文心4.5Turbo将发布!体验文心4.5与X1后,预测新模型能力更强、价格迎新低
对于我们普通开发者而言,我感觉文心4.5 Turbo的发布将带来三个维度的变革:首先,实时交互能力的大幅提升使得多模态应用的开发门槛显著降低,开发者可以轻松构建支持即时图文生成的创意工具;其次,推理效率的优化让毫秒级响应的智能对话系统成为可能,这将彻底改变人机交互的体验标准;在测试文心系列模型的过程中,最打动我的不是冰冷的基准测试分数,而是那些真实的落地场景:当4.5生成的甄嬛骑摩托图让我会心一笑
近年来,大模型技术的快速发展让AI应用变得更加多样化和实用化。作为长期关注大模型技术落地的开发者,我在最近测试了百度最新发布的文心4.5和X1大模型。从实际应用中确实感受到了国产模型近一步的进化,尤其是在多模态理解和复杂任务处理上,这两款模型的表现不只是“能用”,而是真正达到了“好用”、“会用”、“敢用”的水平。
今天,百度官方公布了将在4月25日的Create 全球 AI开发者大会上发布新模型的消息。没想到,仅仅一个月后,下一代文心模型就要出来了。
百度预告,这次新模型是文心4.5 Turbo。根据我这段时间对文心4.5、文心X1的使用感受,我个人预测,文心4.5 Turbo会延续这两款模型优势能力,比如推理能力、深度思考能力等的基础上,再做进一步升级和优化。
我比较期待的是价格,因为不论是文心4.5还是文心X1 ,之前都因为低于ChatGPT和DeeSeek R1的价格出圈。李彦宏之前也多次表示随着技术升级大模型成本下降数量级。显然,文心4.5 Turbo的成本很可能将下降到一个新水平。
我们先来看看文心4.5和X1的表现,大家可以从中预测一下文心4.5 Turbo的升级点。
一、技术解读——文心X1及4.5简介
文心大模型4.5和文心大模型X1是3月16日正式发布的,而且两款模型发布时就在文心一言官网上线和提前免费向全体用户开放了。
模型能力上,文心大模型4.5的多项基准测试成绩优于GPT4.5、DeepSeek-V3等,并在平均分上以79.6分高于GPT4.5的79.14。
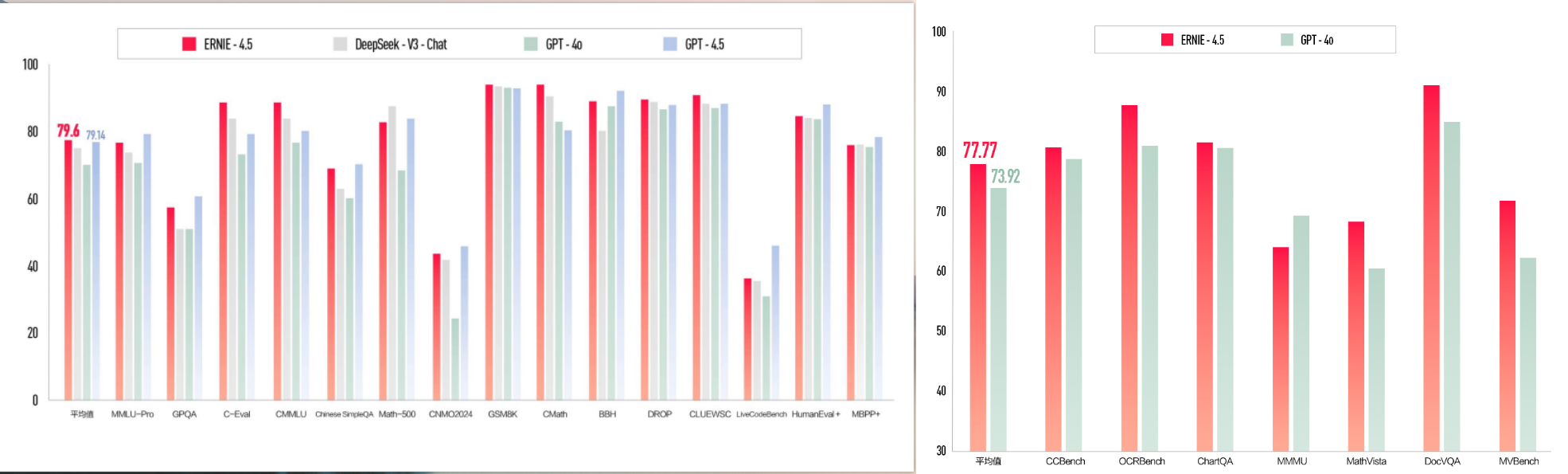
