
从大语言模型到具身智能:30个核心概念解析AI智能体时代的技术图谱
本文系统梳理了AI智能体技术体系,涵盖基础模型层(LLM、微调、LoRA、MoE、多模态、VLM)、智能体架构层(Agent、自主智能体等)、工具与通信层、工程实践层和产品形态层五大维度。重点解析了30个核心概念,包括大语言模型的原理与选型、高效微调技术、多模态能力构建,以及智能体的感知-规划-行动-反思闭环架构。文章揭示了从底层模型到上层应用的完整技术栈,为开发者提供了AI智能体系统设计的全景视
本文系统梳理了AI智能体时代的核心技术概念、产品形态与工程实践,涵盖了基础模型层(如LLM、微调、LoRA等)、智能体架构层(如Agent、ReAct、规划等)、工具与通信层(如工具调用、Function Calling、MCP等)、工程实践层(如RAG、Prompt Engineering等)和产品形态层(如Multi-Agent、具身智能等)五大维度,旨在帮助读者建立从底层原理到上层应用的完整认知框架。文章深入解析了30个核心名词,探讨了AI智能体技术的发展趋势与未来方向。
从大语言模型到多智能体协作,从提示工程到具身智能——系统梳理AI智能体时代的核心技术概念、产品形态与工程实践。
前言
2023年以来,随着大语言模型(LLM)能力的飞速提升,AI智能体(Agent)正从概念走向工程实践。从AutoGPT的爆火到LangChain生态的成熟,从OpenAI的Function Calling到Anthropic的MCP协议,从单智能体到Multi-Agent协作——整个技术栈正在发生深刻变革。
本文对AI智能体领域的30个核心名词进行系统性解读,覆盖基础模型层、智能体架构层、工具与通信层、工程实践层和产品形态层五大维度,帮助读者建立从底层原理到上层应用的完整认知框架。
一、基础模型层
1. LLM(Large Language Model)大语言模型
大语言模型是AI智能体的"大脑",是所有Agent能力的基础底座。
技术原理
LLM基于Transformer架构(Vaswani et al., 2017),通过自回归方式(autoregressive)预测下一个token来生成文本。其核心机制包括:
- 自注意力机制(Self-Attention):让模型在处理序列时能够关注到不同位置之间的依赖关系。注意力计算公式为:Attention(Q, K, V) = softmax(QK^T / √d_k)V
- 预训练+微调范式:先在海量无标注文本上进行自监督预训练(如GPT系列的next-token prediction,BERT的masked language modeling),再通过指令微调(Instruction Tuning)和RLHF(基于人类反馈的强化学习)对齐人类意图
- 规模涌现效应:当模型参数量突破一定阈值(通常在数十亿级别),会涌现出零样本学习、思维链推理等能力(Wei et al., 2022)
代表模型
| 模型 | 参数量 | 特点 |
|---|---|---|
| GPT-4o | 未公开(推测>1T MoE) | 多模态原生,速度快 |
| Claude 4系列 | 未公开 | 长上下文(200K),安全对齐 |
| Gemini 2.5 | 未公开(推测>1T MoE) | 原生多模态,推理能力强 |
| Llama 3 | 8B-405B | 开源标杆 |
| DeepSeek-V3 | 671B MoE | 国产开源,推理成本低 |
在智能体中的角色
LLM为Agent提供以下核心能力:自然语言理解与生成——理解用户指令并生成响应;推理能力——通过CoT等方式进行逻辑推理;工具调用决策——判断何时、如何调用外部工具;上下文管理——在Memory中维护对话状态和历史信息。
选择LLM时需在能力、速度和成本之间权衡。对于需要高频决策的Agent,推理速度快的模型(如GPT-4o-mini、Claude Haiku)可能更合适;对于需要深度推理的场景,强推理模型(如Claude Opus、o3)更优。
2. Fine-tuning 微调
微调是让通用LLM适配特定领域或任务的关键技术。
三种主要范式
- 全量微调(Full Fine-tuning):更新模型全部参数。效果最好但成本最高,需要大量高质量标注数据(通常数千到数万条),且需要多张高端GPU。适用于需要深度适配的场景。
- 指令微调(Instruction Tuning):使用"指令-响应"对格式的数据训练模型理解和执行指令。这是InstructGPT、Alpaca等模型成功的关键。数据格式通常为
(instruction, input, output)三元组。 - 对齐微调(Alignment Tuning):通过RLHF或DPO(Direct Preference Optimization)让模型输出更符合人类偏好。RLHF流程为:SFT → 训练奖励模型 → PPO优化;DPO则跳过奖励模型,直接用偏好对优化。
在智能体中的应用
微调可以让LLM更好地生成结构化输出(如JSON格式的工具调用参数),理解特定领域的API规范,或者在特定场景下做出更准确的工具选择决策。例如,为客服Agent微调一个专门处理退款流程的模型,可以显著提升任务完成率。
3. LoRA(Low-Rank Adaptation)高效微调方法
LoRA(Hu et al., 2021)通过低秩分解大幅降低微调的参数量和计算成本。
核心思想
冻结预训练模型的全部参数W,对每一层的权重更新ΔW进行低秩分解:ΔW = BA,其中B∈R(d×r),A∈R(r×k),秩r远小于d和k。训练时只更新A和B两个小矩阵,参数量从d×k降低到r×(d+k)。
技术优势
- 显存效率:以Llama 2-7B为例,全量微调需要约56GB显存,LoRA(r=16)仅需约16GB
- 无推理延迟:训练完成后可将LoRA权重合并回原始模型,推理时无额外开销
- 多任务切换:可维护多个LoRA适配器,根据不同任务动态加载
- 参数高效:通常r=8~64即可达到接近全量微调的效果
进阶变体
- QLoRA(Dettmers et al., 2023):在4-bit量化基础上做LoRA,单张24GB显卡可微调65B模型
- DoRA:将权重分解为方向和幅度分别微调,效果优于标准LoRA
