
LLM智能体自我进化教程(非常详细),SKILLRL框架从入门到精通,收藏这一篇就够了!
大语言模型(LLM)智能体在复杂任务中展现出惊人的能力,但它们往往孤立运行,无法从过往经验中学习。传统的基于记忆的方法主要存储原始轨迹,这些轨迹冗余且充满噪声,阻碍了智能体提取高层可复用的行为模式。本文介绍的SKILLRL框架通过自动技能发现和递归进化,填补了原始经验与策略改进之间的鸿沟。该框架在ALFWorld、WebShop和七个搜索增强任务上取得了最先进性能,比强基线方法提升超过15.3%,
大语言模型(LLM)智能体在复杂任务中展现出惊人的能力,但它们往往孤立运行,无法从过往经验中学习。传统的基于记忆的方法主要存储原始轨迹,这些轨迹冗余且充满噪声,阻碍了智能体提取高层可复用的行为模式。本文介绍的SKILLRL框架通过自动技能发现和递归进化,填补了原始经验与策略改进之间的鸿沟。该框架在ALFWorld、WebShop和七个搜索增强任务上取得了最先进性能,比强基线方法提升超过15.3%,并且在任务复杂度增加时保持鲁棒性。
研究背景
大语言模型智能体通过与复杂环境的自然语言交互,在网络导航、深度研究等任务中展现出卓越能力。然而,每次任务执行本质上都是独立的,当前LLM智能体孤立运行,无法从过去的成功或失败中学习。这种局限性严重阻碍了智能体的进化。现有基于记忆的方法主要在采样过程中将原始轨迹直接保存到外部数据库,作为未来相似任务的参考。虽然直观,但这些原始轨迹通常冗长且包含大量冗余和噪声,使模型难以提取关键信息。
研究问题
- 经验利用效率低:现有方法存储原始轨迹,这些轨迹冗余且充满噪声,难以从中提取关键信息进行有效知识转移
- 缺乏高层次抽象:现有方法仅仅模仿过去的解决方案,未能提炼核心原则或调整智能体的内部策略以利用记忆进行引导决策
