小白程序员必备:收藏这份大模型智能体实战指南,轻松掌握AI自动化核心技能
函数调用是大型语言模型 (LLM) 与工具交互的主要方式。经常会看到“函数”和“工具”互换使用,因为“函数”(可重用代码块)是智能体用来执行任务的“工具”。工具通过使用底层应用程序或系统的 API 来扩展智能体的功能。对于没有 API 的旧系统,智能体可以依赖computer-use模型,像人一样通过 Web 和应用程序 UI 直接与这些应用程序和系统交互。每个工具都应具有标准化的定义,从而实现工
本文介绍了如何利用大模型构建智能体以自动化复杂工作流程。内容涵盖智能体的核心组件(模型、工具、指令)、设计方法、编排模式(主管模式和群体模式)以及实际应用中的挑战与应对策略。此外,还提供了构建可扩展AI智能体的路线图,包括选择合适的LLM、设计推理过程、制定操作指南、集成工具与API等关键步骤,旨在帮助读者理解和应用大模型智能体技术。
一、引言
在评估agent可以在哪些方面发挥价值时,应优先考虑以前难以实现自动化的工作流程,尤其是在传统方法不太好解决的情况下:
-
复杂决策: 涉及细致判断、例外情况或情境敏感决策的工作流程,例如客户服务工作流程中的退款批准;
-
难以维护的规则: 由于规则集庞大而复杂,导致系统变得难以管理,例如,执行供应商安全审查时,更新成本高昂或容易出错;
-
严重依赖非结构化数据: 例如,处理房屋保险索赔,涉及解释自然语言、从文档中提取含义或与用户进行对话式交互的场景。
在构建agent之前,请务必确认您的用例能够明确满足这些标准。否则,传统方案可能就足够了。
二、智能体设计组件
一般来看,智能体由三个核心组件构成:
- Model: LLM 为智能体的推理和决策提供支持;
- Tools: 智能体可以用来执行操作的外部函数或 API;
- Instructions: 明确定义智能体行为方式的指导方针和规则。
2.1 选择模型
不同的模型在任务复杂性、延迟和成本方面各有优劣。并非所有任务都需要最智能的模型——简单的检索或意图分类任务可能由更小、更快的模型处理,而像决定是否批准退款这样更复杂的任务则可能需要功能更强大的模型。
一个行之有效的方法是,首先使用功能最强大的模型构建智能体原型,以此建立每个任务的性能基准。然后,尝试替换为功能较弱的模型,观察它们是否仍能达到可接受的结果。这样,既不会过早限制智能体的能力,又能诊断出功能较弱的模型在哪些方面表现良好,在哪些方面表现不佳。
2.2 定义工具
函数调用是大型语言模型 (LLM) 与工具交互的主要方式。经常会看到“函数”和“工具”互换使用,因为“函数”(可重用代码块)是智能体用来执行任务的“工具”。
工具通过使用底层应用程序或系统的 API 来扩展智能体的功能。对于没有 API 的旧系统,智能体可以依赖computer-use模型,像人一样通过 Web 和应用程序 UI 直接与这些应用程序和系统交互。每个工具都应具有标准化的定义,从而实现工具和智能体之间灵活的多对多关系。文档完善、经过全面测试且可重用的工具能够提高工具调用的正确率。
总的来说,智能体需要三种类型的工具:
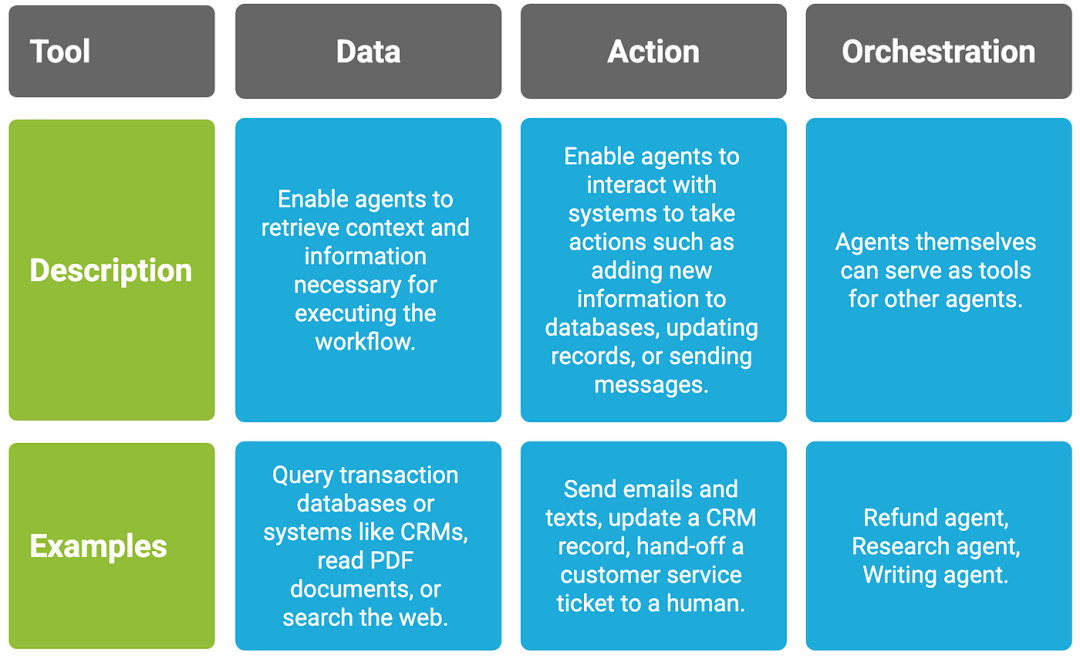
下面是如何使用 Agents SDK 为智能体配备一系列工具的方法:
