
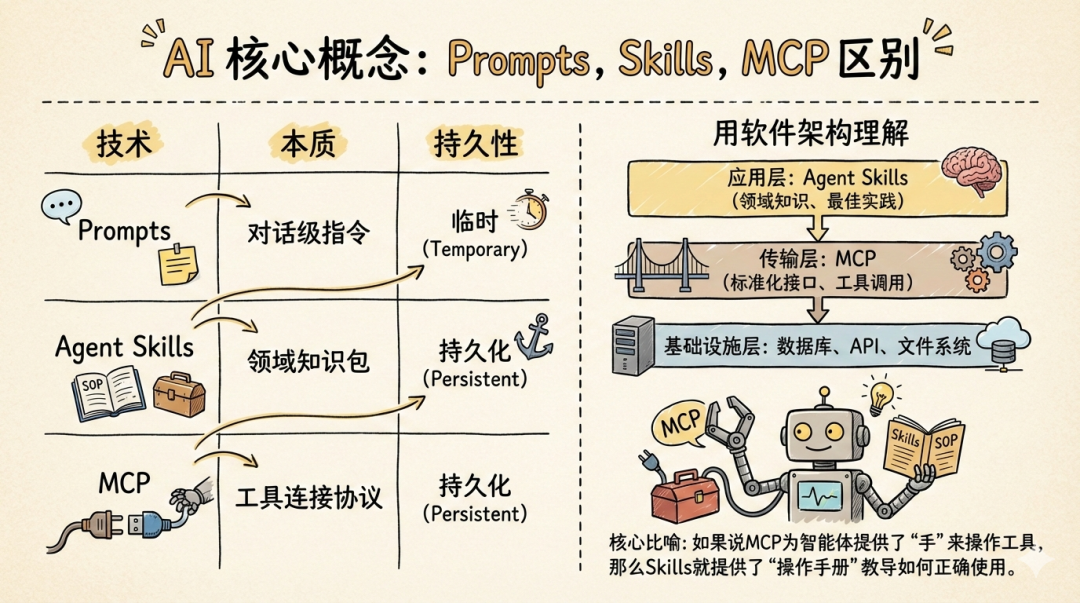
一文搞懂 Skills:会成为第二个 MCP 吗?
Skills 是什么? 一个标准化描述和复用 Agent 能力的协议,定义了如何描述能力、声明依赖、定义执行流程。
MCP 让 Agent 能"连接"世界,Skills 让 Agent 能"复用"能力。两者结合,构成 Agent 基础设施的核心。
Skills 是什么? 一个标准化描述和复用 Agent 能力的协议,定义了如何描述能力、声明依赖、定义执行流程。
和 MCP 什么关系? Skills 在 MCP 之上。MCP 解决工具连接,Skills 解决能力复用。一个 Skill 可以调用多个 MCP 工具和其他 Skills。
解决什么问题? 让 Agent 能力可以封装、分享、复用,避免重复造轮子,让最佳实践可以沉淀传播。
会成为标准吗? 很可能。解决真实痛点,有大厂推动,正在形成生态效应。
本文从技术角度深度拆解 Skills 协议的设计理念、核心规范与实现细节。
一、为什么需要Skills?
从一个真实场景说起:假设你是一家公司的运营负责人,每周一早上需要给老板发一份上周的销售分析报告。这个任务看起来简单,但实际上涉及很多步骤。
首先,你要从公司的数据库里把上周的销售数据导出来。然后,你需要按产品线、按区域、按渠道等多个维度做分析,算出各种同比环比增长率。接着,你要把这些数据做成直观的图表。之后,你要把分析结论和图表整理成一份 Word 或 PDF 报告。最后,你要写一封邮件,把报告发给老板,还要抄送给相关同事。
现在,你有了一个 AI Agent 助手。你对它说:“帮我生成上周的销售报告发给老板。”
Agent 能完成这个任务吗?
