
收藏!小白到专家:LangChain+FastAPI构建RAG系统,掌握大模型异步API部署全流程
本文详细介绍如何使用LangChain和FastAPI构建和部署RAG系统,涵盖技术原理、核心组件(文档加载器、文本分割、索引、检索和生成模型)、开发环境配置、异步API实现及Docker容器化部署策略。通过完整示例,展示从原型到可扩展应用的开发流程,帮助开发者构建基于真实信息的智能问答系统,提升大模型应用的准确性和相关性。
了解如何使用 LangChain 构建和部署基于 FastAPI 的 RAG 系统。学习异步处理、高效的 API 调用和文档检索技术。
检索增强生成(RAG)是目前人工智能领域最令人兴奋的技术之一。它结合了从海量数据集中精确检索真实信息的能力和大型语言模型的推理能力。其结果如何?不仅准确,而且高度相关。正因如此,RAG 被广泛应用于聊天机器人、搜索引擎以及个性化内容等领域。
但关键在于:构建原型只是成功的一半。真正的挑战在于部署:将你的想法转化为可靠、可扩展的产品。
本文将向您展示如何使用LangChain和FastAPI构建和部署 RAG 系统。您将学习如何从一个可运行的原型发展成为一个可供真实用户使用的完整应用程序。
让我们开始吧!
一、什么是 RAG?
正如我们在另一份指南中探讨的那样,检索增强生成(RAG)是自然语言处理中一种相当先进的方法,它真正提升了语言模型的功能。
RAG 不仅依赖于模型已有的知识,而且还从外部来源获取新的、相关的信息,然后再生成响应。
工作原理如下:当用户提出问题时,系统并非仅仅依赖模型预先学习的数据。它首先会搜索大量的文档或数据源,提取最相关的信息,然后将其输入到语言模型中。凭借其内置知识和新检索到的信息,模型可以生成更加准确、更及时的回答。
RAG融合了检索和生成功能,因此其回复不仅智能,而且基于真实可靠的信息。这使其非常适合回答问题、开发聊天机器人,甚至生成对事实准确性和理解上下文至关重要的内容。
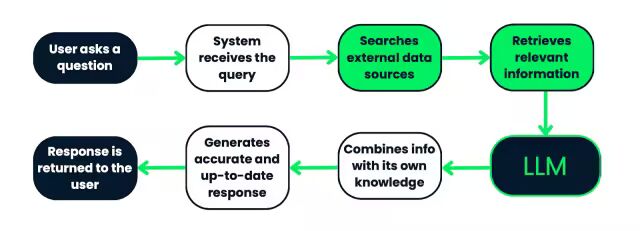
RAG系统的工作流程如下:首先,用户提交查询,系统处理该查询,并在外部数据源中搜索相关信息。然后,将检索到的信息输入到LLM(逻辑逻辑模型)中,LLM会将这些信息与其已有的知识相结合,生成准确且最新的响应。最后,将响应返回给用户。此流程确保响应基于真实且与上下文相关的数据。
1.关键组成部分
构建 RAG 系统时,有几个关键部分是其正常运行所必需的:文档加载器、文本分割、索引、检索模型和生成模型。让我们来详细了解一下:
2.文档加载器、文本分割和索引
第一步是准备数据。文档加载器、文本分割和索引就是用来做这件事的:
- 文档加载器:这些工具从各种来源(文本文件、PDF、数据库等)提取数据,并将其转换为系统实际可用的格式。简而言之,它们确保所有重要数据都已准备就绪,并以正确的格式提供给后续步骤。
- 文本分割:数据加载完成后,会被分割成更小的片段。这一点至关重要,因为更小的片段更容易搜索,而且由于语言模型的处理能力有限,它们更擅长处理小块信息。
- 索引:拆分数据后,需要对数据进行组织。索引会将这些文本块转换为向量表示。这种设置使得系统能够轻松快速地搜索所有数据,并找到与用户查询最相关的内容。
3.检索模型
这些是 RAG 系统的核心。它们负责挖掘所有索引数据,找到你需要的信息。
- 向量存储:这些数据库旨在处理文本块的向量表示。它们使用一种称为向量相似性搜索的方法,将查询与存储的向量进行比较并提取最佳匹配项,从而使搜索变得极其高效。
- 检索器:这些组件负责实际的搜索工作。它们接收用户的查询,将其转换为向量,然后在向量存储库中搜索最相关的数据。一旦获取到这些信息,就会将其传递给下一步:生成。
4.生成模型
现在,奇迹发生了。一旦获取到相关数据,生成模型就会接管并生成最终结果。
- 语言模型:这些模型负责生成实际的响应,确保响应连贯一致且符合上下文。在RAG系统中,它们会结合检索到的数据和自身的内部知识,生成最新且准确的响应。