from agents import Agent, WebSearchTool, function_tool
@function_tool
def save_results(output):
db.insert({"output": output, "timestamp": datetime.time()})
return "File saved"
search_agent = Agent(
name="Search agent",
instructions="Help the user search the internet and save results if asked.",
tools=[WebSearchTool(), save_results],
)
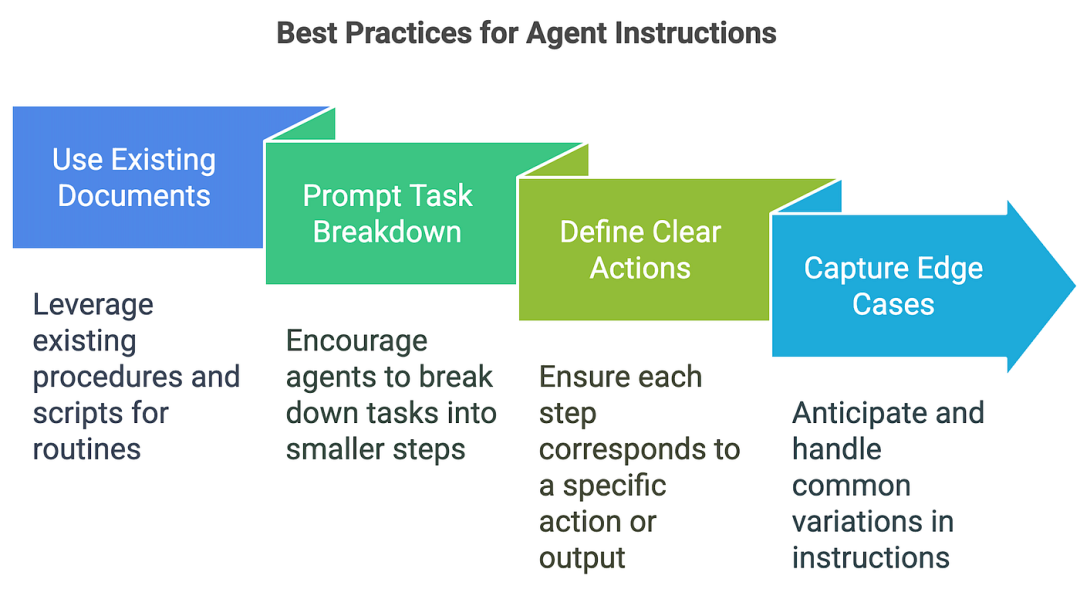
2.3 配置说明
高质量的指令对于任何基于 LLM(学习生命周期管理)的应用都至关重要,尤其对于客服人员而言更是如此。清晰的指令可以减少歧义,提升客服人员的决策能力,从而实现更流畅的工作流程和更少的错误。
三、编排
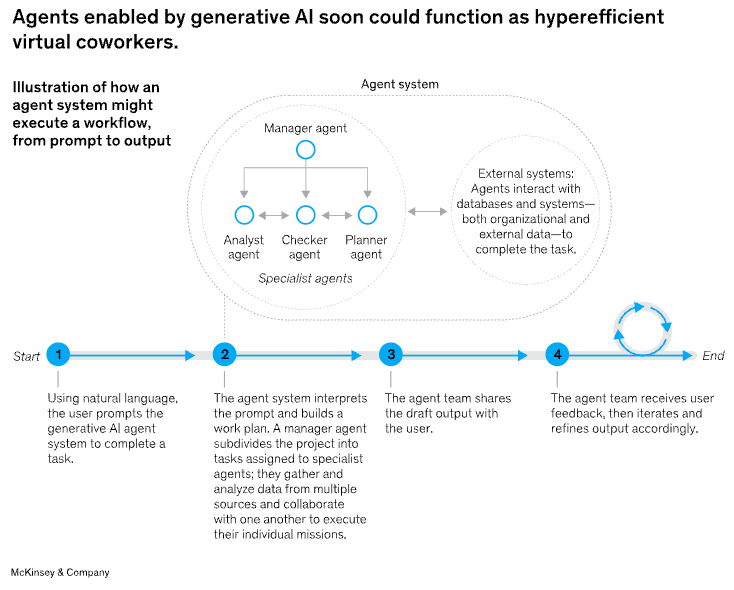
有了基础组件,就可以考虑使用编排模式,使智能体能够有效地执行工作流程。
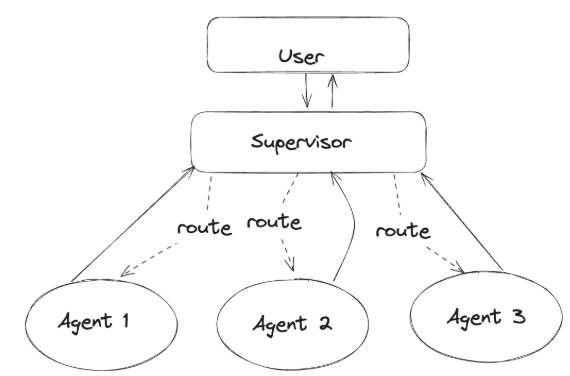
多智能体系统可以建模为图,其中智能体用节点表示。在管理者和监督者模式下,边表示工具调用;而在分散式和群体模式下,边表示智能体之间执行任务的交接。
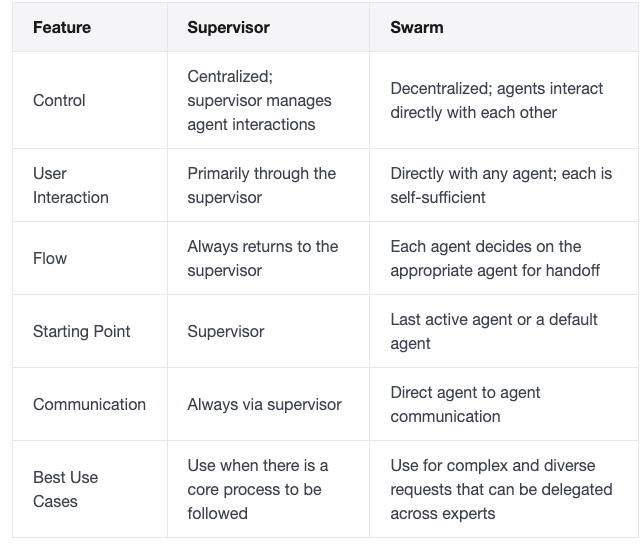
下面是主管模式和群体模式的区别
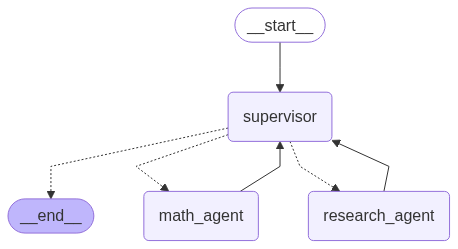
四、主管模式代码实现
创建一个主管智能体来协调多个专业智能体。
pip install langgraph-supervisor langchain-openai
export OPENAI_API_KEY=<your_api_key>
from langchain_openai import ChatOpenAI
from langgraph.graph import START, END
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.prebuilt import create_react_agent
from langgraph_supervisor import create_supervisor
from IPython.display import Image, display
import os
# Select LLM
model = ChatOpenAI(model="gpt-4o", api_key=os.getenv("OPENAI_API_KEY"))
# Define tools
def add(a: float, b: float) -> float:
"""Add two numbers."""
return a + b
def multiply(a: float, b: float):
"""Multiply two numbers."""
