
Agent Skill深度拆解:原理+各大主流Agent实现,一篇看懂
最近,似乎无论走到哪里都能听到一个词——“Skill”。随着“龙虾”的火爆出圈,这个早在去年10月就备受讨论的“新概念”再度冲上热搜。其实,早在2025年4月谷歌推出A2A(Agent-to-Agent)协议时,“Agent Skill”的雏形便已出现;但真正让它从概念走向行业规范,是在25年10月Claude Code发布“Agents Skill”功能之后。如今,它已演变为各大Agent开发厂
什么是Agent SKILL
最近,似乎无论走到哪里都能听到一个词——“Skill”。随着“龙虾”的火爆出圈,这个早在去年10月就备受讨论的“新概念”再度冲上热搜。其实,早在2025年4月谷歌推出A2A(Agent-to-Agent)协议时,“Agent Skill”的雏形便已出现;但真正让它从概念走向行业规范,是在25年10月Claude Code发布“Agents Skill”功能之后。如今,它已演变为各大Agent开发厂商共同遵守的标准协议。
优点
- 一次构建多个产品使用:目前已经作为事实标准被各个Agent产品使用,例如:cursor、codex等
- 可用于企业内部专业知识沉淀,知识转化成的skill文件夹具备版本控制和多平台移植能力,。
- 开箱即用,通过技能扩展机制,用户可即时为智能体拓展新功能。
- 工作流标准化:将多步骤任务转化为可重复执行、可审计的标准化工作流。
文件夹结构
核心结构简单直接:每个技能本质上是一个包含SKILL.md文件的文件夹。
该文件至少包含技能元数据(名称与描述)和执行指导,用于告知智能体如何完成特定任务。
技能文件夹还可集成配套的脚本、模板和参考资料,形成完整的能力封装包。
my-skill/
├── SKILL.md # 必须: instructions + metadata
├── scripts/ # 可选: executable code
├── references/ # 可选: documentation
└── assets/ # 可选: templates, resources等静态文件
工作机制
技能采用渐进式上下文加载机制,以实现高效的上下文管理:
发现:启动时,智能体仅加载每个可用技能的元数据(名称与描述),初步建立任务匹配索引。
激活:当任务需求与技能描述匹配时,智能体将完整SKILL.md执行指令载入上下文环境。
执行:智能体遵循指令执行任务,并可根据需要加载引用的资源文件或运行内置代码。
SKILL.md详细规范
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
---
......
| 字段名 | 必填 | 约束条件 |
|---|---|---|
name |
是 | 最多64个字符,仅允许小写字母、数字、-服务。不得以连字符开头或结尾。 |
description |
是 | 最多1024个字符,不可为空。描述该技能的功能及适用场景。 |
license |
否 | 证书类型。 |
compatibility |
否 | 最多500个字符。声明环境要求(目标产品、系统依赖包、网络访问权限等)。 |
metadata |
否 | 用于存储附加元数据的任意键值对映射。 |
allowed-tools |
否 | 以空格分隔的预批准工具列表,表示该技能允许调用的工具。(实验性功能) |
