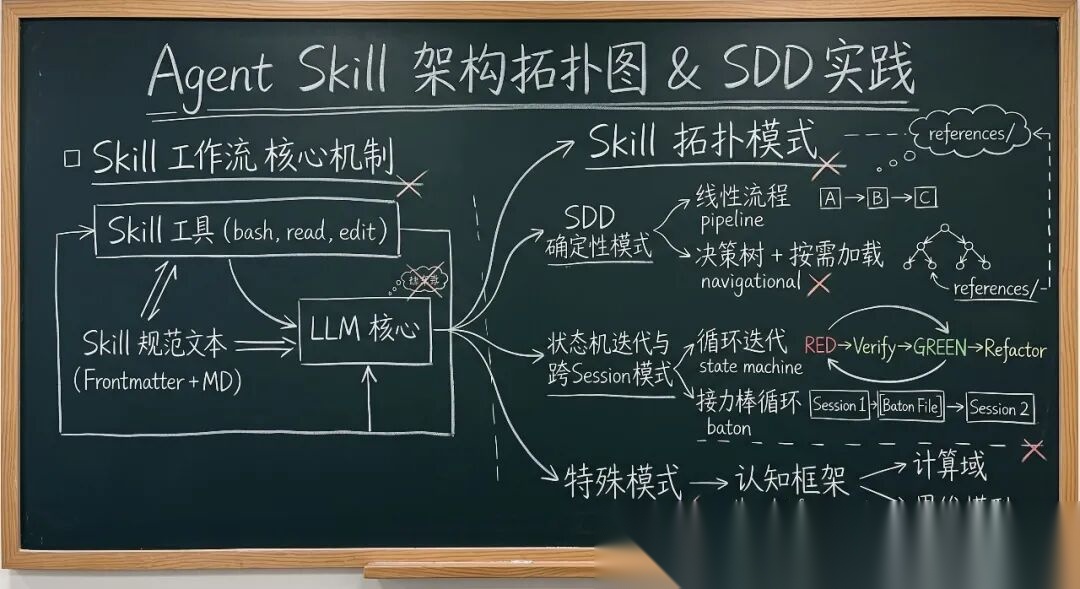
Skills 的 5 种架构设计模式
当 AI Agent 从"能对话"进化到"能干活",Skill(技能包)就成了决定其执行质量的关键基础设施。它不是简单的 Prompt 堆砌,而是一套让 LLM 在特定场景下"知道该做什么、知道怎么做"的知识注入体系。
本文基于 OpenAI、Google Labs、Trail of Bits 等 7 个顶级 Skill 仓库的深度分析,提炼出 5 种经过验证的设计模式与一套通用写作方法论,帮助你在企业级 Agent 建设中少走弯路。
一、Skill 的本质:知识注入,而非工具创造
一个标准的 Skill 是一个文件夹,核心是SKILL.md文件,采用 YAML frontmatter + Markdown 正文的格式。当 LLM 判断需要某个 Skill 时,会调用skill工具加载它,将其全部内容注入对话上下文,LLM 据此自主决策如何执行。
关键认知:Skill 不生成新工具,它注入的是"指令文本"。LLM 仍然使用已有的 bash、read、edit 等基础工具来执行这些指令。这意味着 Skill 的设计质量,直接决定了 LLM 的执行准确率。
一个完整的 Skill 目录通常包含:
- SKILL.md:主文件(必须)
- scripts/:可执行脚本(可选)
- references/:详细参考文档(可选,按需加载)
- resources/:模板、清单等资源(可选)
- examples/:示例(可选)
二、Frontmatter:决定 Skill 是否被加载的"门面"
Frontmatter 是 LLM 扫描所有可用 Skill 时的第一接触点。其中description字段最为关键,它直接决定 LLM 会不会加载你的 Skill。
好 description 的三要素:
- 触发短语:把用户可能说的话写进去,如 “deploy my app”、“push this live”
- 时序位置:说明"在什么之前/之后"使用,如 “before writing implementation code”
- 产品关键词:覆盖的平台或产品名要列全
反面教材是模糊的描述如 “Helps with deployment stuff”,LLM 根本无法判断何时该调用。
进阶的扩展字段包括references(声明核心参考文档)、allowed-tools(声明工具权限)、type(workflow/component)、estimated_time(预估执行时间)等,可根据复杂度选择性添加。
三、5 种核心设计模式
模式 1:线性流程 “先做 A,再做 B,最后做 C”
- 适用场景:部署、安装、迁移等有明确步骤的操作。
- 代表:OpenAI 的vercel-deploy(77 行,最小但完整的模板)
- 结构要点:
Prerequisites(前置条件)→ Quick Start(主流程 Step 1→2→3)→ Fallback(降级方案)→ Troubleshooting(故障排除)
- 关键技巧:
- 安全默认值:如 “Always deploy as preview, not production”,防止 LLM 做出危险操作
- 具体命令:每步给出可直接执行的 bash 命令,LLM 不需要猜测
- 超时提示:如 “Use a 10 minute timeout”,防止因超时而中断
- 负面指令:明确说"不要做 X",如 “Do not curl the deployed URL to verify”
- 判断标准:如果你的 Skill 能用"先做 A,再做 B,最后做 C"描述,就用线性模式。
模式 2:决策树 + 按需加载 – “大平台的渐进式披露”
-
适用场景:大型平台选型、产品导航、问题诊断,知识域有 10+ 个分支。
-
代表:OpenAI 的cloudflare-deploy(224 行)
-
结构要点:
Authentication(认证前置)→ Quick Decision Trees(按用户意图分类)→ Product Index(产品索引表)
-
关键技巧:
-
用户意图分类:用 “I need to run code” 而非 “Compute products”,说用户的语言
-
树形导航:用├─ 边缘无服务器函数 → workers/帮助 LLM 快速定位
-
渐进式披露:主文件控制在 7KB,references/ 按需展开到几十万字,不浪费上下文窗口
-
进阶思路:同一个知识域可以拆成两个 Skill,导航型只做选型,操作型包含认证、命令、故障排除。
模式 3:循环迭代 “做 → 验证 → 改进”
- 适用场景:TDD、代码审查、设计评审等需要反复执行的流程。
- 代表:obra 的test-driven-development(371 行)
- 结构要点:
The Iron Law(铁律)→ Red-Green-Refactor(循环体:RED → Verify RED → GREEN → Verify GREEN → REFACTOR → Repeat)→ Common Rationalizations(借口反驳表)→ Verification Checklist(退出条件)