- **LoRA+**:对A和B矩阵使用不同学习率,进一步提升效果
在智能体场景中,LoRA使团队能够低成本地为不同垂直领域(医疗、法律、金融等)定制Agent的"大脑",而无需从头训练大模型。
4. MoE(Mixture of Experts)混合专家模型
MoE通过条件计算实现"大模型的能力,小模型的成本"。
架构原理
MoE模型由多个"专家网络"(Expert)和一个"门控网络"(Router/Gating Network)组成。对于每个输入token,门控网络选择Top-K个专家进行计算,而非激活全部参数。例如Mixtral 8x7B拥有8个7B专家(总参数46.7B),但每次推理只激活2个专家(约12.9B活跃参数)。
关键技术
- 负载均衡:通过辅助损失(Auxiliary Loss)确保各专家被均匀使用,避免"赢者通吃"
- 专家卸载(Expert Offloading):将不活跃的专家卸载到CPU/磁存,降低GPU显存需求
- 细粒度专家:DeepSeek-V2/V3采用细粒度专家分割,使用更多更小的专家,提升路由灵活性
对智能体的意义
MoE使Agent能够在不显著增加推理成本的前提下使用更大规模的模型。对于需要同时处理多种任务类型的Agent系统,不同专家可能自然地专业化为不同任务模式——语言理解、代码生成、数学推理等——形成隐式的"分工"。
5. Multimodal 多模态
多模态能力让AI智能体突破纯文本限制,理解和生成图像、音频、视频等多种信息形式。
技术路线
- 早期融合(Early Fusion):在模型输入端统一处理不同模态。典型代表为GPT-4V/4o和Gemini,通过视觉编码器(如ViT)将图像转换为token序列,与文本token共同输入Transformer
- 晚期融合(Late Fusion):各模态独立编码后在高层融合。典型代表为Flamingo(DeepMind)
- 统一架构:使用单一模型架构处理所有模态,如Chameleon(Meta)
应用场景
在智能体领域,多模态能力支撑了:GUI Agent——通过屏幕截图理解和操作图形界面;数据分析Agent——解读图表、PDF文档;客服Agent——处理用户上传的图片、语音消息;机器人Agent——理解物理环境的视觉信息。
6. VLM(Vision-Language Model)视觉语言模型
VLM是多模态模型的子类,专注于视觉理解和语言生成的联合理解。
核心架构
VLM通常由三部分组成:视觉编码器(如ViT-L/14、SigLIP)负责将图像编码为特征向量;投影层(通常是线性层或轻量MLP)将视觉特征映射到语言模型的嵌入空间;语言模型(如LLaMA、Vicuna)负责基于视觉和文本输入生成响应。
代表模型
- GPT-4o:OpenAI的原生多模态模型,支持图像、音频、视频输入
- Claude 3.5 Sonnet:Anthropic的视觉理解模型,在图表解读和OCR方面表现优异
- Qwen-VL系列:阿里通义千问的视觉语言模型,支持多图理解
- LLaVA:开源VLM标杆,架构简洁高效
在智能体中的作用
VLM是构建GUI Agent(图形界面操作智能体)和Embodied Agent(具身智能体)的核心能力。例如,一个基于VLM的GUI Agent可以"看到"手机屏幕,理解按钮、输入框的位置和功能,然后生成相应的点击、滑动操作指令。
二、智能体架构层
7. Agent 智能体
AI智能体是能自主感知环境、做出决策并采取行动来达成目标的AI系统。
核心能力框架
一个完整的AI Agent通常具备以下能力(参考Wooldridge & Jennings, 1995的经典定义并结合LLM时代的实践):
- 感知(Perception):通过文本输入、视觉输入、API响应等获取环境信息
- 规划(Planning):将复杂目标分解为可执行的子任务序列
- 记忆(Memory):维护短期上下文和长期知识
- 行动(Action):调用工具、执行代码、发送消息等
- 反思(Reflection):评估行动结果并调整策略
与传统AI的区别
传统AI(如推荐系统、分类模型)是"被动响应"的——给定输入,产生输出。而Agent是"主动循环"的——它持续感知-思考-行动,直到达成目标。这种循环(Agent Loop)是Agent系统的核心架构模式。
架构模式
- ReAct:交替进行推理(Reasoning)和行动(Acting)
- Plan-and-Execute:先制定完整计划,再逐步执行
- Reflexion:在行动后进行反思,从错误中学习
- Hierarchical:高层Agent制定目标,低层Agent执行任务
8. Autonomous Agent 自主智能体
自主智能体是Agent的高级形态,能够在极少甚至无人类干预的情况下持续运行。
关键特征
- 自主目标追求:接收高层目标后自主分解和执行
- 持续运行:不像ChatBot那样逐轮对话,而是持续循环执行
- 自我修正:当执行遇到错误时,能自主诊断和调整策略
- 资源管理:自主管理API调用、token使用等资源
典型系统
- AutoGPT(2023年3月):首个引起广泛关注的自主Agent,能自主搜索网页、编写代码、管理文件
- Devin(Cognition AI, 2024):自主软件工程师Agent,能端到端完成编程任务
- OpenAI Operator(2025):自主浏览器操作Agent
- Claude Code(Anthropic):自主编程Agent,能在终端中自主完成软件工程任务
工程挑战
自主Agent面临的核心挑战包括:幻觉累积——错误决策在循环中被放大;目标漂移——Agent可能偏离原始目标;资源消耗——长时间运行带来高昂的API成本;安全边界——需要防止Agent执行有害操作。
9. ReAct(Reasoning + Acting)思考+行动推理范式
ReAct(Yao et al., 2023)是当前最主流的Agent推理框架,将推理和行动交替进行。
核心流程
Thought: 我需要查询今天的天气信息Action: search("北京今天天气")Observation: 北京今天晴,气温15-25°CThought: 天气信息已获取,现在回复用户Action: finish("北京今天晴,气温15-25°C,适合出行。")
