
LLM 评估体系详解:从多轮对话到 RAG 与 AI Agent 的落地评估
是时候准备面试和实习了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。智能体评估主要是测试你的 LLM 应用,以确保其性能保持一致。这不是最令人兴奋的话题,但越来越多的公司开始关注它。因此,值得深入研究应该追踪哪些指标来实际衡量这种性能。在推送任何更改
是时候准备面试和实习了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

智能体评估主要是测试你的 LLM 应用,以确保其性能保持一致。
这不是最令人兴奋的话题,但越来越多的公司开始关注它。因此,值得深入研究应该追踪哪些指标来实际衡量这种性能。
在推送任何更改时进行适当的评估也有助于确保一切正常运行。
因此,在本文中,我对多轮聊天机器人、RAG 和智能体应用的常见指标进行了一些研究。
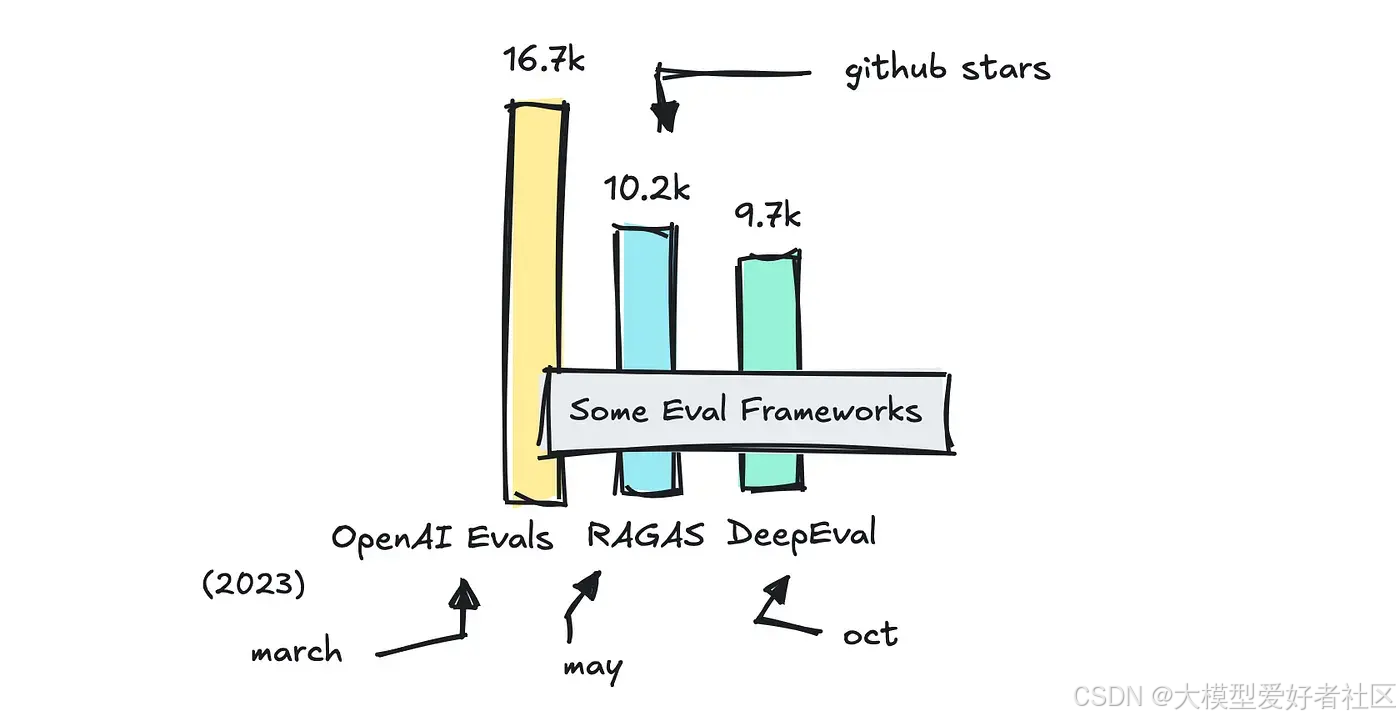
我还包含了对 DeepEval、RAGAS 和 OpenAI 的 Evals 库等框架的快速回顾,这样你就知道何时选择什么。
本文分为两部分。如果您是新手,第一部分将简要介绍 BLEU 和 ROUGE 等传统指标,提及 LLM 基准测试,并介绍在评估中使用 LLM 作为评判者的理念。
如果这对您来说不是新内容,您可以跳过这部分。第 2 部分将深入探讨不同类型 LLM 应用的评估。
我们之前做了什么
如果您熟悉我们如何评估 NLP 任务以及公共基准的工作原理,可以跳过第一部分。
如果你不是,那么了解早期的指标如准确率和 BLEU 最初是用于什么以及它们如何工作就很重要,同时也要理解我们如何测试像 MMLU 这样的公共基准。
