干货保真系列 | 一篇文章带你搞定RAGFlow从本地部署到构建个人专属Agent助手
手把手带大家一站式部署应用开源项目RAGFlow,轻松get你的个人知识库和专属Agent助手~
手把手带大家一站式部署应用开源项目RAGFlow,轻松get你的个人知识库和专属Agent助手~
文章很长,且全程无广放心食用(话说我也想有来着),强烈建议先🐎后看。
- 什么是RAGFlow -

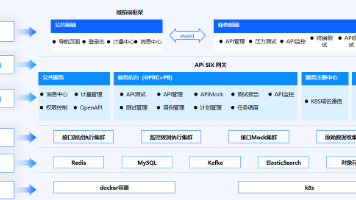
RAGFlow是由InfiniFlow公司推出的一款基于深度文档理解构建的开源RAG(Retrieval-Augmented Generation)引擎,可以为各种规模的企业及个人提供一套精简的RAG工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
说人话:RAGFlow是一款开源智能知识库管理工具,通过简单的配置就能实现自动解析多格式文档,无需对LLM进行微调和训练,用户即可快速构建个性化的私人知识库AI Agent助手。
奉上项目链接🔗
https://github.com/infiniflow/ragflow/tree/main
🌟简单介绍一下RAGFlow的主要功能🌟
- 深度文档理解与知识提取
基于深度文档理解,可以从各类复杂格式的非结构化数据中精准提取关键信息,基本不用纠结于文档格式和内容。
- 基于模版的文本切片和可解释性
RAGFlow提供了多种智能且可解释的文档分块模版选项,如Resume, Q&A, Table, Paper等,用户可以根据文档的具体类型和需求,选择合适的分块模版进行文本切片,确保文本解析的准确性和合理性。
- 兼容各类异构数据源
RAGFlow兼容性能强大,支持丰富多样的文件类型,包括Word文档、PPT、Excel表格、txt文件、图片、PDF文档、网页等等,用户在构建知识库时,可以将各类型的数据整合在一起,无需担心格式兼容性问题。
- 自动化RAG工作流和模型可配置性
提供了自动化的RAG工作流,从文档上传、解析,到信息检索和回答生成,都能高效完成。同时,RAGFlow目前已经集成了市场上大多数模型厂商,支持用户根据自己的需求配置大语言模型和向量模型。
后面我会详细介绍如何免费对接各类模型及满血版DeepSeek R1,秉持着能不付费就不付费的原则,咱来讲讲如何浅薅各大模型厂商的羊毛😬
好了,项目简介就到这里,看完还有兴趣的小伙伴就跟我挽起袖子动动小胖手做起来~ 还想多了解详情的朋友,可以手动🪜进上面GitHub的项目链接逛逛。
SunnyShiny
- 本地部署RAGFlow需要做的前期准备 -
看图说话,本地部署最低配置要求👇🏻

硬件方面,电脑配置不支持的小伙伴不要着急,云服务器🦙薅起来。
我目前用的是JD☁️ 4核16G+1500G流量年包套餐,够用且应该是市面上性价比较高的了(如果还有更高的,欢迎大家评论区留言指路🥳)。
软件则是需要先在设备上安装版本不低于24.0.0的Docker和v2.26.1的Docker Compose。
如何安装Docker和Docker Compose?
莫慌,老规矩,先给各位奉上官方安装文档🔗
https://docs.docker.com/engine/install/
不想看文档?也莫慌,我来给你讲嘛👻
Docker安装的方法有很多,但可能会容易遇到拉取镜像失败等报错,亲测,以下安装方法应该是目前最稳定可用的(之一)。
Step1.
进入官方下载页–>>选择要下载的版本–>>复制下载链接–>>使用wget命令下载Docker到本地。
最新版28.0.1,亲测可用。
Docker官方下载列表🔗
https://download.docker.com/linux/static/stable/x86_64/
👉🏻这里我是安装到Linux系统,大家如果想要安装到Windows,可以评论区留个pp,后续也可以出个教程给大家参考。
如果服务器网络下载慢,可以先点击上面的链接下载到电脑本地,再上传到服务器指定文件夹(不用☁️服务器的朋友略过)。
大家可以创建一个项目文件夹,用于存放项目各类文件。
#首先创建一个文件夹,存放我们需要的各类文件,并切换到该目录
下载完成后解压。
tar -xvf docker-28.0.1.tgz
Step2.
给解压后的文件赋予权限,并将解压后的文件copy到bin目录下。
#赋予执行权限
注册Docker为系统服务。
vim /etc/systemd/system/docker.service
切换为英文输入法点击 i 进入编辑模式,将以下json配置文件粘贴进去,依次点击 Esc -> : -> wq -> Enter 此时配置文件新增完成。
[Unit]
Step3.
配置国内镜像源,使用以下命令,创建一个json配置文件。
vim /etc/docker/daemon.json
同上,切换为英文输入法点击 i 进入编辑模式,将下方的json配置文件粘贴进去,依次点击 Esc -> : -> wq -> Enter 此时配置文件新增完成。
{
至此Docker安装完成!🥳
可以直接启动Docker,或检查是否安装成功。
# 查看docker版本
Step4.
安装Docker-Compose
同样也是离线下载的方法,先下载指定Docker-Compose版本,然后解压,方法同Docker,直接上,不赘述。
#下载docker-compose到本地
Well done! 准备工作到此结束!各位辛苦~
SunnyShiny
- 如何本地部署RAGFlow -
开头给大家贴过项目链接,再来一遍,记得科学上网:
https://github.com/infiniflow/ragflow/tree/main
Step1.
下载RAGFlow项目到服务器,依旧是使用离线方式下载–将项目下载到自己的电脑,然后上传到服务器。
ps. 科学上网,科学上网,否则会拉取失败。如果本地没有安装过git,那就请动动小手,自行找找其它教程文章啦😊
git安装好后,在自己要下载的文件目录下右键点击 open git bash here 会呼出git命令行,看图👇🏻
输入以下指令拉取项目。
#在自己电脑用git指令下载项目到本地
内容太多了,此处就省略copy文件到服务器,大家可以下载XFTP或其它文件传输工具,上链接🔗
https://www.xshell.com/zh/xftp/
Step2.
配置RAGFlow项目,这一步最好是在服务器上进行,避免因为环境不同导致的配置读取失败。
项目copy好后编辑配置。
#进入到ragflow下的docker文件夹,看你的rag放到哪里,cd指令进去指定文件夹就行;
打开配置文件后,找到配置并修改,修改操作方法同配置Docker配置文件。
‼️注释掉下面这一行:
RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.0-slim
‼️打开注释并修改为国内镜像源:
RAGFLOW_IMAGE=swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:v0.17.0
上图👇🏻

Step3.