每个步骤包含三个要素:Thought(推理过程,解释为什么要执行这个动作)、Action(具体的工具调用或操作)、Observation(行动的结果反馈)。
优势
相比纯推理(Chain-of-Thought)和纯行动(Act-only),ReAct的优势在于:推理过程为行动提供了合理的解释和规划,而行动的结果又为推理提供了真实的外部信息,形成正反馈循环。实验表明,ReAct在HotpotQA等知识推理任务上显著优于纯CoT方法。
变体
- ReAct + Self-Consistency:多次采样取最优推理路径
- ReAct + Reflexion:加入反思步骤,从失败中学习
- Tree-of-Thought + Acting:将推理探索组织为树结构
10. CoT(Chain-of-Thought)思维链
思维链(Wei et al., 2022)是一种让LLM展示中间推理步骤来提升复杂问题求解能力的技术。
核心发现
当LLM直接回答复杂推理问题时准确率较低,但如果在prompt中加入"Let’s think step by step"或提供逐步推理的示例,模型的推理准确率会大幅提升。例如,在GSM8K数学推理基准上,CoT prompting将PaLM-540B的准确率从17.9%提升到58.1%。
实现方式
- Few-shot CoT:在prompt中提供包含推理过程的示例
- Zero-shot CoT:简单添加"Let’s think step by step"触发推理
- Auto-CoT:自动将复杂问题分解为推理子问题
- Self-Consistency(Wang et al., 2023):多次采样CoT推理路径,通过多数投票选择最终答案
在Agent中的应用
CoT是Agent规划能力的底层支撑。当Agent面对"帮我订一张明天从北京到上海的机票"这样的复杂指令时,CoT推理帮助它分解为:1)解析用户意图 → 2)确定出发地、目的地、日期 → 3)调用航班查询API → 4)筛选结果 → 5)确认预订。
11. Planning 规划能力
规划是Agent将高层目标分解为可执行子任务序列的核心能力。
规划策略
- 任务分解(Task Decomposition):将复杂目标拆分为简单子任务。可使用提示词如"请将此任务分解为若干子步骤"
- 依赖分析:识别子任务之间的先后依赖关系
- 资源评估:评估每个子任务所需的工具和信息
- 回退机制:当某步骤失败时,规划替代路径
规划算法
- HTN(Hierarchical Task Network):将任务组织为层次化网络
- LLM-as-Planner:直接用LLM进行规划,如"HuggingGPT"(Shen et al., 2023)用ChatGPT作为控制器调度HuggingFace上的各种AI模型
- ReWOO(Xu et al., 2023):先完整规划再执行,减少中间token消耗
- LATS(Zhou et al., 2023):将规划建模为蒙特卡洛树搜索
工程实践要点
在实际产品中,规划模块通常需要:约束条件——限制最大步骤数防止无限循环;验证机制——在执行前检查计划的合理性;可解释性——向用户展示计划内容以获取反馈。
12. Reflection 反思机制
反思让Agent能够评估自身行为的质量并从经验中学习。
核心架构(Reflexion,Shinn et al., 2023)
行动 → 失败 → 反思失败原因 → 生成反思文本 → 将反思存入记忆 → 下次遇到类似情况时调用反思记忆
反思类型
- 即时反思:每步行动后立即评估结果是否符合预期
- 任务级反思:整个任务完成后总结成功/失败经验
- 跨任务反思:在多个任务间积累通用经验
应用场景
- 代码生成Agent:运行测试后反思为什么测试失败,修改代码
- 客服Agent:分析用户不满的对话,调整回复策略
- 数据分析Agent:当分析结论被用户否决时,反思数据处理逻辑
反思机制是Agent从"执行者"进化为"学习者"的关键,但在工程实践中需要控制反思的频率和深度,避免过度反思导致的延迟和token消耗。
13. Memory 智能体记忆
记忆系统让Agent能够维持上下文状态并在交互间积累知识。
记忆分类(参考认知科学)
| 类型 | 对应概念 | 存储介质 | 生命周期 | 示例 |
|---|---|---|---|---|
| 感觉记忆 | Sensory Memory | LLM上下文窗口 | 单次对话 | 最近几条消息 |
| 工作记忆 | Working Memory | 对话历史+摘要 | 当前会话 | 对话摘要、当前任务状态 |
| 长期记忆 | Long-term Memory | 向量数据库/文件 | 持久化 | 用户偏好、历史经验 |
技术实现
- 上下文窗口管理:滑动窗口 + 摘要压缩。当对话超过上下文窗口时,对早期消息进行摘要
- 向量数据库存储:将对话、文档等信息嵌入为向量,存入向量数据库,通过语义相似度检索
- 知识图谱:将实体和关系组织为图结构,支持复杂推理
- 文件系统记忆:如MemGPT(Packer et al., 2023)将文件系统作为虚拟内存,LLM自主管理信息的存取
工程挑战
- 遗忘与干扰:长期记忆中可能存在矛盾信息,需要冲突解决策略
- 检索精度:向量相似度不等于语义相关性,需要混合检索策略
- 隐私安全:用户敏感信息的加密存储和访问控制
14. Supervisor Agent 管理/调度智能体
Supervisor Agent是Multi-Agent系统中的"指挥官",负责任务分配和流程协调。
架构模式
Supervisor Agent├── Worker Agent 1(代码生成)├── Worker Agent 2(数据分析)├── Worker Agent 3(文档撰写)└── Worker Agent 4(测试验证)
Supervisor接收用户请求后,分析任务类型,将其分配给合适的Worker Agent,监控执行进度,汇总结果返回给用户。
调度策略
- 静态路由:根据任务类型硬编码分配规则
- LLM路由:Supervisor自身也是一个LLM,通过推理决定将任务分配给谁
- 竞标式调度:多个Worker评估自身能力并"竞标"任务