命名规范:✅ notion-project-setup ❌ Notion_Project_Setup
SKILL架构
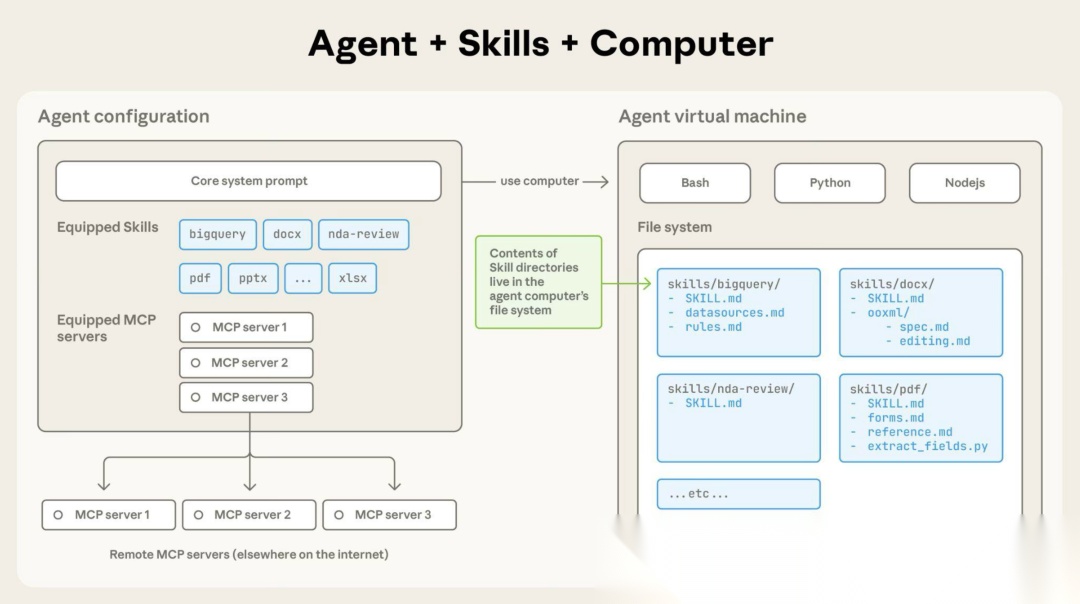
这张图揭示了 SKILL 架构最关键的一点:元数据在上下文,内容在文件系统。
Agent 上下文 → 只有 skill 的 name + description(轻量)
Agent 虚拟机文件系统 → 完整的 SKILL.md + 参考文档 + 脚本(按需读取)
开源Agent框架实现
这里参考了几个开源的Agent项目中如何支持agentskill协议
DeepAgents
基于 LangGraph 的 Agent Builder 项目,通过 AgentMiddleware 支持 SKILL,利用文件工具、代码执行工具加载 SKILL 内容并执行脚本。
工作流程
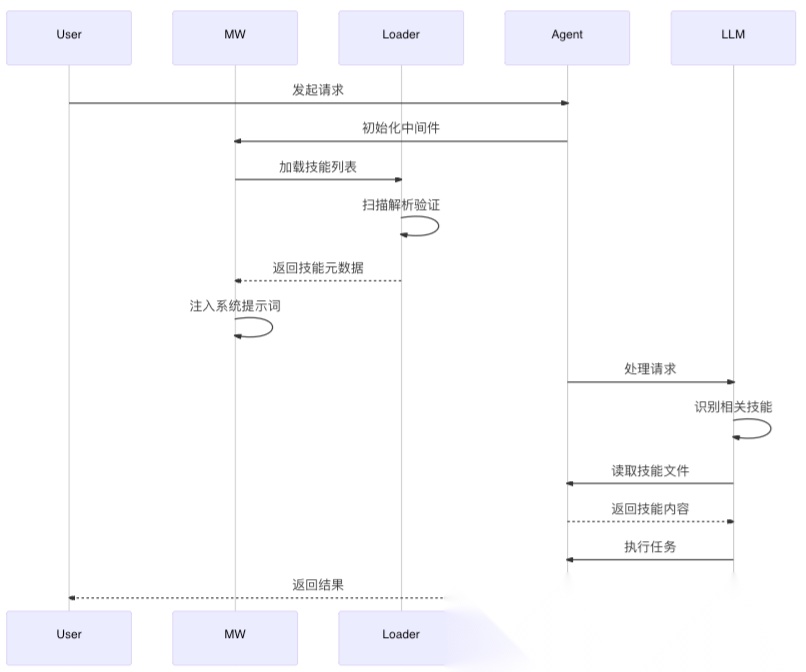
核心组件
Loader
负责加载本地 Agent SKILL 文件。
SkillsMiddleware
基于 LangChain 的 AgentMiddleware 实现,提供钩子能力:
- before_agent:将 SKILL 列表注入 Agent 状态字典
- wrap_model_call:在
system_prompt中注入所有 SKILL 描述和本地路径
Agent
基于 create_agent 创建,封装中间件:
- FilesystemMiddleware:注入文件处理、Shell 指令等工具
- SkillsMiddleware:配合 FilesystemMiddleware 实现 SKILL 加载
特点
- 支持项目目录与 Agent 目录两级 SKILL 优先级加载
- 通过元工具(文件读取、命令执行)处理资源读取和脚本执行,不做额外封装
agent-framework
微软开源的 Python Agent 框架,通过 SkillsProvider(继承自 Context Provider)在模型调用前后添加钩子函数。
工作流程
1. 接入SKILL
# 先创建provider
skills_provider = SkillsProvider(
skill_paths=Path(__file__).parent / "skills"
)
# 创建agent, 将skills provider传入
agent = AzureOpenAIChatClient(credential=AzureCliCredential()).as_agent(
name="SkillsAgent",
instructions="You are a helpful assistant.",
context_providers=[skills_provider],
)
2. 模型调用前注入SKILL相关元数据
在 before_run 中将 SKILL 选择提示词注入 system_prompt,并新增两个工具:
SKILL 选择提示词
DEFAULT_SKILLS_INSTRUCTION_PROMPT = """\
You have access to skills containing domain-specific knowledge and capabilities.