评估 NLP 任务
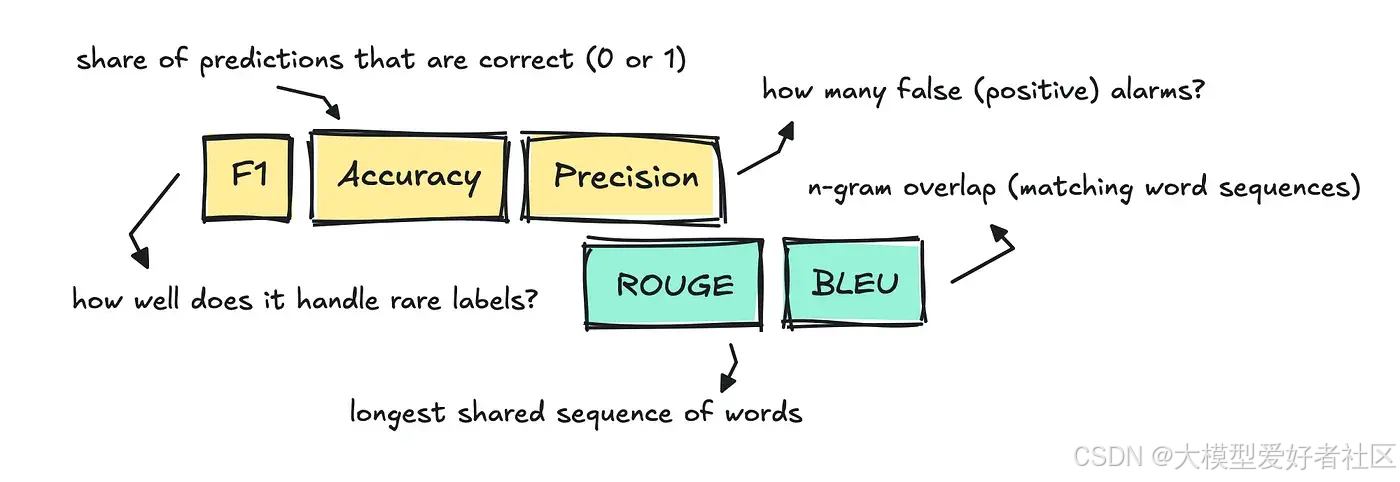
当我们评估传统的自然语言处理任务,如分类、翻译、摘要等时,我们会采用准确率、精确率、F1 值、BLEU 和 ROUGE 等传统指标。
这些指标至今仍在使用,但主要是在模型产生单一且易于比较的"正确"答案时。
以分类为例,任务是为每个文本分配单个标签。为了测试这一点,我们可以使用准确率,通过比较模型分配的标签与评估数据集中的参考标签,来判断其是否正确。
这非常明确:如果分配了错误的标签,得分为 0;如果分配了正确的标签,得分为 1。
这意味着如果我们为包含 1000 封邮件的垃圾邮件数据集构建一个分类器,并且模型正确标记了其中的 910 封,那么准确率将是 0.91。
对于文本分类,我们也经常使用 F1 值、精确率和召回率。
在文本摘要和机器翻译等自然语言处理任务中,人们经常使用 ROUGE 和 BLEU 来评估模型的翻译或摘要与参考文本的匹配程度。
两个分数都计算重叠的 n 元语法,虽然比较的方向不同,但本质上只是意味着共享的词块越多,分数就越高。
这相当简单,因为如果输出使用不同的措辞,得分就会很低。
当回答只有一个正确答案时,所有这些指标效果最佳,但通常不适用于我们今天构建的 LLM 应用。
LLM 基准测试
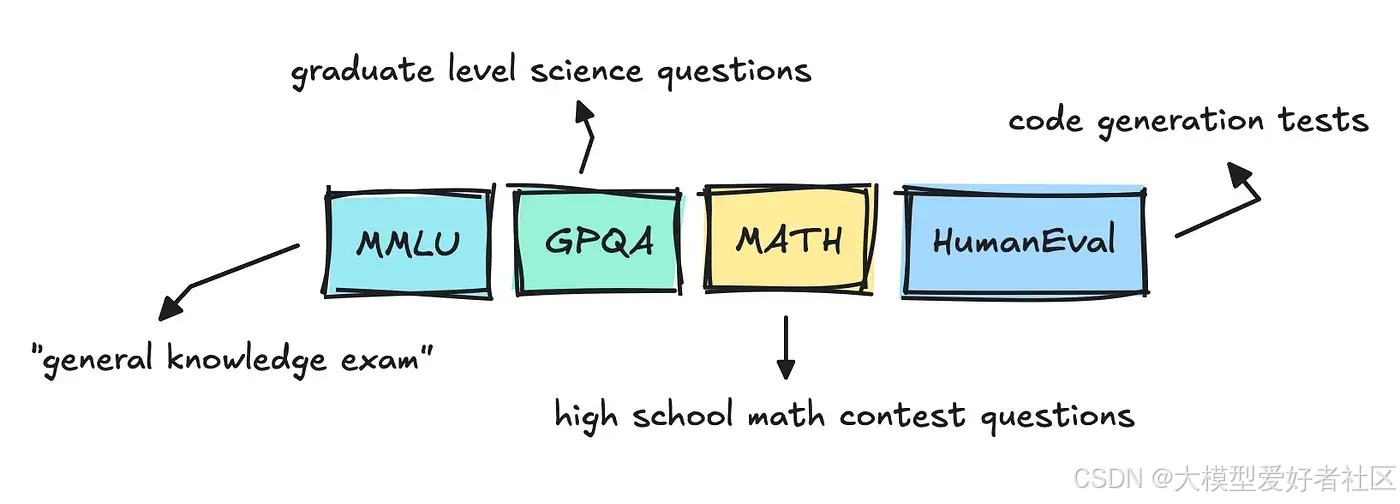
如果你看过新闻,你可能已经注意到,每当新的大型语言模型版本发布时,它都会遵循几个基准:MMLU Pro、GPQA 或 Big-Bench。
这些是通用评估,其更准确的术语其实是"基准测试"而非评估(我们将在后面讨论)。
尽管每个模型还进行了其他各种评估,包括毒性、幻觉和偏见评估,但最受关注的评估更像是考试或排行榜。
