
LLM如何“思考”与“行动”,揭秘AI Agent的底层逻辑与进化之路!
现代语言模型(LLM)通过自回归语言建模方式,在海量文本数据中学习并压缩人类语言模式与知识。Transformer架构,特别是Decoder-Only变体,赋予模型全局上下文感知和长程推理能力。指令微调(SFT)与对齐(如DPO)技术使模型理解指令、进行推理和自我检查。然而,LLM存在知识滞后、幻觉、无法调用工具、缺乏长期记忆和规划能力等硬伤,这些缺陷催生了AI Agent框架,通过集成工具调用、
现代语言模型(LLM)通过自回归语言建模方式,在海量文本数据中学习并压缩人类语言模式与知识。Transformer架构,特别是Decoder-Only变体,赋予模型全局上下文感知和长程推理能力。指令微调(SFT)与对齐(如DPO)技术使模型理解指令、进行推理和自我检查。然而,LLM存在知识滞后、幻觉、无法调用工具、缺乏长期记忆和规划能力等硬伤,这些缺陷催生了AI Agent框架,通过集成工具调用、记忆模块、ReAct循环和多Agent协作,赋予模型感知、行动、记忆和规划能力,使LLM从“大脑”进化为具备完整“身体”的智能体。

本节我们从最基础的地方讲起:现代语言模型(LLM)到底是怎么工作的,它为什么能“懂那么多东西”,又为什么它本身还不够,必须加上Agent的框架才能真正“活起来”。
理解这些内容后,再去看ReAct、Plan-and-Execute、多Agent团队时,就会觉得“原来是这么一回事”。
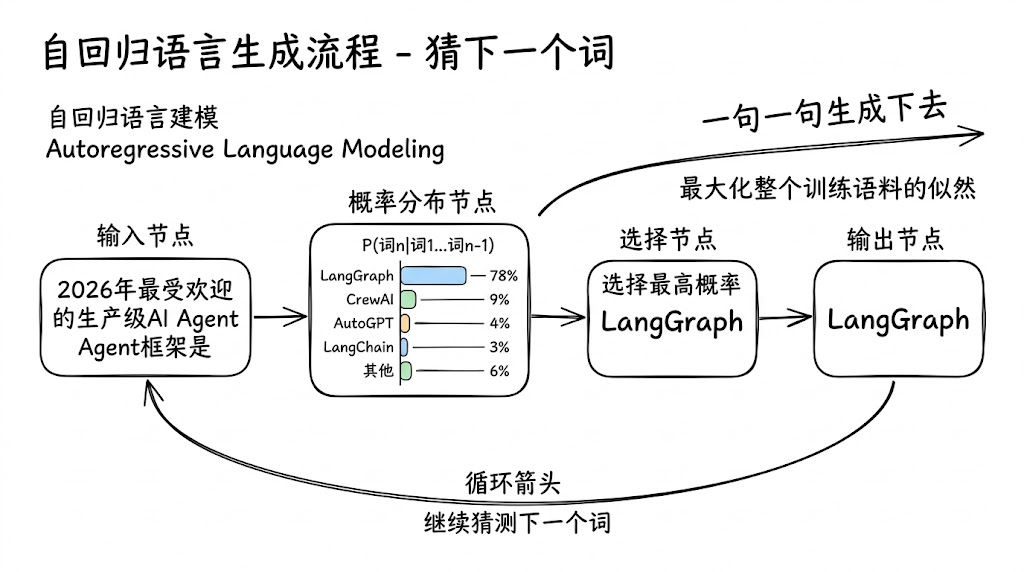
1. 语言模型最基本的工作方式:猜下一个词
所有的现代大语言模型(GPT系列、Claude、Llama、Qwen、Gemma、Grok……)在最底层做的事其实只有一件:
看到前面这些词,猜下一个词最可能是什么。
举个例子:
已经出现的文字是:
“2026年最受欢迎的生产级AI Agent框架是”
模型接下来会给出一串概率最高的候选词,比如:
- • LangGraph …… 78%
- • CrewAI ……… 9%
- • AutoGPT ……… 4%
- • LangChain …… 3%
- • 其他 ………… 6%
然后它通常选概率最高的那个(或者用一点随机性来增加多样性),输出“LangGraph”,接着再继续猜下一个词……就这样一句一句生成下去。
这个“猜下一个词”的训练方式叫自回归语言建模(Autoregressive Language Modeling),核心数学目标是最大化整个训练语料的似然:
P(整个句子) = P(词1) × P(词2|词1) × P(词3|词1词2) × ……
模型就是在海量文本上反复练习这个“填空游戏”,练到最后,它就“记住”了人类语言的几乎所有模式、事实、逻辑、写作风格。
2. 为什么它能“知道”那么多知识?