- 上下文响应生成:生成模型将用户的问题与检索到的数据融合在一起,生成一个不仅能回答问题,还能反映从相关信息中提取的具体细节的响应。
| 组件 | 描述 |
| 文件加载器 | 从文本文件、PDF 或数据库等来源提取数据,并将信息转换为系统可用的格式。 |
| 文本分割 | 将数据加载成更小的块,从而更容易在语言模型的限制范围内进行搜索和处理。 |
| 索引 | 将拆分的数据组织成向量表示,从而实现快速高效的搜索,以找到与查询相关的信息。 |
| 向量库 | 专门用于存储向量表示的数据库,使用向量相似性搜索根据查询检索最相关的信息。 |
| 检索 | 搜索组件将查询转换为向量,搜索向量存储,并检索与下一步最相关的数据块。 |
| 语言模型 | 利用检索到的数据和内部知识,生成连贯且符合语境的回答。 |
| 上下文响应生成 | 将用户的问题与检索到的数据相结合,生成详细的答案,在回答问题的同时融入相关信息。 |
二、搭建开发环境
在构建 RAG 系统之前,我们需要确保开发环境已正确设置。以下是您需要的:
- Python 3.10+:请确保已安装 Python 3.10 或更高版本。您可以使用以下命令检查 Python 版本:
python --version - 虚拟环境:下一步是使用虚拟环境将所有依赖项集中在一个位置。为此,请在项目目录中创建一个虚拟环境并将其激活:
python3
-
m venv ragenv
source ragenv
/
bin
/
activate
# For Linux/Mac
ragenv\Scripts\activate
# For Windows
安装依赖项:现在,使用 pip 安装所需的软件包。
python3 -m venv ragenv
source ragenv/bin/activate # For Linux/Mac
ragenv\Scripts\activate # For Windows
| FastAPI | 独角兽 | 朗链 | OpenAI API |
| 一个用于构建 API 的现代化 Web 框架。 | 用于运行 FastAPI 应用程序的 ASGI 服务器。 | RAG 系统的主要库。 | 使用 GPT 模型生成响应。 |
专业提示:请务必创建一个 requirements.txt 文件,以指定项目所需的软件包。如果您使用:pip freeze > requirements.txt
此命令将生成一个 requirements.txt 文件,其中包含所有已安装的软件包及其版本,您可以将其用于部署或与他人共享环境。
添加您的 OpenAI API 密钥:要将 OpenAI 语言模型集成到您的 RAG 系统中,您需要提供您的 OpenAI API 密钥:
- 获取您的 API 密钥:如果您还没有 API 密钥,可以通过登录OpenAI 平台上的帐户来生成您的 OpenAI API 密钥。
- 创建 .env 文件:在项目根目录下,创建一个 .env 文件来安全地存储您的 API 密钥。.env 文件允许您加载环境变量。
- 将 API 密钥添加到 .env 文件:打开 .env 文件并添加以下行,将 your-openai-api-key 替换为您的实际 OpenAI 密钥:
OPENAI_API_KEY=your-openai-api-key - 在代码中加载 API 密钥:确保您的应用程序在运行时加载此密钥。在您的 Python 代码中,您可以使用 python-dotenv 包自动从 .env 文件加载环境变量:
pip install python-dotenv - 然后,在你的 Python 脚本 rag.py 中添加:
from
dotenv
import
load_dotenv
import
os
load_dotenv
(
)
openai_api_key
=
os
.
getenv
(
"OPENAI_API_KEY"
)
现在,您的 OpenAI API 密钥已从环境中安全加载,您可以开始在 RAG 系统中使用它了!