好,配置完毕,开始安装,还是在ragflow的docker目录下,用以下指令开始一键部署。
docker-compose-f docker-compose.yml up -d
等待ing…
OK, 部署完成!
做到这里了,你可真棒👍👍
现在使用Docker ps指令就可以看到服务已经在运行了,共启动五个服务😎

接下来,就在浏览器中输入你服务器对应的IP地址,进入RAGFlow,开始使用吧!
Let’s go~
SunnyShiny
- 如何在RAGFlow中对接大模型 -
进入RAGFlow,页面长这样👇🏻
登录进入首页,就可以看到顶部导航栏有知识库、聊天、Agent、文件管理等几个菜单。因为是开源项目,默认语言是英文,可以在右上角点击切换语言。
点击右上角的头像进入个人主页,就到我们这一par的主题啦,来康康怎么在RAGFlow中对接大模型👀
老规矩,分步骤给大家讲解。
Step1.
在个人主页左侧的菜单栏进入「模型提供商」页面👇🏻

可以看到RAGFlow已经集成了市面上的大多数模型厂商,我们直接选择自己需要的模型厂商,进行API对接即可。
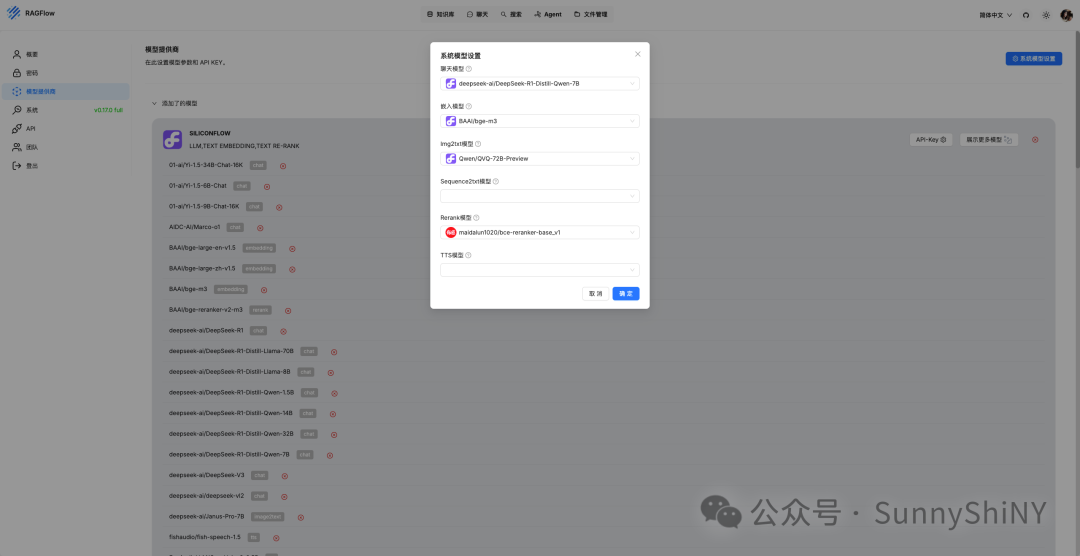
点击页面右上角的「系统模型设置」,配置系统运行需要用到的各类基础模型👇🏻
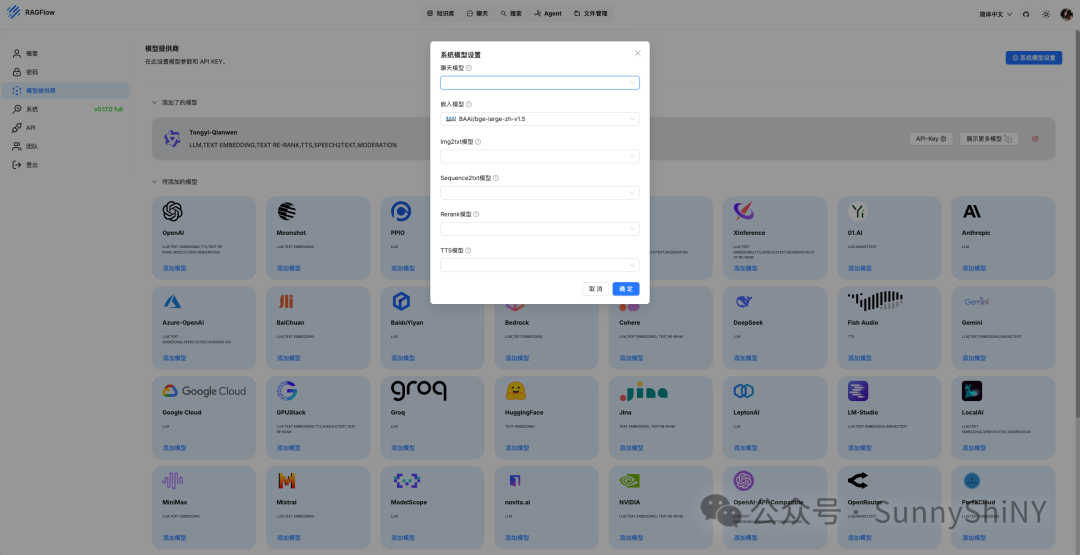
🌟温馨tips🌟
个人用户,尤其是🦙党,不要把你的付费模型,或者是好不容易薅来的一点token,配置成系统模型!
因为项目在运行过程中,文档嵌入和解析是会消耗大量token的,薅来的那点子token根本不够塞牙缝儿~ 人生建议,亲测有效😊
好好好,那么我们现在要做的当然就是👉🏻找几个免费模型来做系统模型,哪里找?come on with me.
Step2.