Each skill provides specialized instructions, reference documents, and assets for specific tasks.
<available_skills>
{skills}
</available_skills>
When a task aligns with a skill's domain, follow these steps in exact order:
1. Use `load_skill` to retrieve the skill's instructions.
2. Follow the provided guidance.
3. Use `read_skill_resource` to read any referenced resources, using the name exactly as listed
(e.g. `"style-guide"` not `"style-guide.md"`, `"references/FAQ.md"` not `"FAQ.md"`).
Only load what is needed, when it is needed."""
工具
load_skill:加载指定 SKILLread_skill_resource:加载 SKILL 关联的资源文件
特点
- 支持通过代码自定义
SKILL对象,不局限于 SKILL 目录 - 将
SKILL.md外的文件称为resource,可自动注入 - 利用 Function Calling 分别加载
SKILL.md和指定资源,不支持脚本执行
Agno
Agno项目在Agent中扩展了skills属性,使用上需要传入skill load对象
工作方式
from agno.skills import SKILLs, LocalSKILLs
# 1. 创建 SKILLs 协调器,指定加载器
skills = SKILLs(
loaders=[
LocalSKILLs("/path/to/shared-skills"),
LocalSKILLs("/path/to/project-skills"),
]
)
agent = Agent(
model=OpenAIChat(id="gpt-4o"),
skills=skills
)
新定义的SKILLs对象中提供了系统提示词的注入以及读取skill的多个工具:
- get_skill_instructions:加载skill.md
- get_skill_reference:除skill.md外其他关联文件
- get_skill_script:执行script文件
特点
- 只支持本地目录下的skill加载,在合并的pr里有一段基于db方式加载skill的实现,但没进主分支。
- 将目录下SKILL.md以外的其他文件读取以及script执行。
pydantic-ai-skills
基于pydantic-ai开发的skills支持扩展包,pydantic官方认可,出于架构考虑没有合并到主仓库,而是以可选依赖方式提供。实现方式还是将skill的元数据加载、详情加载等方式作为Agent的工具集。
工作方式
在pydantic-ai,Agen通过导入SKILLsToolset创建基于SKILL的工具集,使用方式如下:
from pydantic_ai import Agent, SKILLsToolset
# Default: uses ./skills directory
agent = Agent(
model='openai:gpt-5.2',
instructions="You are a helpful assistant.",
toolsets=[SKILLsToolset()]
)
将 SKILL 分为三类对象:
- 元数据:来自
SKILL.md - resource:SKILL 目录下其他可解析文件
- script:
scripts/下的 Python 脚本
SKILLsToolset 提供四个工具:
list_skills:获取所有 SKILL 元数据load_skill:获取 SKILL 详情read_skill_resource:读取资源文件run_skill_script:执行 Python 脚本(本地执行,无沙箱)
特点
- 支持本地目录和代码自定义 SKILL、Resource、Script
- 利用 Tool Calling 分别加载SKILL资源和执行Script
- 支持 Python 脚本执行,但无沙箱环境
开源实现总结
1. SKILL加载方式多种
当前开源实现中,SKILL加载方式呈现多样化趋势,基本都支持本地文件加载,部分框架已实现基于代码定义、DB查询等方式的SKILL加载能力。
2. SKILL注入机制
SKILL注入普遍采用各自框架的Hook机制,在模型调用前将全部SKILL元数据注入系统提示词中,实现动态加载与上下文增强。
3. SKILL文件处理方式
SKILL相关文件的读取与执行,主流做法是封装为独立的Tool Call工具进行处理。少数实现采用“元工具”形式,直接提供文件读取、脚本执行等基础工具支持,为SKILL运行提供底层能力。
SKILL 实践规范
SKILL 辅助生成
Anthropic 官方提供 SKILL 生成工具,支持通过自然语言创建完整的 SKILL 项目,并具备技能审查、对话式改进等功能。下载地址
实践指南
1. 何时使用 SKILL
使用 SKILL 的前提是:“离开 SKILL,当前模型不知道该怎么做”。适用场景包括:
- 模型未知的领域知识:内部流程、私有术语、行业判断标准
- 复杂工作流指导:多步骤决策逻辑,需复用
- 增强工具调用能力:指导如何组合使用工具
2. 明确技能价值
编写 SKILL 前,先确定 2-3 个具体用例,清晰描述完整流程。
优秀示例:项目 Sprint 规划
- 触发条件:“帮我规划这个 sprint” 或 “创建 sprint 任务”
- 执行步骤:
- 从 Linear 获取当前项目状态(通过 MCP)
- 评估团队交付能力和可用资源
- 提供任务优先级建议
- 在 Linear 中创建带标签和估时的任务
- 最终结果:完成 sprint 规划并创建任务
关键思考:
- 用户目标是什么?