像 MMLU 这样的数据集是多选题,已经存在相当一段时间了。我之前其实浏览过它,也看到了它有多么混乱。
有些问题和答案相当模糊,这让我觉得 LLM 提供商会尝试在这些数据集上训练他们的模型,以确保能够正确回答这些问题。
这给公众带来了一些担忧,认为大多数 LLMs 在这些基准测试中表现良好只是因为过拟合,以及为什么需要新的数据集和独立的评估。
LLM 评分器
要对这些数据集进行评估,您通常可以使用准确性和单元测试。然而,现在不同的是增加了一种被称为 LLM-as-a-judge 的方法。
为了对模型进行基准测试,团队将主要使用传统方法。
只要题目是选择题或者只有一个正确答案,那么除了将答案与参考答案进行精确比对之外,就不需要其他任何东西了。
对于 MMLU 和 GPQA 等具有多项选择答案的数据集来说,情况也是如此。
对于编程测试(HumanEval、SWE-Bench),评分器可以直接运行模型的补丁或函数。如果所有测试都通过,则问题被视为已解决,反之亦然。
然而,正如您可以想象的那样,如果问题模糊或开放式,答案可能会有所波动。这一差距催生了"LLM 作为评判"的方法,即像 GPT-4 这样的大型语言模型对答案进行评分。
MT-Bench 是使用 LLMs 作为评分者的基准测试之一,因为它向 GPT-4 提供两个竞争性的多轮回答,并询问哪个更好。
Chatbot Arena 使用人工评分员,我认为现在通过结合使用 LLM 作为评判者来扩展规模。
为了透明度,您也可以使用 BERTScore 等语义标尺来比较语义相似度。我这里省略了现有的方法,以保持内容的简洁。
因此,团队可能仍会使用 BLEU 或 ROUGE 等重叠指标进行快速检查,或在可能的情况下依赖精确匹配解析,但新的做法是让另一个大型语言模型来评判输出结果。
我们如何使用 LLM 应用