如果没有OpenAI API ,也可以通过这篇文章本地搭建模型提供服务也是可以的 不用云端!Ollama 帮你在笔记本部署Qwen3,保姆级教程
PostgreSQL 和 PGVector(可选):如果您计划使用 PGVector 进行向量存储,请确保在您的机器上安装并配置 PostgreSQL。您可以使用 FAISS(本文将使用)或其他 LangChain 支持的向量数据库。
Docker(可选):Docker可以帮助您将应用程序容器化,以确保跨环境部署的一致性。如果您计划使用 Docker,请确保您的机器上也安装了 Docker。
三、使用 LangChain 构建 RAG 管道
构建 RAG 系统的第一步是准备系统用于检索相关信息的数据。这包括将文档加载到系统中、进行处理,然后确保文档格式易于索引和检索。
1.文件加载器
LangChain 提供多种文档加载器,可处理不同的数据源,例如文本文件、PDF 或网页。您可以使用这些加载器将文档导入系统。
我非常着迷于北极熊,所以我决定上传以下文本文件(my_document.txt),其中包含以下信息:“北极熊:北极巨人”
北极熊(Ursus maritimus)是地球上体型最大的陆地食肉动物,它们完美地适应了北极的极寒环境。北极熊以其浓密的白色皮毛而闻名,这有助于它们融入白雪皑皑的景色中。它们是强大的猎手,依靠海冰捕猎海豹,海豹是它们的主要食物来源。
北极熊最令人着迷之处在于它们对环境的惊人适应能力。在厚厚的皮毛下,是一层厚达4.5英寸的脂肪层,为它们在严酷的冬季提供保暖和能量储备。它们巨大的爪子帮助它们在冰面和开阔水域上行走,使它们成为游泳健将——能够长途跋涉寻找食物或新的领地。
不幸的是,气候变化正对北极熊构成严重威胁。随着北极变暖,海冰融化的时间提前,形成的时间推迟,这缩短了北极熊捕猎海豹的时间。食物短缺导致许多北极熊难以生存,一些地区的北极熊数量正在减少。
北极熊在维持北极生态系统的健康方面发挥着至关重要的作用,它们的困境有力地提醒我们气候变化对世界野生动物的广泛影响。目前正在开展保护工作,以保护它们的栖息地,并确保这些雄伟的生物能够在野外继续繁衍生息。
from langchain_community.document_loaders import TextLoader
loader = TextLoader('data/my_document.txt')
documents = loader.load()
这里加载了一个简单的文本文件到系统中,仅作为教学示例,但您可以添加任何类型的文档!例如,您可以添加组织内部的文档。文档变量现在保存着文件的内容,可以进行处理了。
2.将文本分段
大型文档通常会被拆分成较小的块,以便于索引和检索。这一过程至关重要,因为较小的块更容易被语言模型处理,从而实现更精确的检索。您可以在我们关于人工智能和红绿灯分类的块策略指南中了解更多信息。
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
document_chunks = splitter.split_documents(documents)
这里,文本被分割成500个字符的块,块与块之间有50个字符的重叠。这种重叠有助于在检索过程中保持各块之间的上下文关联。
数据准备就绪后,下一步是对其进行索引,以便高效检索。索引过程包括将文本块转换为向量嵌入,并将其存储在向量存储库中。
3.嵌入
LangChain支持使用各种模型(例如OpenAI或HuggingFace模型)创建向量嵌入。这些嵌入表示文本块的语义含义,因此适用于相似性搜索。
简单来说,嵌入本质上是将文本(例如文档中的段落)转换成人工智能模型可以理解的数字的方法。这些数字(或向量)以一种便于人工智能系统处理的方式表示文本的含义。
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
我们使用OpenAI 的嵌入库来处理这种转换。首先,我们引入 OpenAI 的嵌入工具,然后对其进行初始化,使其可以立即使用。
3.向量存储
生成词嵌入后,下一步是将它们存储在向量存储库中,例如PGVector、FAISS 或 LangChain 支持的任何其他存储库。这样,在进行查询时,就可以快速准确地检索相关文档。
from langchain_community.vectorstores import FAISS
vector_store = FAISS.from_documents(document_chunks, embeddings)
在这种情况下,我们使用FAISS,它是一款专为搜索大型向量集而设计的出色工具。FAISS 可以帮助我们快速找到最相似的向量。
具体来说,我们从 LangChain 引入 FAISS,并用它来创建一个所谓的向量存储库。它就像一个特殊的数据库,专门用于高效地存储和搜索向量。
这种设置的妙处在于,当我们稍后进行搜索时,FAISS 将能够浏览所有这些向量,找到与给定查询最相似的向量,并返回相应的文档块。
数据建立索引后,现在可以实现检索组件,该组件负责根据用户查询获取相关信息。
5.检索
现在我们正在设置检索器。该组件会遍历已索引的文档,并找到与用户查询最相关的文档。
现在,妙处在于,你并非随机搜索,而是利用词嵌入进行智能搜索,因此搜索结果在语义上与用户搜索的内容更为接近。让我们深入分析一下这行代码:
retriever
=
vector_store
.
