
制约 OpenClaw 最关键的不是框架,而是 LLM 本身
本文探讨了当前LLM(大语言模型)在构建OpenClaw等Agent系统时面临的三大核心瓶颈。首先分析了"用语言理解替代控制流"带来的本质限制,指出最制约系统上限的三大问题:长上下文中的注意力退化、跨步骤状态一致性不足,以及校准能力("我不确定"表达)的缺失。文章详细阐述了每个瓶颈的具体表现和工程缓解方案,如结构化状态对象传递、关键信息显式提醒等,同时强调这
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
你认为当前LLM哪些能力瓶颈最制约OpenClaw的上限?
一、核心问题:用语言理解替代控制流
给LLM包执行力,本质上是在用LLM的语言理解能力替代传统软件的控制流逻辑。这在短任务、明确场景下效果惊人,但在长任务、复杂场景下会遭遇几道明显的天花板——不是OpenClaw框架设计得不好,而是LLM本身当前的能力边界决定的。
说人话就是: 想象你让一个记忆力超强但没有长期规划能力的朋友帮你处理复杂事务。他能完美执行每一个单独的指令,但当任务链条变长、情况变复杂时,他可能会忘记之前的约束、对同一个概念产生不同的理解,或者在不确定时强行给出答案而不是问你确认。
最制约OpenClaw上限的瓶颈,按严重程度排列是:
- 长上下文中的注意力退化
- 跨步骤的状态一致性
- 对"我不确定"的校准能力(calibration)
前两个是工程可部分缓解的,第三个是当前LLM最根本的局限,也是Agent出错最难察觉的根源。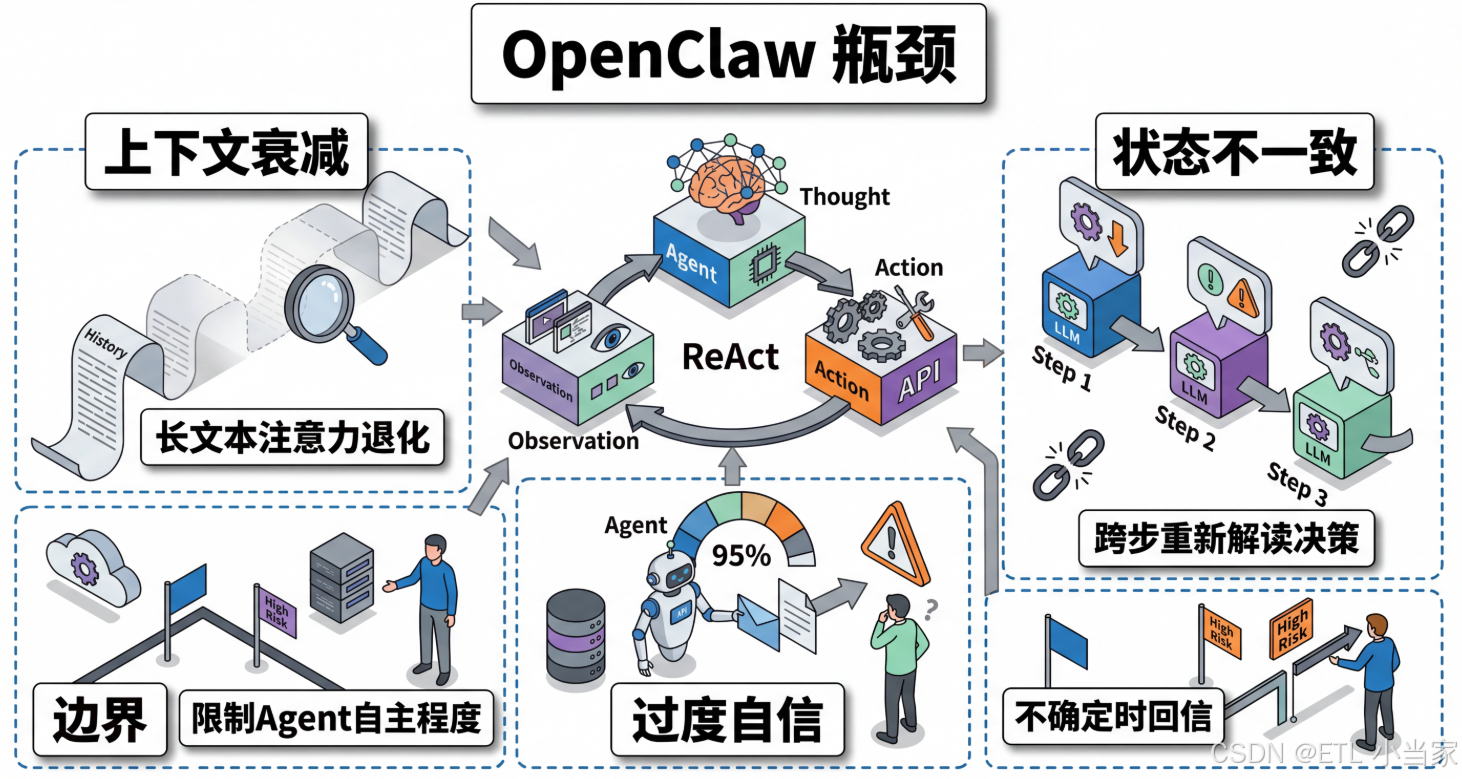
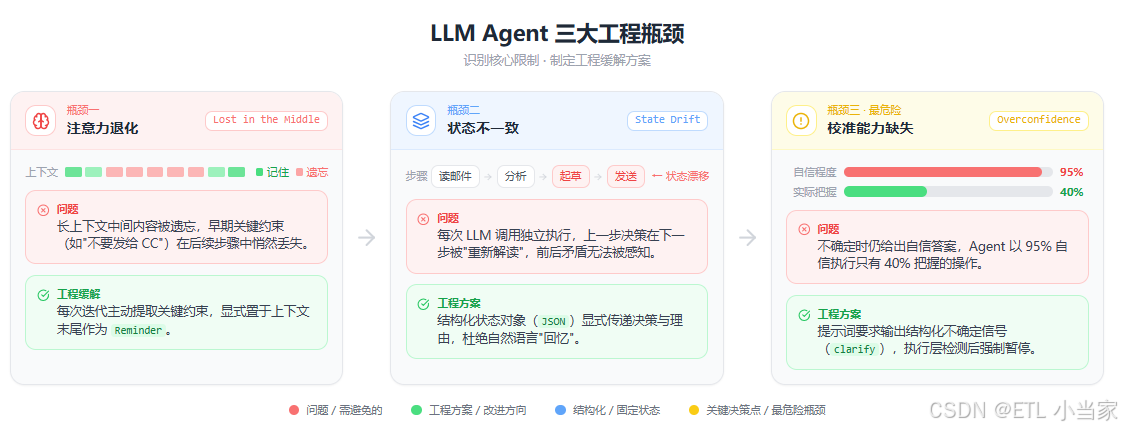
二、瓶颈一:长上下文注意力退化
LLM的上下文窗口越来越大(GPT-4o 128K,Claude 3.5 200K),但"能装进去"和"能有效利用"是两回事。大量研究表明,LLM对上下文的注意力分布不均匀——靠近开头和结尾的内容被更好地记住,中间的内容容易被忽略,这个现象叫"lost in the middle"。
对OpenClaw的实际影响
一个运行了几十轮的ReAct循环,早期步骤里获取到的关键信息(比如用户说过"不要发给CC里的人")可能在后续步骤里被遗忘,Agent照样执行了用户明确说过不要的操作。
工程缓解方案
在每次ReAct循环迭代时,主动把关键约束提取出来放到上下文末尾(“reminder”),而不是依赖LLM自己在长上下文中找到它。
// 不好的做法:依赖LLM在长上下文中找到早期约束
const context = [...longHistory, currentTask];