现在主要的变化是,我们测试的不再仅仅是 LLM 本身,而是整个系统。
当我们能够做到时,我们仍然使用程序化方法进行评估,就像以前一样。
为了获得更细致的输出,我们可以从一些简单且确定性的方法开始,比如查看 n-gram 重叠的 BLEU 或 ROUGE,但现在大多数现代框架都会使用 LLM 评分器来进行评估。
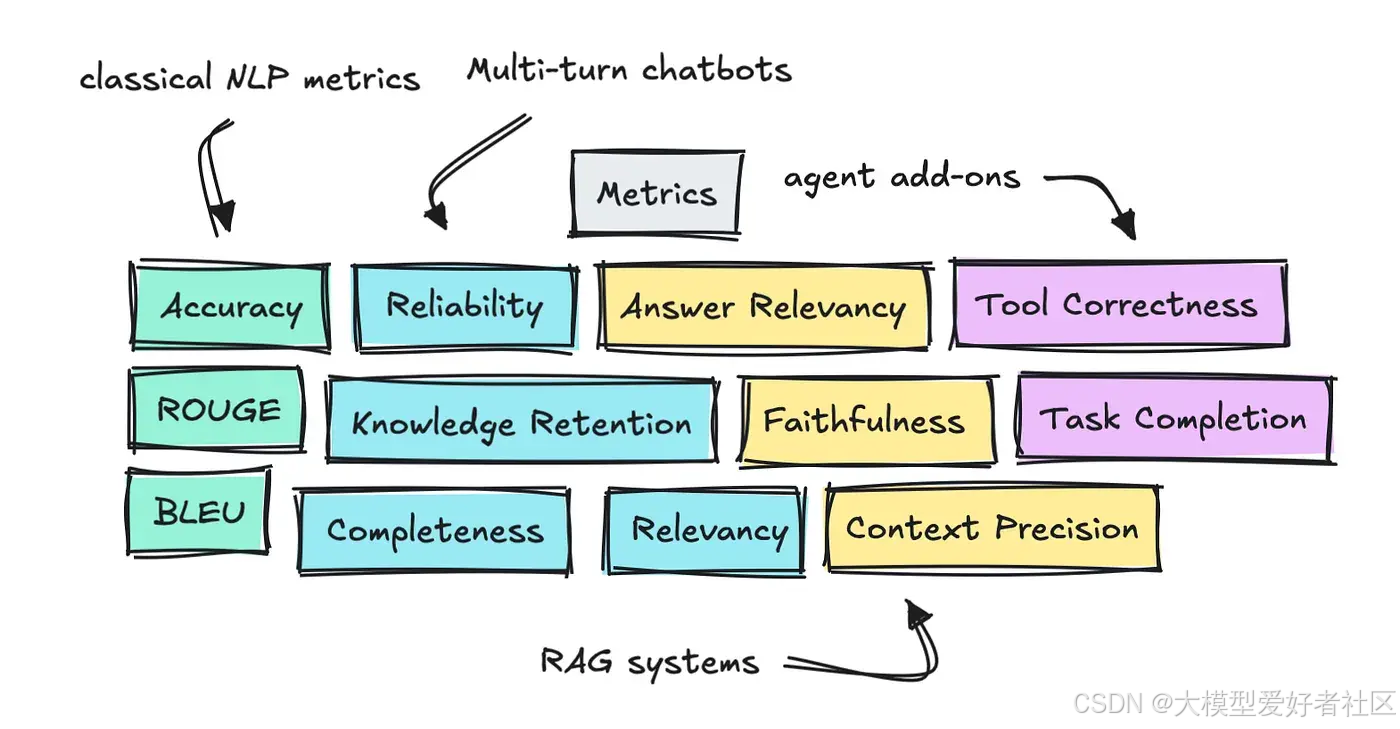
有三个值得讨论的领域:如何评估多轮对话、RAG 和代理,包括实施方法和可采用的指标类型。
您可以在下方看到这三个领域中已经定义的大量指标。
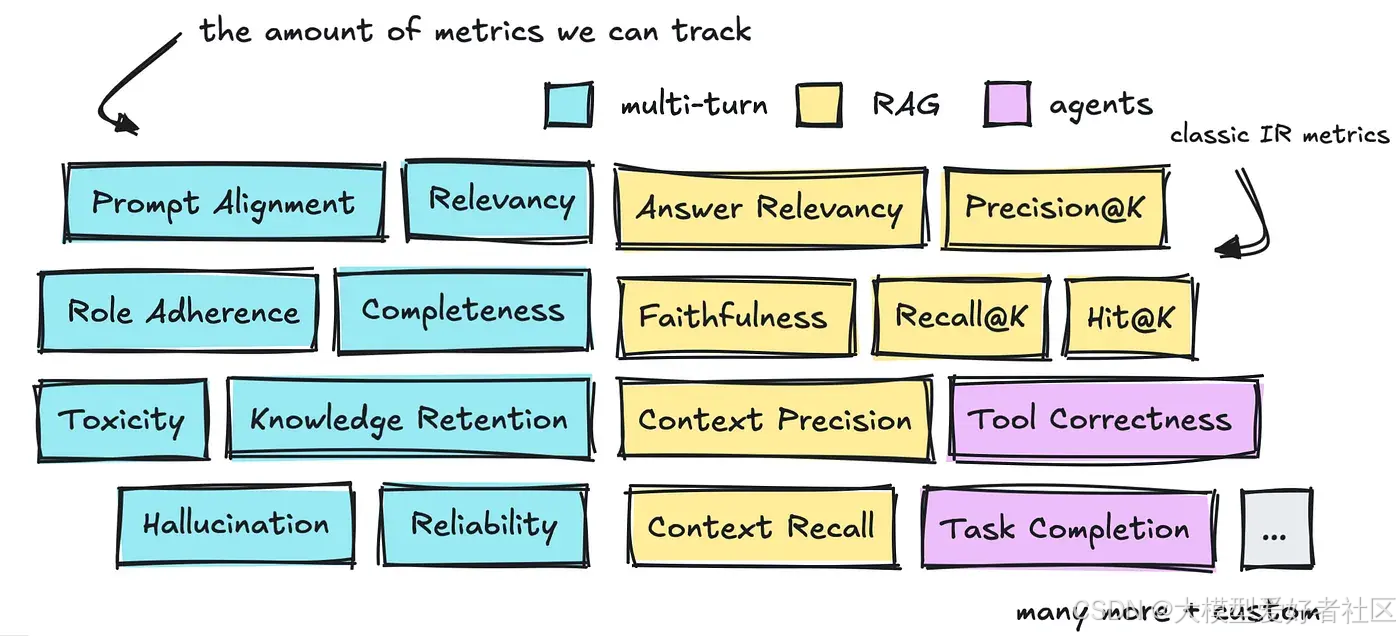
在继续讨论帮助我们解决问题的不同框架之前,我们将简要介绍所有这些内容。
多轮对话
第一部分是关于为多轮对话构建评估方法,也就是我们在聊天机器人中看到的那种对话。
当我们与聊天机器人互动时,我们希望对话感觉自然、专业,并且能够记住关键信息。我们希望对话能够始终围绕主题,并且真正回答我们提出的问题。
人们在这里跟踪的标准指标相当多。首先我们可以讨论的是相关性/连贯性和完整性。
相关性是一个指标,用于衡量 LLM 是否恰当地回应用户的查询并保持主题相关,而完整性则指最终结果是否真正解决了用户的目标。
也就是说,如果我们能够追踪整个对话过程中的满意度,我们也能够追踪它是否真的"降低了支持成本"并增加了信任,同时提供了高"自助服务率"。
第二部分是知识保留与可靠性。
也就是说:它是否能记住对话中的关键细节,我们能否相信它不会"迷失"?仅仅记住细节是不够的。它还需要能够自我纠正。
这是我们在氛围编码工具中看到的现象。它们会忘记自己犯过的错误,然后反复重蹈覆辙。我们应该将其归类为低可靠性或稳定性。
我们可以追踪的第三部分是角色遵循和提示对齐。这追踪 LLM 是否坚持其被赋予的角色,以及是否遵循系统提示中的指令。