as_retriever
(
search_type
=
"similarity"
,
search_kwargs
=
{
"k"
:
5
}
)
首先,我们将矢量存储库转换为检索器。您知道您已经将 FAISS 矢量存储库填充了文档嵌入信息吗?现在,我们告诉它:“嘿,当用户向我提问时,就用这些信息来搜索内容吧。”
现在,search\_type 参数才是关键所在。检索器可以采用不同的搜索方式,这里你有几个选项。相似性搜索是检索的基础。它会检查哪些文档的含义与查询最接近。
所以,当你说“search_type=‘similarity’”时,你是在告诉检索器,“根据我们生成的嵌入,找到与查询最相似的文档”。
使用 search_kwargs={“k”: 5} 可以进行微调。k 值告诉检索器要从向量存储中提取多少个文档。在本例中,k=5 表示“给我 5 个最相关的文档”。
这非常强大,因为它有助于减少干扰信息。你不会得到一大堆可能略微相关的结果,而是只获取最重要的信息。
6.查询
在这部分代码中,我们将使用 LangChain 设置 RAG 系统的核心引擎。您已经拥有了检索器,它可以根据查询检索相关文档。
现在,我们添加了 LLM,并使用它来根据检索到的文档实际生成响应。
from
langchain_openai
import
OpenAI
# Updated import
from
langchain
.
chains
import
RetrievalQA
这里,我们要导入两个关键要素:
- OpenAI:这是你们的大型语言模型,我们从langchain_openai包中引入了它。这个模型将负责生成文本回复。
- 检索问答:这是 LangChain 的一项特殊功能,它将检索和问答(问答)结合起来。它将您的检索器(用于查找相关文档)连接到您的 LLM(用于生成答案)。
llm
=
OpenAI
(
openai_api_key
=
openai_api_key
)
这行代码使用您的 OpenAI API 密钥初始化 LLM。您可以将其理解为加载系统的“大脑”——这个模型将接收文本、理解文本并生成响应。
qa_chain
=
RetrievalQA
.
from_chain_type
(
llm
=
llm
,
chain_type
=
"stuff"
,
retriever
=
retriever
)
接下来才是真正激动人心的部分。我们正在搭建问答链,它将所有组件连接起来。RetrievalQA.from\_chain\_type() 方法会创建一个问答链,也就是说,“将检索器和 LLM 结合起来,创建一个能够根据检索到的文档回答问题的系统。”
然后,我们指示算法链使用刚刚初始化的 OpenAI LLM 来生成答案。之后,我们连接您之前构建的检索器。检索器负责根据用户的查询查找相关文档。
然后我们设置 chain_type=“stuff”:好的,这里的“stuff”是什么?它实际上是 LangChain 中的一种链类型。“stuff”意味着我们将所有相关的检索文档加载到 LLM 中,并让它基于所有这些文档生成响应。
这就像把一堆笔记扔到LLM的桌子上,然后说:“来,用这些信息来回答这个问题。”
还有其他类型的链(如“map_reduce”或“refine”),但“stuff”是最简单、最直接的。
query
=
"Are polar bears in danger?"
response
=
qa_chain
.
