
Hadoop2.5.2完全分布式环境搭建
Hadoop2.5.2完全分布式环境搭建本文搭建Hadoop 2.5.2版本的完全分布式系统,主要是 HDFS HA,忽略了ResourceManger HA 、Web ApplicationProxy 和Job HistoryServer。 软件版本信息dk: jdk-8u111-linux-x64.tar.gzhadoop: hadoop-2.5
Hadoop2.5.2完全分布式环境搭建
本文搭建Hadoop 2.5.2版本的完全分布式系统,主要是 HDFS HA,忽略了ResourceManger HA 、Web Application Proxy 和Job HistoryServer。
软件版本信息
jdk: jdk-8u111-linux-x64.tar.gz
hadoop: hadoop-2.5.2.tar.gz
vmware: VMware_workstation_full_12.5.0.11529
ubuntu: ubuntu-16.04.1-server-amd64.iso
zookeeper:zookeeper-3.4.9.tar.gz
参考资料:
http://www.aboutyun.com/thread-9115-1-1.html
一 概述
1. HDFS
基础架构
1.1. NameNode(Master)
· 命名空间管理:命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。
· 块存储管理
1.2. DataNode(Slaver)
namenode和client的指令进行存储或者检索block,并且周期性的向namenode节点报告它存了哪些文件的block。
2. HDFS HA架构
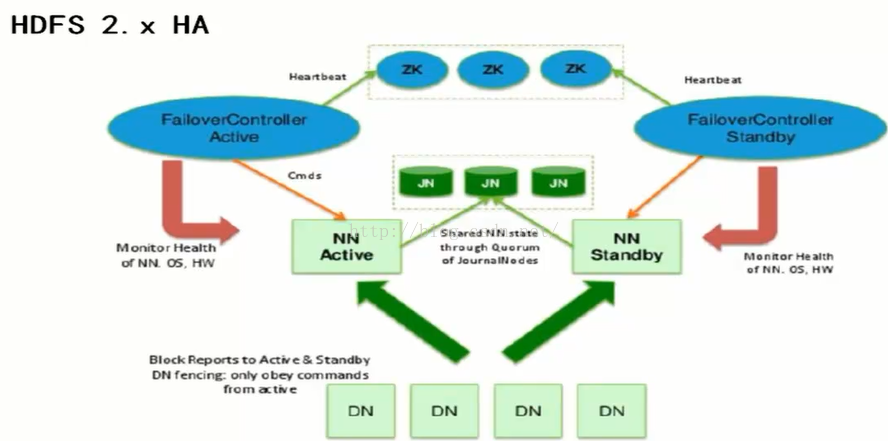
使用Active NameNode,Standby NameNode两个结点解决单点问题,两个结点通过JounalNode共享状态,通过ZKFC选举Active,监控状态,自动备援。
2.1 Active NameNode:
接受client的RPC请求并处理,同时写自己的Editlog和共享存储上的Editlog,接收DataNode的Block report,block location updates和heartbeat。
2.2 Standby NameNode:
同样会接到来自DataNode的Block report, block location updates和heartbeat,同时会从共享存储的Editlog上读取并执行这些log操作,使得自己的NameNode中的元数据(Namespcae information + Block locations map)都是和Active NameNode中的元数据是同步的。所以说Standby模式的NameNode是一个热备(Hot StandbyNameNode),一旦切换成Active模式,马上就可以提供NameNode服务。
2.3 JounalNode:
用于Active NameNode, Standby NameNode同步数据,本身由一组JounnalNode结点组成,该组结点奇数个。
2.4 ZKFC:
监控NameNode进程,自动备援。
3. YARN
基础架构
3.1 ResourceManager(RM)
接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
3.2 NodeManager
节点上的资源管理,启动Container运行task计算,上报资源、container情况给RM和任务处理情况给AM。
3.3 ApplicationMaster
单个Application(Job)的task管理和调度,向RM进行资源的申请,向NM发出launch Container指令,接收NM的task处理状态信息。NodeManager
3.4 Web Application Proxy
用于防止Yarn遭受Web攻击,本身是ResourceManager的一部分,可通过配置独立进程。ResourceManagerWeb的访问基于守信用户,当Application Master运行于一个非受信用户,其提供给ResourceManager的可能是非受信连接,Web Application Proxy可以阻止这种连接提供给RM。
3.5 Job History Server
NodeManager在启动的时候会初始化LogAggregationService服务,该服务会在把本机执行的container log (在container结束的时候)收集并存放到hdfs指定的目录下.ApplicationMaster会把jobhistory信息写到hdfs的jobhistory临时目录下,并在结束的时候把jobhisoty移动到最终目录,这样就同时支持了job的recovery.History会启动web和RPC服务,用户可以通过网页或RPC方式获取作业的信息
二 节点规划
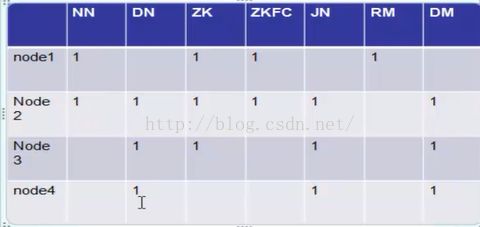
1说明在该节点上部署,例如NN(nameNode)在node1和node2上部署。
其中,ZKFC必须和NN在同一个节点上。
共有以下4个节点:
node1: 192.168.233.129
node2: 192.168.233.130
node3: 192.168.233.131
node4: 192.168.233.132
三 搭建步骤
1. 将节点ip地址与hostname绑定