很多人觉得奇怪:模型只是猜下一个词,怎么会知道“香港是特别行政区”“E=mc²”“LangGraph比AutoGPT更适合生产”这些事?
答案在于规模 + 压缩。
- • 训练数据量极大:2026年主流模型预训练数据通常在15万亿~50万亿个token之间,相当于让模型把人类互联网上公开的大部分文字都“读”了一遍又一遍。
- • 知识被高度压缩进权重里:模型并没有一个“知识库文件夹”,而是把所有事实、关系、规律都分散编码在了几百亿到几千亿个参数(权重)中。
- • 当你问它问题时,它并不是去查表,而是通过注意力机制瞬间把相关的几百万个权重“点亮”,重新“计算”出最符合上下文的答案。
所以LLM的知识不是“背下来的”,而是统计学意义上的模式压缩。这也是为什么它有时会“胡说八道”(幻觉):当模式匹配出错或训练数据有噪声时,它会自信地输出错误的但“看起来很合理”的内容。

3. Transformer:现代LLM的“心脏”架构
2017年的论文《Attention is All You Need》彻底改变了AI领域。从那以后,几乎所有强大的语言模型都用了Transformer架构,而且在Agent领域,几乎100%都是Decoder-Only变体。
简单来说,Transformer 是一个非常聪明的“阅读 + 写作”机器,它能同时看整段文字,快速搞清楚哪些词对当前词最重要,然后据此生成下一个词。
因此 Transformer 由两大部分组成,像一个“翻译工厂”:
- • Encoder(编码器):负责把输入句子“理解”成一组丰富的表示向量(常用于BERT类模型)。
- • Decoder(解码器):负责根据Encoder的输出,一步步生成目标句子(常用于机器翻译)。