invoke
(
{
"query"
:
query
}
)
在这里,我们会向系统提出问题并获得响应。invoke() 方法会触发整个流程。
它接收您的查询,将其发送给检索器以获取相关文档,然后将这些文档传递给 LLM,LLM 生成最终响应。
print
(
response
)
最后一步是打印 LLM 生成的响应。系统根据检索到的文档,生成对查询的完整、信息充分的答案,并将其打印出来。
最终脚本如下所示:
from
dotenv
import
load_dotenv
import
os
from
langchain_community
.
document_loaders
import
TextLoader
from
langchain
.
text_splitter
import
RecursiveCharacterTextSplitter
from
langchain_openai
.
embeddings
import
OpenAIEmbeddings
from
langchain_community
.
vectorstores
import
FAISS
from
langchain
.
chains
import
RetrievalQA
from
langchain_openai
import
OpenAI
# Load environment variables
load_dotenv
(
)
openai_api_key
=
os
.
getenv
(
"OPENAI_API_KEY"
)
# Load the document
loader
=
TextLoader
(
'data/my_document.txt'
)
documents
=
loader
.
load
(
)
# Split the document into chunks
splitter
=
RecursiveCharacterTextSplitter
(
chunk_size
=
500
,
chunk_overlap
=
50
)
document_chunks
=
splitter
.
split_documents
(
documents
)
# Initialize embeddings with OpenAI API key
embeddings
=
OpenAIEmbeddings
(
openai_api_key
=
openai_api_key
)
# FAISS expects document objects and the embedding model
vector_store
=
FAISS
.
from_documents
(
document_chunks
,
embeddings
)
# Use the vector store's retriever
retriever
=
vector_store
.
as_retriever
(
)
# Initialize the LLM (using OpenAI)
llm
=
OpenAI
(
openai_api_key
=
openai_api_key
)
# Set up the retrieval-based QA chain
qa_chain
=
RetrievalQA
.
from_chain_type
(
llm
=
llm
,
chain_type
=
"stuff"
,
retriever
=
retriever
)
# Example query
query
=
"Are polar bears in danger?"
response
=
qa_chain
.
invoke
(
{
"query"
:
query
}
)
# Print the response
print
(
response
)
7.使用 FastAPI 开发 API
现在需要构建一个 API 来与你的 RAG 系统进行交互。但是,为什么部署过程中需要这一步呢?
想象一下,你一直在按照本教程操作,并且已经设置好了一个非常棒的RAG系统,该系统根据你的文档和需求进行了个性化定制——它可以提取相关信息、处理查询并生成智能响应。但是,你究竟该如何让用户或其他系统与它进行交互呢?
FastAPI 是您的中间人。它为用户或应用程序创建了一种简单、结构化的方式,让他们可以向您的 RAG 系统提出问题并获得答案。
FastAPI 是异步的、高性能的。这意味着它可以同时处理多个请求而不会变慢,这对于可能需要检索大量数据或运行复杂查询的 AI 系统来说至关重要。
在本节中,我们将修改之前的脚本并创建其他脚本,以确保您的 RAG 系统具有可访问性、可扩展性,并能够处理实际流量。首先,让我们创建用于处理 RAG 系统传入请求的路由。
8.编写你的 main.py 文件
在你的工作目录中创建一个main.py文件。这将是 FastAPI 应用的入口点。它将成为 FastAPI 的核心——这个文件会将所有 API 路由、依赖项和 RAG 系统整合在一起。
from
fastapi
import
FastAPI
from
endpoints
import
router
app
=
FastAPI
(
)
app
.
include_router
(
router
)
这是一个非常简单的设置,但很清晰。我们在这里要做的是设置一个 FastAPI 实例,然后从另一个文件中引入所有路由(或 API 路径),我们接下来会创建这个文件。
9.修改你的 rag.py 脚本
现在,一切都汇聚到这里了。我们将编写一个函数,当用户提交查询时,该函数会实际执行您的 RAG 系统。
async
def
get_rag_response
(
query
:
str
)
:
此函数被标记为async异步函数,这意味着它在等待响应的同时可以处理其他任务。
当您处理基于检索的系统时,此功能尤其有用,因为获取文档或查询LLM可能需要一些时间。这样,FastAPI可以在后台处理其他请求,同时处理当前请求。
retriever
=
setup_rag_system
(
)
这里我们调用了该setup_rag_system()函数,正如我们之前提到的,它会初始化整个检索器管道。这意味着:
- 您的文档已加载并分块。
- 生成嵌入向量。
- FAISS 矢量存储库旨在实现快速文档检索。
该检索器将负责根据用户的查询获取相关的文本块。
现在,当用户提出问题时,检索器会遍历矢量存储中的所有文档,并根据查询提取最相关的文档。
retrieved_docs
=
retriever
.
