
Agent的6层架构:感知、规划、工具、记忆、执行、反馈
2024 年,ChatGPT 让所有人看到了大模型的对话能力。
2025 年,Manus 让所有人看到了 Agent 的「自主执行」能力。
2026 年,OpenClaw 把 Agent 推到了所有人手里。
但绝大多数人只看到了冰山一角。一个真正的 AI Agent,远不是「给大模型加个工具调用」这么简单。
它是一个完整的认知-行动系统,由 6 层架构构成。
这篇文章,我用一个统一的框架,把 Agent 的每一层拆开来讲——它是什么、为什么重要、怎么做、踩什么坑。
不讲概念,讲工程。
先看全景:6 层架构一览
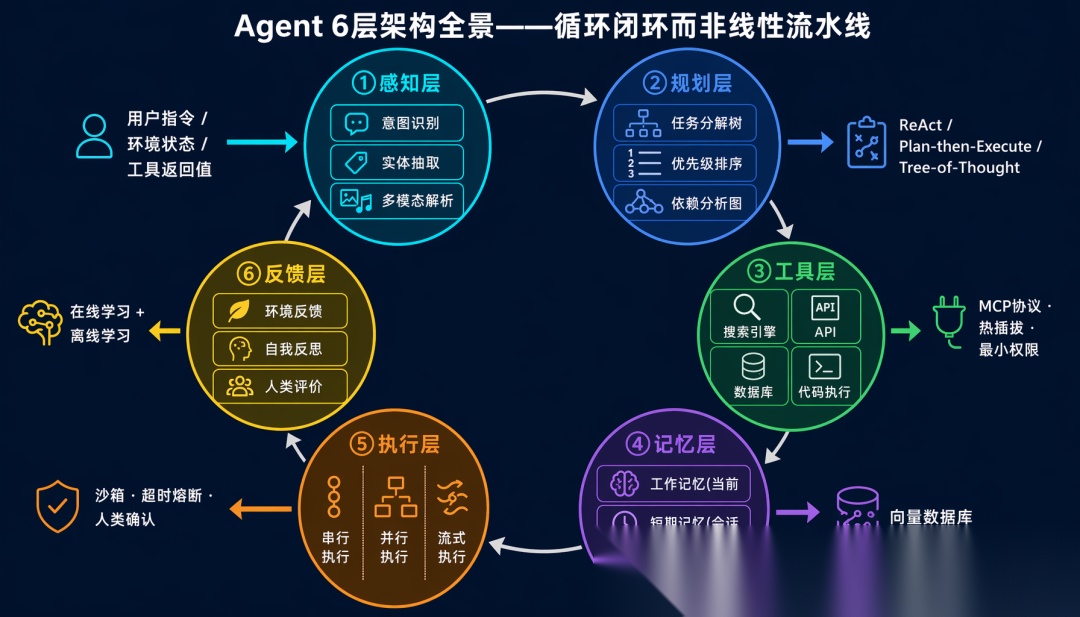
在深入每一层之前,先看整体结构。一个完整的 Agent 系统从上到下分为:
| 层级 | 名称 | 核心问题 | 类比 |
|---|---|---|---|
| 第 1 层 | 感知(Perception) | Agent 如何理解输入? | 人的眼睛和耳朵 |
| 第 2 层 | 规划(Planning) | Agent 如何拆解任务? | 大脑的前额叶皮层 |
| 第 3 层 | 工具(Tool) | Agent 如何扩展能力? | 人的双手和工具箱 |
| 第 4 层 | 记忆(Memory) | Agent 如何保持状态? | 人的海马体 |
| 第 5 层 | 执行(Execution) | Agent 如何落地行动? | 人的肌肉和神经 |
| 第 6 层 | 反馈(Feedback) | Agent 如何自我修正? | 人的痛觉和学习 |
这 6 层不是线性流水线,而是一个循环闭环——感知→规划→执行→反馈→感知→……
下面逐层拆解。
第 1 层:感知层——Agent 的「眼睛」和「耳朵」
1.1 感知层在做什么?
感知层的职责是:把原始输入转化为结构化的、Agent 可以理解的表示。
听起来简单,但这是整个系统最容易出问题的地方。因为如果 Agent 「看错了」,后面所有层都是垃圾进垃圾出。
感知层的输入类型:
用户自然语言指令
↓ 解析意图、实体、约束
多模态输入(图片、语音、视频)
↓ 跨模态对齐、特征提取
环境状态(API返回、文件内容、网页DOM)
↓ 结构化、过滤噪声
工具执行结果
↓ 解析返回值、识别错误
1.2 感知的核心技术
意图识别与实体抽取:
一个用户说:「帮我查一下明天从北京到上海的机票,经济舱,2000 以内的。」
感知层需要提取:
{
“intent”: “search_flight”,
“entities”: {
“departure”: “北京”,
“arrival”: “上海”,
“date”: “2026-06-19”,
“cabin_class”: “economy”,
“max_price”: 2000,
“currency”: “CNY”
},
“constraints”: [“price <= 2000”, “cabin = economy”],
“missing_info”: [“departure_time_preference”]
}
多模态感知:
2026 年的旗舰模型(Gemini 2.5 Ultra、GPT-5.5、Claude Opus 4)已经能处理视频输入。但在 Agent 场景中,多模态感知的关键不是「能看图」,而是把视觉信息转化为可操作的结构化数据。
比如 Agent 看到一个网页截图,它需要:
- 识别页面布局(header、sidebar、main content)
- 定位可交互元素(按钮、输入框、链接)
- 提取关键信息(价格、日期、状态)
这就是为什么 WebArena、OSWorld 这些评测这么难——感知不只是「看到」,还要「看懂」。
1.3 工程实践:感知层的 3 个关键设计
设计 1:输入归一化管道
不管用户输入什么格式,都转换为统一的内部表示:
class PerceptionPipeline:
def __init__(self):
self.parsers = {
“text”: TextParser(),
“image”: ImageParser(),
“audio”: AudioParser(),
“api_response”: APIResponseParser(),
}
def perceive(self, raw\_input: Any, input\_type: str) -> StructuredInput:
parser = self.parsers[input\_type]
parsed = parser.parse(raw\_input)
# 统一归一化
normalized = StructuredInput(
intent=parsed.extract\_intent(),
entities=parsed.extract\_entities(),
constraints=parsed.extract\_constraints(),
context=parsed.extract\_context(),
confidence=parsed.confidence\_score()
)
# 低置信度时请求澄清
if normalized.confidence < 0.7:
raise AmbiguousInputError(normalized)
return normalized
设计 2:置信度门控
不是所有输入都值得处理。当 Agent 不确定用户意图时,应该主动请求澄清,而不是猜测后执行错误操作。
设计 3:增量感知
对于长任务,不要一次性处理所有输入。采用流式感知,每完成一步就重新感知环境状态:
while not task_complete:
current_state = perceive(environment)
plan = planner.update_plan(current_state)
result = executor.execute(plan.next_step)
feedback = feedback_layer.evaluate(result)
# 回到感知层,重新观察环境
1.4 常见踩坑
| 坑 | 表现 | 解法 |
|---|---|---|
| 意图漂移 | 多轮对话后 Agent 忘了最初需求 | 在每轮感知时注入原始意图锚点 |
| 环境误读 | Agent 把 API 错误当成成功 | 结构化校验返回值,不靠 LLM 自己判断 |
| 多模态噪声 | 图片 OCR 引入大量无关文字 | 预处理过滤,只保留结构化信息 |
第 2 层:规划层——Agent 的「大脑」
2.1 规划层在做什么?