- 动态委派:Worker在执行中遇到超出能力范围的子任务时,可请求Supervisor重新分配
典型实现
- LangGraph Supervisor:LangChain提供的Supervisor模式实现
- CrewAI:通过"角色扮演"模式实现Agent间的层级协作
- AutoGen:微软的Multi-Agent框架,支持灵活的对话拓扑
15. Worker Agent 执行智能体
Worker Agent是Multi-Agent系统中的"执行者",专注于完成特定类型的任务。
设计原则
- 单一职责:每个Worker专注于一类任务(如只做代码生成、只做数据分析)
- 工具绑定:为每个Worker配置其职责范围内所需的工具集
- 输入输出标准化:定义清晰的输入格式和输出格式,便于与其他Agent协作
- 失败处理:定义明确的失败上报机制,超出能力范围时通知Supervisor
示例设计
一个软件开发Multi-Agent系统可能包含以下Worker:
| Worker角色 | 职责 | 配置工具 |
|---|---|---|
| Architect | 系统设计、技术选型 | 文档搜索、架构模板库 |
| Coder | 编写代码 | 文件读写、代码执行、Git |
| Tester | 编写和运行测试 | 测试框架、代码覆盖率工具 |
| Reviewer | 代码审查 | 静态分析工具、Linter |
| Deployer | 部署上线 | CI/CD API、云服务API |
三、工具与通信层
16. Tool Calling 工具调用
工具调用是Agent与外部世界交互的核心机制。
工作流程
- LLM分析用户请求,判断需要调用哪些工具
- LLM生成结构化的工具调用请求(函数名+参数)
- Agent框架解析调用请求,执行实际的工具调用
- 将工具执行结果返回给LLM
- LLM基于结果继续推理或生成最终回复
工具描述规范
工具通常通过JSON Schema描述:
{ "name": "get_weather", "description": "获取指定城市的天气信息", "parameters": { "type": "object", "properties": { "city": {"type": "string", "description": "城市名称"}, "date": {"type": "string", "description": "日期,格式YYYY-MM-DD"} }, "required": ["city"] }}
工程实践
- 并行调用:当多个工具调用无依赖关系时,应并行执行以降低延迟
- 超时与重试:为工具调用设置超时和重试策略
- 结果格式化:将工具返回的原始数据格式化为LLM易于理解的形式
- 权限控制:对危险操作(如删除文件、发送邮件)实施二次确认
17. Function Calling 函数调用
Function Calling是OpenAI于2023年6月提出的标准化工具调用接口,后来被广泛采纳为行业标准。
核心概念
Function Calling不是指Agent实际执行函数,而是指LLM生成结构化的函数调用意图。实际执行由下游系统完成。
消息流示例
// 1. 用户消息{"role": "user", "content": "北京今天天气怎么样?"}// 2. 模型响应(function_call){"role": "assistant","tool_calls": [{ "function": { "name": "get_weather", "arguments": "{\"city\": \"北京\"}" } }]}// 3. 工具执行结果{"role": "tool","content": "{\"temperature\": \"22°C\", \"condition\": \"晴\"}"}// 4. 模型最终回复{"role": "assistant", "content": "北京今天天气晴朗,气温22°C。"}
行业影响
Function Calling的标准化极大降低了Agent开发的门槛。各大模型提供商(OpenAI、Anthropic、Google、开源模型)都实现了兼容的接口,使得Agent框架可以跨模型使用相同的工具定义。
18. MCP(Model Context Protocol)模型通信/控制协议
MCP是由Anthropic于2024年11月推出的开放标准协议,旨在标准化AI模型与外部工具和数据源之间的通信。
设计动机
在MCP出现之前,每个Agent框架和每个工具集成都需要单独的适配器,形成"M×N"的集成困境。MCP将其简化为"M+N":工具提供方只需实现MCP Server,Agent框架只需实现MCP Client。
核心架构
MCP Client(AI应用/Agent) ←→ MCP Protocol ←→ MCP Server(工具/数据源)
MCP Server暴露三类能力:
- Tools(工具):可被LLM调用的函数(类似Function Calling)
- Resources(资源):可被客户端读取的数据(如文件内容、数据库查询结果)
- Prompts(提示模板):可复用的提示词模板
支持的传输方式
- stdio:通过标准输入输出通信,适用于本地工具
- HTTP + SSE(Server-Sent Events):适用于远程服务
生态影响
MCP正在成为AI工具集成的事实标准。主流开发工具(VS Code、Cursor、Claude Desktop)、云服务(AWS、Stripe、GitHub)和数据库(PostgreSQL、SQLite)都已提供MCP Server。这意味着任何支持MCP的Agent框架都可以无缝接入这些工具。
19. A2A(Agent-to-Agent)智能体间协作
A2A(Agent-to-Agent)是Google于2025年4月提出的开放协议,旨在实现不同AI智能体之间的互操作性。
核心设计
- Agent Card:每个Agent发布一个JSON格式的能力描述文件,包含其支持的技能、输入输出格式、认证方式等
- Task协议:Agent间通过标准化的Task对象交换信息,包含消息、工件(Artifacts)和状态