vi /etc/hosts
然后对里面的内容修改:
127.0.0.1 localhost
127.0.1.1 node1
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.233.129 node1
192.168.233.130 node2
192.168.233.131 node3
192.168.233.132 node4
注意4个节点都修改。
2. 设置ssh密码免登陆
首先在节点node1上生成秘钥:
root@node1:~# ssh-keygen -t rsa
Generating public/private rsa keypair.
Enter file in which to save thekey (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for nopassphrase):
Enter same passphrase again:
Your identification has beensaved in /root/.ssh/id_rsa.
Your public key has been saved in/root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:2QRbW8iRXpuqAfL2CBj/qPYgHDlYAyHkEGMLXtVGOOEroot@node1
The key's randomart image is:
+---[RSA 2048]----+
|X= ..o=...o+. |
|Boo .o o ++o. |
| +o Eo ..o. o |
|..o.. . +. o |
|.+ + o .S .. |
|. + o o . . |
|... = o o |
| .... o o |
| ..o. |
+----[SHA256]-----+
上面命令执行过程中如果停顿下来要输入,直接按enter键。
##使用另一种方法(ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa)直接生成秘钥不管用,无法免密码登录,搜索半天没有找到解决方法
##看来还得多试验,找到自己系统能跑通的方法。
##最后发现原来是有两种生成秘钥的算法:RSA 和 DSA
##我的ubuntu系统不支持DSA,只支持RSA的,不知道为啥。
然后使用命令
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将node1的公钥放到~/.ssh/authorized_keys中,这样node1就可以免密码登录本身node1。
再将node1生成的公钥传到node2上:
root@node1:~# scp /root/.ssh/id_rsa.pub root@node2:~
登录Node2,将node1传过来的公钥追加到自身的认证文件后
root@node2:~# cat id_rsa.pub >>.ssh/authorized_keys
此时,从nose1就可以免密码登录node2了。
其余节点类似。
3. 上传文件
将hadoop-2.5.2.tar.gz上传到node1,并解压到目录/usr/local/hadoop/
root@node1:/usr/local/hadoop/hadoop-2.5.2# l
bin/ etc/ include/ lib/ libexec/ LICENSE.txt NOTICE.txt README.txt sbin/ share/
4. 设置环境变量
首先设置系统环境变量
vi ~/.bashrc
export JAVA_HOME=/usr/local/java/jdk1.8.0_111
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
exportPATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.5.2
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
然后 source ~/.bashrc
然后设置hadoop的环境变量
打开$HADOOP_HOME/etc/hadoop-env.sh
root@node1:/usr/local/hadoop/hadoop-2.5.2/etc/hadoop#vi hadoop-env.sh
将JAVA_HOME的全路径写上,注意这里必须是写全路径,不能用${JAVA_HOME},否则hadoop找不到JAVA_HOME
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/local/java/jdk1.8.0_111
5.配置 $HADOOP_HOME/etc/hdfs-site.xml
root@node1:/usr/local/hadoop/hadoop-2.5.2/etc/hadoop#more hdfs-site.xml
<?xmlversion="1.0" encoding="UTF-8"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<!--
Licensed under theApache License, Version 2.0 (the "License");
you may not usethis file except in compliance with the License.