文心4.5是百度自研的新一代原生多模态大模型,在图文、视频、音频等多模态融合建模方面实现了多项关键突破:
- FlashMask 动态注意力掩码:显著提升了长文本和多轮对话的建模效率,改善生成连贯性。
- 多模态异构专家扩展技术:根据不同模态特征建立“专家子模型”,结合模态感知损失函数,提升跨模态融合能力。
- 时空维度表征压缩技术:对视频等序列内容进行高效语义压缩,增强模型在长视频中的信息提取能力。
- 自反馈Post-training技术:结合人类反馈与自我对齐机制,强化模型在人类指令对齐方面的鲁棒性。
这些技术使得文心4.5在处理图表、梗图、视频、文档时表现出更高的准确性、连贯性和生成质量,尤其在原生多模态架构下表现出对复杂任务的深度理解力。
而文心 X1具备更强的理解、规划、反思、进化能力,其代表了百度在“AI智能体”方向的积极探索,它强调的不只是“理解语言”,而是“理解任务并完成任务”,其核心创新包括:
- 递进式强化学习:模型在不同场景(搜索、写作、工具调用)中逐步增强能力,实现能力递进式迭代;
- 基于思维链和行动链的端到端训练:让模型具备从“思考-计划-执行”的闭环,类似人类解决复杂问题的方式;
- 多元统一奖励机制:通过不同维度的评价体系为模型训练提供稳定反馈,避免过拟合单一指标;
- 全面的工具调用能力:内置支持包括高级搜索、AI绘图、文档解析、网页读取、代码执行、学术检索等丰富工具,具备一定程度的“Agent化”雏形。
这些能力让X1不仅能完成复杂推理与写作任务,更能自主调用工具完成检索、分析、生成等一整套流程任务,真正展现了“深度思考”的模型特性。
二、实测——文心X1及4.5效果分析
文心4.5在多模态理解能力上展现出显著优势,尤其在跨模态隐喻解析方面表现突出。
为验证其能力,我进行了两组测试:首先上传经典的数学梗图"连续不一定可导",模型不仅准确识别了数学概念,更令人惊喜的是能够解析其中的幽默逻辑,这种对专业概念与生活隐喻的跨模态理解,展现出接近人类语言学家的认知水平。
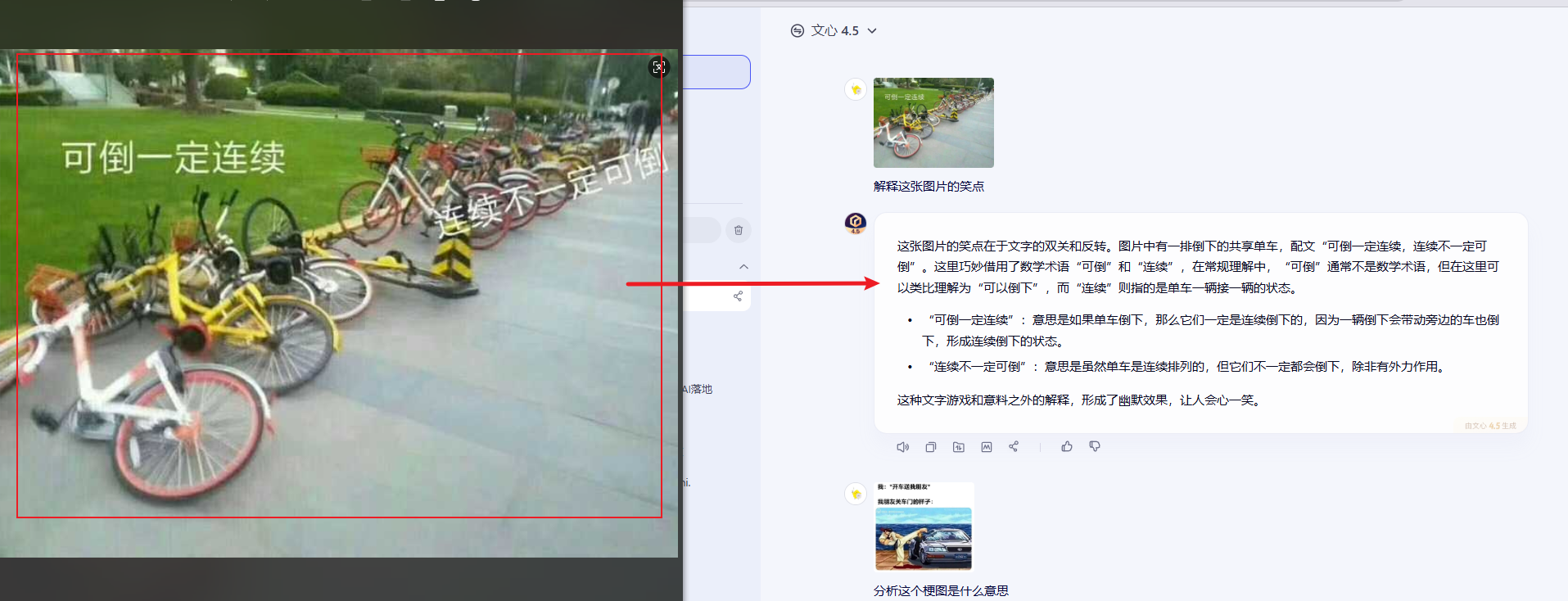