- 关键技巧:
- 强硬语气:如 “Delete it. Start over.”,LLM 倾向于"灵活变通",命令式语气提高遵从率
- Good/Bad 对比:用和标签包裹代码示例,对比教学效果最好
- 借口反驳表:预判 LLM 可能的 12 种偷懒借口并逐一反驳,堵死所有逃避路径
- 验证清单:8 项 checklist 作为循环退出条件,确保质量达标才能结束
模式 4:接力棒循环 – “跨 Session 的持久化”
- 适用场景:多次迭代的长期项目,需要跨多个 session 持续工作,或多 Agent 协作。
- 代表:Google Labs 的stitch-loop(203 行)
- 核心机制:用next-prompt.md作为"接力棒"文件,LLM 不需要记住"上次做到哪了",只需读写文件即可续接状态。
- 6 步执行协议:
-
Read the Baton(读接力棒)
-
Consult Context Files(查阅上下文)
-
Generate(执行任务)
-
Integrate(集成结果)
-
Update Documentation(更新文档)
-
Prepare the Next Baton(写下一个接力棒:关键!)
- 与模式 3 的区别:循环迭代依赖对话上下文,单次会话内完成;接力棒循环依赖外部文件系统,支持跨 session 的长期项目(天~周级别)。
模式 5:多阶段 + 检查点 – “复杂项目的编排器”
-
适用场景:跨越多天/多周,需要在关键节点做 Go/No-Go 决策的复杂流程。
-
代表:Dean Peters 的discovery-process(502 行)
-
结构要点: 每个 Phase 统一包含 Activities(调用哪些子 Skill)→ Outputs(阶段产出)→ Decision Point(检查点:YES/NO + 时间影响)
-
关键技巧:
-
统一阶段模板:LLM 快速理解结构,降低认知负担
-
决策检查点:如 “达到饱和了吗?YES → 下一阶段,NO → +1 周”,防止盲目推进
-
Skill 编排:大 Skill 调度 10+ 个子 Skill,形成编排器模式
-
时间影响标注:每个 NO 路径标注 “+2-3 days”、“+1 week”,让用户了解延迟成本
特殊模式:思维框架 – “控制 LLM 怎么想”
- 适用场景:安全审计、架构分析等需要深度思考而非快速执行的场景。
- 代表:Trail of Bits 的audit-context-building(302 行)
- 核心逻辑:给 LLM 分析框架(如第一性原理、5 Why、5 How)而非具体命令;用量化阈值强制分析深度(如"每个函数最少 3 个不变量、5 个假设");用"非目标约束"克制 LLM 冲动(如"不要识别漏洞、不要提出修复,先理解再判断")。
四、通用写作技巧:让 LLM 不偷懒、不越界
1.防止偷懒的 4 种武器
- 强硬语气:命令式表达提高遵从率
- 借口反驳表:预判并堵死自我合理化路径
- 量化阈值:给出硬性最低标准
- 负面指令:明确说"不要做 X"
2.教学的 3 种有效方式:
- Good/Bad 对比学习
- 给出具体可执行的命令
- 展示完整的输出格式示例
3.安全与边界的 3 条原则
- 安全默认值(默认选最安全的选项)
- 权限最小化(只在必要时提升权限)
- 人类兜底(不确定时交给人判断)
4.知识组织的 3 层架构:
- 第 1 层:Frontmatter(~100 tokens)LLM 扫描决定是否加载
- 第 2 层:SKILL.md 正文(2K-5K tokens)核心指令、决策树、流程步骤
- 第 3 层:references/ 和 resources/(1K-3K tokens/个,按需加载) 详细文档、示例、清单
总上下文占用建议控制在 10K tokens 以内(主文件 + 1-2 个参考文档)。
五、模式选择决策树
你的 Skill 需要做什么?
├─ 执行有明确步骤的操作 → 模式 1:线性流程
├─ 在大量选项中帮用户选择 → 模式 2:决策树 + 按需加载
├─ 单次会话内反复"做→验证→改进" → 模式 3:循环迭代
├─ 跨多个 session 持续推进 → 模式 4:接力棒循环
├─ 跨越多天/多周,有阶段和 Go/No-Go 决策 → 模式 5:多阶段 + 检查点
└─ 需要深度分析而非快速执行 → 特殊模式:思维框架
六、写在最后
Skill 设计的终极目标不是让 LLM"更聪明",而是让它"更可靠"。线性流程解决"怎么做对"的问题,决策树解决"选哪个对"的问题,循环迭代解决"做到什么程度算好"的问题,接力棒解决"断了怎么续"的问题,多阶段检查点解决"什么时候该停"的问题。
对于企业级 Agent 建设,建议从线性模式的最小可用 Skill 开始(一个SKILL.md+ 前置条件 + 步骤 + 故障排除),在真实业务场景中验证后再逐步叠加决策树、循环迭代等复杂模式。记住:Skill 的复杂度应该与业务场景的复杂度匹配,过度设计本身就是一种风险。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)