- 能力发现:Agent可通过Agent Card发现其他Agent的能力并建立协作
与MCP的关系
MCP解决的是Agent与工具之间的连接问题(Agent → Tool),A2A解决的是Agent与Agent之间的连接问题(Agent → Agent)。两者互补:一个Agent可以通过MCP调用工具,同时通过A2A与其他Agent协作。
应用场景
- 跨平台协作:Google的Agent可以与Microsoft的Agent协作完成任务
- 专业化分工:不同公司提供不同领域的专业Agent(如旅行Agent、财务Agent),通过A2A协议协同服务用户
- Agent市场:Agent可以像API一样被发现和调用
20. Plugin 插件
插件是ChatGPT率先推出的LLM能力扩展机制,允许模型在对话中调用第三方Web服务。
ChatGPT Plugin架构(2023年)
- 插件提供一个OpenAPI规范的API描述文件
- ChatGPT读取API描述并决定何时调用
- 插件返回结果,ChatGPT生成自然语言回复
历史意义与局限
ChatGPT Plugin是Function Calling/MCP的先驱,验证了LLM调用外部工具的可行性。但其局限在于:绑定特定平台(ChatGPT)、安全性依赖平台审核、功能受限于HTTP API。随着Function Calling和MCP的出现,Plugin模式正在被更通用的标准取代。
当前意义
虽然ChatGPT Plugin Store已于2024年关闭,但"插件"的概念仍然重要——它代表了LLM作为"平台"的愿景:模型本身是中枢,通过插件/工具连接各种服务。GPTs和Claude Projects可以视为Plugin理念的进化形态。
21. Vector DB 向量数据库
向量数据库是AI智能体长期记忆和RAG系统的基础设施。
核心功能
将文本、图像等数据通过嵌入模型(Embedding Model)转换为高维向量,存储并支持高效的相似度检索。
主流方案对比
| 数据库 | 类型 | 特点 | 适用场景 |
|---|---|---|---|
| Pinecone | 云托管 | 全托管,易用 | 生产环境快速上线 |
| Weaviate | 开源/云 | 支持混合检索 | 需要BM25+向量混合检索 |
| Milvus | 开源/云 | 高性能,支持GPU加速 | 大规模向量检索 |
| Qdrant | 开源/云 | Rust实现,性能优异 | 高性能要求 |
| Chroma | 开源 | 轻量级,API简洁 | 开发原型和小型项目 |
| FAISS | 库(Meta) | 高性能相似度搜索 | 嵌入到应用中使用 |
检索策略
- 纯向量检索:基于余弦相似度/内积的ANN(近似最近邻)搜索
- 混合检索:向量检索 + 关键词检索(BM25),取两者结果的融合
- 重排序(Re-ranking):先用向量检索获取候选集,再用交叉编码器精排
在Agent系统中,向量数据库用于存储对话历史摘要、知识库文档、工具使用经验等,支撑Agent的长期记忆。
四、工程实践层
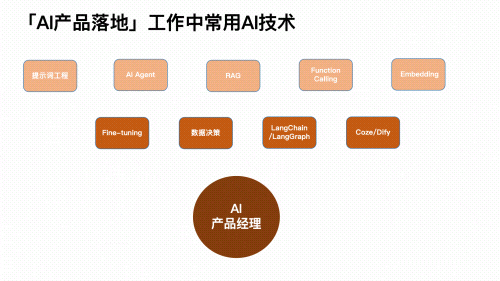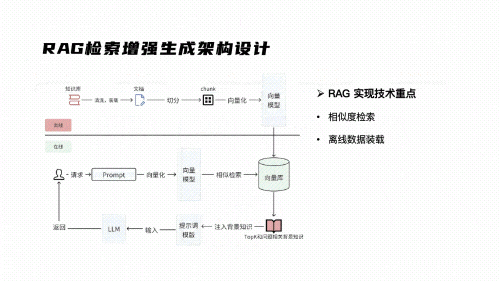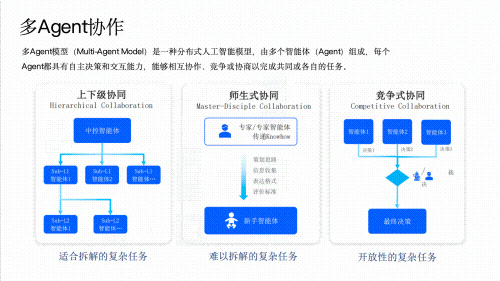
22. RAG(Retrieval-Augmented Generation)检索增强生成
RAG(Lewis et al., 2020)通过检索外部知识来增强LLM的生成质量,是解决模型幻觉和知识过时问题的主流方案。
标准流程
用户问题 → 查询改写 → 向量检索 → 文档重排 → 将检索结果注入Prompt → LLM生成回答
关键技术环节
- 文档处理:PDF/Word/网页的解析和分块(Chunking)。分块策略(固定长度、语义分块、递归分块)直接影响检索质量
- 嵌入(Embedding):将文本块转换为向量。主流嵌入模型:OpenAI text-embedding-3-large、BGE系列(BAAI)、Cohere embed-v3
- 检索:从向量数据库中检索与问题最相关的文本块
- 上下文构建:将检索到的文本块组织到Prompt中
- 生成:LLM基于检索到的上下文生成回答
进阶技术
- Agentic RAG:Agent自主决定是否需要检索、检索什么、如何组合检索结果
- Graph RAG:结合知识图谱进行检索,提升多跳推理能力
- Corrective RAG(Yan et al., 2024):检索后评估文档质量,不合格则重新检索或使用网络搜索
- Self-RAG(Asai et al., 2023):LLM自主判断是否需要检索和检索结果是否相关
在智能体中的作用
RAG为Agent提供了访问外部知识库的能力,使其能基于最新、准确的信息做出决策和生成回复。对于企业Agent,RAG是连接内部知识库(产品文档、规章制度、历史工单)的桥梁。
23. Prompt Engineering 提示工程
提示工程是通过精心设计输入文本来引导LLM产生期望输出的技术。
核心技巧
- 角色设定(Role Prompting):为模型分配特定角色以影响输出风格和质量。如"你是一位资深的Python工程师"
- 少样本学习(Few-shot Learning):提供少量示例引导模型理解任务格式
- 思维链(Chain-of-Thought):引导模型展示推理过程
- 结构化输出:要求模型以特定格式(JSON、XML等)输出
- 约束设定:明确告诉模型不能做什么(如"不要编造信息")
在Agent开发中的应用
Prompt Engineering在Agent中的关键应用场景:
- 系统提示词(System Prompt):定义Agent的角色、能力边界、行为规范
- 工具描述:用精确的语言描述工具的功能和参数,提升工具选择准确率
- 错误处理指令:告诉Agent如何处理工具调用失败、信息不足等情况
- 输出格式控制:确保Agent的回复格式符合产品要求
框架化方法
- CRISPE框架:Capacity(能力)+ Role(角色)+ Insight(洞察)+ Statement(陈述)+ Personality(个性)+ Experiment(实验)