You may obtain acopy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless requiredby applicable law or agreed to in writing, software
distributedunder the License is distributed on an "AS IS" BASIS,
WITHOUTWARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the Licensefor the specific language governing permissions and
limitationsunder the License. See accompanying LICENSE file.
-->
<!-- Putsite-specific property overrides in this file. -->
<configuration>
#
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
##namenode节点名
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
##两个namenode的RPC协议端口
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
##两个namenode的HTTP协议的端口
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
#JN node的地址端口
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node2:8485;node3:8485;node4:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
#JN node的工作目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/jndata/data</value>
</property>
#开启自动切换
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
6.配置 $HADOOP_HOME/etc/core-site.xml
root@node1:/usr/local/hadoop/hadoop-2.5.2/etc/hadoop#more core-site.xml
<?xml version="1.0"encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0(the "License");
you may not use this file except in compliancewith the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to inwriting, software
distributed under the License is distributed on an"AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,either express or implied.
See the License for the specific languagegoverning permissions and
limitations under the License. See accompanyingLICENSE file.
-->
<!-- Put site-specific property overrides in thisfile. -->
<configuration>
#namenode的入口
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
#ZK
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
#hadoop的临时工作目录
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadooptempdata</value>
</property>
7.配置 $HADOOP_HOME/etc/slaves
slaves中保存的是datanode的节点名
root@node1:/usr/local/hadoop/hadoop-2.5.2/etc/hadoop#more slaves
node2
node3
node4
因为上面规划中,datanode节点在node2,node3,node4中,所以这里就是填node2,node3,node4
--最后把上面的所有内容包括配置文件拷贝到node2,node3,node4中同样目录下。
8. 安装稳定版的zookeeper
http://mirror.bit.edu.cn/apache/zookeeper/stable/
这里下载的是最新的3.4.9稳定版
解压到路径/usr/local/zookeeper-3.4.9
8.1 配置zookeeper配置文件
根据官网介绍http://zookeeper.apache.org/doc/r3.4.9/zookeeperStarted.html
copy一个zoo.cfg
root@node1:/usr/local/zookeeper-3.4.9/conf# cp zoo_sample.cfg zoo.cfg
配置内容如下
root@node1:/usr/local/zookeeper-3.4.9/conf# more zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
dataDir=/usr/local/hadooptempdata
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
8.2 配置zookeeper的myid
进入dataDir=/usr/local/hadooptempdata 这个目录
创建文件名myid,并输入id号
root@node1:/usr/local/zookeepertempdata# more myid
1
这个myid文件的id值,说明当前是第几个server,在node1节点上是第一个server,所以是1,在节点node2上,值就是2.