接下来是关于安全性的指标,例如幻觉和偏见/毒性。
幻觉很重要需要追踪,但也相当困难。人们可能会尝试设置网络搜索来评估输出,或者将输出拆分为不同的主张,由更大的模型(LLM 作为裁判风格)进行评估。
还有其他方法,例如 SelfCheckGPT,它通过在同一提示下多次调用模型来检查其一致性,观察模型是否坚持原始答案以及有多少次出现偏离。
对于偏见/毒性,您可以使用其他 NLP 方法,例如微调分类器。
您可能想要跟踪的其他指标可以针对您的应用程序进行定制,例如代码正确性、安全漏洞、JSON 正确性等等。
至于如何进行评估,您并不总是需要使用 LLM,尽管在大多数情况下标准解决方案确实会使用。
在某些情况下,例如解析 JSON 时,我们可以直接提取正确答案,自然就不需要使用 LLM。正如我之前所说,许多 LLM 提供商也使用单元测试来评估与代码相关的指标。
不言而喻,用于判断的 LLMs 并不总是超级可靠的,就像它们所衡量的应用程序一样,但我这里没有给你任何数据,所以你得自己去寻找。
检索增强生成 (RAG)
为了继续扩展我们在多轮对话中可以追踪的内容,我们可以转向在使用 RAG 时需要衡量的指标。
对于 RAG 系统,我们需要将过程分为两部分:分别衡量检索和生成指标。
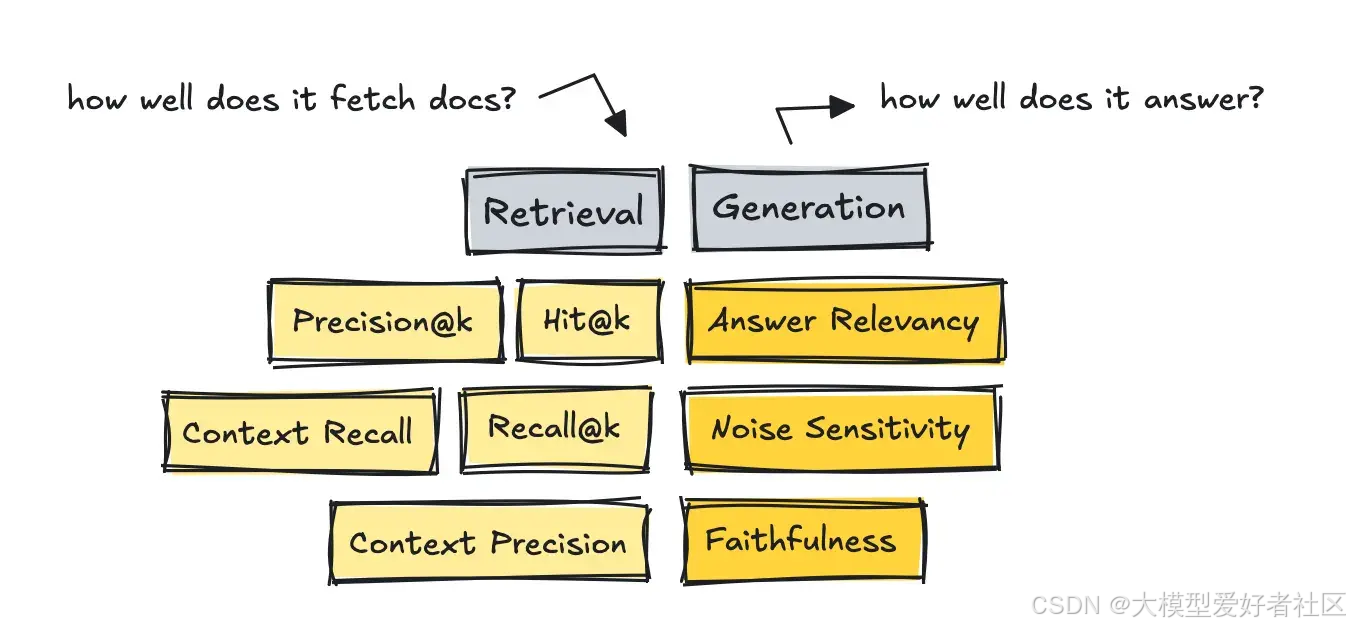
首先要衡量的是检索能力,以及获取的文档是否与查询内容相符。
如果在检索方面得分较低,我们可以通过设置更好的分块策略、更换嵌入模型、添加混合搜索和重排序等技术、使用元数据进行过滤以及类似方法来调整系统。
为了衡量检索效果,我们可以使用依赖人工整理数据集的传统指标,也可以使用以 LLM 作为评判者的无参考方法。