return a * b
def divide(a: float, b: float):
"""Divide two numbers."""
return a / b
tavily_api_key = os.getenv("TAVILY_API_KEY", "your_tavily_api_key")
web_search = TavilySearchResults(max_results=3, tavily_api_key=tavily_api_key)
# Create Worker Agents
research_agent = create_react_agent(
model=model,
tools=[web_search],
name="research_agent",
prompt=(
"You are a research agent.\n\n"
"INSTRUCTIONS:\n"
"- Assist ONLY with research-related tasks, DO NOT do any math\n"
"- After you're done with your tasks, respond to the supervisor directly\n"
"- Respond ONLY with the results of your work, do NOT include ANY other text."
)
)
math_agent = create_react_agent(
model=model,
tools=[add, multiply, divide],
name="math_agent",
prompt=(
"You are a math agent.\n\n"
"INSTRUCTIONS:\n"
"- Assist ONLY with math-related tasks\n"
"- After you're done with your tasks, respond to the supervisor directly\n"
"- Respond ONLY with the results of your work, do NOT include ANY other text."
)
)
# Create Supervisor Agent
supervisor_agent = create_supervisor(
model=model,
agents=[research_agent, math_agent],
prompt=(
"You are a supervisor managing two agents:\n"
"- a research agent. Assign research-related tasks to this agent\n"
"- a math agent. Assign math-related tasks to this agent\n"
"Assign work to one agent at a time, do not call agents in parallel.\n"
"Do not do any work yourself."