- 需要哪些多步骤工作流?
- 需要哪些工具支持?
- 应嵌入哪些领域知识和最佳实践?
3. 编写原则
- 原子化设计:一个 SKILL 只做一件事,避免万能工具
- 主文件精简:
SKILL.md保持简洁(建议 500 行以内),详细文档放在references/按需加载 - 有效的技能说明:采用 [功能说明] + [使用时机] + [关键能力] 结构,明确能力边界, 示例:
description: 分析 Figma 设计文件并生成开发者交接文档。当用户上传 .fig 文件、询问"设计规格"或"设计转代码交接"时使用。 - 从简入手:先用 Markdown 指令跑通骨架,再逐步引入脚本与复杂逻辑
- 自动化优先:避免在流程中嵌入复杂人机交互,以免干扰 Agent 交互控制
4. 定义 SKILL 评估标准
- 触发率:SKILL 加载触发频率
- 工具调用效率:在 n 次工具调用内完成工作流
- 稳定性:多次运行同一任务,结果一致性
SKILL 现状与问题
现状
Agent Skill 从2025年10月正式发布,到12月成为跨平台开放标准,不到5个月内完成了从"Claude专属功能"到"行业基础设施"的跨越,微软、OpenAI等主流平台相继跟进,当前生态扩散势头强劲。
截至2026年3月,单统计一个网站 Agent Skill 数量已突破42万(来源https://skillsmp.com/)。但数量爆炸的背后,安全治理严重滞后——仅 ClawHub 一个平台就发现7.1%的 Skill 存在 API 密钥泄露风险,治理体系的缺失已成为生态最大隐患。
当前存在的问题
- 安全审核:SKILL越复杂带来的安全风险越大,公开的SKILL存在着prompt注入风险
- 缺乏版本管理:更新 SKILL 需手动保留旧版快照,无内置版本控制
- 资源文件加载不稳定:渐进式披露设计下,资源加载依赖 Agent 自行判断,多轮交互增加风险
- 脚本执行需隔离:依赖基础设施提供沙箱环境隔离执行
可优化方向
1. 服务加载 SKILL
遵循标准 SKILL 规范,既支持本地 SKILL 目录加载以便调试,也支持远程调用获取 SKILL,并在服务启动时加载至内存。
2. Agent 加载 SKILL
SKILL 选择机制
参考 DeepAgents,采用中间件方式将技能集成至 Agent。
SKILL 脚本扩展Tool Calling
开源 SKILL 中的脚本通常为 Python 脚本,需沙箱执行,支持通过Restful API 或 MCP 协议调用三方服务。
要求:SKILL 中明确声明所依赖的外部工具,并提供 JSON Schema 格式声明文件,Agent 自动加载,转换为大模型Tool Calling格式供模型决策。
优势:将脚本执行转化为工具调用形式,提升决策与执行稳定性。
**SKILL 工具封装:**参考多数项目设计,对 SKILL 文件进行独立工具封装,以 Tool Calling 形式提供:
- 读取主文件
SKILL.md - 读取资源文件(符合规范中支持的类型)
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 4
4 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)