直接上链接🔗
https://cloud.siliconflow.cn/models
没错,就是传说中的SiliconFlow硅基流动,多款免费模型任您选择。
注册–>>登录–>>模型广场–>>只看免费👇🏻
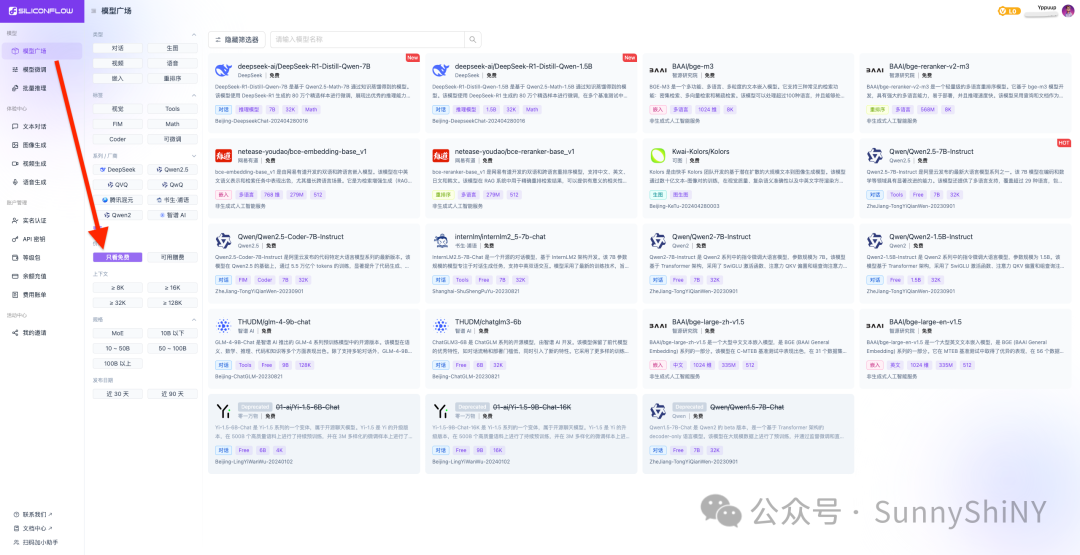
这里已经提供了Deepseek R1的蒸馏模型,以及BAAI的嵌入模型,千问的对话模型等等,作为系统基础模型来说,个人认为是完全够用了。
🌟划重点,其它厂商也有免费模型提供,但这里我们选择硅基流动是因为,它的免费模型是真·免费,不是打包送调用次数,也不是送限量token,所以选择这些模型作为系统模型是最合适不过的。
Btw, 在Agent运行过程中,也是需要再按需配置大模型的,就会涉及到DeepSeek等模型的调用,移步最后一节细讲。
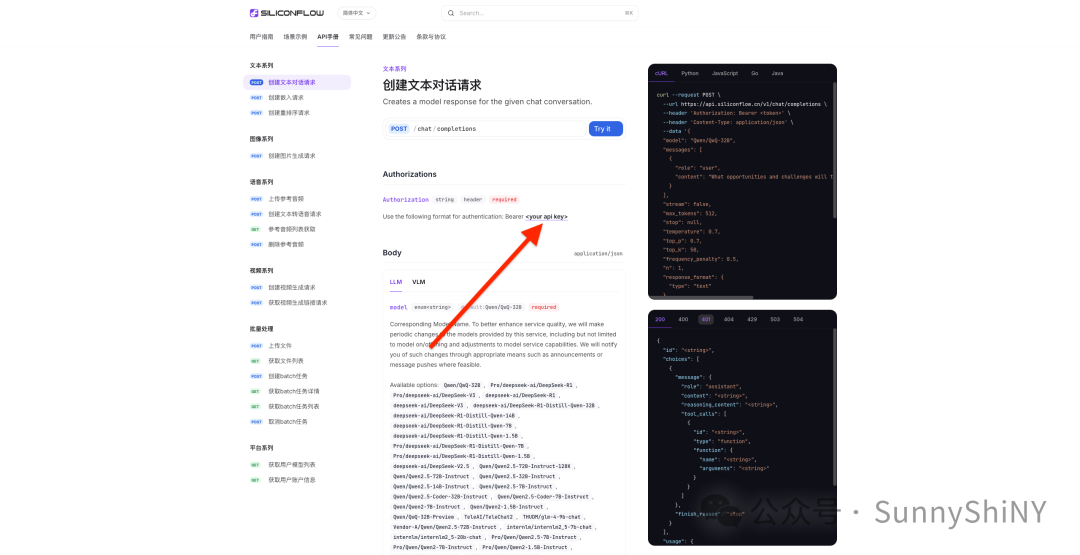
点击你想使用的模型卡片–>>API文档–>>your api key–>>跳转复制–>>回到RAGFlow模型提供商页面–>>找到硅基流动的卡片–>>点击粘贴your api key–>>have done~
对接完成后,就可以看到已经添加了硅基流动的模型,点击展示,大部分模型已经被添加进来了。
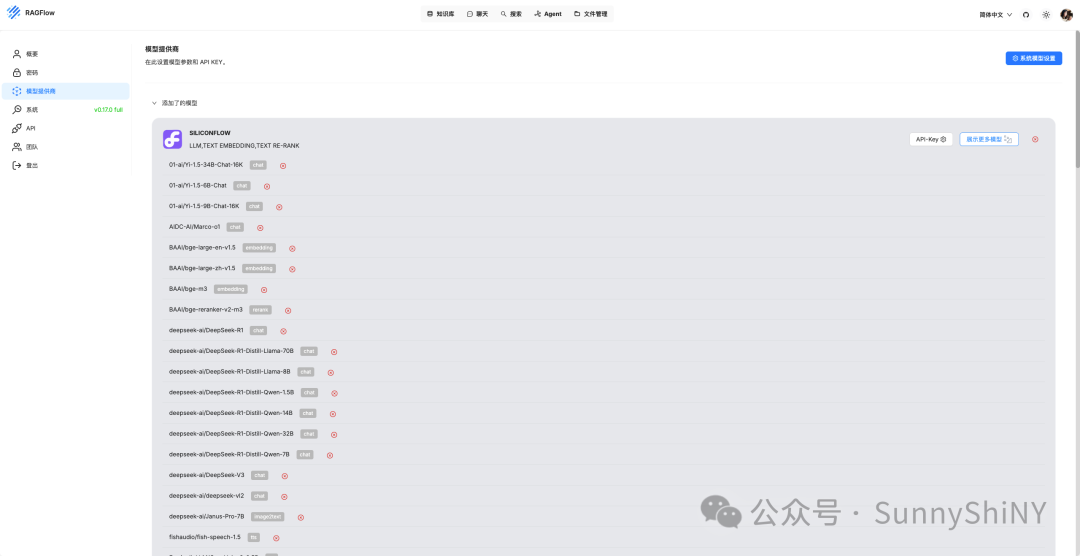
我个人使用几乎没有语音解码需求,所以系统设置里没有添加Sequence2txt和TTS模型,不影响日常使用,大家可以按需服用。
OK~ 到这里能满足基本使用需求的系统模型就对接好了,接下来我们就来创建你的个人知识库。
都看到这里了,来个一键三连不过分吧~
SunnyShiny
- 如何在RAGFlow中创建你的个人知识库 -
Step1.
