从“提示词猜谜”到“精准导演”:Seedance 2.0 开启 AI 视频的工业化时代
**摘要: 字节跳动发布的Seedance 2.0标志着AI视频生成进入"导演时代",通过创新技术解决行业核心痛点。其双分支扩散变换器架构(Dual-branch Diffusion Transformer)实现多模态信息的并行处理与深度融合,配合全能参考系统支持12个参考文件输入,可精准控制角色、风格、运镜和音画同步。相比传统AI视频模型,Seedance 2.0在角色一致性
如何让 AI 真正理解并忠实执行创作者的意图?长期以来,AI 视频创作更像是一场与机器的“提示词猜谜”游戏,结果往往充满随机性,角色形象在不同镜头间“漂移”,风格难以统一,这极大地限制了其在专业领域的应用。
字节跳动近期发布的 Seedance 2.0,正以其革命性的技术架构,宣告 AI 视频正式迈入一个全新的“导演时代”。它不再仅仅是一个被动的内容生成器,而是一个能够精准响应、协同创作的“数字摄制组”,将 AI 从单纯的“大脑”进化为真正能“动手”的“双手”。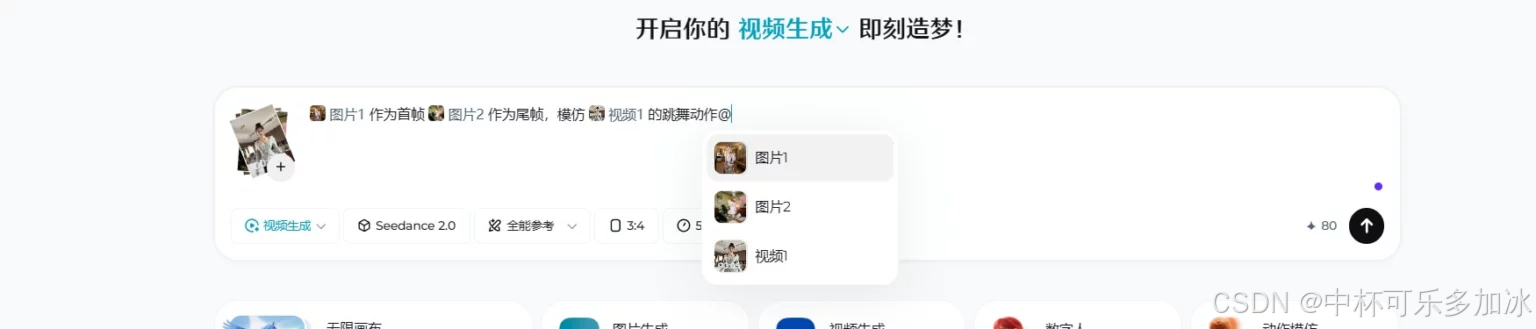
一、告别“失控”与“猜谜”:Seedance 2.0 解决的核心痛点

在深入 Seedance 2.0 的技术细节之前,我们必须清晰地认识到它所瞄准并解决的行业痛点。传统的 AI 视频生成流程,其核心症结在于创作者意图与最终输出之间存在巨大的“信息鸿沟”。
| 对比维度 | 传统 AI 视频模型 | Seedance 2.0 |
|---|---|---|
| 创作控制 | 主要依赖文本提示词,控制粒度粗糙,易产生歧义。 | 多模态全能参考系统,支持图像、视频、音频、文本多维度精准控制。 |
| 角色一致性 | 难以保持,人物在不同场景或动作下易出现“身份危机”。 | 高一致性,通过专用参考输入锁定角色特征,实现跨镜头稳定。 |
| 风格与运镜 | 难以精确复现特定视觉风格或复杂镜头语言。 | 高可控性,可指定参考视频或图像,精准复刻风格、光影、运镜。 |
| 音画关系 | 通常为视频生成后独立配音,音画分离,缺乏内在关联。 | 原生音画同步,音频作为生成参数,深度影响画面动态与节奏。 |
| 工作流模式 | “提示词-生成-调整-再提示”的迭代猜谜,效率低下。 | “意图-参考-生成-微调”的导演式工作流,高效且可控。 |
二、Dual-branch Diffusion Transformer
Seedance 2.0 之所以能实现前所未有的精准控制,其核心在于其创新性的 “双分支扩散变换器”(Dual-branch Diffusion Transformer) 架构。这一设计是 Seedance 2.0 区别于市面上其他 AI 视频模型的关键所在,它解决了多模态信息融合的根本性难题。
2.1 架构原理:并行处理与深度融合
