
快速上手大模型:深度学习12(目标检测、语义分割、序列模型)
本文介绍了计算机视觉中的目标检测、语义分割和序列模型三大任务。目标检测部分详细讲解了边界框表示方法及代码实现,并概述了R-CNN系列、SSD、YOLO等经典算法的发展历程和特点。语义分割部分简要说明其像素级分类的特性。序列模型部分则介绍了时间序列数据的建模方法,包括马尔科夫假设和潜变量模型等自回归模型计算方法。文章还指出当前主流算法已转向YOLOv8/v9、DINOv2、SAM等更先进的模型。
目录
1 目标检测
1.1 边界框(Bounding box)
用来描述对象的空间位置。 边界框是矩形的,由矩形左上角的以及右下角的𝑥和𝑦坐标决定。 另一种常用的边界框表示方法是边界框中心的(𝑥,𝑦)轴坐标以及框的宽度和高度。
1.2 代码
(1)库
%matplotlib inline import torch from d2l import torch as d2l d2l.set_figsize() img = d2l.plt.imread('../img/catdog.jpg') d2l.plt.imshow(img);(2)边界框
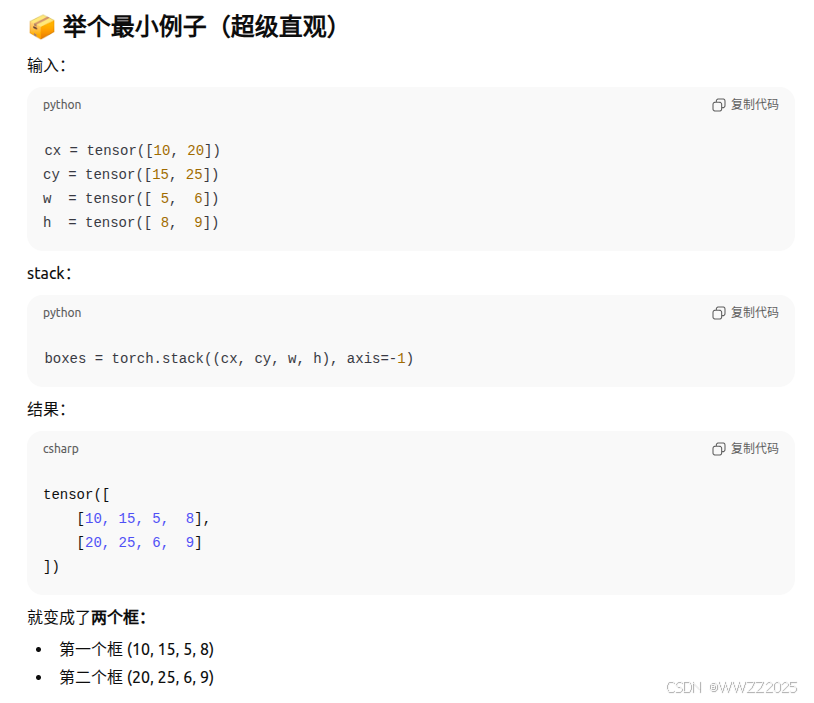
#@save def box_corner_to_center(boxes): """从(左上,右下)转换到(中间,宽度,高度)""" x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3] cx = (x1 + x2) / 2 cy = (y1 + y2) / 2 w = x2 - x1 h = y2 - y1 boxes = torch.stack((cx, cy, w, h), axis=-1) return boxes #@save def box_center_to_corner(boxes): """从(中间,宽度,高度)转换到(左上,右下)""" cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3] x1 = cx - 0.5 * w y1 = cy - 0.5 * h x2 = cx + 0.5 * w y2 = cy + 0.5 * h boxes = torch.stack((x1, y1, x2, y2), axis=-1) return boxes # bbox是边界框的英文缩写 dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]torch.stack((cx, cy, w, h), axis=-1):
#@save def bbox_to_rect(bbox, color): # 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式: # ((左上x,左上y),宽,高) return d2l.plt.Rectangle( xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1], fill=False, edgecolor=color, linewidth=2) fig = d2l.plt.imshow(img) fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue')) fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));

1.3 常用算法
1.3.1 R-CNN
2014,它先找出可能有物体的区域(候选框),再用CNN对每个区域做分类和位置回归。
工作流程:
(1)Selective Search找候选区域(region proposals)
输入一张图片
使用传统算法(不是CNN)生成大约 2000 个候选框(Region proposals)
这些框可能包含物体
(2)对每个候选框做裁剪 + resize + CNN 特征提取
对每个 Region 裁剪出来后
resize 到固定大小(如 224×224)
输入到 CNN(如 AlexNet)
输出特征向量(4096 维)
(3)使用 SVM 分类 + 回归框调整
CNN 提取的特征用于:
SVM分类器 → 判断框里是 猫 / 狗 / 人 / 背景
回归器(regressor) → 调整框的位置(更准确)
1.3.2 Fast R-CNN
2015,整张图只做一次CNN → 得到特征图 → 在特征图上裁剪候选框 → 分类 + 回归。
相比R-CNN,它把速度从几十秒/张 → 0.2秒/张。
1.3.3 Faster R-CNN
2015,Faster R-CNN = Fast R-CNN + 用CNN来生成候选框Region Proposal Network(RPN)
1.3.4 Mask R-CNN
2017,Mask R-CNN = Faster R-CNN + 实例分割(Instance Segmentation)
1.3.5 单发多框检测SSD
一次前向就同时预测各位置的类别和边界框(多个预设框/anchor),速度快且精度不错,适合实时检测。
多尺度目标检测
多尺度:模型能够检测图像中不同大小的目标。
%matplotlib inline import torch from d2l import torch as d2l img = d2l.plt.imread('../img/catdog.jpg') h, w = img.shape[:2] h, w def display_anchors(fmap_w, fmap_h, s): d2l.set_figsize() # 前两个维度上的值不影响输出 fmap = torch.zeros((1, 10, fmap_h, fmap_w)) anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5]) bbox_scale = torch.tensor((w, h, w, h)) d2l.show_bboxes(d2l.plt.imshow(img).axes, anchors[0] * bbox_scale) display_anchors(fmap_w=4, fmap_h=4, s=[0.15]) display_anchors(fmap_w=2, fmap_h=2, s=[0.4]) display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
1.3.6 YOLO
把检测看成回归问题,网络一次前向就同时预测每个网格的类别和框(速度非常快,适合实时)。
1.3.7 小结
上述算法目前已经淘汰,了解即可,目前SLAM+大模型+具身智能主流算法:
(1)实时机器人检测(SLAM 前端)
YOLOv8 / YOLOv9(速度最快)
RT-DETR(高精度 + transformer)
(2)建图 / 语义 SLAM(多任务 dense 特征)
DINOv2(最强 dense feature)
SAM / SAM2(大模型分割)
Mask2Former(语义分割)
(3)具身智能(Embodied AI + 大模型)
视觉backbone:
SigLIP
DINOv2
ViT-L / ViT-H
SAM2(mask-aware reasoning)
前端检测可选:
YOLO-World(支持开放词汇检测)
DINO-DETR
2 语义分割Semantic Segmentation
语义分割将图片中的每个像素分类到对应的类别。
目前主流使用Mask2Former。
3 序列模型
目标参数随时间变化而变化。典型例子量化模型,股价预测。
建模:在时间t观察到
,那么得道T个不独立的随机变量
,条件概率展开
。
对条件概率建模
,其中f是对见过的数据建模,亦称自回归模型。
自回归模型计算方法有:
(1)马尔科夫假设
(2)潜变量模型
更多推荐



 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)