),
add_handoff_back_messages=True,
output_mode = "full_history",
).compile()
display(Image(supervisor_agent.get_graph().draw_mermaid_png()))
使用 pretty_print_messages 辅助函数来美观地渲染流式代理输出
from langchain_core.messages import convert_to_messages
def pretty_print_message(message, indent=False):
pretty_message = message.pretty_repr(html=True)
if not indent:
print(pretty_message)
return
indented = "\n".join("\t" + c for c in pretty_message.split("\n"))
print(indented)
def pretty_print_messages(update, last_message=False):
is_subgraph = False
if isinstance(update, tuple):
ns, update = update
# skip parent graph updates in the printouts
if len(ns) == 0:
return
graph_id = ns[-1].split(":")[0]
print(f"Update from subgraph {graph_id}:")
print("\n")
is_subgraph = True
for node_name, node_update in update.items():
update_label = f"Update from node {node_name}:"
if is_subgraph:
update_label = "\t" + update_label
print(update_label)
print("\n")
messages = convert_to_messages(node_update["messages"])
if last_message:
messages = messages[-1:]
for m in messages:
pretty_print_message(m, indent=is_subgraph)
print("\n")
测试流程完整代码,请参考:https://t.zsxq.com/yNO6D
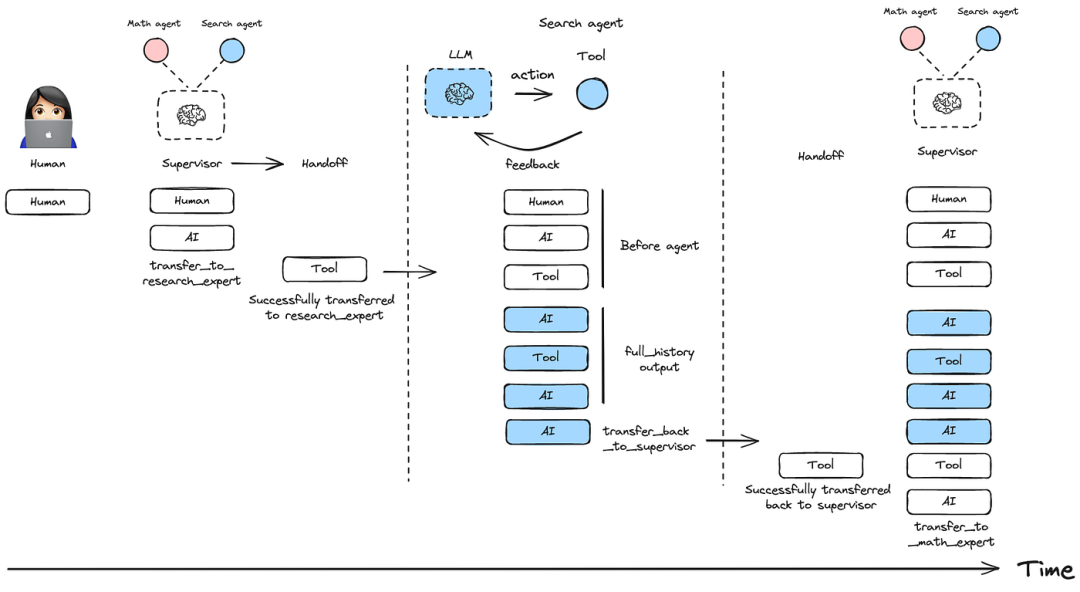
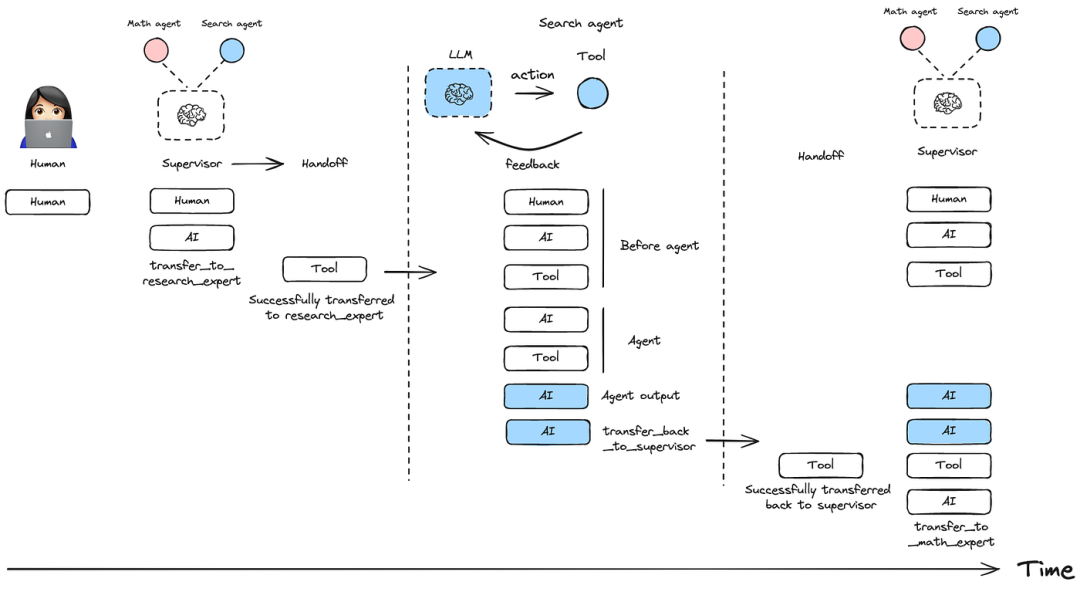
4.1 消息历史记录管理
控制如何将智能体消息添加到多智能体系统的整体对话历史记录中:
a)请提供客服人员的完整邮件历史记录:
supervisor = create_supervisor(
agents=[agent1, agent2],
output_mode="full_history"
)
仅包含最终的智能体回复:
supervisor = create_supervisor(
agents=[agent1, agent2],
output_mode="last_message"
)
4.2 多级层次结构
你可以通过创建一个主管来管理多个主管,从而创建多级层级系统。
research_team = create_supervisor(
[research_agent, math_agent],
model=model,
supervisor_name="research_supervisor"
).compile(name="research_team")
writing_team = create_supervisor(
[writing_agent, publishing_agent],
model=model,
supervisor_name="writing_supervisor"
).compile(name="writing_team")
top_level_supervisor = create_supervisor(
[research_team, writing_team],
model=model,
supervisor_name="top_level_supervisor"
).compile(name="top_level_supervisor")
4.3 定制交接工具
默认情况下,管理程序使用预置的 create_handoff_tool 创建的交接工具。您也可以创建自己的自定义交接工具。以下是一些修改默认实现的思路:
- 更改工具名称和/或描述;
- 为 LLM 添加工具调用参数以进行填充,例如下一个代理的任务描述;