在第二组测试中,我选取了一张反映生活文化的梗图。文心4.5回答道:这个梗图通过幽默的方式表达了一种生活中常见的尴尬场景。这种夸张的表现手法意在调侃一些人在关车门时用力过猛的行为,可能会让车主感到心疼或无奈。
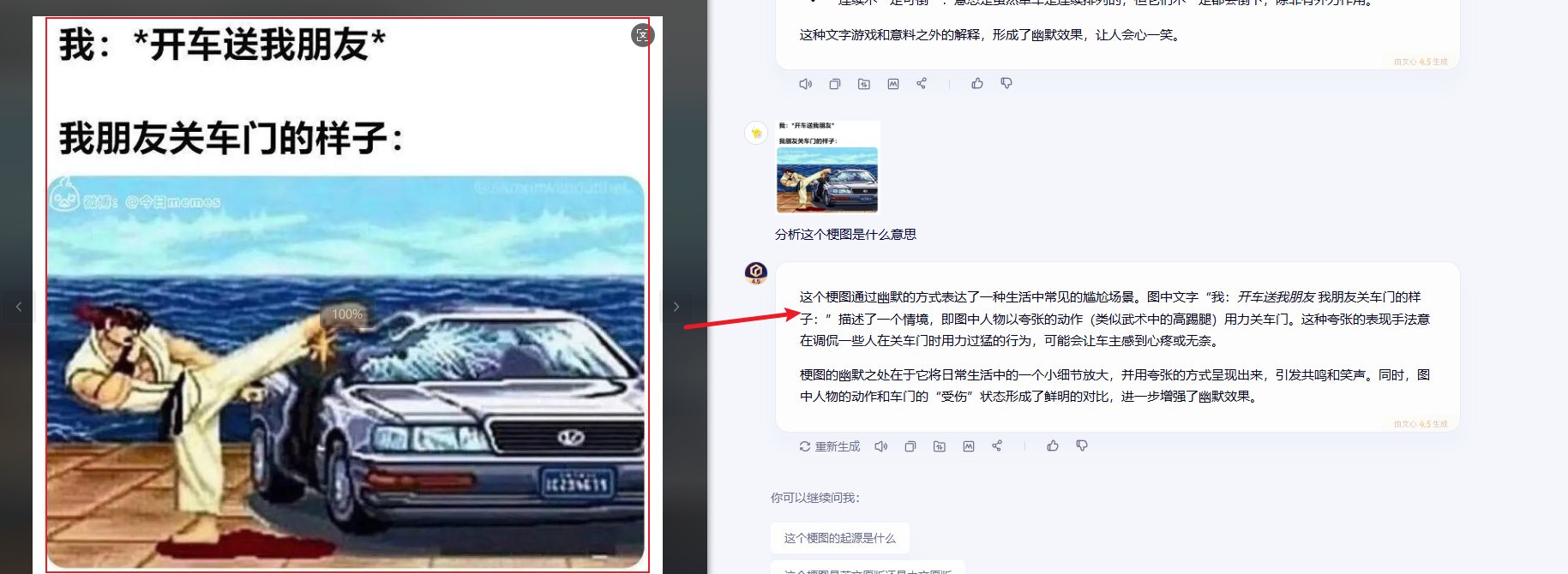
其不仅识别了图像元素,还捕捉到了文化里的微妙情绪。这种对细节的敏锐捕捉,源于其多模态异构专家扩展技术,通过自适应模态感知损失函数,解决了不同模态梯度不均衡问题,让模型在处理跨模态任务时表现得游刃有余。
这种对生活细节和情感维度的精准把握,体现了模型深层的文化理解能力,这源于百度创新的多模态异构专家扩展技术:首先,自适应模态感知损失函数有效解决了跨模态任务中的梯度不均衡问题;其次,FlashMask动态注意力掩码技术实现了对关键信息的精准聚焦。这两项核心技术共同作用,使模型在"谐音梗""文化隐喻"等传统视觉模型难以处理的复杂语义任务上,展现出类人的逻辑推理和情感共鸣能力,真正实现了"有逻辑的视觉理解"。
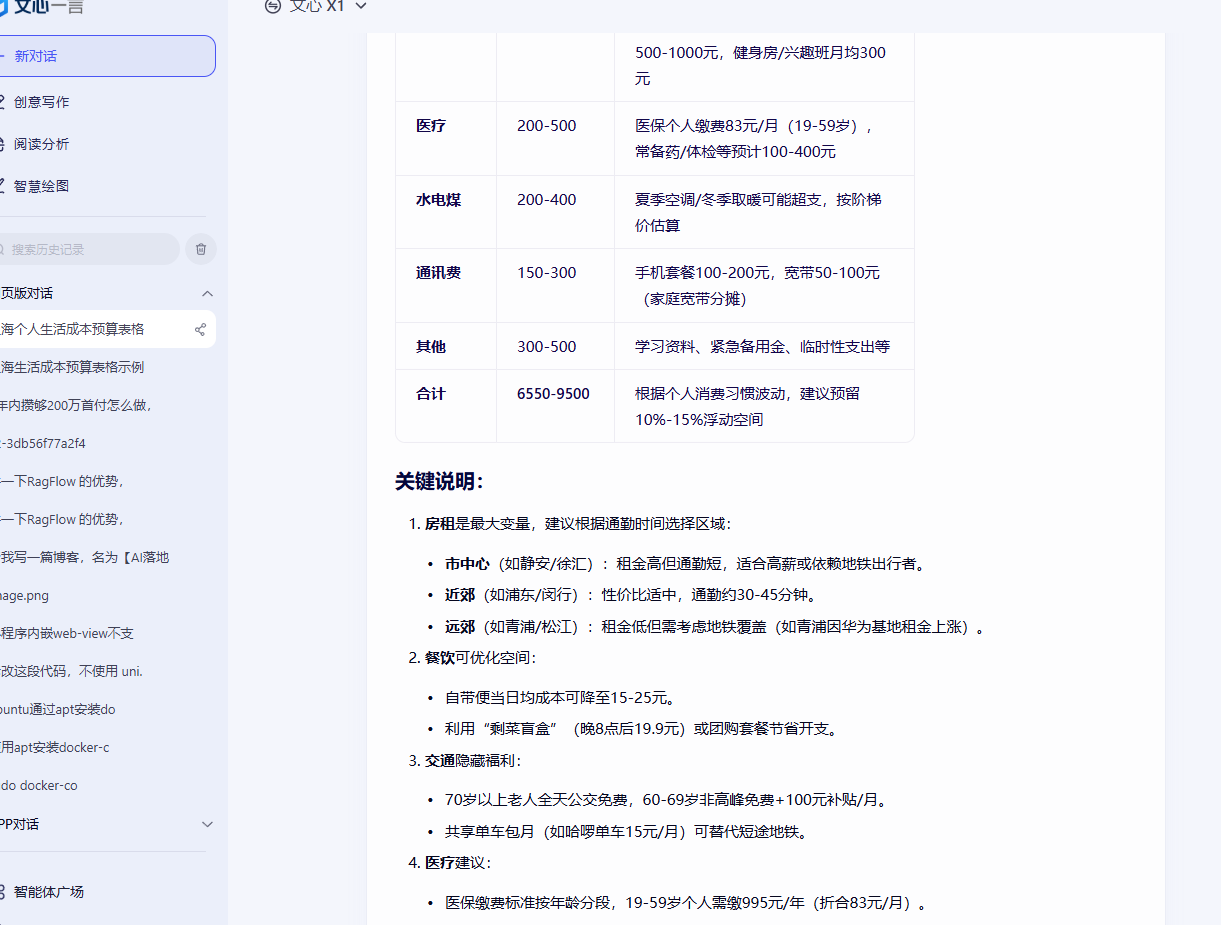