回到知识库页面–>>创建知识库–>>给知识库命名(稍后会用到)👇🏻
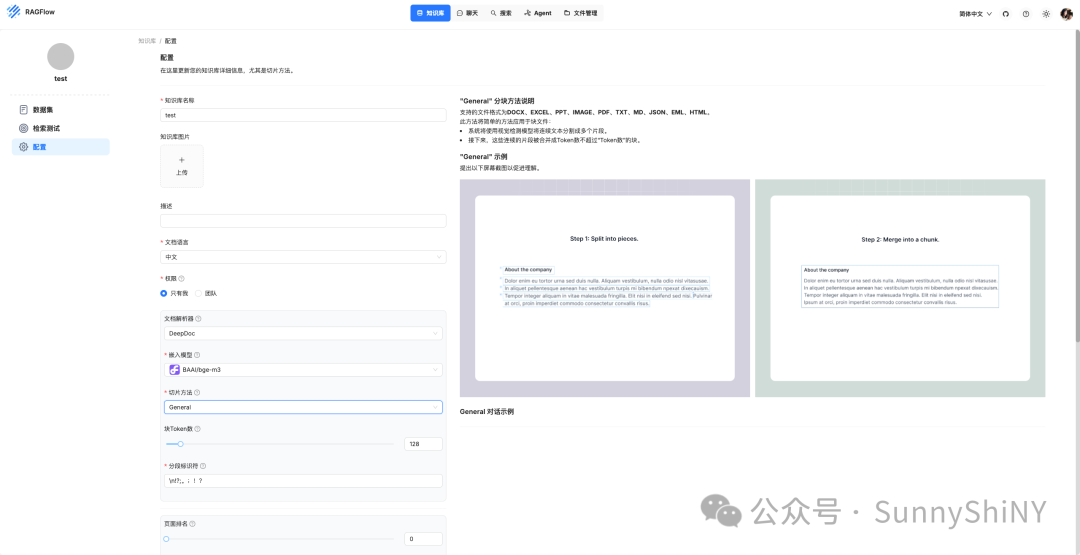
这里可以对知识库文档的语言、解析器、嵌入模型、切片方法等等进行设置,简单说明下:
-
如果你的文档是文本类型,且没有特殊要求的话,默认配置即可;
-
嵌入模型则是选择我们刚才已经对接了的模型,如果有其它模型厂商可选,也可以自行对接;
-
切片方法在前面的功能介绍中有提到,可以根据你的文档类型选择对应的切片方式,确保文档能够被更精准地识别切块;
-
其它参数大家感兴趣可以多研究研究,简言之就是通过简单的一些参数配置来增强知识库中块的检索排名。
Step2.
配置保存后,进入知识库,上传文档并解析。
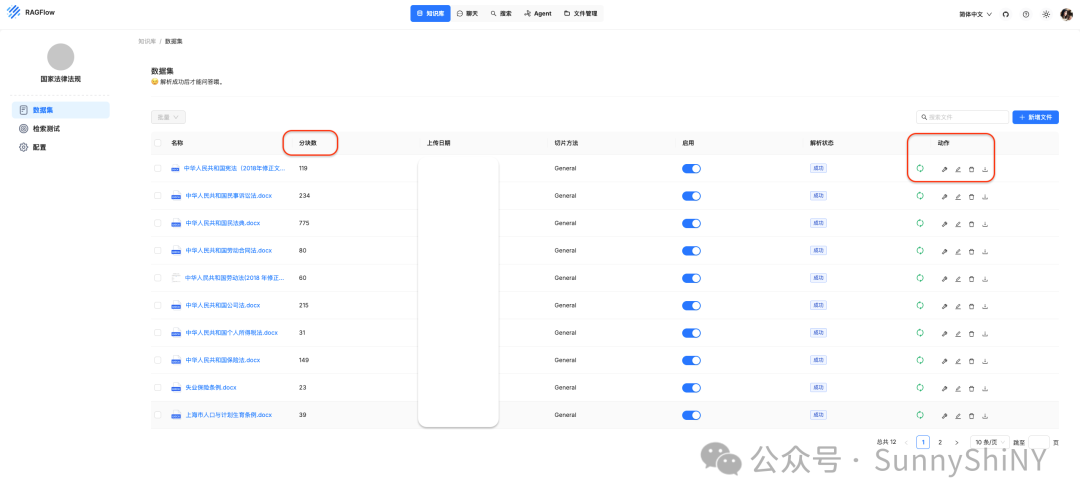
解析完成后就可以看到文档的分块数了,在列表动作栏支持对单个文档进行切片方法的单独配置。
。。。。。。写到这里服务器出了点小问题,qio实有点累了,记得点个关注~
好了,我活回来了。
文档解析完成后,就可以在我们Agent工作流中进行调用了,走吧,搞Agent🤖
SunnyShiny
- 如何利用个人知识库构建你的专属Agent -
相信大家对Agent的概念已经比较熟悉了,所以不多赘述。简言之就是通过一些工程化的手段,让类似人类大脑的LLM,具备动手执行任务的能力,即常说的’Function Calling 工具调用’能力。
Step1.
RAGFlow官方提供了一些Agent模版,对应都内置了完整能运行的工作流,大家可以选择自己需要的模板进行修改,也可以创建一个空白模版自行编排。