但在现代生成式LLM(也就是我们用来做Agent的那些模型)中,只保留了Decoder部分,这就是Decoder-Only架构。
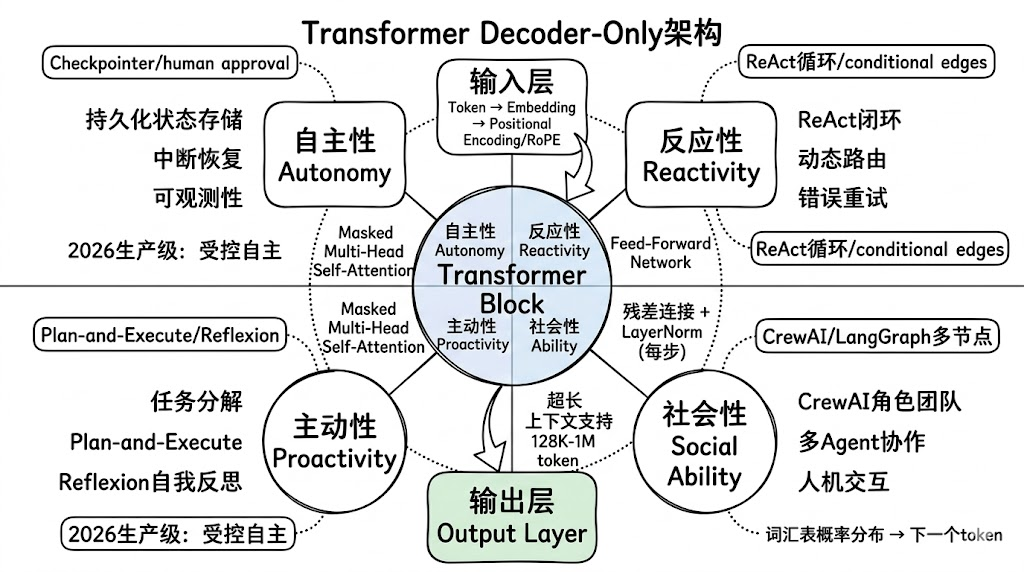
为什么只用Decoder?因为Agent最需要的就是“从左到右、一步步生成思考和行动”的能力,而Encoder-Decoder更适合“输入A → 输出B”的固定映射任务(如翻译、摘要),对开放式生成和长对话不够灵活。
Decoder-Only架构的内部结构(从输入到输出的完整流程):
-
- 输入层
把文字切成token → 转成数字向量(Embedding)→ 加上位置信息(Positional Encoding / RoPE)。
- 输入层
-
- 多层Transformer Block(最核心部分,每层都重复以下步骤)
- ◦ Masked Multi-Head Self-Attention(带掩码的多头自注意力)
每个token同时“看”它前面所有token(但不能偷看后面的词),计算它们对自己的重要性。
公式简写版:
Attention = softmax( (Q × K^T) / √d ) × V
多头就是把这个过程平行做几次,从不同角度关注上下文。 - ◦ Feed-Forward Network(前馈网络)
每个token独立经过一个小型神经网络,做更深层的特征变换(类似“深度思考”)。 - ◦ 残差连接 + LayerNorm
每步都把原始输入加回去(残差),再做归一化,防止梯度消失,让模型能堆到几十上百层。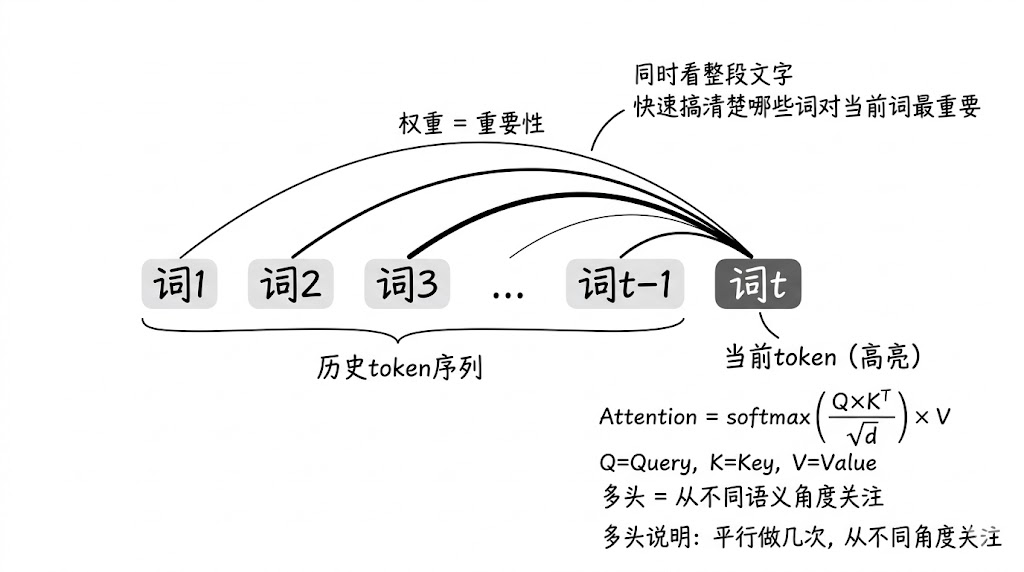
-
- 输出层
最后一层输出一个巨大的词汇表概率分布,选出下一个token。
- 输出层
为什么这个结构特别适合Agent?