- 静态记忆限制:静态记忆库无法预判智能体将遇到的所有场景,当策略改进并探索新状态区域时,面临现有技能提供指导不足的情况
主要贡献
- 基于经验的技能蒸馏机制:首次引入从环境交互中收集多样化轨迹的差异化处理机制,成功轨迹保留为示范,失败轨迹合成为简洁的失败教训,有效缓解上下文噪声
- 分层技能库(SKILL BANK):构建分层技能库,区分通用技能和任务特定技能,实现高效检索,显著减少token占用同时增强推理效用
- 递归技能进化机制:引入递归技能进化机制,使技能库和智能体策略在强化学习过程中协同进化,确保在任务复杂度增加时保持鲁棒性
- 卓越的实验性能:在ALFWorld、WebShop和七个搜索增强基准测试中取得最先进性能,平均提升15.3%
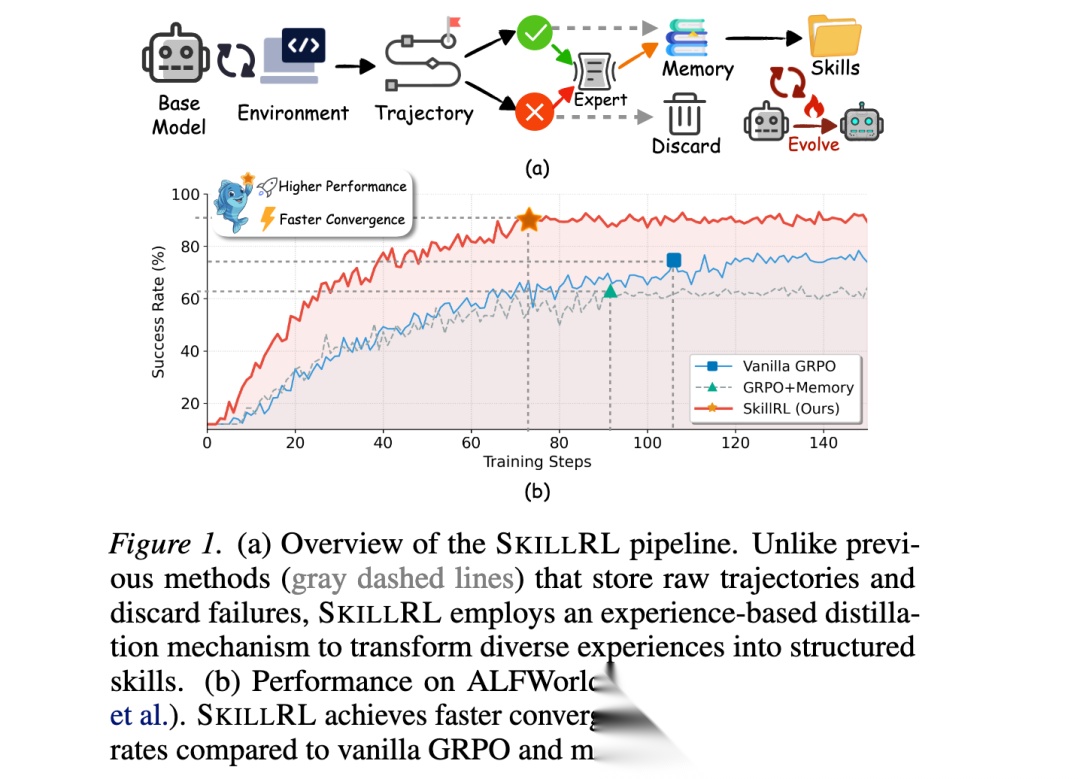
方法论精要
SKILLRL框架由三个核心组件构成:基于经验的技能蒸馏机制、分层技能库构建和递归技能进化机制。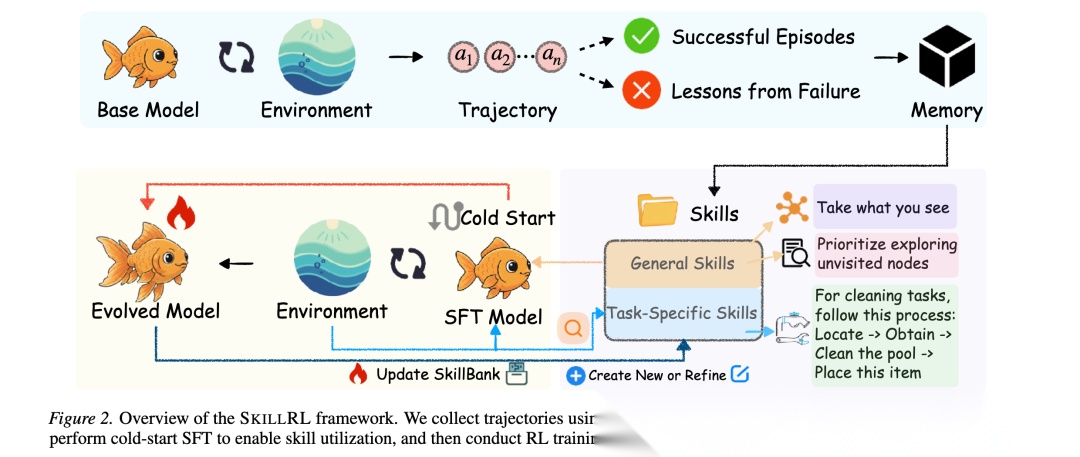
基于经验的技能蒸馏:原始轨迹τ从环境交互中收集,包含探索性动作、回溯和冗余步骤。SKILLRL使用教师模型将轨迹蒸馏为紧凑、可复用的技能。与仅保留成功轨迹的先前方法不同,SKILLRL刻意保留成功轨迹和失败轨迹。对于成功轨迹,提取导致任务完成的战略模式:。对于失败轨迹,合成简洁的失败教训:,分析识别失败点、有缺陷的推理、应该做什么以及防止类似失败的一般原则。
分层技能库构建:SKILL BANK分为两个层次:(1)通用技能捕获适用于环境内所有任务类型的通用战略原则,如探索策略、状态管理原则和目标跟踪启发式方法。(2)任务特定技能编码任务类别的专门知识,捕获领域特定的动作序列、前提条件和约束、常见失败模式以及优化程序。在推理时,通用技能始终作为基础指导,任务特定技能通过语义相似性检索:。技能蒸馏相比原始轨迹实现10-20× token压缩。