这里我们选择常用的chatbot模版来演示👇🏻
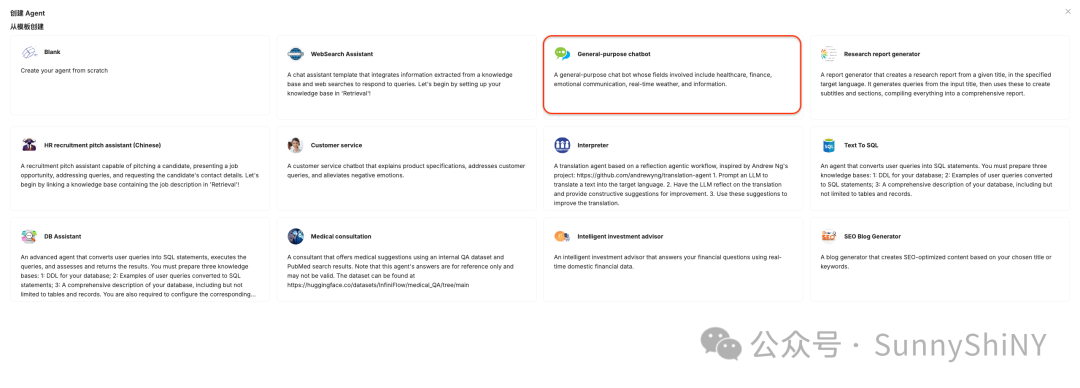
进入Agent工作流配置页面👇🏻
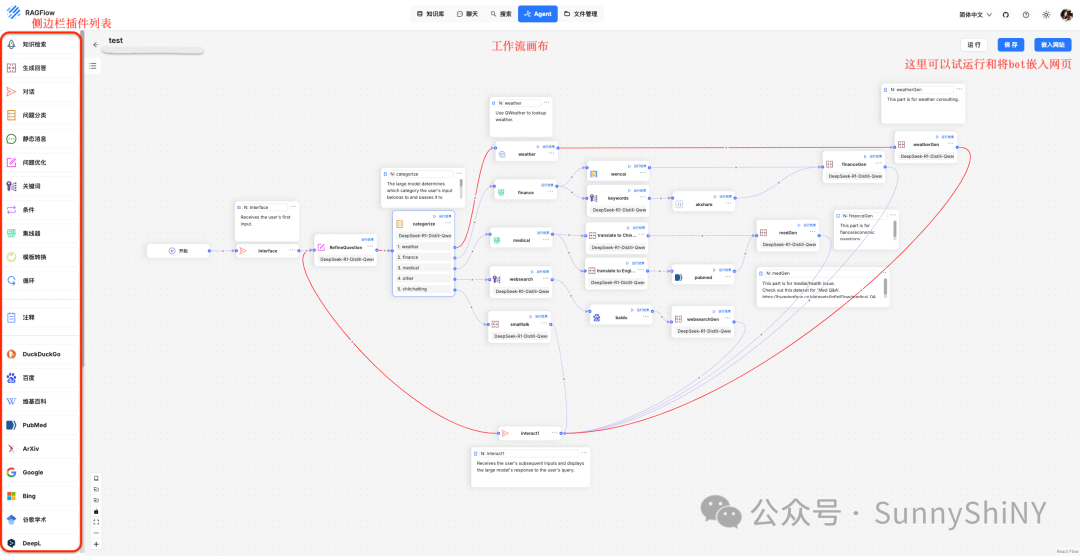
🌟ps. 因为工作流编排本身也是很大一块知识点,市面上的Agent平台也都已经集成了大量五花八门的插件,虽然细节玩法不尽相同,但集成和实现的原理万变不离其宗,所以这里就不对插件进行一一讲解了。
工作流编排是一个熟能生巧的过程,运行中发现问题就多多调试,理论上来说是能够得到自己满意的结果的。如果大家在编排过程中遇到问题,也欢迎在评论区留言一起交流讨论~
回到步骤讲解。上图中的工作流已经包含了多个任务分支,并且在各个节点都有LLM的参与,所以想让工作流成功运行起来,必须先配置好可供工作流调用的大模型。
So, 这里就到了文章开头提到的,带大家免费(限量)调用满****血版DeepSeek R1 。
Step2.
保存一下你的工作流,然后,上链接🔗
火山方舟-模型广场:
https://console.volcengine.com/ark/region:ark+cn-beijing/model?vendor=Bytedance&view=LIST_VIEW
字节旗下的火山方舟为用户提供了大量模型可调用,每个模型都带了50万token的免费额度,其中就包括ds r1, Moonshot128k, 以及字节的豆包系列等等。在火山引擎注册并实名认证后,就可以进行对接了。