- RISEN框架:Role(角色)+ Instructions(指令)+ Steps(步骤)+ End goal(目标)+ Narrowing(约束)
24. Workflow 工作流编排
工作流编排是将Agent的推理和行动组织为可管理、可监控的执行流程。
编排模式
- 链式(Chain):任务按顺序执行,前一步的输出是后一步的输入
- 并行(Parallel):多个独立任务同时执行
- 条件分支(Conditional):根据条件选择不同的执行路径
- 循环(Loop):重复执行直到满足退出条件
- 人机交互(Human-in-the-Loop):在关键节点等待人类确认
主流编排框架
- LangChain / LangGraph:最流行的LLM应用开发框架,LangGraph基于状态图实现复杂工作流
- LlamaIndex:专注RAG工作流的编排
- CrewAI:基于角色的Multi-Agent协作编排
- Semantic Kernel(Microsoft):企业级LLM应用编排框架
- Prefect / Airflow:传统工作流引擎,可用于编排LLM批处理任务
工程考量
- 可观测性:每个步骤的输入输出、延迟、token消耗都需要被追踪
- 容错设计:步骤失败时的重试、降级、回退策略
- 版本控制:工作流定义的版本管理和灰度发布
- 成本控制:限制每步的token使用量和API调用频率
25. Framework 开发框架
AI智能体开发框架为Agent的构建提供了标准化的模块和抽象。
主流框架对比
| 框架 | 核心特点 | 适用场景 |
|---|---|---|
| LangChain/LangGraph | 生态最全,社区活跃 | 通用Agent和RAG应用 |
| CrewAI | 角色扮演,易于理解 | Multi-Agent协作 |
| AutoGen(Microsoft) | 灵活的对话拓扑 | 研究和复杂的Multi-Agent |
| LlamaIndex | 数据连接和RAG | 知识密集型应用 |
| Haystack(deepset) | 模块化Pipeline | 生产级NLP应用 |
| Semantic Kernel | 企业级,.NET/Python | 微信 生态集成 |
| Smolagents(HuggingFace) | 轻量级,代码Agent | 快速原型开发 |
框架选型建议
- 快速原型:LangChain + OpenAI,最快上手
- 生产部署:LangGraph + 可观测性(LangSmith/LangFuse)
- Multi-Agent:CrewAI(简单场景)或 AutoGen(复杂场景)
- 知识库应用:LlamaIndex + 向量数据库
26. Code Interpreter 代码解释器
代码解释器让Agent能够编写和执行代码来完成数据分析、数学计算等任务。
工作原理
Agent在一个安全的沙箱环境中(通常是Docker容器或Jupyter内核)执行Python代码,获取执行结果(输出、图表、文件)并反馈给用户。
OpenAI Code Interpreter
OpenAI于2023年推出的Code Interpreter(后改名Advanced Data Analysis)是这一技术的标志性产品:
- 支持用户上传文件供Agent分析
- Agent自主编写Python代码处理数据
- 可生成图表、进行统计分析、创建文件
- 沙箱环境预装了pandas、matplotlib、numpy等常用库
在Agent架构中的作用
Code Interpreter扩展了Agent的"行动"能力,使其不再局限于预定义的工具集。Agent可以编写任意代码来解决未预见的问题,实现真正的"通用问题求解"。
安全考量
代码执行需要严格的安全沙箱:资源限制(CPU、内存、执行时间)、网络隔离(防止数据泄露)、文件系统隔离(防止越权访问)、白名单机制(限制可用的Python库)。
27. Orchestrator 编排器
编排器是复杂Agent系统中负责协调多个组件、管理执行流程的核心组件。
职责范围
- 任务路由:根据请求类型将任务分配给合适的处理单元
- 状态管理:维护全局执行状态和上下文
- 资源调度:管理API配额、计算资源、并发限制
- 结果聚合:将多个子任务的结果组合为最终输出
- 错误恢复:检测失败并触发恢复流程
架构模式
- 集中式编排:一个Orchestrator管理所有Agent,如Supervisor模式
- 去中心化编排:Agent之间直接通信,无需中央协调者
- 事件驱动编排:通过消息队列(如Kafka、RabbitMQ)异步协调
- 状态机编排:用有限状态机定义Agent的执行流程
与传统微服务编排的区别
Agent编排的独特挑战在于不确定性——LLM的输出不可预测,编排器需要处理各种意外情况(模型幻觉、格式错误、超时等),而传统微服务编排通常假设服务行为是确定性的。
五、产品形态层
28. Multi-Agent 多智能体
Multi-Agent系统通过多个Agent的协作来完成单个Agent难以胜任的复杂任务。
协作模式
- 层级式(Hierarchical):Supervisor分配任务给Worker,Worker汇报结果
- 辩论式(Debate):多个Agent就同一问题进行辩论,通过"对抗"提升答案质量(Liang et al., 2023)
- 投票式(Voting):多个Agent独立处理同一任务,通过投票选择最优解
- 流水线式(Pipeline):Agent依次处理,前一个Agent的输出是后一个的输入
典型系统
- MetaGPT(Hong et al., 2023):模拟软件公司的多角色协作(产品经理→架构师→工程师→QA)
- ChatDev(Qian et al., 2023):通过Agent对话完成软件开发
- CrewAI:提供简洁的Multi-Agent开发范式
- AutoGen:微软的Multi-Agent对话框架
产品应用
Multi-Agent在以下场景中展现价值:代码开发——设计、编码、测试、审查由不同Agent分工完成;研究分析——信息搜集、数据分析、报告撰写由不同Agent协作;客户服务——路由Agent判断类型,专业Agent处理问题,质检Agent审核回复。