递归技能进化:在RL训练之前执行冷启动SFT,教师模型生成技能增强推理轨迹,演示如何检索、解释和应用技能。然后进行递归技能进化:在每个验证epoch后,监控每个任务类别的成功率,仅对的类别触发进化。收集失败轨迹,分析以识别差距:,然后更新技能库。使用GRPO优化技能增强策略,锚定到参考策略的KL惩罚确保RL优化保留学习的技能利用能力。
实验洞察
SKILLRL在九个具有挑战性的LLM智能体基准测试中进行了评估:ALFWorld、WebShop和七个搜索增强QA任务。实验使用Qwen2.5-7B-Instruct作为基础模型,OpenAI o3作为技能蒸馏和SFT数据生成的教师模型。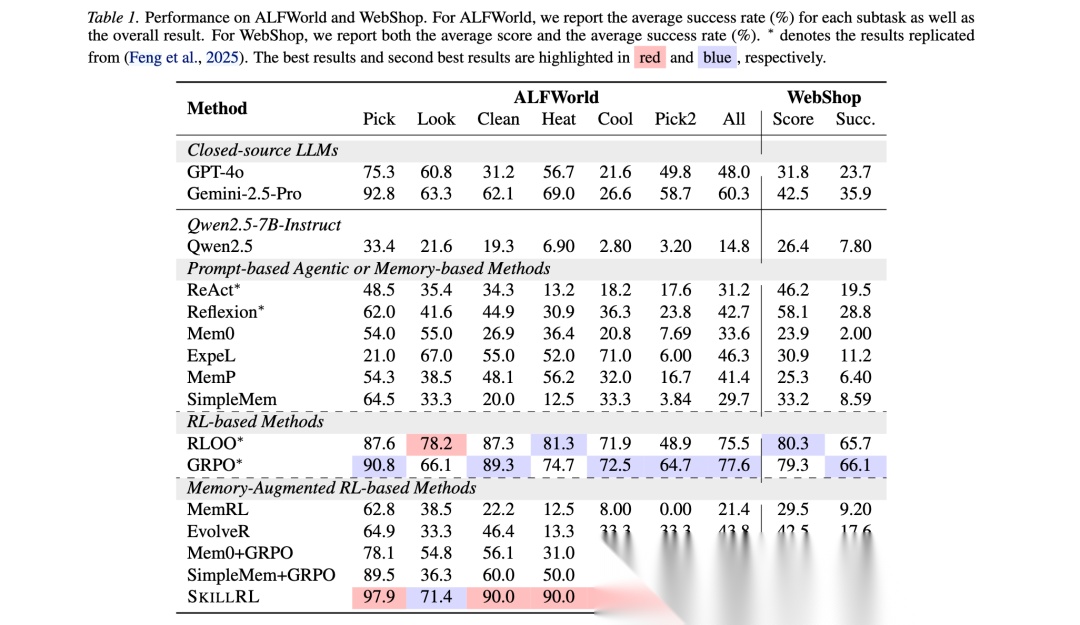
主要结果
在与基线方法的比较中,SKILLRL在两个基准测试上持续超越所有基线。在ALFWorld上,SKILLRL实现89.9%的成功率,在WebShop上达到72.7%,显著超越最佳基于提示的基线。相比标准RL基线(PPO、RLOO、GRPO),SKILLRL实现最佳整体性能。在ALFWorld上12.3%的绝对提升(从77.6%到89.9%)直接归因于技能增强机制而非算法差异。在Cool和Pick2等复杂子任务中,SKILLRL分别超越GRPO 23.0%和22.8%。
SKILLRL大幅超越现有记忆增强RL框架。MemRL在ALFWorld上仅获得21.4%,EvolveR显示改进(43.8%)但受限于对粗糙轨迹存储的依赖。Mem0+GRPO在ALFWorld和WebShop上分别提高到54.7%和37.5%,但仍以约35.2%的绝对成功率差距落后于SKILLRL。