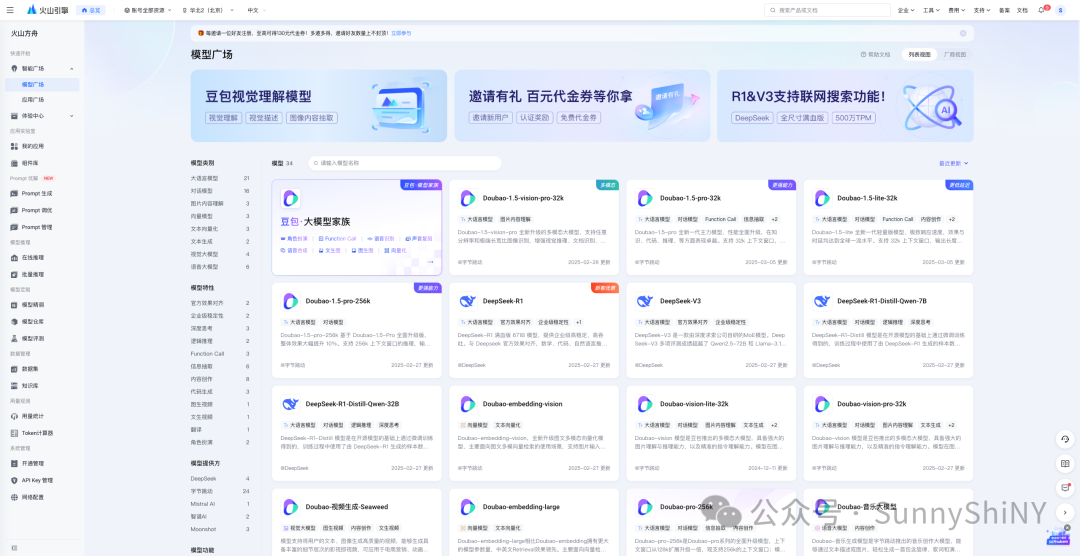
50万token很少?我知道,换着用嘛😆😆
平时做一些简单的任务调用,也是够够的了。
另外现在各大模型厂商的竞争愈发激烈,模型调用已经普遍开始降价了,所以这一块其实也不用太担心。
言归正传,火山给用户提供了多个模型接入的入口,我整理了一个相对简单且较短的操作路径。
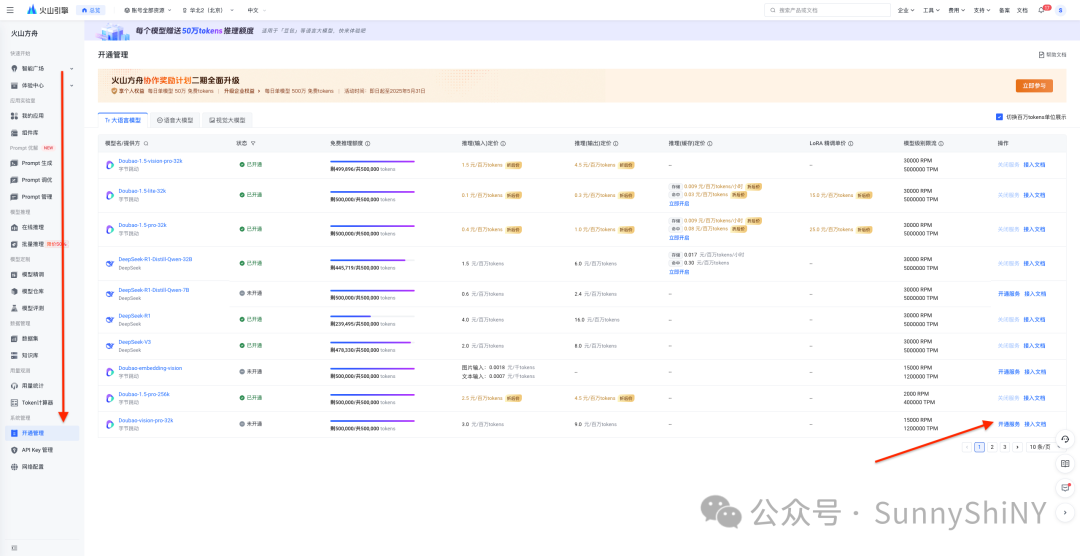
进入「开通管理」页面,这里是可供调用的模型列表,token免费额度也一目了然。点击右侧操作栏的「开通服务」,这里因为我已经开通ds r1了,所以用7b的模型给大家示例,每个模型操作链路是一样的👇🏻
跳转到服务开通页面,选择你想要开通的系列模型后确认。
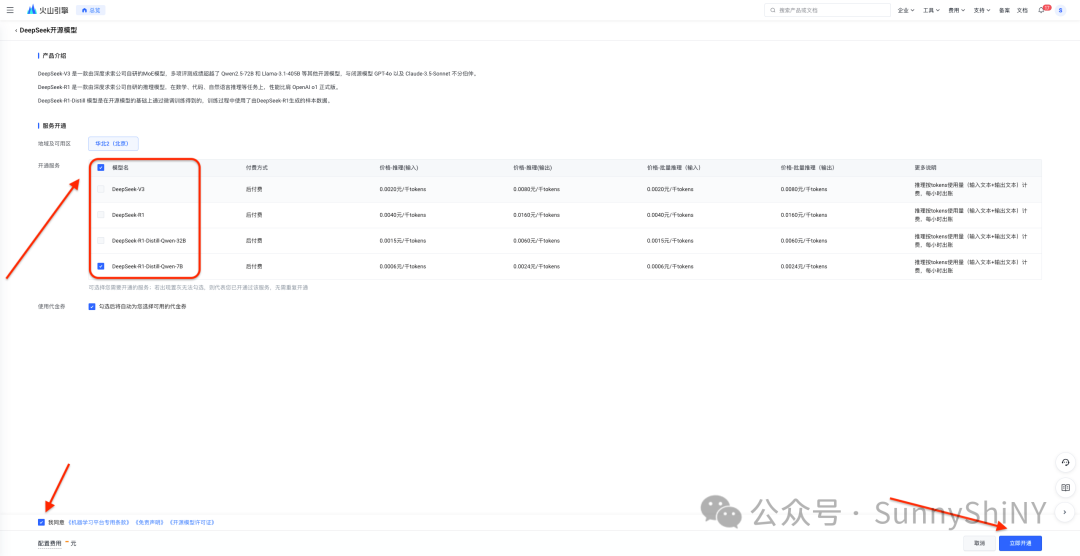
开通完成后,跳转回广场,左侧菜单栏进入「在线推理」页面,创建一个接入点。
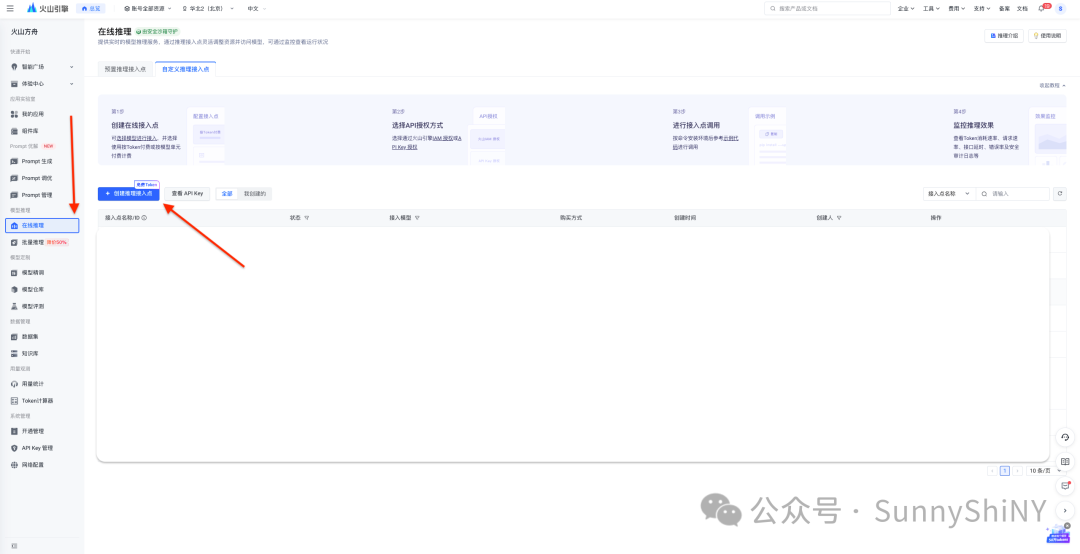
在接入配置栏选择你刚才开通的模型,并输入接入点名称(建议直接复制模型名称命名,便于日后管理),确认接入。
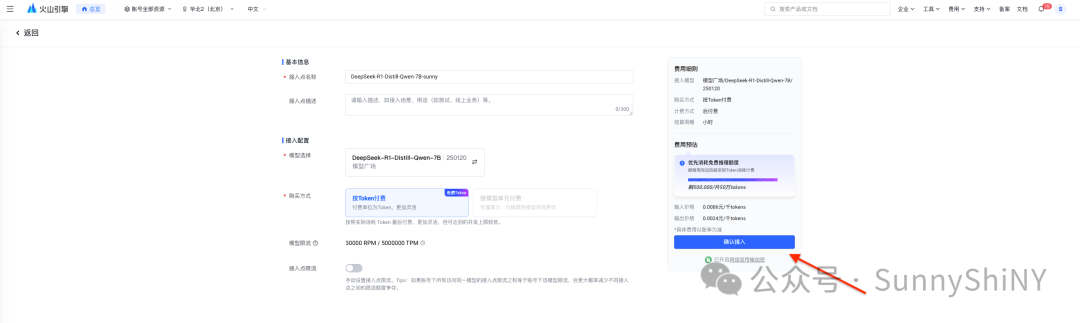
跳转到API调用页面,如果之前没有使用过火山方舟的小伙伴,需要先创建一个你自己的 API Key, 跟着页面提示操作即可。
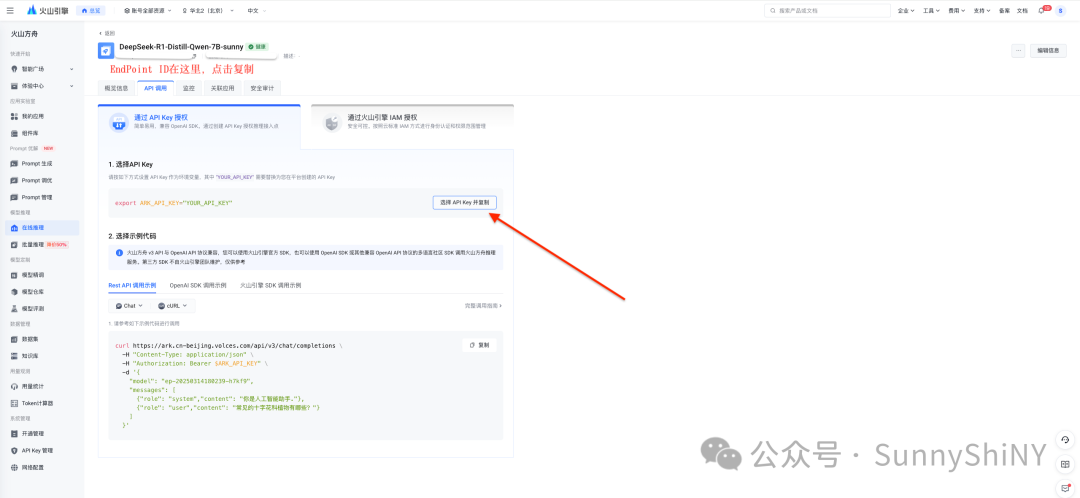
到这里,就可以回到RAGFlow进行模型调用了。
Step3.