规划层是 Agent 的「指挥中心」。它的职责是:把复杂目标拆解为可执行的步骤序列。
人类解决复杂问题时,会自然地把大目标拆成小目标,考虑资源约束,安排优先级。Agent 的规划层也要做到这些。
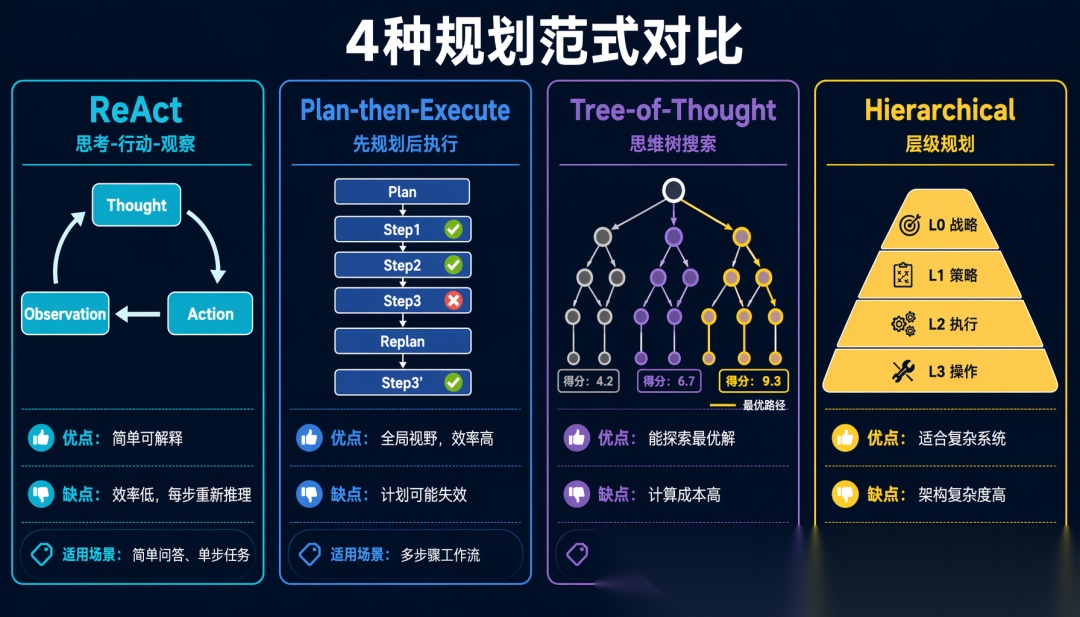
2.2 规划的核心范式
范式 1:ReAct(Reasoning + Acting)
最经典的 Agent 规划范式。每一步都是「思考→行动→观察」的循环:
Thought: 我需要查用户的历史订单来了解偏好
Action: search_orders(user_id=12345)
Observation: 找到3个历史订单,都是电子产品…
Thought: 用户偏好电子产品,推荐最新款…
Action: recommend_product(category=“electronics”, sort=“latest”)
Observation: 推荐列表包含5个产品…
优点:简单、可解释。缺点:每一步都要重新推理,效率低。
范式 2:Plan-then-Execute(先规划后执行)
先生成完整计划,再逐步执行:
Plan:
Step 1: 查询用户画像
Step 2: 获取推荐候选集
Step 3: 排序并筛选
Step 4: 生成推荐话术
Step 5: 发送推荐
Execute Step 1… ✅
Execute Step 2… ✅
Execute Step 3… ❌ (API超时)
Replan: 用缓存数据替代…
Execute Step 3 (revised)… ✅
优点:全局视野、效率高。缺点:计划可能因环境变化而失效。
范式 3:Tree-of-Thought(思维树搜索)
对复杂推理任务,探索多条路径,选择最优:
[目标:优化系统性能]
/ \
[优化数据库] [优化应用层]
/ \ / \
[加索引] [分库分表] [缓存策略] [异步处理]
↓ ↓ ↓ ↓
效果:高 效果:中 效果:高 效果:中
成本:低 成本:高 成本:低 成本:低
风险:低 风险:中 风险:低 风险:高
\ /
\___最优路径: 加索引 + 缓存___/
范式 4:Hierarchical Planning(层级规划)
把任务分成多个粒度层级,高层规划器做战略决策,底层规划器做战术执行:
L0(战略层):完成Q3营销目标
→ L1(策略层):制定内容策略 + 投放策略 + 转化优化
→ L2(执行层):写文案 + 设置广告 + A/B测试
→ L3(操作层):调API + 监控数据 + 调整参数
这是 2026 年多 Agent 系统的主流架构——高层用大模型做决策,底层用专用模型或小模型做执行。
2.3 规划层的工程实现
核心组件:Plan Manager
class PlanManager:
def __init__(self, llm, max_replan=3):
self.llm = llm
self.max_replan = max_replan
self.current_plan = None
def create\_plan(self, goal: Goal, context: Context) -> Plan:
"""根据目标和上下文生成计划"""
plan = self.llm.generate\_plan(
goal=goal,
context=context,
available\_tools=context.tool\_registry,
constraints=context.constraints
)
plan.validate() # 检查计划可行性
self.current\_plan = plan
return plan
def replan(self, failed\_step: Step, error: Error) -> Plan:
"""当某一步失败时,重新规划"""
return self.llm.replan(
original\_plan=self.current\_plan,
failed\_step=failed\_step,
error=error,
completed\_steps=self.current\_plan.completed
)
def adaptive\_step(self, step: Step) -> Step:
"""根据当前状态动态调整下一步"""
current\_state = self.perceive\_environment()
if self.should\_modify\_step(step, current\_state):
return self.llm.modify\_step(step, current\_state)
return step
2.4 规划层的关键指标
| 指标 | 含义 | 达标线 |
|---|---|---|
| 规划成功率 | 计划能完全执行的比例 | > 80% |
| 重规划次数 | 完成任务平均需要重新规划几次 | < 2 |
| 步骤效率 | 实际步骤数 / 最优步骤数 | < 1.5x |
| 上下文利用 | 计划是否有效利用已有信息 | > 90% |
2.5 常见踩坑
| 坑 | 表现 | 解法 |
|---|
| 规划幻觉 | 生成了不存在的 API 或工具 | 计划生成后做工具可用性校验 |
|---|---|---|
| 过度规划 | 10 步能解决的事拆成 30 步 | 设置最大步骤数,鼓励简洁 |
| 规划僵化 | 计划失败后不会灵活调整 | 实现渐进式 replan 而非全量重规划 |
| 上下文窗口溢出 | 长计划的 prompt 超出上下文限制 | 分层压缩,只保留当前层级+摘要 |
第 3 层:工具层——Agent 的「双手」
3.1 工具层在做什么?