- • 全局上下文感知:注意力让模型能同时看到整个历史对话、工具返回、规划步骤。
- • 超长上下文支持:2026年主流模型已轻松处理128K–1M token,这意味着Agent可以把几天前的记忆、多次工具调用结果全部塞进去继续思考。
- • 自回归生成天然匹配Agent循环:每生成一个token都是在“思考下一步”,完美契合ReAct的“Thought → Action → Observation”循环。
- • 涌现能力最强:几乎所有零样本推理、Chain-of-Thought、自我反思等能力,都是在Decoder-Only模型上最先爆发并被广泛验证的。
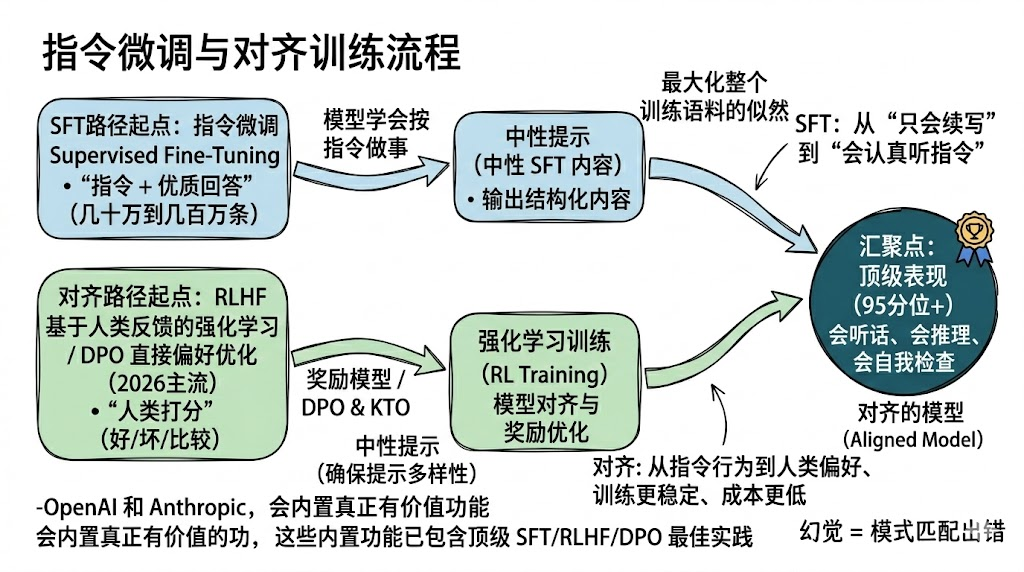
4. 从“只会续写”到“会听话、会思考”:指令微调与对齐
光有Transformer还不够,预训练完的模型只会“续写最顺的文字”,不会听你指令,也不会认真思考。
所以后面还有两步关键训练:
-
- 指令微调(SFT)
收集几十万到几百万条“人类指令 + 优质回答”的数据,让模型专门练习“按照指令做事”。
比如输入:“用表格总结2026年主流Agent框架的优缺点”,模型学会输出结构化的表格,而不是随便续写。
- 指令微调(SFT)
-
- 对齐(RLHF)
- ◦ 先给它看一大堆“好学生范文”(指令+标准答案),让它模仿。
- ◦ 让它自己写几篇作文,找一群人类老师来打分:这篇好、那篇烂、这篇比那篇强。
- ◦ 训练一个专门的“评分机器人”(奖励模型),学会跟人类老师一样打分。
- ◦ 再用强化学习(像训练游戏AI那样),让模型不停写作文 → 评分机器人打高分就奖励,低分就惩罚 → 模型慢慢学会“写出人类爱看的作文”。
2026年的主流对齐技术已经从RLHF转向更高效的 DPO 和 KTO (直接告诉告诉它写的好与不好, 省略模仿、对比、打分过程)和其变体,训练更稳定、成本更低。
正是这两步,让模型从“只会续写”变成了“会认真听指令、会步步推理、会自我检查”。
5. LLM的硬伤,也是Agent诞生的根本原因