文心X1则在深度思考能力展现出相当的优势。比如,这里我询问一个人在上海的生活成本,并让他列出预算表格。文心X1不仅调用高级联网获取实时数据优化了预算方案。它不仅列出了每月的房租、交通、餐饮等基本开支,还预留了应急资金。
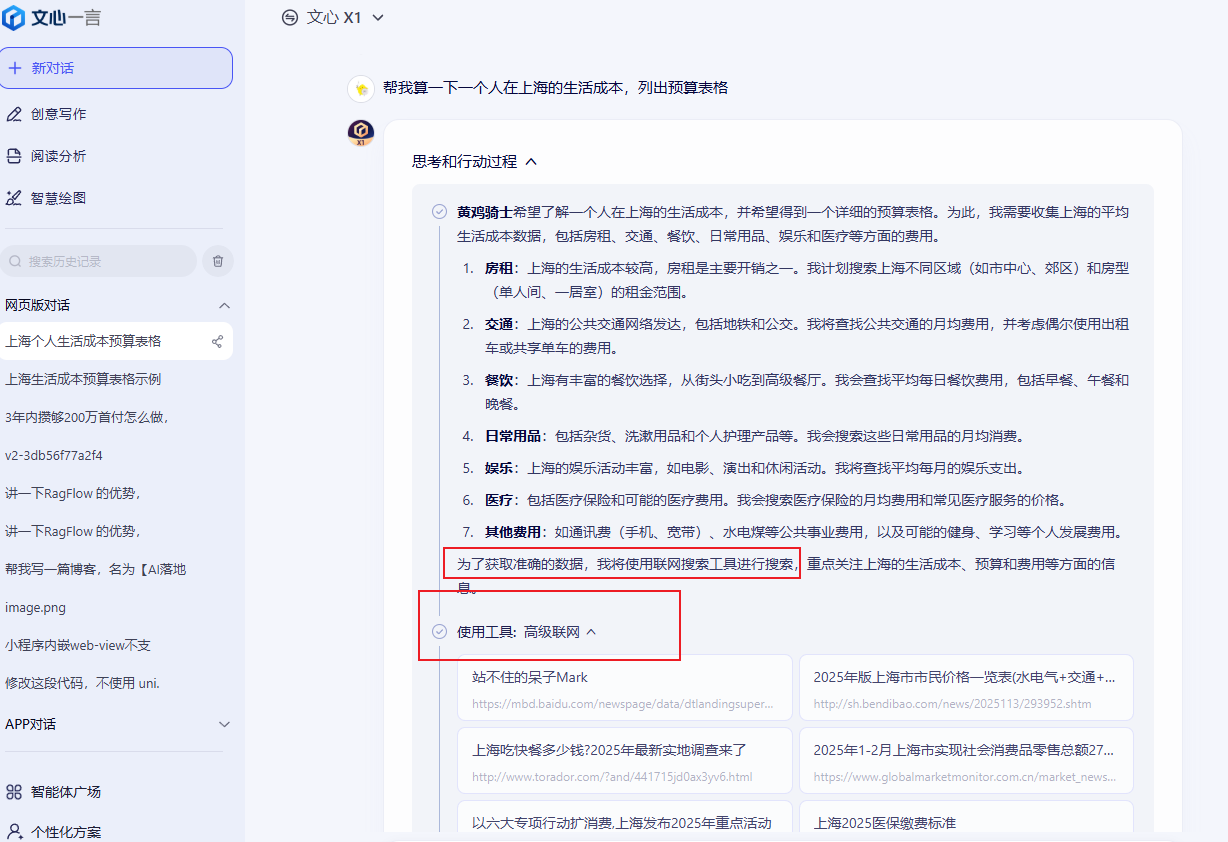
值得一提的是,X1还支持多工具调用,目前已支持高级搜索、文档问答、图片理解、AI绘图、代码解释器、网页链接读取、TreeMind树图、百度学术检索、商业信息查询、加盟信息查询、词云生成等多款工具。
这里我测试了下,输入“生成2024年网络热梗的TreeMind图”,在思考和行动过程中,可以看到文心X1迅速调用了高级搜索工具,从多个数据源获取了最新的网络热梗列表。然后,它利用代码解释器对数据进行处理和分析,生成了一个TreeMind树图。整个过程无需人工干预,模型自主完成了从数据获取到可视化呈现的全流程任务。
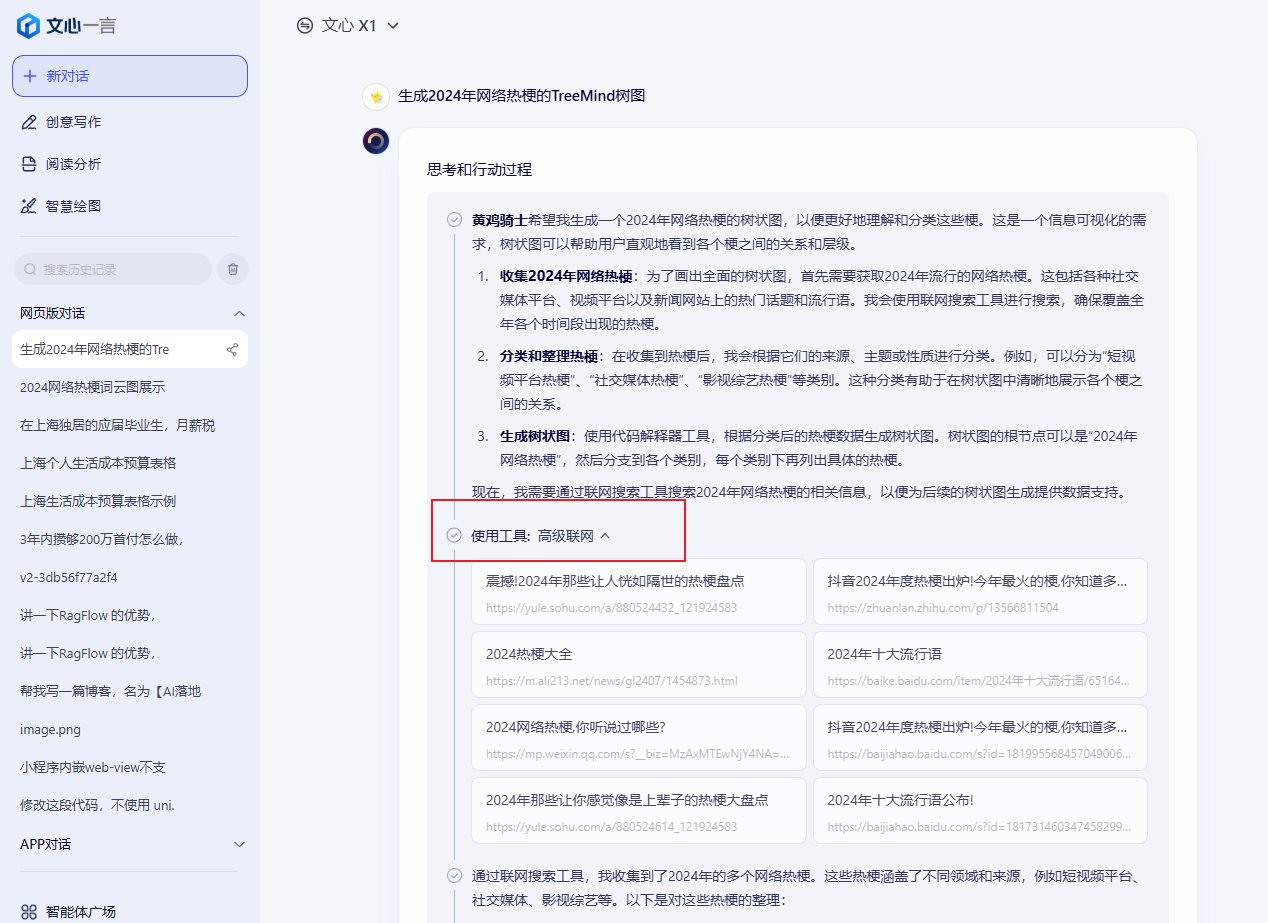