29. Embodied Agent 具身智能体
具身智能体是能够在物理世界中感知和行动的AI系统,将LLM的"智能"延伸到现实世界。
技术栈
高层规划(LLM)→ 任务分解 → 低层控制(运动规划)→ 执行器(机器人) ↑ ↓ ←——————— 感知反馈(摄像头、传感器)←————————
关键组件
- 感知模块:使用VLM理解视觉场景,识别物体、空间关系
- 规划模块:使用LLM将自然语言指令分解为动作序列
- 控制模块:将高层动作转换为机器人底层控制指令
- 反馈模块:执行结果的感知反馈,用于调整行动
前沿研究
- SayCan(Google, 2022):LLM结合机器人可用技能进行任务规划
- PaLM-E(Google, 2023):562B参数的多模态模型,直接输出机器人控制指令
- VoxPoser(Huang et al., 2023):用LLM+VLM为机器人操作生成3D价值地图
- RT-2(Google DeepMind, 2023):将视觉语言模型微调为机器人控制策略
挑战
具身智能体面临的核心挑战是sim-to-real gap(仿真到现实的迁移差距)——在模拟环境中训练的策略在真实世界中往往表现不佳。此外,物理世界的安全约束更为严格——机器人执行错误操作可能造成物理伤害。
30. H2A(Human-to-Agent)人机交互
H2A研究人类如何与AI智能体高效、安全地协作,是Agent产品成功的关键因素。
交互范式演进
- 命令式交互:人类下达精确指令,Agent执行(如早期ChatBot)
- 对话式交互:人类通过自然语言对话与Agent协作(如ChatGPT)
- 委派式交互:人类给出高层目标,Agent自主规划和执行(如AutoGPT)
- 协作式交互:人类和Agent并肩工作,随时介入和调整(如Claude Code的Plan模式)
设计原则
- 可控性:人类应能随时暂停、修改、终止Agent的行为
- 透明性:Agent应向人类展示其推理过程和行动计划
- 可干预性:在关键决策点请求人类确认
- 渐进信任:从高频率确认开始,随着Agent证明可靠而降低确认频率
产品形态
- Claude Code:Plan模式让用户在执行前审查计划,权限系统让用户控制Agent的操作边界
- Cursor/Copilot:在IDE中以"补全+对话"方式辅助编程
- Devin:展示完整的操作过程,用户可随时介入
- OpenAI Operator:浏览器操作Agent,在敏感操作前请求确认
未来趋势
随着Agent自主性的提升,H2A交互将从"人类控制Agent"向"人类指导Agent"演进。人类的角色从"操作者"转变为"监督者"和"教练"——设定目标和约束,监控Agent行为,纠正偏差,而将具体执行交给Agent。
六、技术全景图
30个名词的技术分层
┌─────────────────────────────────────────────────────────┐│ 产品形态层(Product) ││ Multi-Agent │ Embodied Agent │ H2A │ Autonomous Agent │├─────────────────────────────────────────────────────────┤│ 工程实践层(Engineering) ││ RAG │ Prompt Engineering │ Workflow │ Framework ││ Code Interpreter │ Orchestrator │├─────────────────────────────────────────────────────────┤│ 工具与通信层(Protocol) ││ Tool Calling │ Function Calling │ MCP │ A2A ││ Plugin │ Vector DB │├─────────────────────────────────────────────────────────┤│ 智能体架构层(Architecture) ││ Agent │ ReAct │ CoT │ Planning │ Reflection │ Memory ││ Supervisor │ Worker │├─────────────────────────────────────────────────────────┤│ 基础模型层(Foundation) ││ LLM │ Fine-tuning │ LoRA │ MoE │ Multimodal │ VLM │└─────────────────────────────────────────────────────────┘
技术发展趋势
- 模型推理成本持续下降:MoE架构、量化技术、推理优化使Agent的运行成本逐年降低
- 工具标准化:MCP和A2A正在建立Agent工具和协作的标准
- Agent专业化:从通用Agent向垂直领域Agent演进
- 人机协作深化:从简单问答到深度协作,H2A交互设计日益成熟
- 具身智能起步:LLM驱动的机器人正从实验室走向实际应用
结语
AI智能体正在经历从概念验证到工程实践的关键转型期。理解这30个核心名词不仅是掌握技术概念,更是建立系统性思维框架——从底层模型能力到上层产品形态,从单Agent推理到Multi-Agent协作,从纯文本到多模态到具身智能。
这个领域的变化速度极快——MCP协议从发布到成为事实标准仅用了不到半年,A2A协议也在2025年4月刚刚发布。持续关注这些核心概念的演进,是每一位AI从业者和产品人的必修课。
传统产品经理,正在成为下个被淘汰的“传统岗位”。
过去画原型、写 PRD、跟进度的“传统技能包”,在AI时代正迅速贬值。63% 的企业转型做 AI 产品!当下的问题不再是“要不要学 AI ”,而是“如何构建 AI 产品”。
前段时间还跟字节、腾讯的资深 AI 产品经理沟通,他们反馈:在大量招人,只要有 AI 相关的项目经验,基本都能拿到面试机会,而且领导很舍得给钱,涨薪 40-60% 很正常!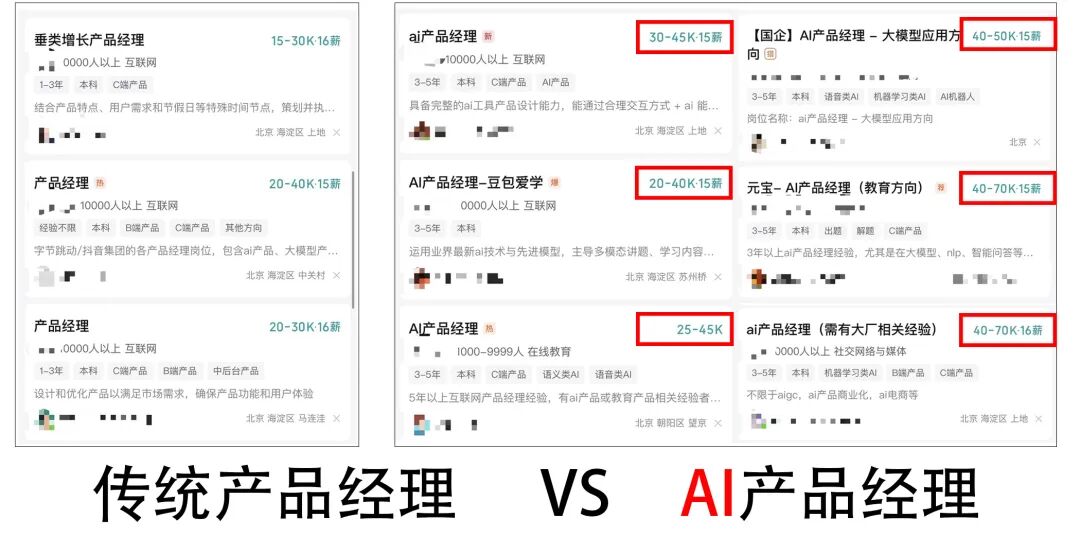
01
接下来的产品人,得卷AI能力了!