8.3 拷贝到其余机器上
将node1上的zookeeper所有文件拷贝到node2和node3上,注意文件myid的值要修改
8.4 配置zookeeper环境变量
root@node1:/usr/local/zookeeper-3.4.9/bin# vi ~/.bashrc
在最下面增加如下两行
export ZK_PATH=/usr/local/zookeeper-3.4.9
export PATH=$PATH:$ZK_PATH/bin
每个zookeeper节点下都加上。
9. 启动 journalnode
根据配置规划,journalnode安装在node2,node3.node4上
登录node2,node3,node4,分别进行如下操作:
进入$HADOOP_HOME/sbin目录,单独启动某个节点的命令是 ./hadoop-daemon.sh start
单独启动JN的命令就是:
root@node2:/usr/local/hadoop/hadoop-2.5.2/sbin#./hadoop-daemon.sh start journalnode
starting journalnode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-journalnode-node2.out
查看是否启动成功:
root@node2:/usr/local/hadoop/hadoop-2.5.2/sbin# jps
2872 QuorumPeerMain
2796 JournalNode
2893 Jps
已经成功启动了
10. 格式化nanenode
JN全部启动之后,新创建的HDFS集群需要格式化namanode。
namenode安装在node1和node2上,先在其中一个节点上格式化,例如先在node1上格式化,再同步到node2上。
进入node1的$HADOOP_HOME/bin目录
输入命令:
root@node1:/usr/local/hadoop/hadoop-2.5.2/bin# hdfsnamenode -format
启动日志最后显示:
16/11/26 21:41:37 INFO common.Storage: Storage directory/usr/local/hadooptempdata/dfs/namehas beensuccessfully formatted.
16/11/26 21:41:38 INFOnamenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
16/11/26 21:41:38 INFO util.ExitUtil: Exiting with status0
16/11/26 21:41:38 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode atnode1/192.168.233.129
表示格式化成功。
即初始化获得了元数据文件
在配置的临时路径hadoop.tmp.dir 下,就有了fsimage文件
root@node1:/usr/local/hadooptempdata/dfs/name/current# ll
total 24
drwxr-xr-x 2 root root 4096 Nov 26 21:41 ./
drwxr-xr-x 3 root root 4096 Nov 26 21:41 ../
-rw-r--r-- 1 root root 351 Nov 26 21:41fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Nov 26 21:41fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 Nov 26 21:41seen_txid
-rw-r--r-- 1 root root 208 Nov 26 21:41 VERSION
现在这个fsimage文件只在node1上有,需要拷贝到node2上,拷贝之前需要先启动node1上的namenode。
11. 启动namenode
进入目录root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin,只启动namenode
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin#./hadoop-daemon.sh start namenode
starting namenode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-namenode-node1.out
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin# jps
1713 QuorumPeerMain
1830 NameNode
1885 Jps
表明namenode已经成功启动。
12. 拷贝元数据
node1上元数据已经初始化,现在需要在没有初始化的节点上进行拷贝操作。
登录node2的bin目录,执行命令:
root@node2:/usr/local/hadoop/hadoop-2.5.2/bin# ./hdfsnamenode -bootstrapStandby
成功之后去node2的临时目录里查看元数据
root@node2:/usr/local/hadooptempdata/dfs/name/current# ll
total 24
drwxr-xr-x 2 root root 4096 Nov 26 21:57 ./
drwxr-xr-x 3 root root 4096 Nov 26 21:57 ../
-rw-r--r-- 1 root root 351 Nov 26 21:57fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Nov 26 21:57fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 Nov 26 21:57seen_txid
-rw-r--r-- 1 root root 208 Nov 26 21:57 VERSION
发现也有了,之后就可以启动node2上的namenode了。
13. 全部启动进程
起单个进程比较慢,下面练习一次启动全部hdfs进程:
先关闭全部hdfs进程,zookeeper除外
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin# ./stop-dfs.sh
Stopping namenodes on [node1 node2]
node2: no namenode to stop
node1: stopping namenode
node2: no datanode to stop
node1: no datanode to stop
node3: no datanode to stop
Stopping journal nodes [node2 node3 node4]
node2: stopping journalnode
node3: stopping journalnode
node4: stopping journalnode
Stopping ZK Failover Controllers on NN hosts [node1node2]
node1: no zkfc to stop
node2: no zkfc to stop
再打开全部hdfs进程
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin# ./start-dfs.sh
Starting namenodes on [node1 node2]
node1: starting namenode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-namenode-node1.out
node2: starting namenode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-namenode-node2.out
node1: starting datanode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-datanode-node1.out
node2: starting datanode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-datanode-node2.out
node3: starting datanode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-datanode-node3.out
Starting journal nodes [node2 node3 node4]
node3: starting journalnode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-journalnode-node3.out
node2: starting journalnode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-journalnode-node2.out
node4: starting journalnode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-journalnode-node4.out
Starting ZK Failover Controllers on NN hosts [node1node2]
node2: starting zkfc, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-zkfc-node2.out
node1: starting zkfc, logging to /usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-zkfc-node1.out
使用jps命令查看启动进程
发现namenode,datanode ,journalnode都启动了,但是zkfc没有启动。
查看zkfc的启动日志:
root@node1:/usr/local/hadoop/hadoop-2.5.2/logs# tail -n50hadoop-root-zkfc-node1.log
2016-11-26 22:33:48,971 FATALorg.apache.hadoop.ha.ZKFailoverController: Unable to start failover controller.Unable to connect to ZooKeeper quorum at node1:2181,node2:2181,node3:2181.Please check the configured value for ha.zookeeper.quorum and ensure thatZooKeeper is running.