get_relevant_documents
(
query
)
这种invoke(query)方法会获取相关的文档。在后台,它会将查询与嵌入向量进行匹配,并根据相似度提取出最佳匹配项。
现在我们已经有了相关文件,我们需要将其格式化为LLM格式。
context
=
"\n"
.
join
(
[
doc
.
page_content
for
doc
in
retrieved_docs
]
)
在这里,我们将所有检索到的文档合并成一个字符串。这一点很重要,因为LLM需要的是一段完整的文本,而不是一堆零散的片段。
我们使用 Python 的join()函数将这些文档块拼接成一个连贯的信息块。每个文档的内容都存储在字段中doc.page_content,我们用换行符(\n)将它们连接起来。
现在我们正在创建LLM的提示。
prompt
=
[
f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"
]
提示的结构方式是告诉 LLM 使用检索到的信息来回答用户的查询。
现在是时候做出回应了。
generated_response
=
llm
.
generate
(
prompt
)
# Pass as a list of strings
现在,OpenAI 模型的任务是接收提示,并根据问题和相关文档生成具有上下文感知的响应。
最后,我们将生成的响应返回给调用该函数的人(无论是用户、前端应用程序还是其他系统)。
return
generated_response
该回复完整、切合实际,可直接用于实际应用。
总而言之,这个函数执行完整的检索和生成循环。以下是流程的简要概述:
-
它设置检索程序以查找相关文档。
-
这些文档是根据查询结果提取出来的。
-
这些文件中的背景信息已为LLM课程准备就绪。
-
LLM 使用该上下文生成最终响应。
-
将响应返回给用户。
from
dotenv
import
load_dotenv
import
os
from
langchain_community
.
document_loaders
import
TextLoader
from
langchain
.
text_splitter
import
RecursiveCharacterTextSplitter
from
langchain_openai
.
embeddings
import
OpenAIEmbeddings
from
langchain_community
.
vectorstores
import
FAISS
from
langchain_openai
import
OpenAI
# Load environment variables
load_dotenv
(
)
openai_api_key
=
os
.
getenv
(
"OPENAI_API_KEY"
)
# Initialize the LLM (using OpenAI)
llm
=
OpenAI
(
openai_api_key
=
openai_api_key
)
# Function to set up the RAG system
def
setup_rag_system
(
)
:
# Load the document
loader
=
TextLoader
(
'data/my_document.txt'
)
documents
=
loader
.
load
(
)
# Split the document into chunks
splitter
=
RecursiveCharacterTextSplitter
(
chunk_size
=
500
,
chunk_overlap
=
50
)
document_chunks
=
splitter
.
split_documents
(
documents
)
# Initialize embeddings with OpenAI API key
embeddings
=
OpenAIEmbeddings
(
openai_api_key
=
openai_api_key
)
# Create FAISS vector store from document chunks and embeddings
vector_store
=
FAISS
.
from_documents
(
document_chunks
,
embeddings
)
# Return the retriever for document retrieval with specified search_type
retriever
=
vector_store
.
as_retriever
(
search_type
=
"similarity"
,
# or "mmr" or "similarity_score_threshold"
search_kwargs
=
{
"k"
:
5
}
# Adjust the number of results if needed
)
return
retriever
# Function to get the response from the RAG system
async
def
get_rag_response
(
query
:
str
)
:
retriever
=
setup_rag_system
(
)
# Retrieve the relevant documents using 'get_relevant_documents' method
retrieved_docs
=
retriever
.
get_relevant_documents
(
query
)
# Prepare the input for the LLM: Combine the query and the retrieved documents into a single string
context
=
"\n"
.
join
(
[
doc
.
page_content
for
doc
in
retrieved_docs
]
)
# LLM expects a list of strings (prompts), so we create one by combining the query with the retrieved context
prompt
=
[
f"Use the following information to answer the question:\n\n{context}\n\nQuestion: {query}"
]
# Generate the final response using the language model (LLM)
generated_response
=
llm
.