消融研究
消融实验评估每个组件的贡献:(1)移除分层结构使ALFWorld性能下降13.1%,WebShop下降11.3%,表明通用战略原则提供必要的基础指导。(2)用原始轨迹替换技能库导致最大性能下降(高达25%),直接支持抽象优于记忆的动机。(3)冷启动SFT至关重要(移除后下降20%),确认基础模型需要初始显式演示阶段。(4)动态进化贡献5.5%改进,确保技能库是动态组件而非静态数据库。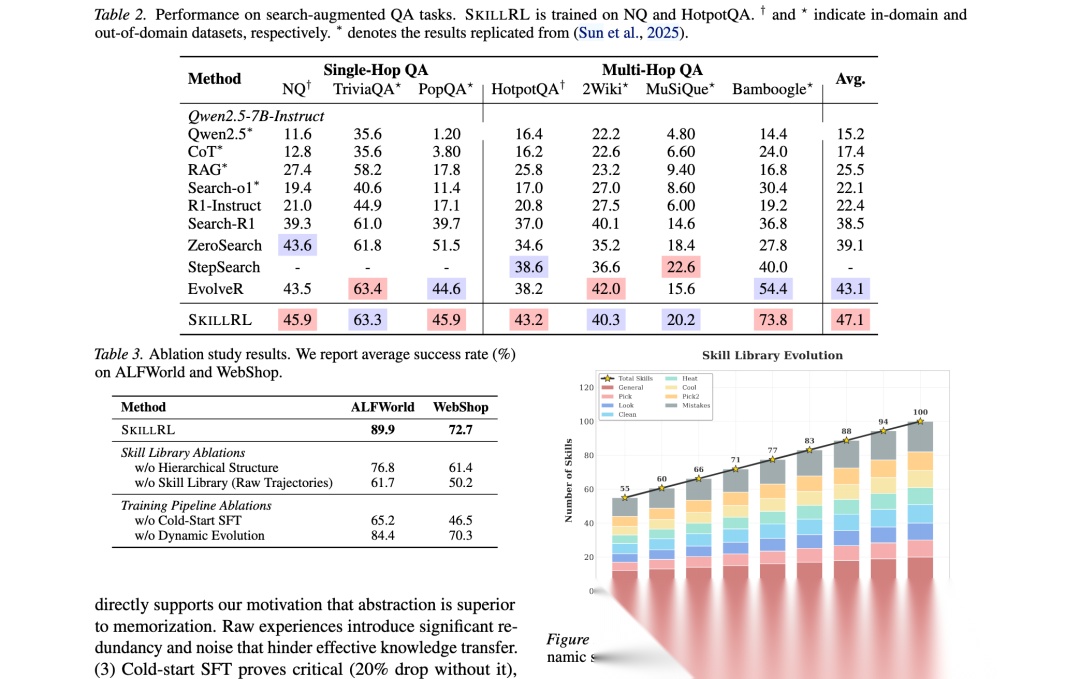
技能库进化与上下文效率
如图3所示,技能库在训练过程中进化。初始技能库包含55个技能(12个通用,43个任务特定),通过动态进化到训练结束时增长到100个技能。图4显示,SKILLRL保持显著更精简的提示(平均<1,300 tokens),相比原始记忆方法(平均约1,450 tokens)实现约10.3%的上下文长度减少。
训练动态
图5说明有无递归技能进化机制的强化学习训练曲线。具有技能进化的SKILLRL展现明显更高的学习率和卓越的渐近性能。SKILLRL在60个训练步骤内实现超过80%的成功率,而基线需要约90个训练步骤才能达到较低峰值。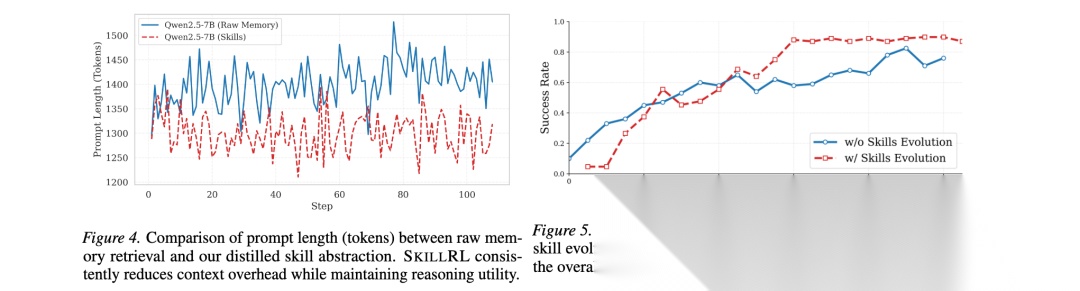
总结:SKILLRL通过技能蒸馏和递归进化,为LLM智能体提供了从经验中高效学习的全新范式,在保持上下文效率的同时实现了卓越的性能提升。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 17
17 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)