我需要先提及经典的 IR 指标,因为它们是最早出现的。对于这些指标,我们需要"黄金"答案,即我们设置一个查询,然后针对该特定查询对每个文档进行排序。
虽然你可以使用 LLM 来构建这些数据集,但我们不使用 LLM 进行测量,因为数据集中已经有可供比较的分数了。
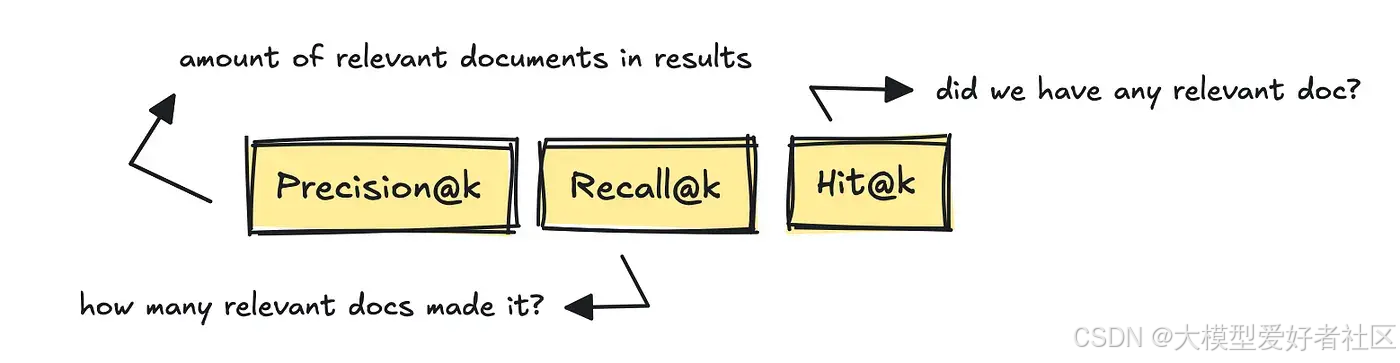
最著名的 IR 指标是 Precision@k、Recall@k 和 Hit@k。
这些指标衡量了获取的相关文档数量、基于黄金参考答案检索到的相关文档数量,以及是否至少有一篇相关文档被纳入结果中。
更新的框架如 RAGAS 和 DeepEval 引入了无需参考的、基于 LLM 评估的指标,如 Context Recall 和 Context Precision。
这些通过使用 LLM 来判断,计算有多少真正相关的块基于查询进入了前 K 列表。
也就是说,基于查询,系统是否实际返回了任何相关文档,或者是否存在过多不相关的文档而无法正确回答问题?
要构建用于评估检索的数据集,您可以从真实日志中挖掘问题,然后由人工进行筛选整理。
你也可以借助 LLM 使用数据集生成器,这些生成器存在于大多数框架中,或者作为像 YourBench 这样的独立工具。
如果你要使用一个 LLM 来建立自己的数据集生成器,可以执行如下操作。
# Prompt to generate questions
qa_generate_prompt_tmpl = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and no prior knowledge
generate only {num} questions and {num} answers based on the above context.
...