generate
(
prompt
)
return
generated_response
10.在 API 路由中定义 API 路由endpoints.py
接下来,我们来创建endpoints.py文件。在这里,我们将定义用户与 RAG 系统交互时实际调用的路径。
from
fastapi
import
APIRouter
,
HTTPException
from
rag
import
get_rag_response
router
=
APIRouter
(
)
@router.get
(
"/query/"
)
async
def
query_rag_system
(
query
:
str
)
:
try
:
# Pass the query string to your RAG system and return the response
response
=
await
get_rag_response
(
query
)
return
{
"query"
:
query
,
"response"
:
response
}
except
Exception
as
e
:
raise
HTTPException
(
status_code
=
500
,
detail
=
str
(
e
)
)
我们创建了一个APIRouter用于管理 API 路由的接口。该/query/接口接受带有查询字符串的 **GET** 请求。它会调用get_rag_response您rag.py文件中的函数,该函数负责处理整个 RAG 流程(文档检索 + 语言生成)。如果出现任何错误,我们会抛出一个包含详细信息的 HTTP 500 错误。
11.使用 Uvicorn 运行服务器
完成所有设置后,您现在可以使用 Uvicorn 运行 FastAPI 应用了。Uvicorn 是一个 Web 服务器,用户可以通过它访问您的 API。
打开终端并运行:
uvicorn app.main:app
--reload
app.main:app``app告诉 Uvicorn在文件中查找实例main.py,并--reload 在对代码进行任何更改时启用自动重新加载。
服务器运行后,打开浏览器并访问http://127.0.0.1:8000/docs。FastAPI 会自动为您的 API 生成 Swagger UI 文档,因此您可以直接在浏览器中进行测试!
FastAPI Swagger UI 提供了一个简洁且交互式的界面,用于探索和测试 API 端点。例如,/query/ 端点允许用户输入查询字符串,并接收由 RAG 管道生成的响应。
12.测试 API
FastAPI 服务器运行后,打开浏览器或使用 Postman 或 Curl 向/query/端点发送 GET 请求。
在浏览器中,通过 Swagger:
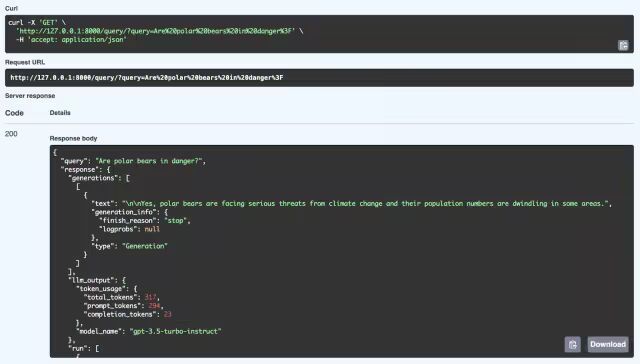
这里我们可以看到 RAG 系统对查询“北极熊是否处于危险之中?”的成功响应。该系统从其知识库中检索相关信息,并使用 GPT-3.5 Turbo-Instruct 模型生成连贯的响应。详细的响应不仅包含答案(是的,北极熊正面临气候变化的严重威胁,其种群数量正在减少),还包含元数据,例如词元使用情况(处理的词元数量)和用于生成响应的模型。该 API 通过 FastAPI 结合检索和生成机制,能够提供结构良好、上下文相关的答案。
现在我们来谈谈 FastAPI 中异步处理的优势,以及为什么它在处理实际 API 请求方面能带来如此大的不同。
您的红黄绿灯系统已经启动并运行。API 正在接收问题,从其知识库中检索相关信息,然后使用语言模型生成回复。
如果整个过程是同步的,系统就会一直运行,等待每个任务完成后才能继续执行下一个任务。例如,在检索文档期间,系统将无法处理任何新的请求。
| 非阻塞 I/O | 性能提升 | 更佳的用户体验 |
| 异步函数允许服务器一次处理多个请求,而不是等待一个请求完成后再开始另一个请求。 | 对于从矢量存储中检索文档或生成文本等任务,异步处理可确保 API 能够高效地处理高负载。 | 客户端可以获得更快的响应速度,即使在高负载情况下,您的 API 也能保持响应速度。 |