这种问题在网上搜了下,没有几条答复,都说检测下防火墙和ha.zookeeper.quorum配置项,这都没有问题,
最后重启了一下zookeeper就行了。
zkfc第一次启动之前,还需要初始化一下:
在其中任意一个nanenode节点上执行即可。
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin# hdfs zkfc-formatZK
成功之后,在开启所有hdfs节点
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin# ./start-dfs.sh
14. 在win10系统上,通过浏览器访问node1的50070端口
在浏览器上,输入ip:port方法访问nanenode
http://192.168.233.129:50070
注意这里不要输入http://node1:50070,因为win10系统可能还没有配置node1和ip的对应关系,会访问不了。
hadoop的端口介绍,参考http://www.tuicool.com/articles/BB3eArJ
例如:

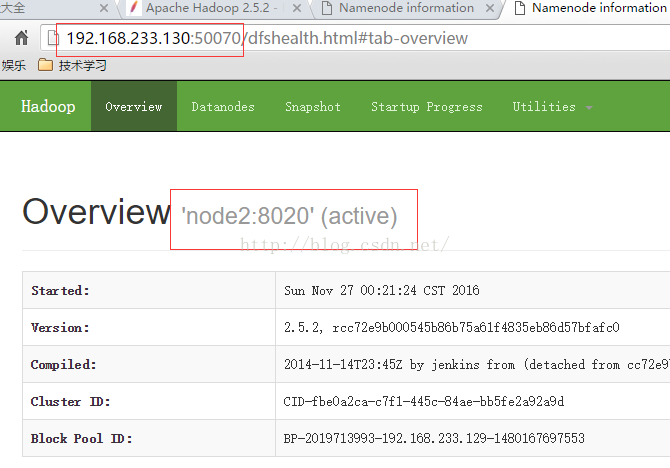
node1和node2,谁先抢到zookeeper的锁,谁就是active。
15. 使用hdfs dfs 命令创建上传文件目录
参考
hadoop hdfs dfs 命令讲解: http://blog.csdn.net/u010220089/article/details/45937417
hadoop fs、hadoop dfs与hdfs dfs命令的区别:http://blog.csdn.net/pipisorry/article/details/51340838
首先创建目录,用于存放hdfs文件
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin# hdfs dfs -mkdir -p /usr/local/hadooptempdata/hdfsfile
然后上传一个文件
root@node1:/usr/local/hadoop/hadoop-2.5.2/sbin# hdfs dfs -put /usr/local/jdk-8u111-linux-x64.tar.gz/usr/local/hadooptempdata/hdfsfile
将 /usr/local/jdk-8u111-linux-x64.tar.gz这个170M左右的大文件上传。
由于一个block的默认大小是128M,所以这个170M的文件会分成两个block。
刷新浏览器,进入Browse the file system界面
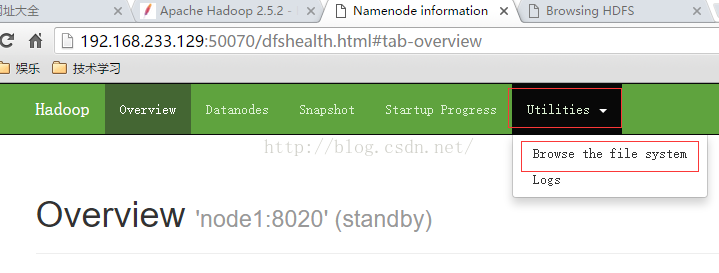

在这里能看到上传的文件jdk-8u111-linux-x64.tar.gz,点击这个文件名
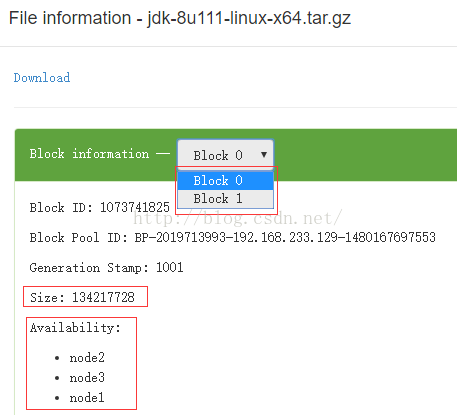
显示这个文件分成了Block 0 和 Block 1 两个块。
其中Block 0 的大小是134217728 byte =128M
分别在node1,node2,node3上都有一个副本。
但是这个文件夹和文件在后台是看不到的。
16. 修改$HADOOP_HOME/etc/yarn-env.sh
只定义日志路径即可
export YARN_LOG_DIR="/usr/local/hadoop/hadoop-2.5.2/logs"
17. 修改$HADOOP_HOEM/etc/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
制定mapreduce的工作框架是yarn
18. 修改$HADOOP_HOME/etc/yarn-site.xml
<configuration>
<!-- Site specific YARN configurationproperties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
参考:
http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/SingleCluster.html
http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/ClusterSetup.html
将这几步的修改也同步拷贝到所有节点。
19. 启动全部进程
现在node1,node2,node3上启动zookeeper
root@node1:/usr/local/hadoop/hadoop-2.5.2#zkServer.sh start