- 更改作为交接的一部分传递给子智能体的数据:默认情况下, create_handoff_tool 会传递完整的消息历史记录(到目前为止在 supervisor 中生成的所有消息),以及指示交接成功的工具消息。
以下是如何将自定义交接工具传递给 create_supervisor 示例:
from langgraph_supervisor import create_handoff_tool
workflow = create_supervisor(
[research_agent, math_agent],
tools=[
create_handoff_tool(agent_name="math_expert", name="assign_to_math_expert", description="Assign task to math expert"),
create_handoff_tool(agent_name="research_expert", name="assign_to_research_expert", description="Assign task to research expert")
],
model=model,
)
还可以控制是否将交接工具调用消息添加到状态中。默认情况下会添加( add_handoff_messages=True ),但如果想要更简洁的历史记录,可以禁用此功能:
workflow = create_supervisor(
[research_agent, math_agent],
model=model,
add_handoff_messages=False
)
此外,您还可以自定义自动生成的交接工具所使用的前缀:
workflow = create_supervisor(
[research_agent, math_agent],
model=model,
handoff_tool_prefix="delegate_to"
)
# This will create tools named: delegate_to_research_expert, delegate_to_math_expert
智能体自定义交接工具的完整示例,请查看:https://t.zsxq.com/s96sN
4.4 消息转发
可以使用 create_forward_message_tool 为管理者配备一个工具,使其能够将从worker agent收到的最后一条消息直接转发到图的最终输出。当管理者判断worker agent的响应已足够,无需进一步处理或总结时,此功能非常有用。它能为管理者节省令牌,并避免因改述而导致对worker agent响应的潜在误解。
from langgraph_supervisor.handoff import create_forward_message_tool
# Assume research_agent and math_agent are defined as before
forwarding_tool = create_forward_message_tool("supervisor") # The argument is the name to assign to the resulting forwarded message
workflow = create_supervisor(
[research_agent, math_agent],
model=model,
# Pass the forwarding tool along with any other custom or default handoff tools
tools=[forwarding_tool]
)
创建一个名为 forward_message 工具,供主管调用。该工具需要一个参数 from_agent 用于指定哪个智能体的最后一条消息应该直接转发到输出端。
五、群体模式代码实现
下面是一个使用 langgraph_swarm 库实现群聚式多智能体系统的示例代码,该库基于 LangGraph 构建,以实现专业智能体之间的动态协作和交接。
我们将沿用与主管模式中相同的数学智能体和研究智能体的例子,完整的代码,请查看:https://t.zsxq.com/coCkC
六、运行智能体
6.1 Invoking调用模式
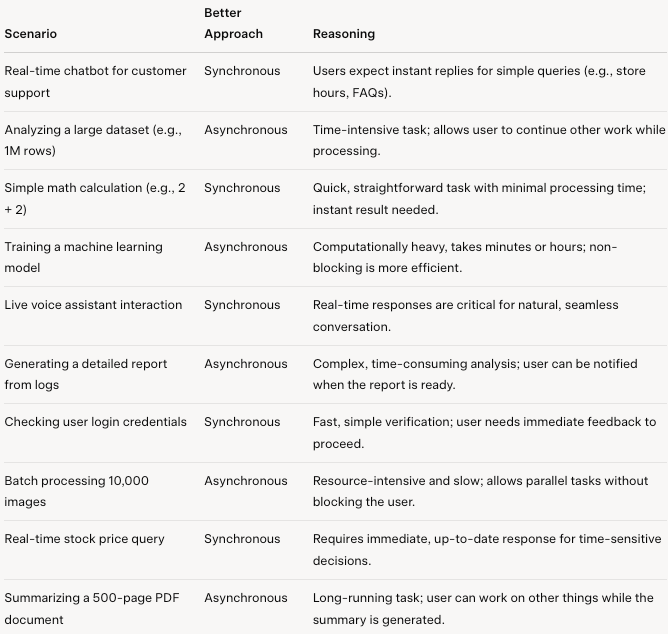
智能体运行方式主要有以下两种模式:
-
使用 .invoke() 或 .stream() 进行同步 :调用者(用户或系统)等待智能体完成其任务后再继续执行;
-
使用 await .ainvoke() 或 async for with .astream() 进行异步操作 :智能体接收请求后,启动处理,并允许调用者继续执行其他任务,而无需等待响应。结果稍后会返回,通常通过回调、通知或轮询机制。
同步调用:
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(...)