// 好的做法:显式提取关键约束放在末尾
const keyConstraints = extractKeyConstraints(longHistory);
const context = [...recentHistory, {constraints: keyConstraints}, currentTask];
但这只是治标,不是治本——我们只是在适应LLM的弱点,而不是解决了问题。
三、瓶颈二:跨步骤状态一致性
一个多步骤任务(比如:读邮件 → 分析优先级 → 起草回复 → 发送)里,每一步都是一次独立的LLM调用。LLM不是一个有持久状态的程序——它每次都是从上下文里重新"理解"当前情况,而不是在内存里修改一个变量。
导致的问题
上一步的决策在下一步可能被"重新解读"。步骤三起草回复时,LLM可能对"高优先级"的定义和步骤二略有不同,导致实际发送的内容和分析结论不一致。
对人类来说,"前后矛盾"是明显的错误信号;对LLM来说,每次调用都是独立的,没有"前后"的概念。
工程解决方案:结构化状态对象
把关键决策显式存储为机器可读的状态,而不是让LLM从自然语言里"回忆"上一步说了什么:
| 方法 | 描述 | 效果 |
|---|---|---|
| 自然语言记忆 | 让LLM从对话历史里"记住"上一步的判断 | 容易出现重新解读,状态不一致 |
| 结构化状态 | 把关键状态显式传入下一步 | 确保状态一致性,减少歧义 |
// 好的做法:结构化状态传递
const taskState = {
step: 'draft_reply',
context: {
email: { from: '...', subject: '...', body: '...' },
priority: 'high', // 上一步的决策,显式传入
priorityReason: '涉及合同截止日期', // 连同理由一起传,避免重解读
constraints: ['不要提及价格细节', '不要 CC 给 BD 团队'],
}
};
四、瓶颈三:Calibration——"我不确定"的能力
这是最被低估、也最危险的瓶颈。LLM在不确定的时候,不会说"我不确定",而是会给出一个听起来自信的答案。
在Agent场景下的致命后果
这种过度自信(overconfidence)在聊天场景下只是体验问题,但在Agent场景下会直接导致错误操作被执行——Agent以95%的自信去做了一件它其实只有40%把握做对的事情。
具体体现为:
- 面对歧义的用户指令时,Agent倾向于自行选择一种解读然后继续执行
- 面对工具调用失败时,Agent可能尝试用其他方式绕过,而不是承认"这件事我做不到"