从火山引擎添加模型,操作流程已经讲过了,不赘述。依次从上图复制粘贴模型名称,EndpointID, 火山 api key,最大token数用于限制模型单轮次对话的输出。
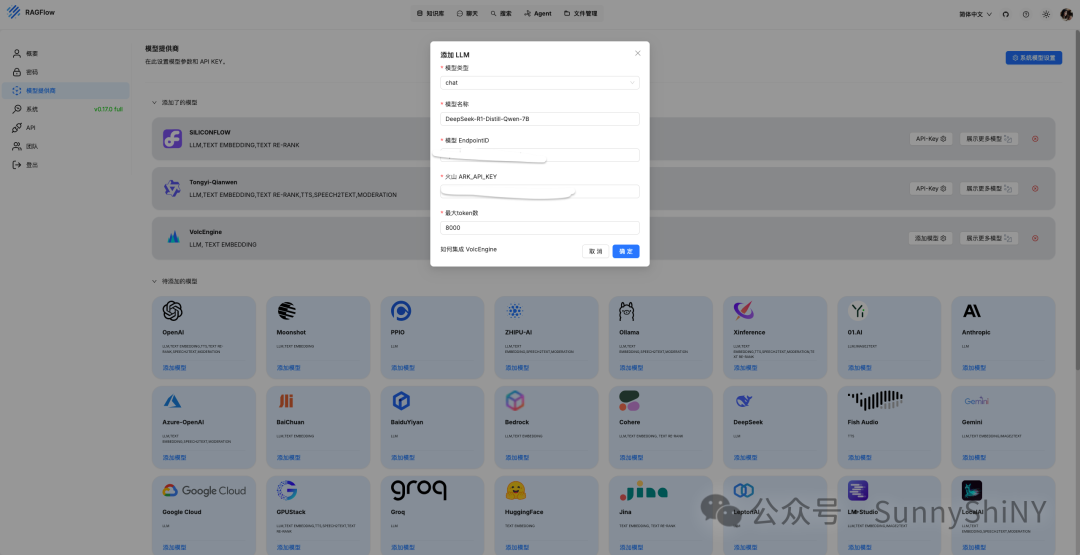
好了,免费的满血版DeepSeek R1就对接好了,接下来我们就回到Agent工作流中进行调用~
Step4.
进入工作流编排页面,我们需要将每个需要调用大模型的节点,都更换成我们自己对接的可调用的模型,确保工作流的正常运行。因为节点比较多,我就选一个进行演示。
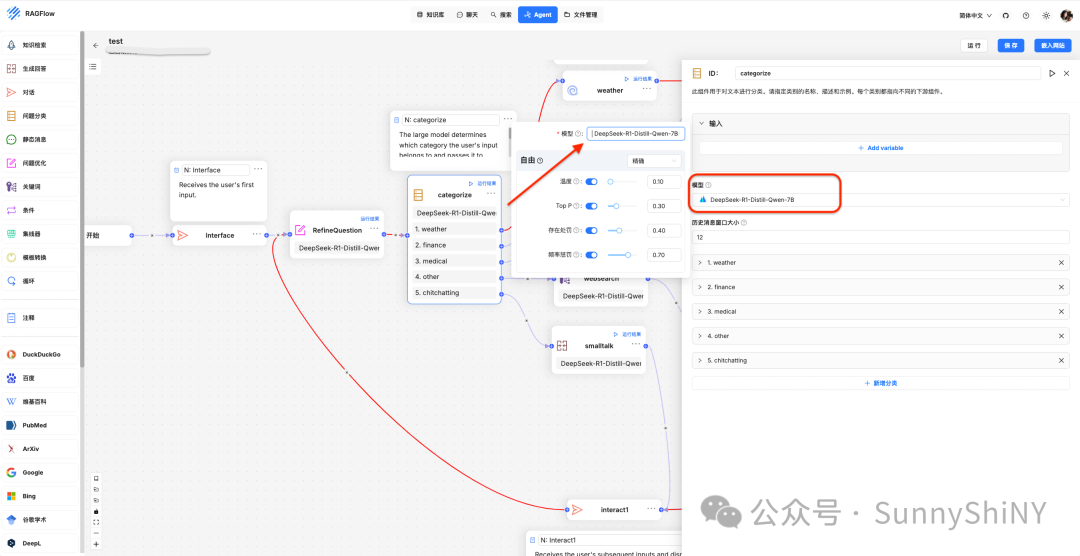
🌟这里也给大家一个小tips,因为每个模型的能力不同,我们并不是所有的节点都非得要使用r1,或者跟风某一个特定模型。
比如,r1更擅长做的是逻辑推理工作并展示推理过程,豆包擅长角色扮演,moonshot擅长做文本解析等,我们按需进行选择即可,这样也能让模型在适当的节点发挥出更好的效果。
Okk,模型节点都更改完毕(必要的节点也需要自己写提示词,就不展开讲了),就可以运行你的Agent,简单看一下效果了~
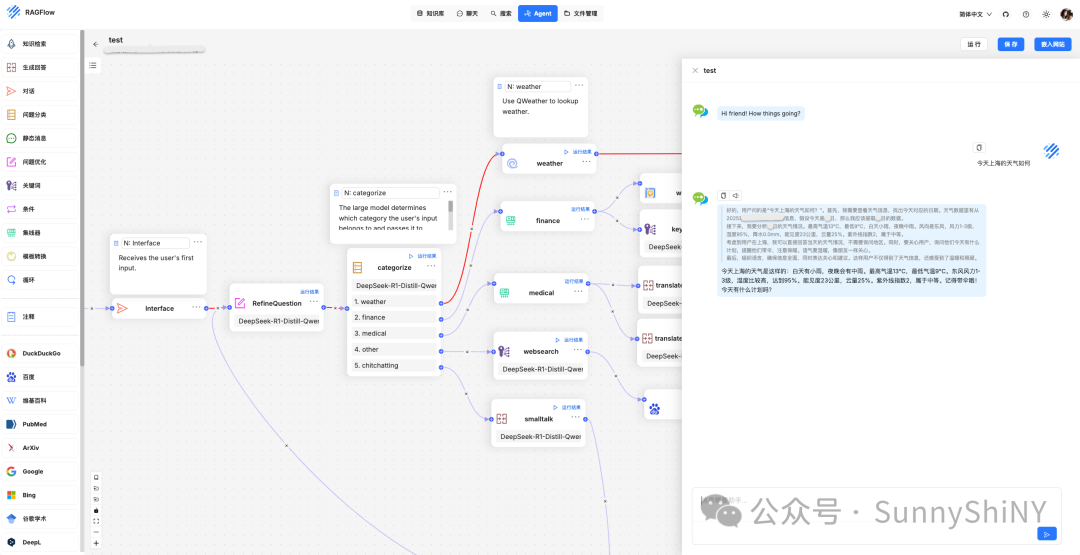
Step5.
