
AtomicVLA:释放机器人原子技能学习的潜力
26年3月来自中山大学、深圳鹏城实验室和深圳引望科技公司的论文“AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots”。
视觉-语言-动作(VLA)模型的最新进展展现其在机器人操作任务中的巨大潜力。然而,现实世界中的机器人任务往往涉及长时程、多步骤的问题解决过程,并要求具备持续获取技能的泛化能力,而不仅仅局限于单一动作或技能。这些挑战给现有的 VLA 模型带来巨大障碍,因为这些模型通常采用基于聚合数据训练的整体式动作解码器,导致扩展性较差。为了应对这些挑战,提出 AtomicVLA,这是一个统一的规划与执行框架,能够联合生成任务级规划、原子技能抽象和细粒度动作。AtomicVLA 通过“技能引导的混合专家”(SG-MoE)构建一个可扩展的原子技能库,其中每个专家都专注于掌握通用且精确的原子技能。此外,引入一种灵活的路由编码器,能够自动为新技能分配专门的原子专家,从而实现持续学习。通过大量实验验该方法的有效性。在仿真环境中,AtomicVLA 在 LIBERO 和 LIBERO-LONG 任务上的表现分别优于 π0 模型 2.4% 和 10%;在 CALVIN 任务中,其平均任务长度指标也分别比 π0 和 π0.5 模型优出 0.22 和 0.25。此外,在现实世界的长时程任务和持续学习场景中,AtomicVLA 的表现也始终优于基线模型,提升幅度分别达到 18.3% 和 21%。这些结果凸显原子技能抽象和动态专家组合对于长时程及终身机器人任务的有效性。
如图1 所示AtomicVLA 概览。以往采用单一动作头的 VLA 模型存在可扩展性受限及混合技能间严重干扰的问题,而 AtomicVLA 采用 SG-MoE 架构构建一个可扩展的技能专家库。通过在该框架内统一任务规划与动作执行,该模型在仿真及现实环境中的长时程任务与持续学习任务上均展现出卓越的性能。
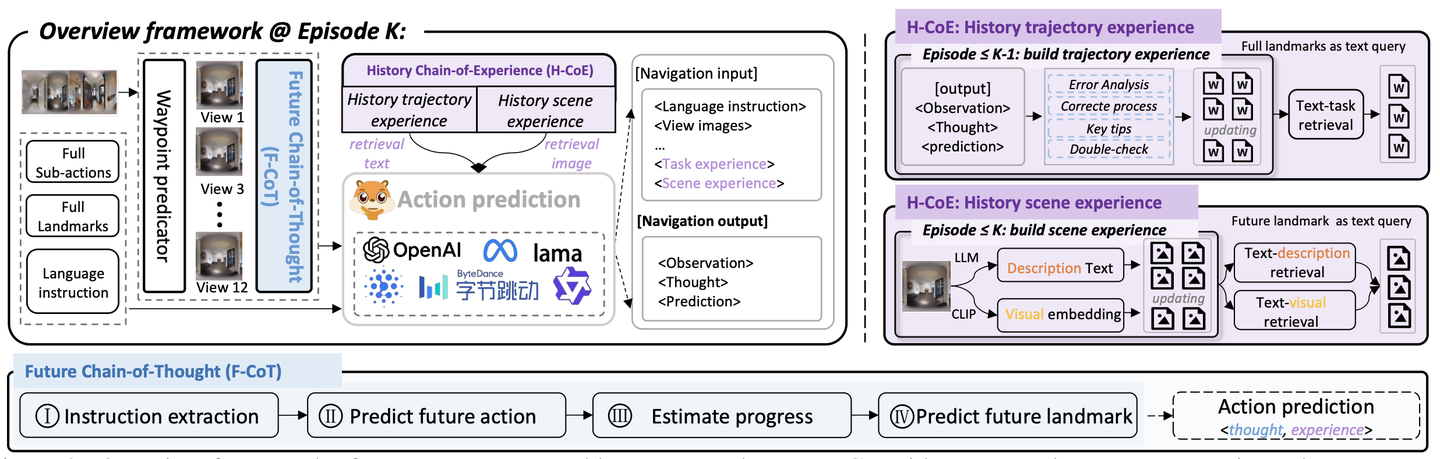
如图2 所示:(a) AtomicVLA 流水线。AtomicVLA 是一个统一任务规划与动作执行的框架。VLM模型自适应地预测原子技能抽象和潜动作。SG-MoE 架构中的动作解码器接收潜动作及新推断出的原子技能抽象,进而生成细粒度的运动动作。(b) 技能引导的专家混合(SG-MoE)。SG-MoE 包含一个技能路由模块、一个共享专家以及多个原子技能专家。路由模块根据原子技能选择最优的技能专家,动作 Token 则由被激活的技能专家和共享专家共同处理。© 具备技能扩展能力的持续学习。通过仅训练新专家并扩展路由模块,即可添加新技能。(d) 基于任务规划的具身数据生成。利用 InternVideo2.5 模型结合主轴分析(Principal-axis analysis),生成高质量的具身推理数据。
统一的任务规划和动作执行
探讨的核心问题是设计一种机器人策略,使其同时具备任务规划(思考)与动作执行(行动)能力,并能根据当前状态自主决定输出模态。
自适应的思考与行动。为了实现两种输出模式之间的无缝切换,引入两个特殊的输出tokens :[think] 和 [act]。如图1所示,给定当前的视觉观测 O1:n_t 和任务指令 l,模型首先预测标识符 [think] 或 [act]。当模型输出 [think] 时,它进入思考模式;在该模式下,模型生成任务链 C_0-k,用于概述高层计划、追踪当前执行进度 C_t 并指定待执行的原子技能抽象 sigma。通常,该模式仅在关键时间步(如任务启动或子技能转换期间)被激活。相反,当预测结果为 [act] 时,模型切换至行动模式;此时,模型根据最近一次 [think] 步骤中确定的原子技能抽象 sigma 以及当前的本体感知状态,生成低层动作片段 A_t。
基于技能引导的专家混合(MoE)架构