然后在node1上启动全部
root@node1:/usr/local/hadoop/hadoop-2.5.2#start-all.sh
This script is Deprecated. Instead usestart-dfs.sh and start-yarn.sh
Starting namenodes on [node1 node2]
node2: starting namenode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-namenode-node2.out
node1: starting namenode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-namenode-node1.out
node1: starting datanode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-datanode-node1.out
node3: starting datanode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-datanode-node3.out
node2: starting datanode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-datanode-node2.out
Starting journal nodes [node2 node3 node4]
node4: starting journalnode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-journalnode-node4.out
node3: starting journalnode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-journalnode-node3.out
node2: starting journalnode, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-journalnode-node2.out
Starting ZK Failover Controllers on NNhosts [node1 node2]
node2: starting zkfc, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-zkfc-node2.out
node1: starting zkfc, logging to/usr/local/hadoop/hadoop-2.5.2/logs/hadoop-root-zkfc-node1.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/hadoop-2.5.2/logs/yarn-root-resourcemanager-node1.out
node1: starting nodemanager, logging to/usr/local/hadoop/hadoop-2.5.2/logs/yarn-root-nodemanager-node1.out
node3: starting nodemanager, logging to/usr/local/hadoop/hadoop-2.5.2/logs/yarn-root-nodemanager-node3.out
node2: starting nodemanager, logging to/usr/local/hadoop/hadoop-2.5.2/logs/yarn-root-nodemanager-node2.out
root@node1:/usr/local/hadoop/hadoop-2.5.2#jps
2512 Jps
1985 DataNode
2341 ResourceManager
1702 QuorumPeerMain
2463 NodeManager
1871 NameNode
有DataNode的地方就有NodeManager。
20. 查看resourceManager的web界面
因为yarn的resourceManager配置在node1上。
在浏览器中打开http://192.168.233.129:8088/
就能看到界面展示:
至此,环境搭建完毕,全部进程都已启动,并能通过浏览器查看hdfs和resourceManager的界面展示。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)