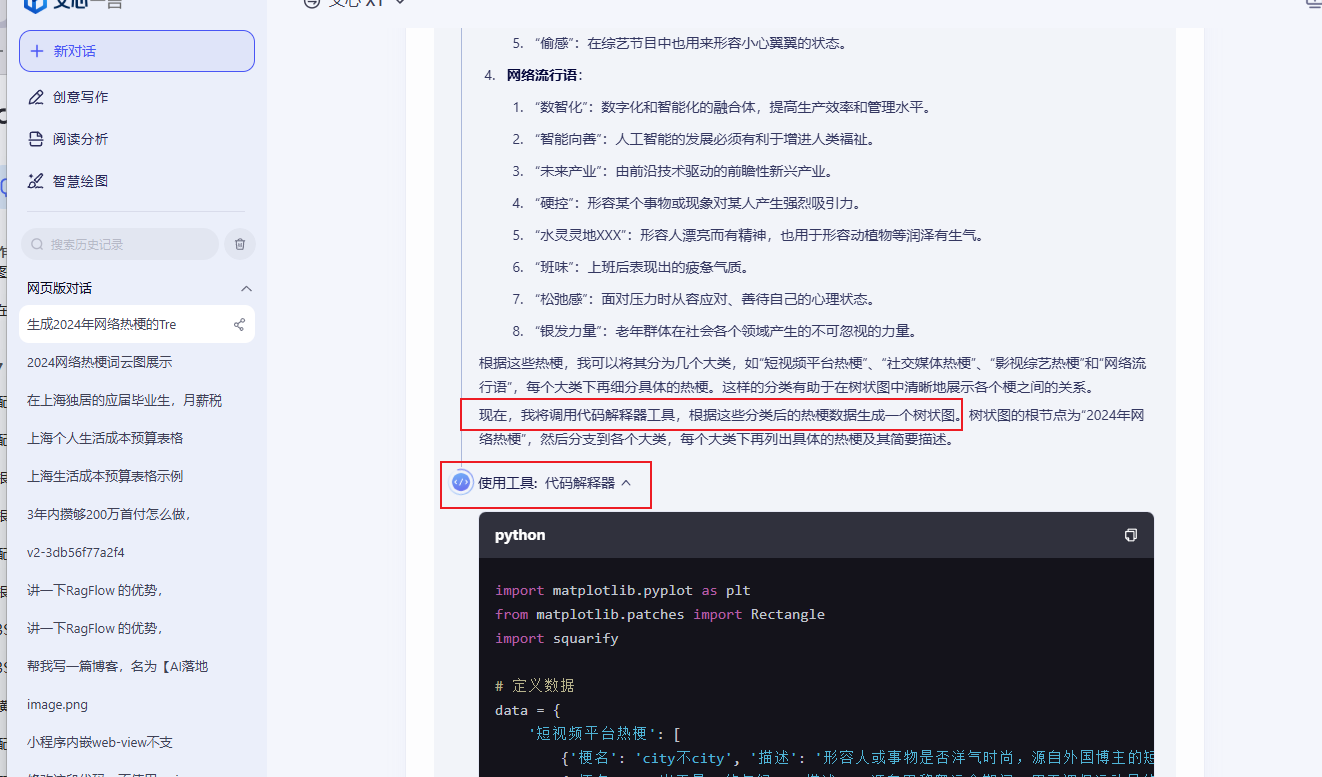
这种“规划+执行”的能力,得益于其递进式强化学习和端到端训练技术,使得模型在复杂任务中能够进行多步推理并给出合理的解决方案。
在价格方面,文心大模型4.5输入价格为0.004元/千tokens,输出0.016元/千tokens,约为GPT4.5价格的1%,而文心大模型X1价格仅为DeepSeek R1一半,输入0.002元/千tokens,输出0.008元/千tokens,即将发布的文心4.5 Turbo推理价格或将再创新低,为行业客户提供更好的服务。
三、新一代文心4.5 Turbo即将亮相,或将比文心4.5全面升级
在测试文心系列模型的过程中,最打动我的不是冰冷的基准测试分数,而是那些真实的落地场景:当4.5生成的甄嬛骑摩托图让我会心一笑时,当X1用代码生成的科学图表让我省时省力时,我看到了技术最本真的价值——它正在成为开发者延伸的"手和脑"。
从文心4.5和文心X1的优势能力推测,文心4.5 Turbo会迎来全面升级,尤其会在开发者最关心的价格和生成速度上再次实现突破。
有内部人士透露,这一版本将在保持文心4.5多模态优势的基础上,实现响应速度和成本效益的双重突破。
在这个AI技术快速迭代的时代,百度通过文心系列大模型的持续进化,正在构建一个更加开放的智能生态。
对于我们普通开发者而言,我感觉文心4.5 Turbo的发布将带来三个维度的变革:首先,实时交互能力的大幅提升使得多模态应用的开发门槛显著降低,开发者可以轻松构建支持即时图文生成的创意工具;其次,推理效率的优化让毫秒级响应的智能对话系统成为可能,这将彻底改变人机交互的体验标准;最重要的是,知识图谱等企业级AI应用的开发成本将大幅下降,小团队和个人也能快速搭建专业级的智能解决方案。
这种"技术温度"的传递,或许正是百度大模型持续迭代的深层意义所在——不是追逐虚幻的指标,而是让每个普通人都能感受到AI带来的改变。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 5
5 0
0- 0



 已为社区贡献86条内容
已为社区贡献86条内容

所有评论(0)