- 在边界场景下,Agent会强行给出一个答案,而不是说"我没有足够的信息做出判断"
启发式缓解方案
在提示词里明确要求Agent在不确定时输出结构化的不确定信号,然后在执行层检测到这个信号时强制暂停:
// 在Brain的系统提示里加入明确要求
const SYSTEM_PROMPT = `
...
When you are uncertain about the user's intent or how to proceed,
output exactly: {"action": "clarify", "question": "<your question>"}
Do NOT guess. Do NOT proceed with a plausible interpretation without flagging it.
...`;
// 执行层检测不确定信号
function handleBrainOutput(output) {
if (output.action === 'clarify') {
sendToUser(`❓ ${output.question}`);
pauseTask(); // 等待用户回应
} else {
executeAction(output);
}
}
五、这些瓶颈意味着什么?
三个瓶颈合在一起,勾勒出当前Agent的能力边界:
| 任务特征 | 出错概率 | 原因 |
|---|---|---|
| 短任务、明确场景 | 低 | LLM优势领域 |
| 长任务、模糊场景 | 高 | 三大瓶颈叠加 |
| 高风险操作 | 极高 | 错误往往是静默的 |
任务越长、步骤越多、场景越模糊,出错概率越高;而且出错往往是静默的,Agent会带着错误继续执行,直到最终结果明显不对。
这不是说Agent现在没用——短任务、明确场景下OpenClaw的效果已经让很多人觉得"超乎想象"。但对于真正的高风险长任务(财务操作、法律文件处理、复杂的多方沟通),当前LLM的这三个瓶颈决定了Agent还不能完全替代人类判断,只能作为"能力放大器"而不是"全权代理人"。
核心结论
LLM能力的天花板,就是Agent自主程度的天花板。
这道墙会随着模型迭代慢慢上移,但在它真正消失之前,好的Agent设计应该始终假设LLM会犯错,并在架构层面为此做好准备——就像优秀的软件工程师永远不会假设网络永远可靠一样。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 16
16 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)