response = agent.invoke({"messages": [{"role": "user", "content": "what is the weather in sf"}]})
异步调用:
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(...)
response = await agent.ainvoke({"messages": [{"role": "user", "content": "what is the weather in sf"}]})
6.2 输入格式
智能体使用 messages 列表作为输入。因此,智能体的输入和输出以 messages 列表的形式存储在智能体状态的 messages 键下。
可以直接在输入字典中提供智能体状态模式中定义的其他字段。这样就可以根据运行时数据或先前的工具输出实现动态行为。
智能体输入必须是一个包含 messages 键的字典。支持的格式有:
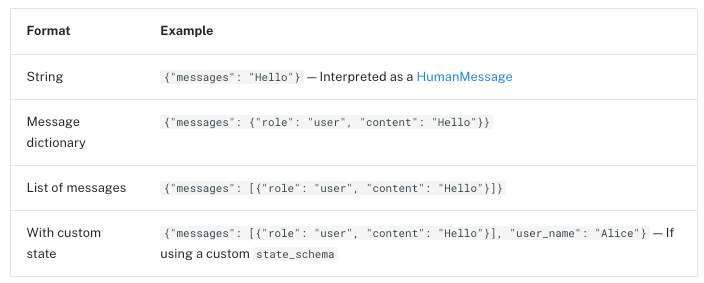
注意: messages 的字符串输入会被转换为 HumanMessage 对象。这与 create_react_agent 中的 prompt 参数不同,后者在作为字符串传递时会被解释为 SystemMessage 对象。
6.3 输出格式
智能体输出是一个字典,包含以下内容:
-
messages : 执行过程中交换的所有消息列表(用户输入、助手回复、工具调用);
-
如果配置了结构化输出 ,则可选择使用 structured_response;
-
如果使用自定义 state_schema ,输出中可能还会用户自定义字段对应的其他键。这些键可以保存工具执行或提示逻辑更新后的状态值。
6.4 流式输出
智能体支持流式输出,从而提升应用程序的响应速度。流式输出支持同步和异步两种模式。
同步流式输出:
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]},
stream_mode="updates"
):
print(chunk)
异步流式输出:
async for chunk in agent.astream(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]},
stream_mode="updates"
):
print(chunk)
6.5 最大迭代次数
我们可以在运行智能体时定义最大迭代次数,也可以在定义智能体时通过 .with_config() 定义它:
运行时定义:
from langgraph.errors import GraphRecursionError
from langgraph.prebuilt import create_react_agent
max_iterations = 3
recursion_limit = 2 * max_iterations + 1
agent = create_react_agent(
model="anthropic:claude-3-5-haiku-latest",
tools=[get_weather]
)
try:
response = agent.invoke(
{"messages": [{"role": "user", "content": "what's the weather in sf"}]},
{"recursion_limit": recursion_limit},
)
except GraphRecursionError:
print("Agent stopped due to max iterations.")
.with_config():
from langgraph.errors import GraphRecursionError
from langgraph.prebuilt import create_react_agent
max_iterations = 3
recursion_limit = 2 * max_iterations + 1
agent = create_react_agent(
model="anthropic:claude-3-5-haiku-latest",
tools=[get_weather]
)
agent_with_recursion_limit = agent.with_config(recursion_limit=recursion_limit)
try:
response = agent_with_recursion_limit.invoke(
{"messages": [{"role": "user", "content": "what's the weather in sf"}]},
)
except GraphRecursionError:
print("Agent stopped due to max iterations.")