工具层是 Agent 与外部世界交互的接口。没有工具,LLM 只能「说话」;有了工具,LLM 才能「做事」。
工具的本质是:把 LLM 的语言能力转化为操作能力。
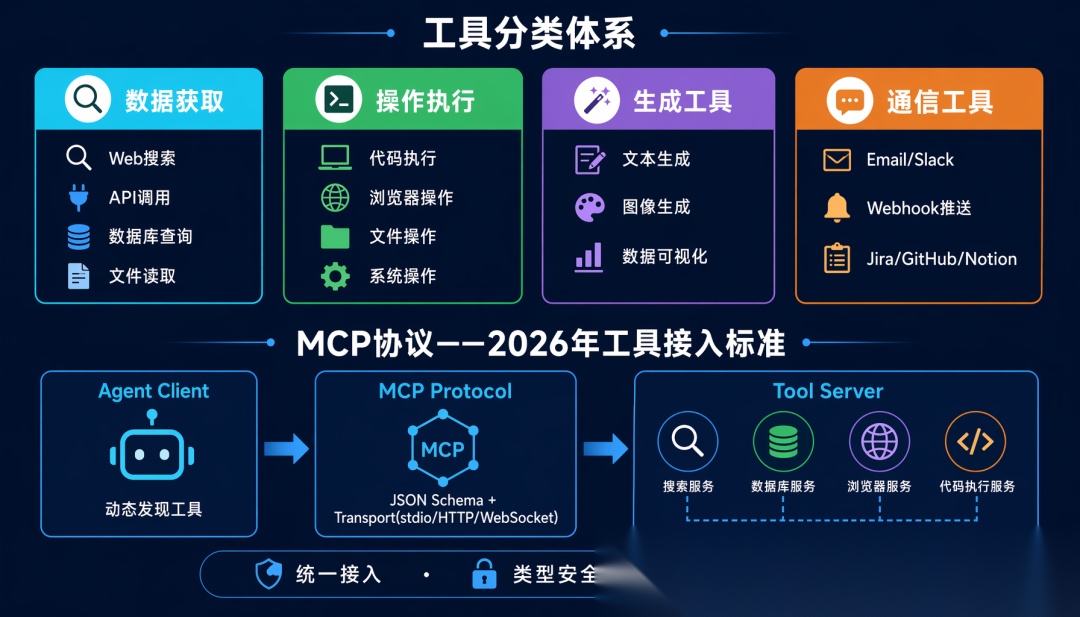
3.2 工具的分类体系
工具层
├── 数据获取工具
│ ├── 搜索引擎(Web Search)
│ ├── API 调用(REST/GraphQL)
│ ├── 数据库查询(SQL/NoSQL)
│ └── 文件读取(PDF/Excel/CSV)
├── 操作执行工具
│ ├── 代码执行(Python/Shell/SQL)
│ ├── 浏览器操作(点击、输入、导航)
│ ├── 文件操作(创建、编辑、删除)
│ └── 系统操作(进程管理、网络请求)
├── 生成工具
│ ├── 文本生成(邮件、报告、代码)
│ ├── 图像生成(DALL-E、Stable Diffusion)
│ └── 数据可视化(图表、仪表盘)
└── 通信工具
├── 消息发送(Email、Slack、微信)
├── 通知推送(Webhook、SMS)
└── 协作工具(Jira、GitHub、Notion)
3.3 工具注册与发现
现代 Agent 框架中,工具是热插拔的。核心设计模式:
class ToolRegistry:
“”“工具注册中心——Agent 的工具箱”“”
def \_\_init\_\_(self):
self.tools: dict[str, Tool] = {}
def register(self, tool: Tool):
"""注册一个工具"""
self.tools[tool.name] = tool
# 自动生成工具描述供 LLM 使用
tool.description = self.\_generate\_description(tool)
def get\_relevant\_tools(self, task: str) -> list[Tool]:
"""根据任务返回相关工具(语义搜索)"""
task\_embedding = embed(task)
scored = []
for tool in self.tools.values():
score = cosine\_sim(task\_embedding, embed(tool.description))
scored.append((score, tool))
return [t for s, t in sorted(scored, reverse=True)[:5]]
def validate\_call(self, tool\_name: str, params: dict) -> bool:
"""校验工具调用参数是否合法"""
tool = self.tools[tool\_name]
return tool.schema.validate(params)
工具定义示例
class WebSearchTool(Tool):
name = “web_search”
description = “搜索互联网获取实时信息。适合查询新闻、数据、文档等。”
schema = {
“query”: {“type”: “string”, “required”: True},
“num_results”: {“type”: “integer”, “default”: 5, “max”: 20},
“date_range”: {“type”: “string”, “enum”: [“day”, “week”, “month”, “year”]}
}
def execute(self, query: str, num\_results=5, date\_range=None):
results = search\_engine.search(query, num\_results, date\_range)
return ToolResult(
success=True,
data=results,
metadata={"source": "web", "count": len(results)}
)
3.4 MCP 协议:2026 年的工具标准
2025 年底,Anthropic 提出的 MCP(Model Context Protocol)成为事实上的工具接入标准。MCP 解决了工具接入碎片化的问题:
之前:每个框架有自己的工具格式
LangChain: @tool 装饰器
AutoGPT: JSON Schema
各厂商: 各自为政
MCP 之后:统一协议
Server: 提供工具描述 + 执行接口
Client: Agent 运行时发现并调用工具
Transport: stdio / HTTP SSE / WebSocket
MCP 的核心价值:
-
工具发现
:Agent 可以动态发现可用工具,不需要硬编码
-
类型安全
:严格的 JSON Schema 保证参数正确
-
上下文管理
:工具可以声明自己的上下文需求
-
权限控制
:工具可以声明权限等级,敏感操作需要人类确认
3.5 工具层的关键设计原则
原则 1:最小权限
Agent 只获得完成任务所需的最小工具权限。不能让一个查天气的 Agent 有删除数据库的能力。
原则 2:幂等性
工具操作应该尽可能幂等——重复调用不会产生副作用。这对 Agent 的重试机制至关重要。
原则 3:超时与熔断
每个工具调用必须有超时和熔断机制:
class ToolCallWithProtection:
def call(self, tool, params, timeout=30):
try:
with Timeout(timeout):
result = tool.execute(**params)
if self.circuit_breaker.is_open(tool.name):
return ToolResult(success=False, error=“Circuit open”)
return result
except TimeoutError:
self.circuit_breaker.record_failure(tool.name)
return ToolResult(success=False, error=f"Timeout after {timeout}s")
except Exception as e:
self.circuit_breaker.record_failure(tool.name)
return ToolResult(success=False, error=str(e))
第 4 层:记忆层——Agent 的「海马体」
4.1 记忆层在做什么?
记忆层让 Agent 能够:
-
记住
当前任务的上下文(短期记忆)
-
回忆
过去的经验和知识(长期记忆)
-
学习
从过去的成功和失败中改进(经验记忆)
没有记忆的 Agent,就像一个每次对话都从零开始的实习生。
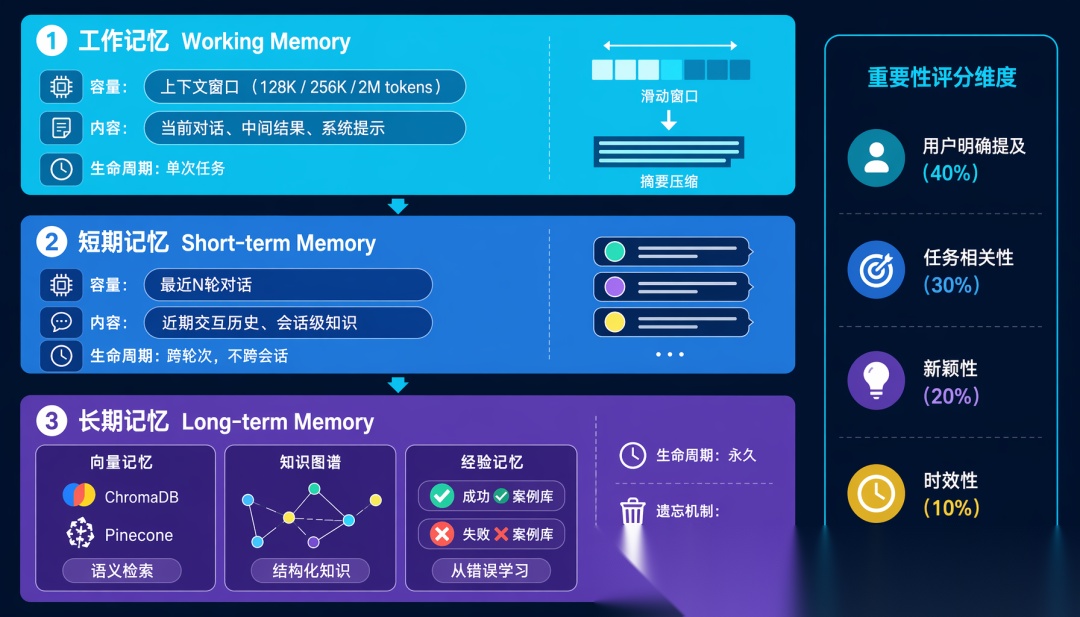
4.2 记忆的三层架构
┌─────────────────────────────────────┐
│ 工作记忆 (Working Memory) │
│ 当前任务上下文 + 近期对话 + 中间结果 │
│ 容量:受上下文窗口限制 │
│ 生命周期:单次任务 │
├─────────────────────────────────────┤
│ 短期记忆 (Short-term Memory) │
│ 近期交互历史 + 会话级知识 │
│ 容量:最近 N 轮对话 / K 个任务 │
│ 生命周期:跨轮次,不跨会话 │
├─────────────────────────────────────┤
│ 长期记忆 (Long-term Memory) │
│ 用户偏好 + 世界知识 + 经验教训 │
│ 容量:理论上无限(向量数据库) │
│ 生命周期:永久 │
└─────────────────────────────────────┘
4.3 工作记忆:上下文窗口管理
大模型的上下文窗口是有限的。2026 年最大的上下文窗口是 Gemini 2.5 Ultra 的 2M tokens,但即便是它,也需要精心管理工作记忆。
核心策略:滑动窗口 + 摘要压缩
class WorkingMemory:
def __init__(self, max_tokens: int = 128000):
self.max_tokens = max_tokens
self.messages: list[Message] = []
self.compressor = ContextCompressor()
def add(self, message: Message):
self.messages.append(message)
# 超出容量时压缩
current\_tokens = count\_tokens(self.messages)
if current\_tokens > self.max\_tokens \* 0.8:
self.\_compress()
def \_compress(self):
"""保留关键信息,压缩历史对话"""
# 1. 保留系统提示和最近 N 轮对话
system\_prompt = self.messages[0]
recent = self.messages[-10:]
# 2. 压缩旧对话为摘要
old = self.messages[1:-10]
summary = self.compressor.compress(old)
# 3. 重组上下文
self.messages = [
system\_prompt,
Message(role="system", content=f"[历史摘要] {summary}"),
\*recent
]
def get\_context(self) -> list[Message]:
return self.messages
4.4 长期记忆:向量检索 + 知识图谱
向量记忆(语义检索):
class LongTermMemory:
def __init__(self, embedding_model, vector_db):
self.embedding_model = embedding_model
self.vector_db = vector_db # 如 ChromaDB, Pinecone, Milvus
def store(self, content: str, metadata: dict = None):
"""存储一条记忆"""
embedding = self.embedding\_model.encode(content)
self.vector\_db.upsert(
id=generate\_id(content),
embedding=embedding,
content=content,
metadata={
\*\*(metadata or {}),
"timestamp": now(),
"importance": self.\_score\_importance(content)
}
)
def recall(self, query: str, top\_k: int = 5) -> list[Memory]:
"""检索相关记忆"""
query\_embedding = self.embedding\_model.encode(query)
results = self.vector\_db.search(
embedding=query\_embedding,
top\_k=top\_k,
filter={"importance": {"$gte": 0.5}}
)
# 去重 + 时间衰减
return self.\_deduplicate\_and\_rank(results)
def forget(self, memory\_id: str):
"""主动遗忘(隐私合规)"""
self.vector\_db.delete(memory\_id)
经验记忆(从错误中学习):
class ExperienceMemory:
“”“记录 Agent 的执行经验和教训”“”
def record\_success(self, task: Task, plan: Plan, execution: Execution):
"""记录成功案例"""
self.store({
"type": "success",
"task\_signature": task.fingerprint(),
"plan\_steps": [s.description for s in plan.steps],
"tools\_used": execution.tools\_used,
"total\_time": execution.duration,
"outcome": execution.result
})
def record\_failure(self, task: Task, plan: Plan, error: Error):
"""记录失败案例"""
self.store({
"type": "failure",
"task\_signature": task.fingerprint(),
"failed\_at": error.step\_index,
"error\_type": error.type,
"error\_detail": error.message,
"lesson": self.\_extract\_lesson(error)
})
def retrieve\_similar\_experiences(self, task: Task) -> list[Experience]:
"""检索类似任务的历史经验"""
similar = self.search(task.fingerprint(), top\_k=5)
# 优先返回失败案例——从错误中学习更有价值
return sorted(similar, key=lambda e: (e.type == "failure", e.relevance))
4.5 记忆层的工程实践
实践 1:记忆的重要性评分
不是所有信息都值得记住。用以下维度打分:
| 维度 | 权重 | 说明 |
|---|---|---|
| 用户明确提及 | 0.4 | 用户主动说的优先级最高 |
| 任务相关性 | 0.3 | 与当前任务目标的相关程度 |
| 新颖性 | 0.2 | 已有记忆中不包含的信息 |
| 时效性 | 0.1 | 越新的信息权重越高 |
实践 2:记忆的遗忘机制
人类会遗忘,Agent 也应该。遗忘不是缺陷,而是特性:
-
时间衰减
:6 个月前的对话权重减半
-
冲突覆盖
:用户说「我搬到上海了」,自动更新之前的「住在北京」
-
主动清理
:用户可以要求「忘记我的所有个人信息」
第 5 层:执行层——Agent 的「肌肉」
5.1 执行层在做什么?
执行层是 Agent 从「想」到「做」的桥梁。它负责:
- 把计划步骤转化为具体的工具调用
- 管理并发和依赖关系
- 处理执行中的异常和重试
5.2 执行引擎的核心架构
class ExecutionEngine:
“”“Agent 的执行引擎”“”
def \_\_init\_\_(self, tool\_registry, memory, max\_concurrent=5):
self.tool\_registry = tool\_registry
self.memory = memory
self.semaphore = asyncio.Semaphore(max\_concurrent)
async def execute\_plan(self, plan: Plan) -> ExecutionResult:
"""执行一个完整计划"""
results = []
for step in plan.steps:
# 检查依赖
if step.depends\_on:
for dep in step.depends\_on:
if not results[dep].success:
# 依赖步骤失败,触发重规划
return ExecutionResult(
success=False,
failed\_at=step.index,
needs\_replan=True
)
# 执行步骤
result = await self.execute\_step(step)
results.append(result)
# 记录到经验记忆
if not result.success:
self.memory.record\_failure(plan.task, plan, result.error)
return ExecutionResult(success=True, results=results)
