
[NeurIPS 2023]Towards Semi-Structured Automatic ICD Coding via Tree-based Contrastive Learning
计算机-人工智能-半结构化分段,树分支先验信息结合和掩码的ICD多标签分类

论文代码:https://github.com/LuChang-CS/semi-structured-icd-coding
目录
2.5.1. Automatic section-based segmentation
2.5.2. Supervised tree-based contrastive learning on sections
2.6.1. Dataset, tasks, and evaluation metrics
1. 心得
(1)还行就是这个局限真的一眼大局限
2. 论文逐段精读
2.1. Abstract
①对于诊断文本ICD疾病分类的挑战:样本有限、医生书写习惯不同、病理多样性
2.2. Introduction
①将电子健康记录(electronic health records,EHR)和International Classification of Diseases (ICD)结合的现实意义是便于医疗记录管理、医疗账单记录、医保报销,未来结合AI的意义是可以用于诊断或诊疗建议
②算法诊断现存挑战:长尾问题、结构化/非结构化记录差异、医生手写习惯差异
③结构化文本和非结构化文本示例:
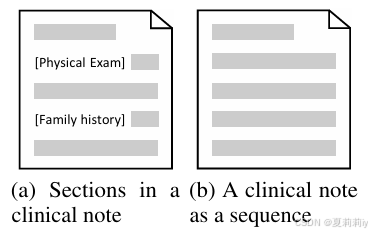
reimbursement n.报销;补偿;赔偿;偿付
2.3. Related work
①记录一些RNN/CNN、Attention/GNN、半监督方法
2.4. Preliminaries
(1)任务描述
①ICD编码:,其中
是编码个数,
是对于第
个ICD编码的含有
个token的描述
②临床记录:含有
个token
③任务:使用模型去预测临床文本的ICD分类
(2)常见的ICD编码框架
①编码诊断文本:
②编码单个ICD描述:;整体ICD嵌入:
③特征融合(感觉不能这么叫,这里实际上有种信息交互的感觉):
④分类:
2.5. Method
2.5.1. Automatic section-based segmentation
①定义一个具有n-gram document frequency-inverse average phrase frequency(DF-IAPF)分数的包含个单词的短语
②定义为包含词
的文档的相对频率,而
则是词
在所有包含词
的文档中的逆平均短语频率:
其中是文档综述,
代表含有
的文档数,
是词
在文档
中的出现次数


③DF-IAPF计算:

④选出来的前20个短语:
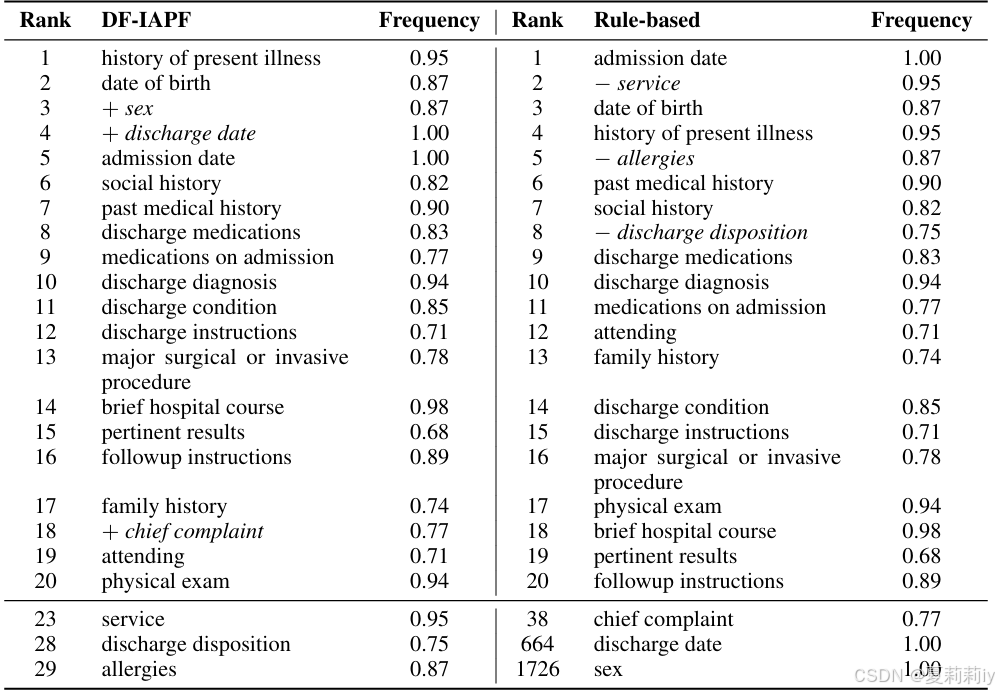
⑤选出的标题短语组成一个标题子集:包含
个标题
⑥按照标题出现的地方对文本进行切割,得到多个片段:
(这个创新点真的合理吗??话说遇到同义词怎么办?十个医生十个标题都不一样)
2.5.2. Supervised tree-based contrastive learning on sections
①从一个临床文本里面随机选个然后再随机选个不同标题的
作为正对;同不同临床文本选同一个标题的
和
也作为正对。因此
中有四个正对
②ICD树形结构中单个样本超级树的构建:
这里表示一个标签节点
的所有祖先
③在超级树中两个样本的相似度定义为:
其中是树可编辑距离
④超级树样例:
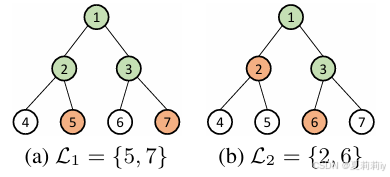
可编辑树距离为2,相似度为0.2
⑤对文本表示使用最大池化:
⑥对比损失:
其中代表MAE损失,
表示向量间余弦相似度,概念表示为:
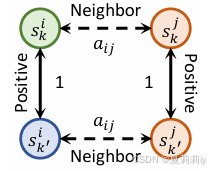
这个损失的意思是让上图Positive的节点相似度接近1,而Neighbor的相似度接近就行
2.5.3. Maskedsection training
①随机打乱的顺序,然后按照
的阈值来随机掩码,最后合并剩下的有效部分
②段掩码操作:
其中是串联操作,
是均匀分布,
指随机排列(好狡猾的写法哈哈哈哈哈哈哈哈哈)
③推理阶段不适用打乱和掩码
2.6. Experiments
2.6.1. Dataset, tasks, and evaluation metrics
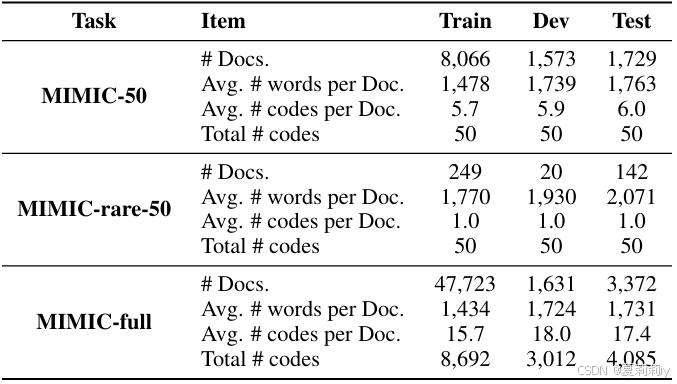
①数据集:MIMIC-50,MIMIC-rare-50,MIMIC-full
②数据划分:
2.6.2. Backbone models
①模型主干:MultiResCNN、HyperCore、JointLAAT、EffectiveCAN、PLM-ICD、Hierarchical、MSMN(KEPT没有被包含是因为计算量不支持)
2.6.3. Implementation details
①最大n-gram:
②标题个数:
③对比学习预训练的batch size:
④学习率:5e-4
⑤优化器:AdamW
⑥Epoch:20
⑦掩码概率:对于MIMIC-full来说,对于MIMIC-50/MIMIC-rare-50来说
⑧设备:Intel i9-11900K CPU, 64GB memory, NVIDIA RTX 3090 GPU
2.6.4. Experimental results
①MIMIC-50上的对比实验:

②MIMIC-rare-50上的对比实验:
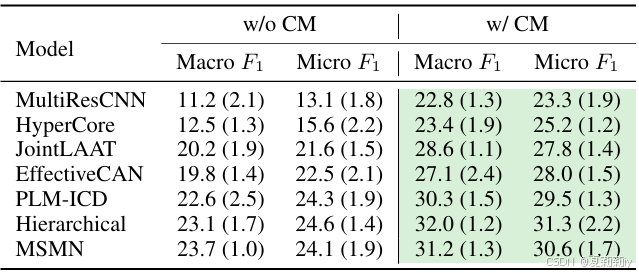
2.6.5. Ablation studies
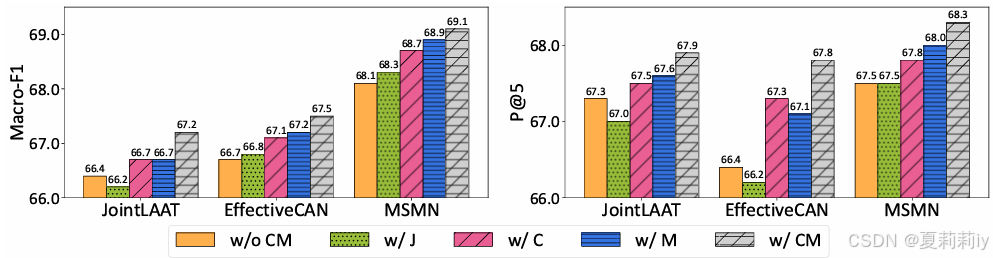
①MIMIC-50上的对比学习预训练(C)和掩码(M)消融:
2.6.7. Case studies
①示例:

snippet n.一小段(谈话、音乐等);一则(新闻);一小条(消息)
2.7. Conclusion
~局限是没有考虑错别字和同义词(...(说实话我觉得这个局限挺大的...
更多推荐
 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)