七、面临的挑战
协调多个智能体所面临的挑战,以下几点值得牢记:
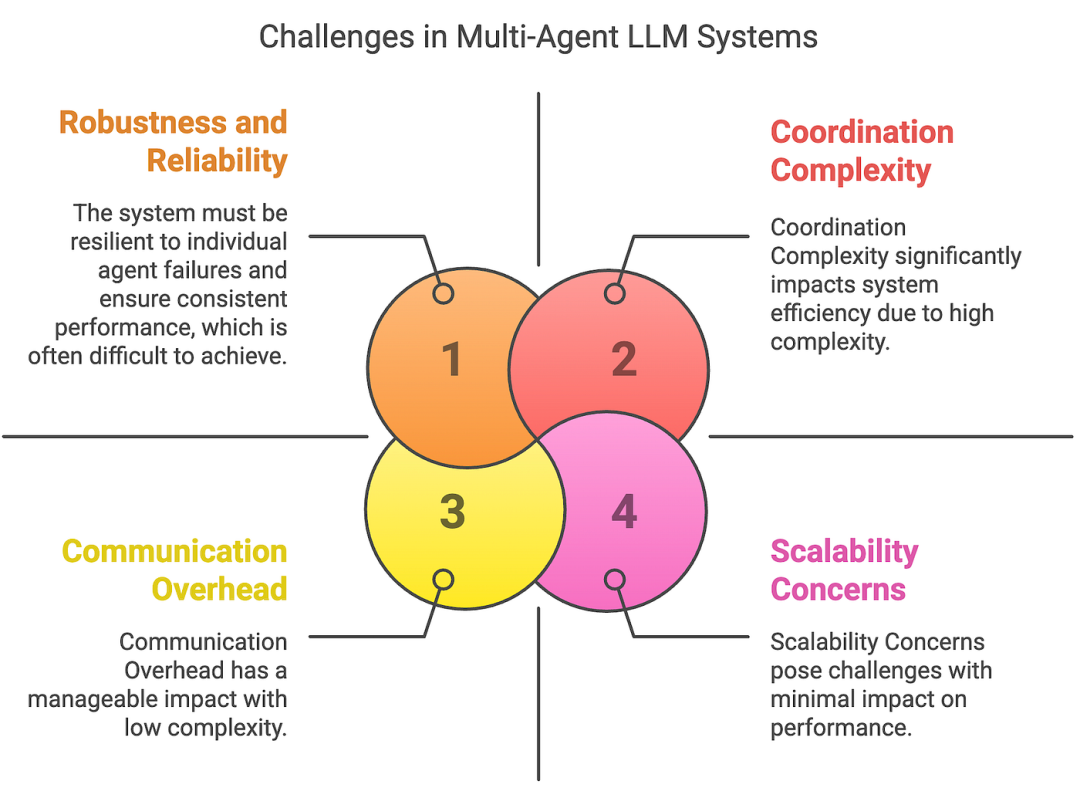
研究人员实验了五种常用的多智能体系统框架在超过150个任务中的应用,并参考了六位专家标注者的见解。他们识别出14种不同的失效模式,并将其归纳为三大类:
- 规范和系统设计缺陷: 由任务定义不明确或系统架构设计不合理引起的问题;
- 智能体间协调不畅: 智能体间沟通不畅或缺乏协调所导致的问题;
- 任务验证和终止: 与验证过程不足和任务完成协议不当相关的失败。
八、应对策略
为了应对这些挑战,可以采用一下两种优化手段:
-
改进智能体角色定义: 提高智能体角色定义的清晰度和精确度,防止误解和角色重叠;
-
增强编排策略: 开发更好的智能体间协调机制,以简化交互和任务执行。
例如,Anthropic 公司发布了模型上下文协议 (MCP),这是人工智能系统和流程如何相互集成的首个行业标准尝试。如果开发者采用MCP标准的智能体模式,那么有助于降低智能体错误率。
谷歌于 2025 年 4 月 9 日推出的 Agent2Agent (A2A)协议 ,使AI agents 能够通过基于 JSON 的“Agent Cards”在不同平台上进行通信和协作。这些Agent Cards描述了智能体的功能、输入和身份验证方案。A2A 和 MCP 相辅相成:A2A 促进智能体之间的互操作性(横向集成),而 MCP 则为智能体提供工具访问权限(纵向集成)。例如,两个智能体可以使用 A2A 协作完成一项任务,同时各自利用 MCP 查询外部数据源,从而创建一个无缝的多智能体生态系统。
九、构建可扩展AI agents的路线图
如果没有合适的路线图,很难构建智能体系统。下面给出一些构建的建议:
- 选择合适的LLM
选择LLM时,应考虑以下因素:
- 擅长推理和逻辑处理
- 支持循序渐进的思考方式(思维链)
- 提供稳定一致的输出
- 设计智能体的推理过程
定义智能体如何处理任务:
- 它是否应该停下来思考片刻再回答?
- 应该按部就班地制定行动计划,还是立即采取行动?
- 当需要额外帮助时,是否应该调用工具?