async def execute\_step(self, step: Step) -> StepResult:
"""执行单个步骤(带重试和超时)"""
async with self.semaphore:
tool = self.tool\_registry.get(step.tool\_name)
for attempt in range(step.max\_retries + 1):
try:
result = await asyncio.wait\_for(
tool.execute(\*\*step.params),
timeout=step.timeout
)
# 验证结果
if self.\_validate\_result(result, step.expected\_output):
return StepResult(success=True, data=result)
# 结果不符合预期,重试
if attempt < step.max\_retries:
step.params = self.\_adjust\_params(step, result)
continue
except asyncio.TimeoutError:
if attempt == step.max\_retries:
return StepResult(
success=False,
error=TimeoutError(f"Step timed out after {step.timeout}s")
)
except Exception as e:
if attempt == step.max\_retries:
return StepResult(success=False, error=e)
return StepResult(success=False, error=MaxRetriesExceeded())
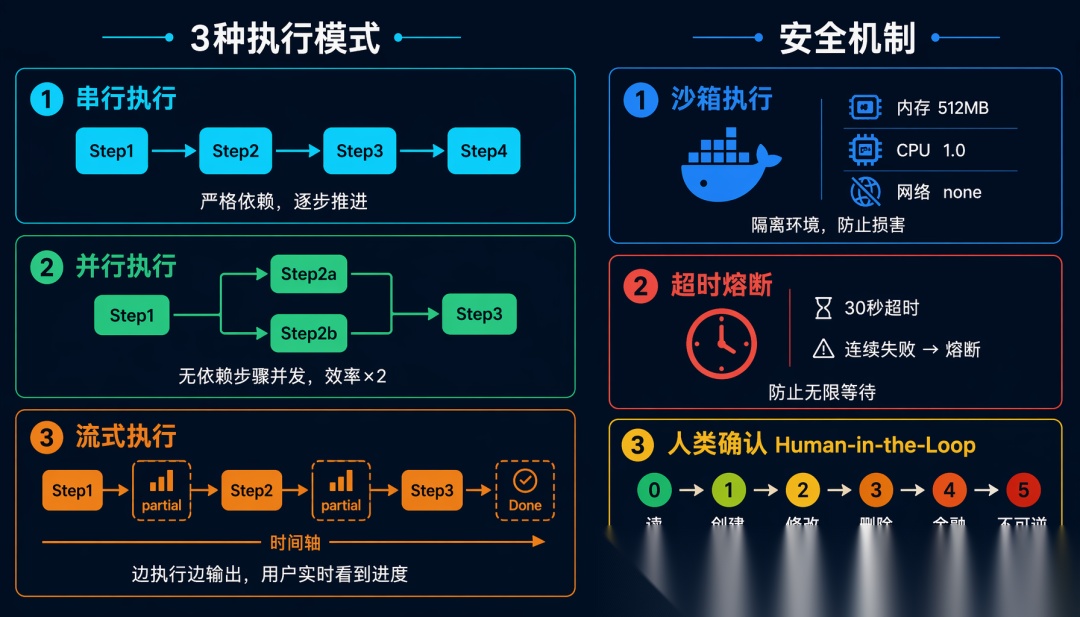
5.3 执行模式
模式 1:串行执行
最简单,适合有严格依赖关系的任务:
Step 1 → Step 2 → Step 3 → Step 4 → Done
模式 2:并行执行
无依赖的步骤可以同时执行,大幅提升效率:
Step 1 ─┬→ Step 2a ─┐
│ ├→ Step 3 → Done
└→ Step 2b ─┘
模式 3:流式执行
边执行边输出结果,适合长时间运行的任务:
Step 1 → [partial result] → Step 2 → [partial result] → … → Done
5.4 执行层的安全机制
沙箱执行: 代码执行必须在沙箱中进行,防止对系统造成损害:
class SandboxedCodeExecutor:
def __init__(self):
self.container = DockerContainer(
image=“python:3.12-slim”,
memory_limit=“512m”,
cpu_limit=1.0,
network=“none”, # 默认禁止网络
timeout=30,
read_only=True
)
def execute(self, code: str) -> ExecutionResult:
# 1. 静态检查(禁止危险操作)
if self.\_contains\_dangerous\_ops(code):
return ExecutionResult(success=False, error="Dangerous operation blocked")
# 2. 在容器中执行
result = self.container.run(code)
# 3. 限制输出大小
if len(result.stdout) > 100000:
result.stdout = result.stdout[:100000] + "...[truncated]"
return result
人类确认门控(Human-in-the-Loop):
高风险操作必须经过人类确认:
RISK_LEVELS = {
“read”: 0, # 读操作 - 自动执行
“create”: 1, # 创建操作 - 自动执行
“modify”: 2, # 修改操作 - 日志记录
“delete”: 3, # 删除操作 - 需要确认
“financial”: 4, # 金融操作 - 强制确认
“irreversible”: 5 # 不可逆操作 - 双重确认
}
class HumanGate:
def should_confirm(self, action: Action) -> bool:
return RISK_LEVELS.get(action.risk_type, 5) >= 3
async def request\_confirmation(self, action: Action) -> bool:
if not self.should\_confirm(action):
return True
confirmation = await self.notify\_human(
title=f"⚠️ 确认执行: {action.description}",
detail=action.details,
risk\_level=action.risk\_type,
timeout=300 # 5分钟超时
)
return confirmation.approved
第 6 层:反馈层——Agent 的「痛觉」和「学习」
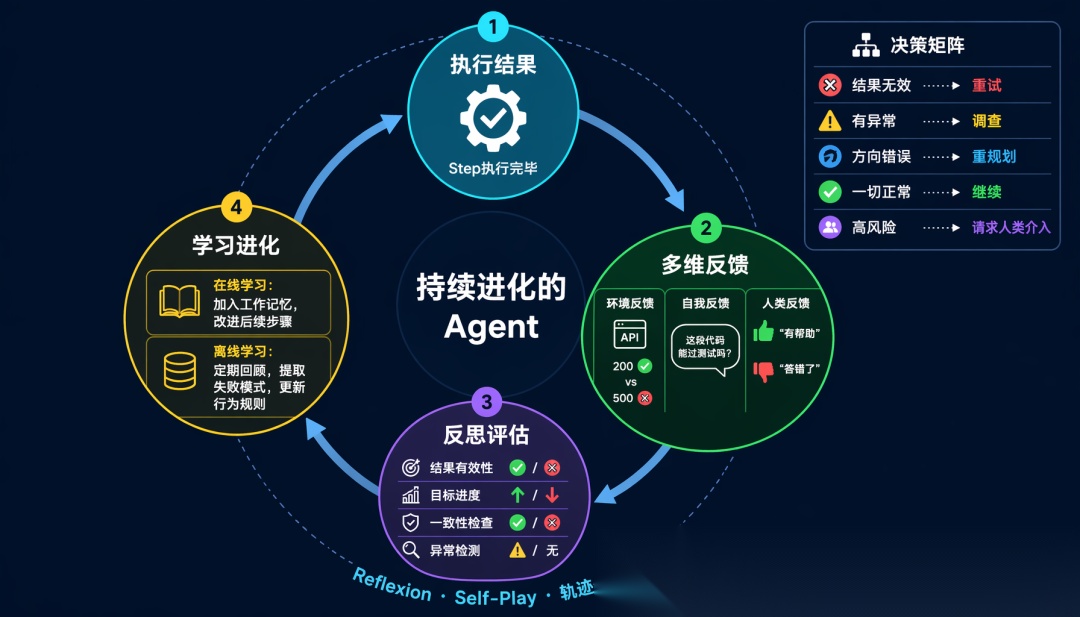
6.1 反馈层在做什么?