- 非阻塞 I/O :异步函数允许服务器一次处理多个请求,而不是等待一个请求完成再开始另一个请求。
- 性能提升:对于从矢量存储中检索文档或生成文本等任务,异步处理可确保 API 能够高效地处理高负载。
- 更佳的用户体验:客户获得更快的响应速度,即使在高负载情况下,您的 API 也能保持响应。
四、RAG部署策略
我们来谈谈部署策略——这是将您的 RAG 系统从原型转化为完全可运行产品的关键步骤。其目标是确保您的系统已打包、部署完毕并做好扩展准备,以便能够应对真实用户的需求。
1.使用 Docker 进行容器化
首先,我们来谈谈Docker。Docker就像一个神奇的盒子,它将你的 RAG 系统所需的一切——代码、依赖项、配置——打包到一个简洁的小容器中。
这样可以确保无论将应用部署到哪里,其行为都完全相同。你可以在不同的环境中运行应用,但由于它运行在容器中,因此无需担心“在我的机器上运行正常”的问题。

你需要创建一个 Dockerfile,它是一组指令,告诉 Docker 如何设置应用程序的环境、安装必要的软件包并启动运行。完成这些步骤后,你就可以从中构建 Docker 镜像,并在容器内运行你的应用程序。它高效、可重复且具有极强的可移植性。
2.云部署
现在,一旦你的系统打包完毕并准备就绪,你很可能需要将其部署到云端。这才是关键所在,因为将 RAG 系统部署到云端意味着它可以从世界任何地方访问。此外,它还能为你提供可扩展性、可靠性,以及对其他云服务的访问权限,从而增强你的系统性能。
我们再来看看另外几个流行的云平台,包括 Azure 和 Google Cloud:
AWS提供 Elastic Beanstalk 等工具,让部署变得非常简单。您只需将 Docker 容器交给 AWS,AWS 就会负责扩展、负载均衡和监控。如果您需要更多控制权,可以使用 Amazon ECS,它允许您在服务器集群上运行 Docker 容器,并根据需要进行扩展或缩减。
Heroku 是另一个简化部署的选择。你只需推送代码,Heroku 就会为你处理基础设施。如果你不想深入了解云资源管理的细节,Heroku 是个不错的选择。
Azure提供 Azure 应用服务,让您可以轻松部署和管理 RAG 系统,并提供对自动缩放、负载均衡和持续部署的内置支持。
为了获得更大的灵活性,您可以使用 Azure Kubernetes 服务 (AKS) 大规模管理 Docker 容器,确保您的系统能够处理高流量,并能够根据需要动态调整资源。
GCP拥有 Google Cloud Run,这是一个完全托管的平台,可让您部署容器并根据流量自动扩展它们。
如果您想要更好地控制您的基础设施,可以选择 Google Kubernetes Engine (GKE),它使您能够跨多个节点管理和扩展您的 Docker 容器,并且还具有与 Google 云服务(如 AI 和机器学习 API)深度集成的额外优势。
每个平台都有其优势,无论您想要的是简单易用和自动化,还是对部署进行更精细的控制。
3.最后想说的话
本文涵盖了许多内容,详细介绍了如何使用 LangChain 和 FastAPI 构建 RAG 系统。RAG 系统是自然语言处理领域的一大进步,因为它引入了外部信息,使 AI 能够生成更准确、更相关、更具上下文感知能力的回复。
借助 LangChain,我们拥有一个强大的框架,可以处理从加载文档、分割文本、创建嵌入到根据用户查询检索信息等所有操作。
然后,FastAPI 为我们提供了一个快速、支持异步的 Web 框架,帮助我们将 RAG 系统部署为可扩展的 API。
这些工具结合起来,可以更轻松地构建能够处理复杂查询、提供精确答案并最终提供更好用户体验的 AI 应用程序。
现在,是时候将你所学到的知识应用到你自己的项目中了。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2025 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?
更多推荐


 33
33 0
0- 0



 已为社区贡献276条内容
已为社区贡献276条内容

所有评论(0)