提示: 从简单的策略入手,例如“ReAct”或“Plan-then-Execute”框架。
- 制定操作指南
制定明确的互动规则:
- 明确回应行为和语气;
- 明确何时使用外部工具;
- 规范响应格式(例如,JSON、Markdown)
- 加入记忆
弥补 LLM 缺乏长期记忆的缺点,方法如下:
- 应用滑动窗口记忆最近上下文;
- 总结过去的对话;
- 持久化关键信息(用户偏好、决策)
提示: MemGPT 或 ZepAI 等工具可以简化内存管理。
- 集成工具和 API
使智能体能够执行现实世界的操作:
- 获取外部数据;
- 更新客户关系管理系统和数据库;
- 执行计算或转换
提示: 使用 MCP 可将工具无缝即插即用地集成到智能体工作流程中。
- 设定明确的目标
向智能体提供具体任务:
✅ “总结用户反馈并提出改进建议”
❌ “乐于助人”
提示: 重点在于缩小任务范围——与其留下开放式的指令,不如明确定义代理人不应该做什么,这样更有效。
- 扩展到多智能体团队
创建能够协作的专业智能体:
- 一个智能体收集信息;
- 另一个智能体则负责解读数据;
- 第三个智能体用于整理和呈现结果。
提示: 明确的职责分工和清晰的角色划分能够带来更高效的多智能体系统。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。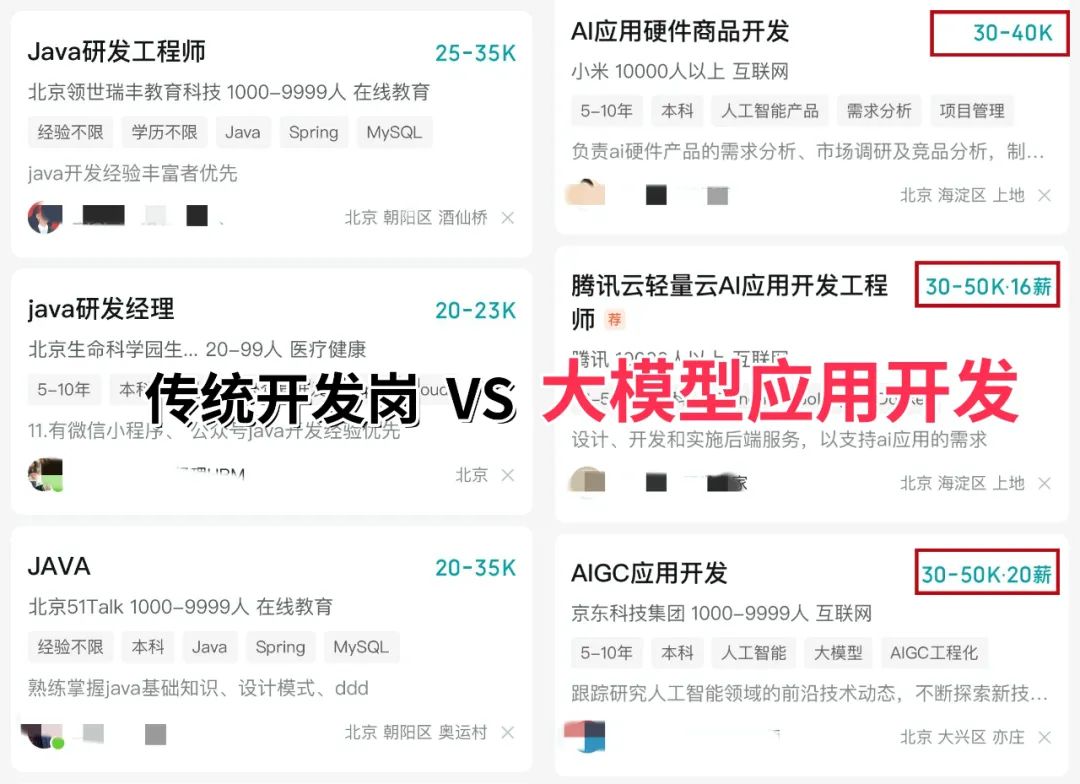
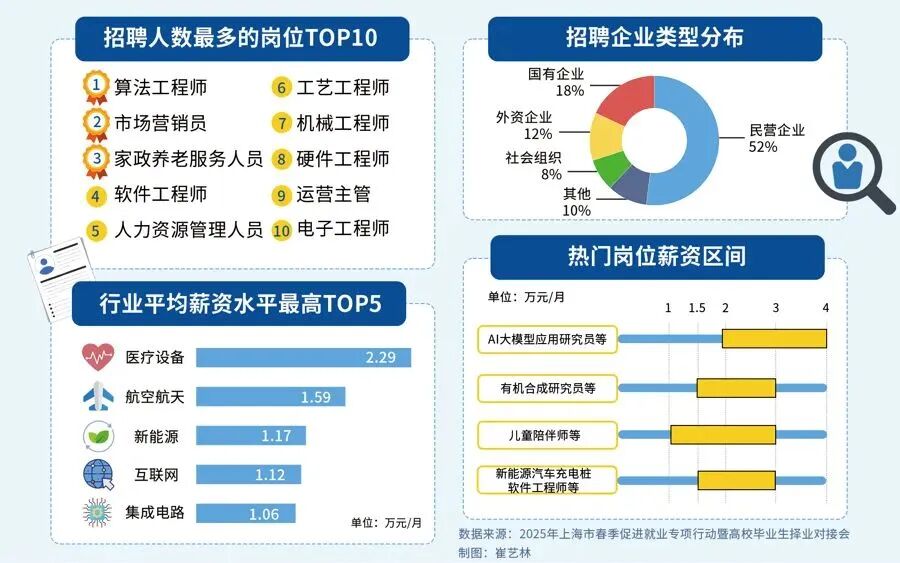
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)