如果我们转向 RAG 系统的生成部分,我们现在正在衡量它使用提供的文档回答问题的能力。
如果这部分表现不佳,我们可以调整提示词,微调模型设置(如温度等),完全替换模型,或针对专业知识进行微调。我们还可以使用思维链(CoT)风格的循环强制其"推理",检查自我一致性,等等。
对于这部分,RAGAS 凭借其指标非常有用:答案相关性、忠实度和噪声敏感度。
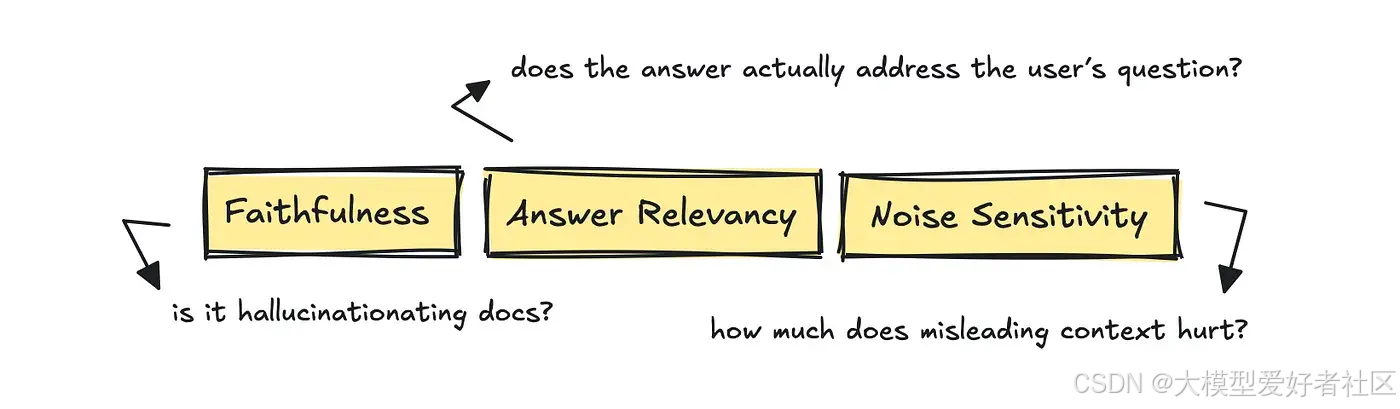
这些指标评估答案是否真正解决了用户的问题,答案中的所有主张是否都有检索到的文档支持,以及少量无关上下文是否会使模型偏离方向。
如果我们看看 RAGAS,他们可能对第一个指标的做法是要求 LLM"从 0 到 1 评分,这个答案在多大程度上直接回答了问题",并提供问题、答案和检索到的上下文。这会返回一个 0-1 的原始分数,可用于计算平均值。
因此,为了进行评估,我们将系统分为两部分,尽管你可以使用依赖 IR 指标的方法,也可以使用依赖 LLM 评分的无参考方法。
我们需要讨论的最后一件事是,智能体如何扩展了我们现在需要跟踪的指标集,超出了我们已经涵盖的范围。
智能体
对于智能体,我们不仅关注输出、对话和上下文。
现在我们也在评估它如何"运作":它能否完成任务或工作流程,执行效率如何,以及在恰当的时机调用正确的工具。
不同的框架会以不同的方式调用这些指标,但本质上,您需要跟踪的两个最重要的指标是任务完成率和工具正确性。