传统的扩散模型在处理多模态输入时,往往采用串行或简单的拼接方式,容易导致不同模态信息之间的冲突或权重失衡。而 Seedance 2.0 的双分支架构,则为“视觉生成”和“参考信息”开辟了两条独立而又紧密协作的处理路径:
- 内容生成分支(Content Generation Branch):这条分支主要负责根据用户提供的文本提示词,构建视频的基础叙事骨架、场景布局和主体动作的初步构想。它专注于生成视频的核心内容和动态,确保故事线的连贯性。
- 参考条件分支(Reference Conditioning Branch):这条分支则专门用于解析和提取用户提供的多达 12 个参考文件(包括图像、视频、音频)中蕴含的精细化信息。例如,从角色图像中提取面部特征、服装细节;从风格视频中学习色彩、光影、纹理;从音频中分析节奏、情绪、声源定位等。
这两条分支并非孤立运作,而是在扩散变换器网络的深层进行持续、精密的交互与融合。参考条件分支提取的精确指令,会以一种“软约束”的形式,实时引导和修正内容生成分支的扩散过程。这种“并行处理、深度融合”的机制,确保了:
- 信息解耦:不同模态的参考信息(如角色外观与场景风格)能够被独立理解,避免了相互干扰。
- 权重动态分配:模型能够根据任务需求,智能地分配不同参考信息的权重,例如在需要高度还原角色时,赋予角色图像更高的权重。
- 全局一致性:从底层架构上保证了生成视频在角色、风格、光影、运动等各个维度上的高度一致性,彻底解决了“角色漂移”和风格跳变的问题。
2.2 核心优势:终结“角色漂移”与“风格失控”
双分支扩散变换器架构最显著的优势在于其对视频内容一致性的强大保障。在以往的模型中,即使是同一个角色,在不同镜头或动作下也可能呈现出细微的面部差异,甚至完全变成另一个人,这在专业制作中是不可接受的。Seedance 2.0 通过将角色特征作为独立的、高优先级的参考条件进行处理,使得生成视频中的人物能够保持惊人的连贯性,无论镜头如何切换、动作如何变化,角色的身份特征始终如一。
同样,对于风格的控制也达到了前所未有的高度。创作者可以上传一段具有特定电影质感的参考视频,Seedance 2.0 就能精准学习其色彩饱和度、光影对比、景深效果乃至镜头运动的韵律,并将其复刻到新的生成内容中,真正实现了“所见即所得”的风格迁移。
三、All-Round Reference
如果说双分支架构是 Seedance 2.0 的“引擎”,那么其“全能参考系统”(All-Round Reference)就是创作者用来驾驶这台引擎的“仪表盘”,也是其实现“精准导演”的关键操作界面。该系统支持最多 12 个参考文件的混合输入,允许创作者以前所未有的精度,解构并定义自己想要的视频画面。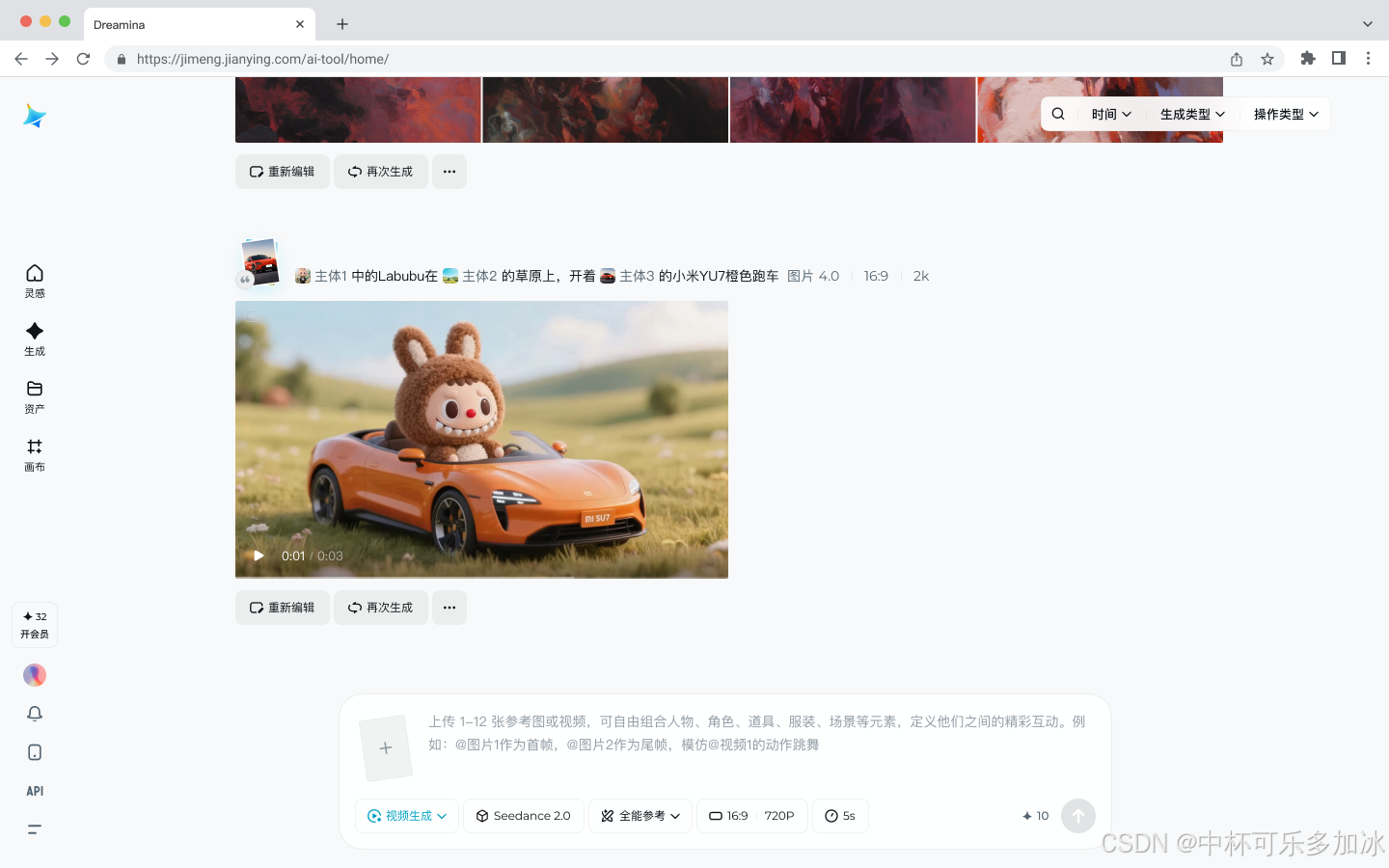
3.1 多模态输入:细致入微的创作指令