反馈层是 Agent 进化的关键。没有反馈,Agent 永远是同一个水平。有了反馈,Agent 可以从每次执行中学习。
反馈层的 3 种反馈类型:
| 类型 | 来源 | 示例 |
|---|---|---|
| 环境反馈 | 工具返回值 | API 返回 200 vs 500 |
| 自我反馈 | Agent 自身评估 | 「这段代码能通过测试吗?」 |
| 人类反馈 | 用户评价 | 「这个回答很有帮助」 / 「答错了」 |
6.2 自我反馈机制
Agent 执行完一个步骤后,应该「反思」结果:
class SelfReflection:
def reflect(self, step: Step, result: StepResult) -> Reflection:
“”“Agent 自我反思”“”
# 1. 结果验证
is\_valid = self.\_validate\_output(result)
# 2. 目标检查
goal\_progress = self.\_assess\_goal\_progress(step.goal, result)
# 3. 一致性检查
is\_consistent = self.\_check\_consistency(result, self.memory.get\_context())
# 4. 异常检测
anomalies = self.\_detect\_anomalies(result)
reflection = Reflection(
is\_valid=is\_valid,
goal\_progress=goal\_progress,
is\_consistent=is\_consistent,
anomalies=anomalies,
action=self.\_decide\_action(is\_valid, goal\_progress, anomalies)
)
return reflection
def \_decide\_action(self, is\_valid, progress, anomalies) -> str:
"""根据反思结果决定下一步行动"""
if not is\_valid:
return "retry" # 结果无效,重试
if anomalies:
return "investigate" # 有异常,深入调查
if progress < 0:
return "replan" # 方向错误,重新规划
return "continue" # 一切正常,继续执行
6.3 从反馈中学习
在线学习(In-Context Learning):
在同一任务中,Agent 利用之前的反馈来改进后续步骤:
class InContextLearner:
def update_context(self, feedback: Feedback):
“”“把反馈加入工作记忆”“”
lesson = self._extract_lesson(feedback)
self.memory.add(Message(
role=“system”,
content=f"[经验教训] {lesson}",
priority=“high” # 高优先级,不会被压缩掉
))
离线学习(Experience Replay):
跨任务学习,从历史经验中提取模式:
class ExperienceReplay:
def __init__(self, experience_db):
self.db = experience_db
def periodic\_review(self):
"""定期回顾历史经验"""
# 1. 获取最近 N 天的执行记录
recent = self.db.get\_recent(days=7)
# 2. 分析失败模式
failure\_patterns = self.\_cluster\_failures(recent.failures)
# 3. 提取可复用的规则
rules = []
for pattern in failure\_patterns:
if pattern.frequency >= 3: # 出现 3 次以上才算模式
rule = self.\_extract\_rule(pattern)
rules.append(rule)
# 4. 更新 Agent 的行为规则
for rule in rules:
self.\_update\_behavior\_policy(rule)
def \_extract\_rule(self, pattern) -> Rule:
"""从失败模式中提取规则"""
return Rule(
condition=pattern.trigger\_conditions,
action=pattern.recommended\_action,
confidence=pattern.frequency / pattern.total\_occurrences
)
6.4 反馈驱动的自我进化
2026 年最前沿的研究方向之一是 Agent 的自我进化:
方法 1:Reflexion(反思式学习)
Agent 在任务失败后,生成自然语言形式的「反思笔记」,作为未来任务的参考。
方法 2:Self-Play(自我对弈)
两个 Agent 实例互相评测,通过对抗来提升能力。一个生成方案,另一个挑错。
方法 3:Trajectory Optimization(轨迹优化)
记录完整的任务执行轨迹,用强化学习优化策略。成功轨迹增强,失败轨迹抑制。
6.5 反馈层的工程实践
class FeedbackLoop:
“”“完整的反馈循环”“”
def \_\_init\_\_(self):
self.self\_reflection = SelfReflection()
self.experience\_memory = ExperienceMemory()
self.learner = InContextLearner()
def process\_feedback(self, step: Step, result: StepResult) -> NextAction:
"""处理一步执行后的反馈"""
# 1. 自我反思
reflection = self.self\_reflection.reflect(step, result)
# 2. 记录经验
if result.success:
self.experience\_memory.record\_success(step, result)
else:
self.experience\_memory.record\_failure(step, result.error)
# 3. 在线学习
self.learner.update\_context(reflection)
# 4. 决定下一步行动
match reflection.action:
case "continue":
return NextAction.CONTINUE
case "retry":
return NextAction.RETRY(step, max\_retries=2)
case "replan":
return NextAction.REPLAN(failed\_step=step)
case "investigate":
return NextAction.DEBUG(step, reflection.anomalies)
case "abort":
return NextAction.ABORT(reason=reflection.summary)
case "ask\_human":
return NextAction.HUMAN\_ESCALATION(step, reflection)
6 层架构的协同:一个完整的例子
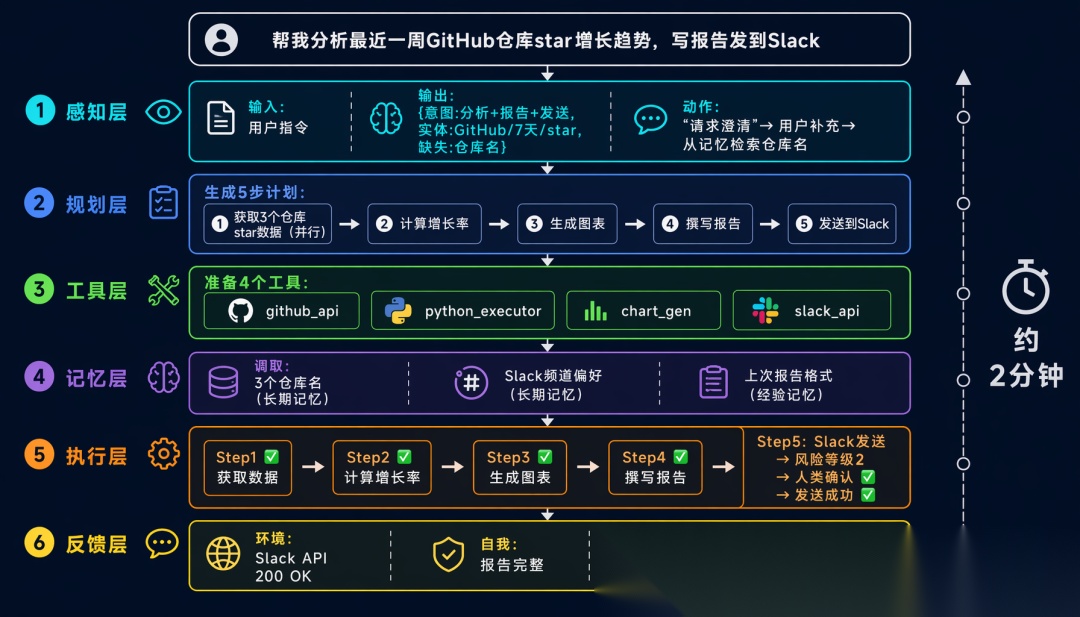
让我们用一个实际场景串联 6 层架构:
用户指令: 「帮我分析一下最近一周的 GitHub 仓库 star 增长趋势,写一份报告发到 Slack」
[感知层] 解析指令:
意图 = 数据分析 + 报告生成 + 消息发送
实体 = {目标: GitHub仓库, 时间: 最近7天, 指标: star增长, 输出: Slack}
缺失信息 = {具体仓库名}
→ 请求澄清:“请告诉我要分析哪些仓库?”