原子技能抽象嵌入。为了增强原子技能之间表征的区分度,采用一种受扩散去噪模型中噪声调度(noise scheduling)启发的编码策略。具体而言,每个原子技能抽象被映射为一个标量噪声水平 σ ∈ [0, 100],随后被嵌入到一个高维向量中。这种连续且结构化的嵌入空间有助于实现技能间的语义分离,并支持将任务稳健地路由至相应的特定技能专家。
技能引导的动态路由。在 π_0 视觉-语言-动作(VLA)基础模型(一种基于大规模多模态数据预训练的通用机器人策略)的基础上,引入由原子动作抽象引导的专家混合(MoE)架构,从而构建一个可扩展的原子技能库。如图 2(b) 所示,技能库包含三个关键组件:(1) 技能路由模块(skill router);(2) 共享专家模块,用于保留 π_0 原有的动作生成能力;以及 (3) 多个原子技能专家模块,每个专家专精于执行特定的原子技能。
为了保持各原子专家在特定技能上的专精能力,首先通过“思维流水线”(thinking pipeline)从高层任务指令和环境观测中提取原子动作抽象。该抽象被确定性地映射为一个固定的高维嵌入向量 Z_σ,作为技能路由模块的条件信号。路由模块据此计算出针对各个专家的概率分布。
其采用稀疏激活策略:仅选择得分最高的专家来生成动作。设 k 为被激活专家的索引,w_k 为其原始得分;最终的动作片段 A 计算为共享专家与所选原子专家的加权组合。该架构使系统既能保留 π_0 强大的泛化能力,又能通过专用专家实现特定技能的高保真执行。
基于技能扩展的持续学习
在实际部署场景中,机器人不可避免地会遇到需要执行训练阶段未曾见过的原子技能的新任务。若直接将这些新技能纳入现有技能库并重新训练整个模型,往往会导致“灾难性遗忘”,从而严重损害先前已习得技能的性能。
AtomicVLA 采用模块化的“技能-专家”机制,实现技能库的持续可扩展性。具体而言,每个原子技能都被映射为一个固定的高维嵌入向量 Z_sigma,从而为该技能提供明确的语义抽象。这种设计天然支持终身学习环境下的增量式学习:当引入新的原子技能时,只需在现有架构中增加相应的专家模块并扩展路由网络即可。
为了确保平滑集成,扩展后的路由网络通过复制原始路由网络的权重进行初始化,而新的路由分支则使用较小的随机值进行初始化。这种初始化策略使模型能够以极少的微调适应扩充后的技能集,同时保持先前习得技能的性能。因此,AtomicVLA 实现原子技能库的高效且无干扰扩展,这正是实现可扩展机器人终身学习的关键需求。
面向任务规划的具身数据生成
为了获取准确可靠的原子动作标注,提出一种基于主轴分析(Principal-Axis Analysis)的轨迹原子分解方法。传统方法,通常依赖视觉-语言模型进行视频理解,或利用基于光流的运动特征来分割动作序列。然而,这些方法容易产生歧义和噪声,往往需要大量的人工后处理来修正和优化结果。
相比之下,本文方法通过分析末端执行器轨迹的关键运动学维度——包括平移位移(∆x, ∆y, ∆z)、旋转变化(∆roll, ∆pitch, ∆yaw)以及夹爪的二值状态——来实现原子动作的粗粒度但具有语义意义的分割。具体而言,对于每个短时运动片段,通过比较平移分量和旋转分量的大小来识别主要的运动模式。同时,追踪夹爪的状态转换,以推断动作语义和执行进度。例如,Z轴坐标持续下降且伴随夹爪闭合动作,表明这是一个“抓取”(pick)动作;而平移位移有限、伴随显著旋转且夹爪处于闭合状态的操作,则被归类为“旋转”(turn)动作。这种融合物理特性的分解方法能够生成在时间上精确且语义上可解释的原子动作边界,从而大幅降低了对人工精修的依赖。
基于主轴分析的输出,将完整的任务轨迹分解为按时间顺序排列的原子动作片段序列。为了精修并验证这些片段的语义标签,利用 InternVideo2.5 模型 [52] 对相应的视频片段进行解读,从而实现对初始原子动作标注的自动修正与丰富。通过将这些精修后的标签与完整轨迹对齐,构建一个结构化的推理链,其中包含已执行的原子动作序列以及针对后续步骤的相关高层规划。这种集成式表征不仅提高原子动作标注的保真度,还提供可解释的、分步执行的指导,从而支持稳健的长程任务规划与决策制定。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)