如果这个 Agent 接入了各种工具——数据库查询工具、Excel 处理工具、图表生成工具、文档编辑工具、邮件发送工具——理论上是可以的。但实际执行时,Agent 需要自己想清楚很多事情。
应该先查哪个数据库的哪张表?SQL 怎么写?查出来的数据格式是什么?要做哪些维度的分析?图表用柱状图还是折线图?报告的结构是什么样的?邮件标题怎么写?正文怎么组织?附件还是正文内嵌?
每次执行这个任务,Agent 都要重新思考这些问题。今天它可能先做图表再写分析,明天可能先写分析再做图表。今天生成的报告是三页,明天可能是五页。质量参差不齐,老板体验很差。
更麻烦的是,隔壁部门的同事看到你的 Agent 能生成销售报告,也想要一个。但你没办法简单地把这个能力"复制"给他,因为这个能力并没有被清晰地定义和封装,它只是散落在 Agent 的各种 prompt 和工具调用里。
这就是 Agent 现在面临的 MCP 解决不了的问题:工具有了,但"怎么组合这些工具来完成一个完整任务"的知识,没有办法标准化地描述和复用。
Skills 如何解决这些问题?
Skills 协议就是为了解决这些问题而生的。
它的核心思想是:把"完成某类任务的完整能力"封装成一个标准化的单元,这个单元可以被描述、被发现、被复用、被分享。
回到销售报告的例子。有了 Skills 之后,可以把"销售报告生成"封装成一个 Skill。这个 Skill 里面清晰地定义了:
- 这个 Skill 能做什么(生成销售分析报告)
- 需要什么输入(时间范围、分析维度、收件人等)
- 会产生什么输出(报告文件、分析摘要、发送状态)
- 依赖哪些工具(数据库 MCP、图表 MCP、文档 MCP、邮件 MCP)
- 具体执行步骤是什么(先查数据、再分析、再做图、再生成报告、最后发邮件)
- 出错了怎么处理(重试几次、失败了怎么降级)
当用户说"帮我生成上周的销售报告发给老板"时,Agent 只需要:识别出应该使用"销售报告生成"这个 Skill,从用户的话里提取出参数(时间范围=上周,收件人=老板),然后调用这个 Skill。剩下的事情,Skill 会按照预定义的流程自动完成。
每次执行都是一样的流程,质量稳定可控。这个 Skill 可以分享给其他人,他们不需要重新摸索。公司可以统一维护和迭代这个 Skill,所有人都能受益。
如果说 MCP 是工具连接的"USB 标准",那么 Skills 就是能力复用的"App Store"。
MCP 让你能够使用各种工具,Skills 让你能够获取别人封装好的能力。就像智能手机,有了统一的接口标准(USB-C)你能连接各种配件,有了应用商店你能下载别人开发的 App,两者结合才构成完整的生态。
二、Skills 协议是什么?
一个完整的 Skill 定义包含六个核心部分。可以把它想象成一份"能力说明书",告诉别人这个能力是什么、怎么用、需要什么条件。
第一部分:元信息——“这个 Skill 是谁”
元信息就像一个人的身份证,包含名字、版本号、作者、分类标签等基本信息。
名称和命名空间用来唯一标识一个 Skill,避免不同开发者起了相同的名字。比如 enterprise.analytics.sales_report 这样的完整标识。
版本号用来管理 Skill 的迭代更新,让使用者知道自己用的是哪个版本。
分类标签方便搜索和发现,比如标记为 sales、analytics、report 等。
第二部分:能力描述——“这个 Skill 能做什么”
这部分是告诉 Agent 和用户这个 Skill 的用途,是 Skill 被正确选择的关键。
给模型看的描述帮助 Agent 判断什么时候应该使用这个 Skill。需要说清楚适用场景和不适用场景,比如"当用户需要分析销售数据时使用;不适用于非销售相关的分析"。
给人看的描述让用户了解这个 Skill 的功能,包括简短介绍和详细说明。
示例对话提供一些触发和不触发的例子,帮助 Agent 更准确地识别意图。
第三部分:接口定义——“怎么使用这个 Skill”
接口定义规定了输入什么、输出什么,就像一个函数的参数和返回值。
输入参数定义了使用这个 Skill 需要提供哪些信息。每个参数要说明名称、类型、是否必填、默认值等。
以销售报告 Skill 为例,输入可能包括:时间范围(必填)、分析维度(可选,默认按产品和区域)、输出格式(可选,默认 PDF)、收件人邮箱(可选,填了就发邮件)。
输出结果定义了 Skill 执行完会返回什么。比如报告文件的下载链接、分析摘要、发送状态等。
第四部分:依赖声明——“运行这个 Skill 需要什么”
依赖声明说明这个 Skill 需要哪些外部资源才能运行,主要包括两类:
MCP 工具依赖:需要哪些 MCP Server。比如销售报告 Skill 需要数据库 MCP(查数据)、存储 MCP(保存报告)、邮件 MCP(发送报告,可选)。
其他 Skill 依赖:需要调用哪些子 Skill。比如需要"数据可视化"Skill 来生成图表。
声明依赖的好处是运行前可以检查条件是否满足,缺什么可以提前知道。
第五部分:执行定义——“具体怎么完成任务”
这是 Skill 的核心,描述了具体的执行步骤。
最常见的是工作流类型,把任务拆成一系列步骤,每个步骤可以是调用 MCP 工具、调用其他 Skill、让 LLM 处理、或者执行代码。步骤之间可以传递数据,比如第一步查出的数据传给第二步分析。
执行定义还包括条件判断(比如只有填了收件人才发邮件)和错误处理(比如重试几次、失败了怎么办)。
第六部分:权限与安全——“有什么限制和保障”
这部分定义了 Skill 需要什么权限、如何保证安全。
权限声明说明需要哪些权限才能运行,比如读取数据库、写入文件、发送邮件等。
安全策略说明如何处理用户数据,比如是否存储、是否发送到外部、是否记录日志等。
# ================================================================
# Skills Protocol Specification v1.0
# 完整的 Skill 定义示例:销售数据分析报告生成
# ================================================================
skill_protocol_version: "1.0"