如今AI大火,行业极速发展的背后,懂AI 产品人才却严重稀缺。这不是要你转技术岗,而是要掌握构建 AI 产品的核心方法:
- 如何将你的领域知识,转化为 AI 产品的核心竞争力?
- 如何用 AI 技术实现你的产品需求?
- 如何设计真正懂用户的 AI 交互体验?
- ……
懂AI,就是产品经理的“救命稻草”!
风口之下,与其焦虑被行业淘汰
不如先人一步享受AI技术带来的红利!
我把AI产品经理的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

(不限年龄!不限岗位!没有代码基础也能学!)
🎁现在扫码,完课还送:
《AI产品面试题库》《AI大模型应用案例集》
02
掌握技术+实战,快速转型!
想成为一名卓越的AI大模型产品经理,需要从技术、到项目实战的全方位转型指南!
**1)**AI产品应用原理解析,产品经理也能听懂!
对于产品经理来说,如果你不懂技术,做不了业务和AI大模型技术衔接、定义不了数据需求,是没法完整的落地一个产品的!
本次课程,专门面向产品经理人群,解析当下最热门的AI产品应用的必备的「大模型」、「多模态」的实际应用和算法原理!解析AI产品应用技术,积累大模型能力!简单易懂,不需要会代码,小白也能掌握!
- 大模型微调:掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。学习如何利用领域数据(如制造、医药、金融等)进行模型定制
- AI Agent智能体搭建:学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。构建垂类场景下的智能助手产品(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)
2)超全行业案例解析!
课程详细讲解现阶段,大模型在各个行业和领域的应用现状!包括:零售与电商、教育、医疗、泛娱乐、法律等等10大行业!
详细讲解案例的思路、应用场景,以及背后的技术原理、核心技术!揭秘各个行业、场景的真实现状,和未来产品的发展与机遇!
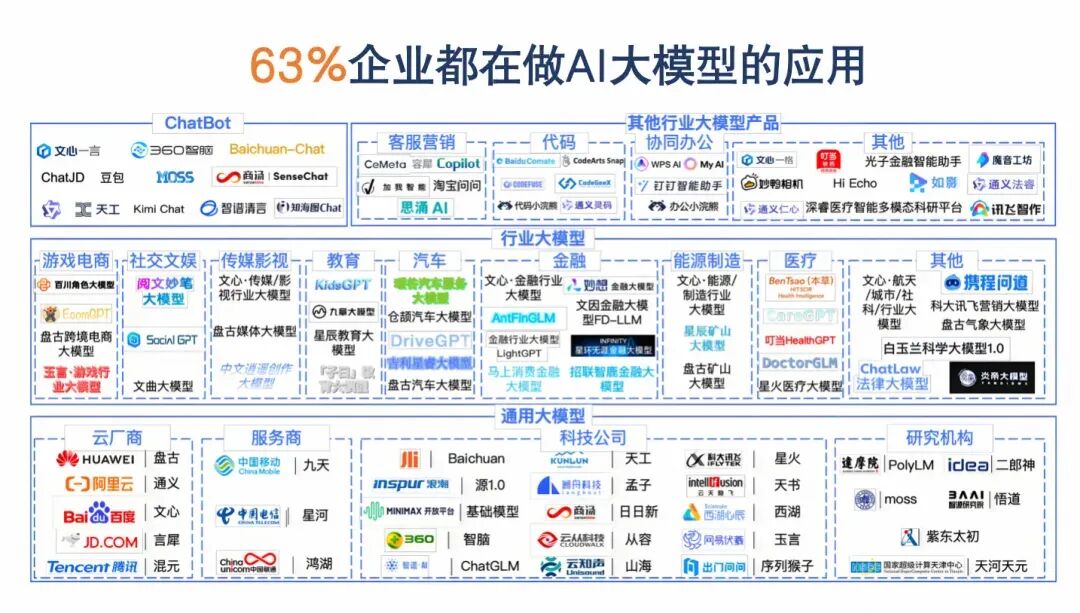
可以说,讲解完一个案例,就能积累一个AI产品实践的经验!
课程中所涉及到的实战项目,都可以直接在自己的工作中使用,让自己的产品/项目有可借鉴的成功案例!
3)AI产品经理求职专项辅导
课程中会系统的帮助大家拆解字节、腾讯、百度等大厂AI PM岗位JD关键词,掌握AI PM高频面试题型与回答框架;展示 AI 相关能力的关键技巧:Prompt设计、模型评估、A/B测试、成本意识、与算法/工程协作经验;
- To B类AI产品经理:突出“行业理解 + 技术落地 + 商业闭环”能力的简历结构设计,展示项目成果;从客户需求洞察到技术方案设计,展现端到产品思维;如何评估To B AI产品的可行性、客户付费意愿与实施成本
- To C类AI产品经理:拆解头部公司岗位JD,将过往尽力转化为AI产品叙事逻辑;从行业趋势、产品设计题、案例分析&数据分析题、技术理解边界等全流程辅导面试;避免无效海投、锁定最适合的AI产品岗位;

03
本次课程,全程直播讲解,能直接对话大佬和专业助教,不懂就问,超详细的案例,小白也能轻松get!
完课后,还赠送《AI产品经理面试题库》、《AI大模型应用案例集》!不断更新中……

适合人群:
- 想转型AI产品经理、AI项目管理专家、AI产品解决方案等岗位
- 想进行AI产品创业的创业者
- 想成为制作AI产品的程序员
- 想利用AI解决企业问题的管理岗
- 想在AI方向寻找就业方向的毕业生
- AI方向前景广阔、待遇好!
目前,很多产品人已经通过完整学习拿到大厂高薪offer,收入嗷嗷涨!
我把AI产品经理的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 8
8 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)