Seedance 2.0 的全能参考系统将创作意图拆解为多个可控维度,并通过不同的模态输入进行精确指导:
- 角色定义(Character Definition):创作者可以上传一张或多张包含人物正脸、侧脸、全身等不同角度的参考图像。Seedance 2.0 会从中提取并锁定角色的关键面部特征、体型比例、服装细节,确保其在整个视频中的身份识别度。这对于需要讲述连贯故事的短片或广告至关重要。
- 风格指定(Style Specification):通过提供一张具有独特艺术风格的图像(如油画、赛博朋克插画)或一段具有特定电影质感的视频片段,模型能够学习并复刻其色彩基调、光影分布、纹理细节、构图偏好等视觉元素。这使得创作者能够轻松实现从复古胶片到未来科技的多种风格转换。
- 动作与运镜(Motion & Cinematography):这是 Seedance 2.0 的一大亮点。创作者可以上传一段包含特定人物动作(如舞蹈、打斗)或复杂镜头运动(如推、拉、摇、移、跟拍)的参考视频。模型能够精准捕捉这些动态信息,并将其应用到新的主体或场景中。例如,让 AI 生成的角色跳出与参考视频中舞者完全一致的舞步,或者以参考视频的镜头语言来呈现新的故事。
- 节奏控制(Rhythm Control):音频在 Seedance 2.0 中不再是附属品。通过输入一段背景音乐或音效,模型不仅能将其作为视频的伴奏,更能分析其节奏、鼓点、情绪起伏,并让画面中的人物动作、场景切换、镜头剪辑与音频实现“卡点”同步。这对于音乐视频(MV)、广告片等对音画节奏要求极高的内容创作具有颠覆性意义。
- 文本提示(Text Prompt):作为基础的创作指令,文本提示词依然重要,它用于描述视频的整体主题、场景、情节等宏观信息,与多模态参考形成互补,共同构建完整的创作意图。
3.2 实际应用:从概念到现实的飞跃
这种细致入微的控制能力,使得 Seedance 2.0 在多个应用场景中展现出巨大潜力:
- 电商广告:过去,为不同产品拍摄广告需要耗费大量人力物力。现在,只需提供产品图片、模特照片和一段风格参考视频,即可快速生成高质量、风格统一的产品广告,并可根据不同平台需求进行快速迭代。
- 电影短片与动画:导演可以上传分镜草图、角色设定图、动作参考视频,让 AI 辅助完成初步的动画制作或电影预演,大幅缩短前期制作周期,并确保角色形象和动作的连贯性。
- 音乐视频(MV):音乐人可以提供歌曲音频、艺人照片和概念艺术图,Seedance 2.0 能够自动生成与音乐节奏、情绪完美契合的视觉内容,甚至实现口型同步,极大地降低了 MV 制作的门槛和成本。
四、原生音画同步与 2K 电影级画质
除了精准的控制力,Seedance 2.0 在输出质量上也达到了行业领先水平,尤其体现在其“原生音画同步”和“2K 电影级画质”两大特性上。
4.1 音频不再是背景:声音驱动的物理世界