# ============================================================
# Part 1: 元信息 (Metadata)
# 描述 Skill 的基本信息,用于注册、发现、版本管理
# ============================================================
metadata:
# 唯一标识
name: "sales_report_generator"
namespace: "enterprise.analytics" # 命名空间,避免冲突
version: "2.1.0"
# 作者与许可
author:
name: "DataTeam"
email: "data@example.com"
organization: "Example Corp"
license: "MIT"
# 分类标签(用于发现和搜索)
tags:
- "sales"
- "analytics"
- "report"
- "business-intelligence"
category: "data-analysis"
# 兼容性声明
compatibility:
skills_protocol: ">=1.0.0"
mcp_version: ">=2.0.0"
# 发布信息
repository: "https://github.com/example/sales-skill"
documentation: "https://docs.example.com/skills/sales-report"
changelog: "https://github.com/example/sales-skill/CHANGELOG.md"
# ============================================================
# Part 2: 能力描述 (Description)
# 告诉 Agent 和用户这个 Skill 能做什么
# ============================================================
description:
# 给 LLM 看的描述(用于 Skill 选择和调用)
for_model: |
销售数据分析与报告生成技能。
适用场景:
- 用户需要分析销售数据时
- 用户需要生成销售报告时
- 用户询问销售趋势、业绩对比时
- 用户要求将分析结果发送给他人时
不适用场景:
- 非销售相关的数据分析
- 实时交易处理
# 给人看的描述
for_human:
short: "销售数据分析与报告生成"
long: |
自动连接企业销售数据源,进行多维度分析(产品、区域、时间、渠道),
生成包含可视化图表的专业报告,支持多种格式导出和邮件发送。
# 能力标签(语义化,用于能力匹配)
capabilities:
- "data_extraction" # 数据提取
- "data_analysis" # 数据分析
- "visualization" # 可视化
- "report_generation" # 报告生成
- "email_delivery" # 邮件发送
# 示例对话(帮助 LLM 理解何时使用)
examples:
- user: "帮我看看上个季度的销售情况"
should_trigger: true
- user: "生成一份销售报告发给老板"
should_trigger: true
- user: "分析一下用户行为数据"
should_trigger: false # 不是销售数据
# ============================================================
# Part 3: 接口定义 (Interface)
# 定义输入输出的数据结构
# ============================================================
interface:
inputs:
- name: "time_range"
type: "object"
required: true
description: "分析的时间范围"
schema:
properties:
start_date:
type: "string"
format: "date"
description: "开始日期 (YYYY-MM-DD)"
end_date:
type: "string"
format: "date"
description: "结束日期 (YYYY-MM-DD)"
required: ["start_date", "end_date"]
examples:
- start_date: "2026-01-01"
end_date: "2026-03-31"
- name: "dimensions"
type: "array"
required: false
description: "分析维度"
items:
type: "string"
enum: ["product", "region", "channel", "salesperson", "customer_type"]
default: ["product", "region"]
- name: "metrics"
type: "array"
required: false
description: "分析指标"
items:
type: "string"
enum: ["revenue", "quantity", "profit", "growth_rate", "market_share"]
default: ["revenue", "quantity"]
- name: "output_format"
type: "string"
required: false
description: "报告输出格式"
enum: ["pdf", "excel", "html", "markdown", "pptx"]