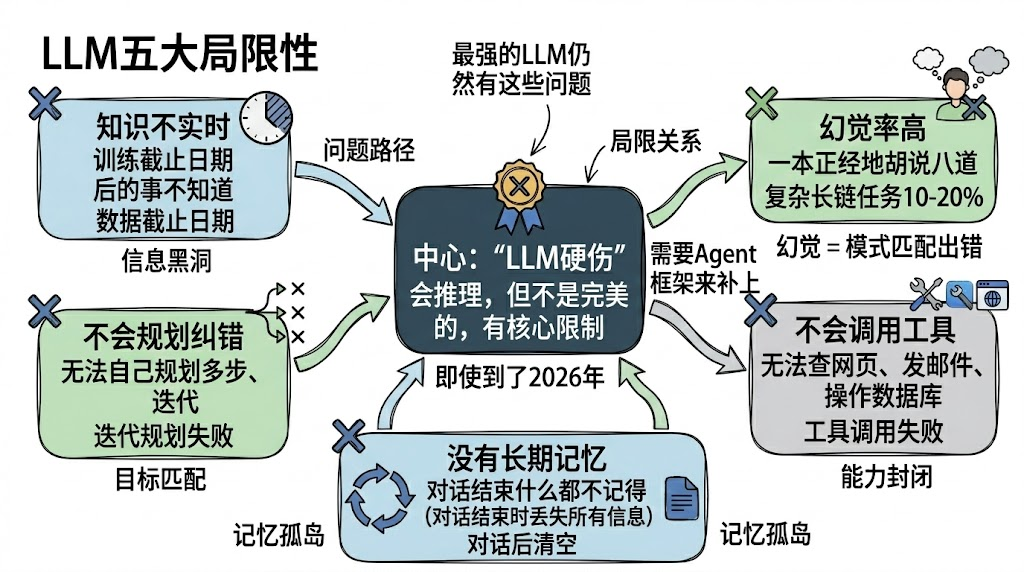
即使到了2026年,最强的LLM仍然有几个致命问题:
- • 知识不是实时的(训练截止日期以后的事它不知道)
- • 会一本正经地胡说八道(幻觉率在复杂长链任务中仍可达10–20%)
- • 不会主动调用工具、查网页、操作电脑
- • 没有长期记忆(一次对话结束后什么都不记得)
- • 不会自己规划多步、迭代纠错
Agent框架的全部意义,就是把这些硬伤一个个补上:
- • 用工具调用让它能查实时信息、发邮件、操作数据库
- • 用记忆模块(向量数据库 + Checkpointer)让它记住历史
- • 用ReAct / Plan-and-Execute / Reflection循环让它能多轮思考、纠错、规划
- • 用多Agent协作让复杂任务分解给专业角色
一句话总结:
LLM是大脑,提供了强大的语言理解、知识储备和推理能力;
Agent是完整身体,给了它眼睛(感知)、手脚(行动)、记忆、规划回路和团队协作能力。
两者缺一不可。
小结
这一节我们从最基础的“猜下一个词”讲起,一路看到了:
- • 自回归训练如何让模型压缩海量知识
- • Transformer(特别是Decoder-Only)如何实现真正的上下文理解和长程推理
- • 指令微调 + DPO对齐如何让模型听话、会思考
- • LLM的硬伤最终如何催生了现代Agent架构
掌握这些原理后,你再去看后续的感知模块、记忆模块、ReAct循环、多Agent团队时,就会发现它们其实都是在围绕LLM这个“大脑”做扩展和补短板。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
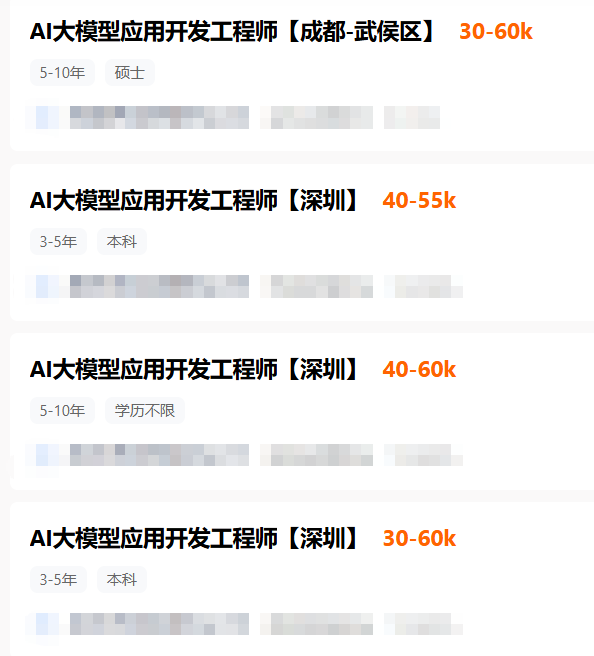
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 7
7 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)