在 Seedance 2.0 中,音频不再是视频生成后的一个独立音轨,而是在模型训练阶段就与视觉信号深度融合的“原生”组成部分。这意味着,模型能够理解声音的物理属性及其对视觉世界的影响。
例如,当一段视频中出现汽车引擎的轰鸣声时,Seedance 2.0 能够根据声音的强度和频率,在画面中自动生成与之匹配的镜头震动效果,增强画面的真实感和冲击力。当角色说话时,其口型能够与语音内容实现像素级的精准同步,消除了传统 AI 视频中常见的“音画不同步”的尴尬。这种声音驱动视觉的机制,使得生成视频的沉浸感和可信度达到了前所未有的高度,让观众的感官体验更加自然流畅。
4.2 2K 60fps:工业级输出标准
Seedance 2.0 能够原生输出 2K 分辨率、60 帧每秒(60fps)的电影级视频。这里的“原生”至关重要,它意味着视频并非通过低分辨率拉伸而来,而是从模型底层就以高分辨率进行渲染。这保证了画面拥有丰富的细节、清晰的纹理和细腻的色彩表现。60fps 的帧率则确保了视频的流畅度,尤其在表现快速运动或复杂场景时,能够提供更加平滑、真实的视觉体验,满足了专业影视制作对画质的严苛要求。
五、横向对比:Sora 2 与 Kling 3.0
在 AI 视频生成领域,OpenAI 的 Sora 2 和其他如 Kling 3.0、Vidu Q3 等模型同样备受关注。Seedance 2.0 在此背景下,展现出其独特的竞争优势:
| 特性 | Seedance 2.0 | Sora 2 | Kling 3.0 |
|---|---|---|---|
| 核心优势 | 精准控制、多模态全能参考、原生音画同步 | 物理世界模拟、长视频生成、高真实感 | 高真实感、特定风格渲染 |
| 控制粒度 | 极高,支持多达 12 个参考文件,细致到角色、风格、动作、节奏。 | 相对宏观,主要通过文本提示词,细节控制需更多尝试。 | 较高,但多模态参考的稳定性与数量不如 Seedance 2.0。 |
| 角色一致性 | 卓越,通过双分支架构和专用参考输入,实现跨镜头稳定。 | 优秀,但在复杂场景或长时间视频中仍有挑战。 | 良好,但在多主体或复杂互动中可能出现偏差。 |
| 音画同步 | 原生深度融合,音频驱动视觉,实现像素级同步。 | 仍在发展中,通常为后期配音或简单匹配。 | 类似,但原生融合程度可能不及 Seedance 2.0。 |
| 工作流定位 | 强调“导演意图”的精准还原,赋能专业创作者。 | 强调“物理世界”的模拟与探索,更具通用性。 | 强调“高质量”的视觉输出,偏向特定风格。 |

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 9
9 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)