default: "pdf"
- name: "recipients"
type: "array"
required: false
description: "报告接收人邮箱列表(为空则不发送)"
items:
type: "string"
format: "email"
default: []
- name: "language"
type: "string"
required: false
description: "报告语言"
enum: ["zh-CN", "en-US", "ja-JP"]
default: "zh-CN"
outputs:
- name: "report"
type: "object"
description: "生成的报告"
schema:
properties:
file_url:
type: "string"
description: "报告文件下载链接"
file_name:
type: "string"
description: "报告文件名"
format:
type: "string"
description: "文件格式"
size_bytes:
type: "integer"
description: "文件大小"
- name: "summary"
type: "object"
description: "分析摘要"
schema:
properties:
total_revenue:
type: "number"
total_quantity:
type: "integer"
growth_rate:
type: "number"
key_insights:
type: "array"
items:
type: "string"
top_products:
type: "array"
top_regions:
type: "array"
- name: "delivery_status"
type: "object"
description: "邮件发送状态"
schema:
properties:
sent:
type: "boolean"
recipients_count:
type: "integer"
sent_at:
type: "string"
format: "datetime"
# ============================================================
# Part 4: 依赖声明 (Dependencies)
# 声明需要的 MCP 服务和其他 Skills
# ============================================================
dependencies:
# MCP 服务依赖
mcp_servers:
- name: "postgresql-mcp"
version: ">=1.5.0"
purpose: "连接销售数据库,执行数据查询"
required: true
config_schema:
properties:
connection_string:
type: "string"
description: "数据库连接字符串"
- name: "google-sheets-mcp"
version: ">=1.0.0"
purpose: "备选数据源,当主数据库不可用时使用"
required: false
- name: "smtp-mcp"
version: ">=1.2.0"
purpose: "发送报告邮件"
required: false # 仅当 recipients 非空时需要
- name: "s3-mcp"
version: ">=1.0.0"
purpose: "存储生成的报告文件"
required: true
# 其他 Skill 依赖
skills:
- name: "data_visualizer"
namespace: "common.visualization"
version: ">=2.0.0"
purpose: "生成图表"
- name: "document_formatter"
namespace: "common.document"
version: ">=1.5.0"
purpose: "格式化和排版报告"
# ============================================================
# Part 5: 执行定义 (Execution)
# 定义 Skill 如何执行
# ============================================================
execution:
# 执行类型: workflow | code | prompt | hybrid
type: "workflow"
# 运行时配置
runtime:
timeout: 300 # 最大执行时间(秒)
max_retries: 3 # 最大重试次数
memory_limit: "512MB" # 内存限制
# 工作流定义
workflow:
# 全局变量/上下文
context:
data_source: "postgresql" # 默认数据源
# 执行步骤
steps:
# Step 1: 参数预处理
- id: "preprocess"
name: "参数预处理"
action: "code"
code: |
# 处理日期格式,设置默认值等
if not inputs.get('time_range'):
# 默认最近一个季度
inputs['time_range'] = get_last_quarter()
context['processed_inputs'] = inputs
output: "processed_inputs"
# Step 2: 获取数据
- id: "fetch_data"
name: "获取销售数据"
action: "mcp_call"
server: "postgresql-mcp"
method: "query"
params:
query: |
SELECT
date, product_id, product_name, region, channel,
salesperson, quantity, revenue, cost
FROM sales
WHERE date BETWEEN '{{time_range.start_date}}'
AND '{{time_range.end_date}}'
ORDER BY date
output: "raw_data"
# 错误处理:如果主数据库失败,尝试备选
on_error:
- condition: "error.type == 'ConnectionError'"
action: "fallback"
fallback_step: "fetch_data_backup"
# Step 2b: 备选数据获取
- id: "fetch_data_backup"
name: "从备选源获取数据"
action: "mcp_call"
server: "google-sheets-mcp"
method: "read_range"
params:
spreadsheet_id: "{{config.backup_sheet_id}}"
range: "Sales!A:I"
output: "raw_data"
skip_if: "raw_data != null" # 如果主数据源成功则跳过
# Step 3: 数据分析(LLM 处理)
- id: "analyze"
name: "数据分析"
action: "llm_process"
model: "claude-3-opus" # 可选,默认使用当前模型
prompt_template: |
你是一位专业的数据分析师。请分析以下销售数据:
## 数据概览
{{raw_data | summarize}}
## 分析要求
- 分析维度:{{dimensions | join(', ')}}
- 分析指标:{{metrics | join(', ')}}
- 时间范围:{{time_range.start_date}} 至 {{time_range.end_date}}
## 输出要求
请提供:
1. 整体趋势分析
2. 各维度对比分析
3. 关键洞察(至少3条)
4. 建议措施
以 JSON 格式输出分析结果。
output_format: "json"
output: "analysis_result"
# Step 4: 生成图表(调用子 Skill)
- id: "create_charts"
name: "生成可视化图表"
action: "skill_call"
skill: "data_visualizer"
params:
data: "{{raw_data}}"
chart_configs:
- type: "line"
title: "销售趋势"
x: "date"
y: "revenue"
- type: "bar"
title: "产品销售对比"
x: "product_name"
y: "revenue"
- type: "pie"
title: "区域销售占比"
dimension: "region"
metric: "revenue"
- type: "heatmap"
title: "产品-区域销售热力图"
x: "product_name"
y: "region"
value: "revenue"
output: "charts"
# Step 5: 生成报告(调用子 Skill)
- id: "generate_report"
name: "生成报告文档"
action: "skill_call"
skill: "document_formatter"
params:
template: "sales_report"
format: "{{output_format}}"
language: "{{language}}"
content:
title: "销售分析报告"
period: "{{time_range.start_date}} - {{time_range.end_date}}"
summary: "{{analysis_result.summary}}"
insights: "{{analysis_result.insights}}"
recommendations: "{{analysis_result.recommendations}}"
charts: "{{charts}}"
raw_data_sample: "{{raw_data | head(10)}}"
output: "report_content"
# Step 6: 上传报告
- id: "upload_report"
name: "上传报告文件"
action: "mcp_call"
server: "s3-mcp"
method: "upload"
params:
bucket: "reports"
key: "sales/{{time_range.start_date}}_{{time_range.end_date}}.{{output_format}}"
content: "{{report_content.file_data}}"
content_type: "{{report_content.mime_type}}"
output: "upload_result"
# Step 7: 发送邮件(条件执行)
- id: "send_email"
name: "发送报告邮件"
condition: "recipients != null && len(recipients) > 0"
action: "mcp_call"
server: "smtp-mcp"
method: "send"
params:
to: "{{recipients}}"
subject: "销售分析报告 ({{time_range.start_date}} - {{time_range.end_date}})"
body: |
您好,
附件是最新的销售分析报告,主要发现如下:
{{analysis_result.insights | join('\n')}}
详细内容请查看附件。
此邮件由系统自动发送。
attachments:
- url: "{{upload_result.url}}"
filename: "销售报告.{{output_format}}"
output: "email_result"
# Step 8: 组装最终输出
- id: "finalize"
name: "组装输出结果"
action: "code"
code: |
return {
"report": {
"file_url": upload_result.url,
"file_name": upload_result.key,
"format": output_format,
"size_bytes": upload_result.size
},
"summary": {
"total_revenue": analysis_result.metrics.total_revenue,
"total_quantity": analysis_result.metrics.total_quantity,
"growth_rate": analysis_result.metrics.growth_rate,
"key_insights": analysis_result.insights,
"top_products": analysis_result.rankings.products[:5],
"top_regions": analysis_result.rankings.regions[:5]
},
"delivery_status": {
"sent": email_result is not None,
"recipients_count": len(recipients) if recipients else 0,
"sent_at": email_result.sent_at if email_result else None
}
}
output: "final_result"
# 全局错误处理
error_handling:
# 重试策略
retry:
max_attempts: 3
backoff: "exponential" # exponential | linear | fixed
initial_delay: 1000 # 毫秒
max_delay: 30000
# 错误回调
on_error:
- error_type: "DataNotFoundError"
action: "return_error"
message: "未找到指定时间范围的销售数据"
- error_type: "PermissionDeniedError"
action: "return_error"
message: "没有访问销售数据的权限"
- error_type: "*" # 其他所有错误
action: "return_error"
message: "报告生成失败:{{error.message}}"
# ============================================================
# Part 6: 权限与安全 (Permissions & Security)
# ============================================================
permissions:
# 必需权限
required:
- "database:sales:read" # 读取销售数据库
- "storage:reports:write" # 写入报告存储
# 可选权限
optional:
三、Skills 会成为第二个 MCP 吗?
Skills 生态现状怎么样?
Anthropic 是 Skills 协议的主要推动者,Claude 原生支持,并在建设官方 Skills Hub。
OpenAI 已宣布支持,原来的 GPTs 正在向 Skills 标准迁移。
Google、Microsoft 等大厂也在跟进集成。
字节 Coze 有国内最完善的类 Skills 生态,正在逐步兼容国际标准。
阿里、百度等也在跟进。
开源社区有社区维护的 Skills Registry,收集开源 Skills。
截至现在,官方认证和社区贡献 Skills 数百个,主要集中在数据分析、内容创作、开发工具、办公自动化、垂直行业等领域。
相比 MCP 超过 2000 个 Server 的成熟生态,Skills 还比较年轻,但增长很快。
那Skills 会成为第二个 MCP 吗?
它们有相似的发展路径
- MCP 的成功路径是:Anthropic 提出 → Claude 率先支持 → OpenAI 跟进 → 成为事实标准。
- Skills 正在走同样的路:Anthropic 提出 → Claude 支持 → OpenAI 跟进 → 其他厂商跟进中。
Skills 解决的是能力复用这个真实痛点。随着 Agent 应用增多,重复造轮子的问题越来越突出,标准化的能力复用方案是刚需。
一旦Skills生态建立,会形成正向循环:更多 Skills → 开发 Agent 更容易 → 更多人开发 Agent → 更多人贡献 Skills。
大概率,Skills 很可能会成为继 MCP 之后的第二个重要标准。
MCP 解决了"连接"问题,Skills 解决了"复用"问题,两者互补,共同构成 Agent 基础设施。
如果说 MCP 是 Agent 时代的"TCP/IP",Skills 就是"HTTP"——在底层协议之上,更贴近应用层的标准。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2026 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2026 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 10
10 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)