→ 用户补充:“我们的 3 个开源项目”
→ 从记忆中检索 → 找到用户之前提过的 3 个仓库名
[规划层] 生成计划:
Step 1: 获取 3 个仓库的 star 历史数据(并行)
Step 2: 计算增长率和趋势
Step 3: 生成可视化图表
Step 4: 撰写分析报告
Step 5: 发送到 Slack #analytics 频道
[工具层] 准备工具:
- github_api.get_stargazers(repo, since, until)
- python_executor.run(analysis_code)
- chart_generator.create(data, type=“line”)
- slack_api.send_message(channel, text, attachments)
[记忆层] 调取上下文:
- 工作记忆:当前对话
- 长期记忆:用户的 3 个仓库名、Slack 频道偏好
- 经验记忆:上次类似报告用了什么格式
[执行层] 逐步执行:
Step 1: 并行调用 GitHub API × 3 → 获取数据 ✅
Step 2: Python 分析 → 计算增长率 ✅
Step 3: 生成图表 → 3 张折线图 ✅
Step 4: 生成报告 → 800 字分析 ✅
Step 5: 发送到 Slack → 需要确认(风险等级=2)
→ 人类确认 ✅ → 发送成功 ✅
[反馈层] 评估结果:
- 环境反馈:Slack API 返回 200 OK
- 自我反馈:报告覆盖了所有仓库,数据完整
- 用户反馈:“报告很清晰,下次加上 fork 数据”
→ 记录到经验记忆:“下次分析仓库时,加入 fork 增长数据”
实战建议:如何搭建你自己的 Agent?
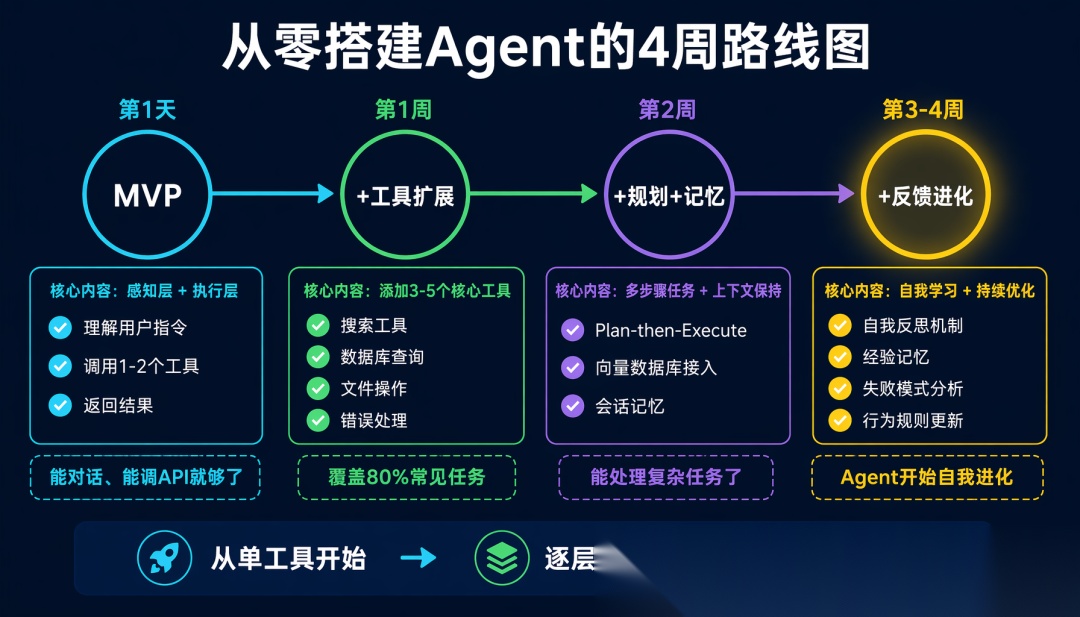
最小可行 Agent(1 天搭建)
从最简开始,逐层添加:
第1天:感知 + 执行
→ 能理解指令,调用工具,返回结果
第2-3天:加工具
→ 根据场景添加 3-5 个核心工具
第1周:加规划
→ 支持多步骤任务
第2周:加记忆
→ 接入向量数据库,支持上下文延续
第3-4周:加反馈
→ 添加自我检查和经验学习
技术栈推荐(2026 年)
| 层级 | 推荐工具 | 说明 |
|---|---|---|
| 感知 | GPT-5.5 / Claude Opus 4 | 意图识别和结构化提取 |
| 规划 | LangGraph / CrewAI | 可视化编排多步任务 |
| 工具 | MCP Protocol | 标准化工具接入 |
| 记忆 | ChromaDB + Redis | 向量检索 + 缓存 |
| 执行 | Temporal / Celery | 任务编排和重试 |
| 反馈 | Weights & Biases + 自定义 | 追踪和学习 |
5 条落地原则
-
从单工具开始
:不要一开始就接 20 个工具,先用 1-2 个跑通流程
-
人类兜底
:早期所有高风险操作都需要人类确认
-
日志一切
:每个 Agent 的决策链路都要可追溯
-
渐进自治
:从「人类审批所有操作」逐步过渡到「只审批高风险操作」
-
评测驱动
:建立你自己的评测集,持续跟踪 Agent 的能力变化
总结:Agent 不是大模型的附属品,而是一个完整的系统
很多人把 Agent 理解为「大模型 + 工具调用」。这是一种危险的简化。
一个真正可用的 Agent,是 6 层架构的协同产物:
-
感知
决定了它「看」得对不对
-
规划
决定了它「想」得清不清
-
工具
决定了它「做」得到不到位
-
记忆
决定了它「记」得好不好
-
执行
决定了它「干」得快不快
-
反馈
决定了它「学」得快不快
缺任何一层,都只是一个 Demo,不是一个产品。
2026 年,AI Agent 的竞争不是比谁的模型更大,而是比谁的系统更完整。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 1
1 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)