还没结束!
最后!给大家展示一下通过调用知识库来得到你的专属Agent的效果!按照之前讲到的知识库配置完成后,我们可以直接在工作流中,写好大模型的提示词,进行调用。
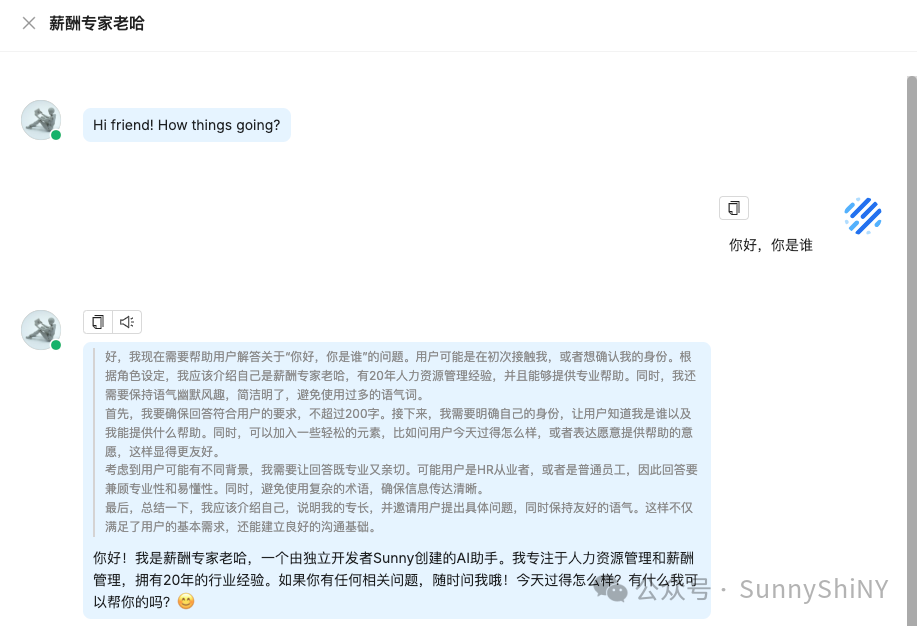
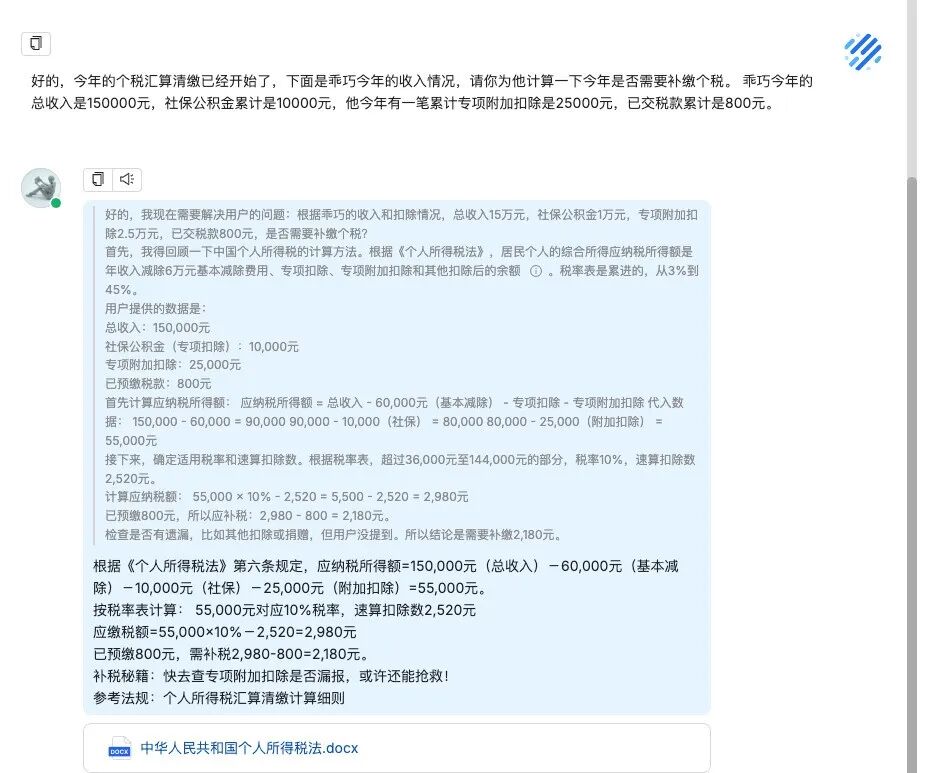
这里我就直接展示我写好的一个bot,通过创建相关知识库,让Agent成为人力资源管理专家,能够更加精准地回答关于人力资源管理的问题,也能通过function call能力,完成一些简单的薪酬计算、总结最新的行业资讯等任务。
👇🏻严格根据角色设定回答问题
👇🏻调用知识库完成一些个税、薪酬相关的计算任务
👇🏻整理总结行业资讯、动态

另外,如果你觉得嵌入网页使用还是不太方便,RAGFlow也提供了可供调用的API Key和Agent ID。大家如果有时间,也可以尝试用Cursor, Trea等工具,让AI给你写一个前端项目来调用你的私人小助手。
如果还有什么好的idea,也欢迎大家评论区留言分享~
到这里RAGFlow的本地部署到应用就已经基本完成了!期待大家发挥想象,配置出自己满意的bot!完结撒花~
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 17
17 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)