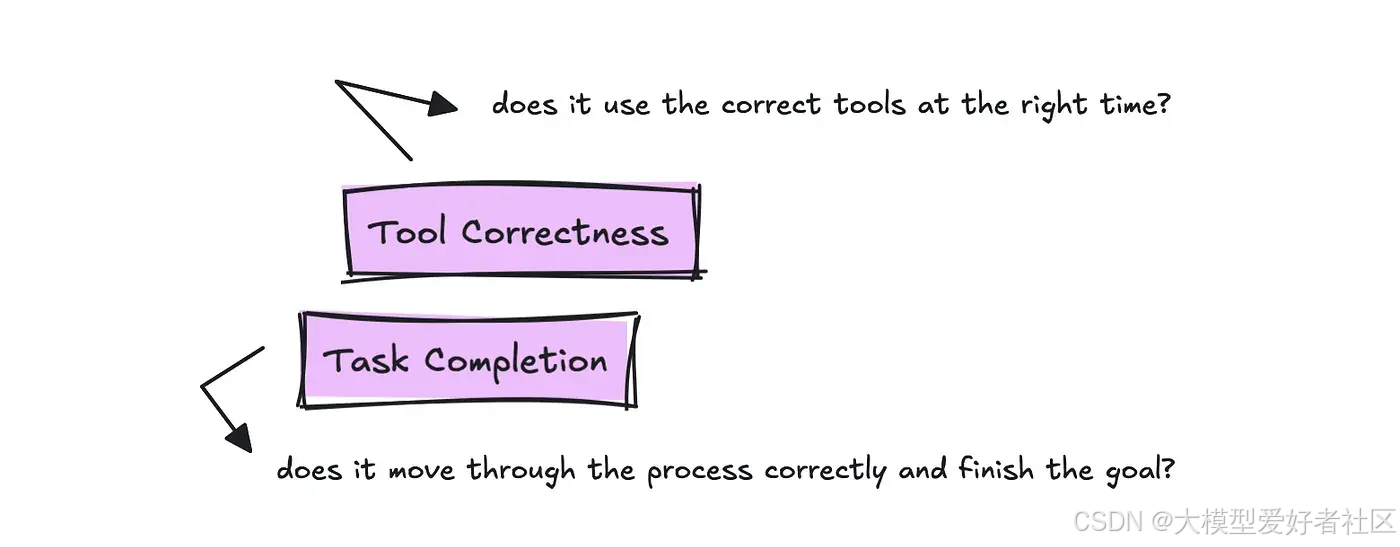
为了跟踪工具使用情况,我们希望了解是否为用户的查询使用了正确的工具。
我们确实需要某种内置真实黄金标准的测试脚本来测试每次运行,但你可以编写一次,然后在每次修改时重复使用它。
对于任务完成度,评估需要阅读整个轨迹和目标,并返回一个 0 到 1 之间的数值及理由。这应衡量智能体完成任务的有效性。
对于智能体,您仍需测试我们已经涵盖的其他内容,具体取决于您的应用程序。
我必须指出:即使有相当多已定义的可用指标,您的用例也会有所不同,因此值得了解常见的指标,但不要假设它们是跟踪您的应用程序的最佳指标。
接下来,让我们来了解一下目前可以帮助你的流行框架概况。
帮助你的框架
有很多框架可以帮助你进行评估,但我想介绍几个流行的框架:RAGAS、DeepEval、OpenAI 和 MLFlow 的 Evals,并分析它们各自的优势以及何时使用哪个。
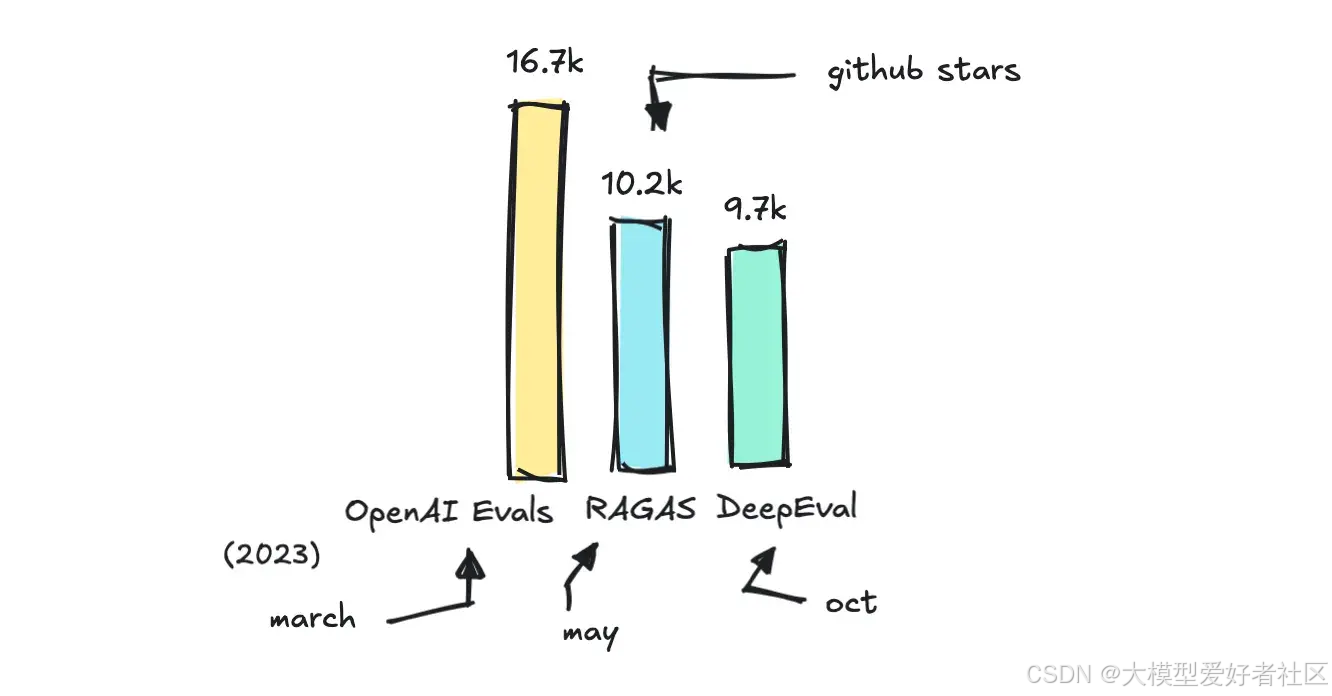
您可以在本仓库中找到我整理的不同评估框架的完整列表。
您也可以使用相当多的特定框架评估系统,例如 LlamaIndex,尤其是在快速原型设计方面。
OpenAI 和 MLFlow 的 Evals 是附加组件而非独立框架,而 RAGAS 最初主要是作为评估 RAG 应用的度量库构建的(尽管他们也提供其他度量)。
DeepEval 可能是所有评估库中最全面的一个。
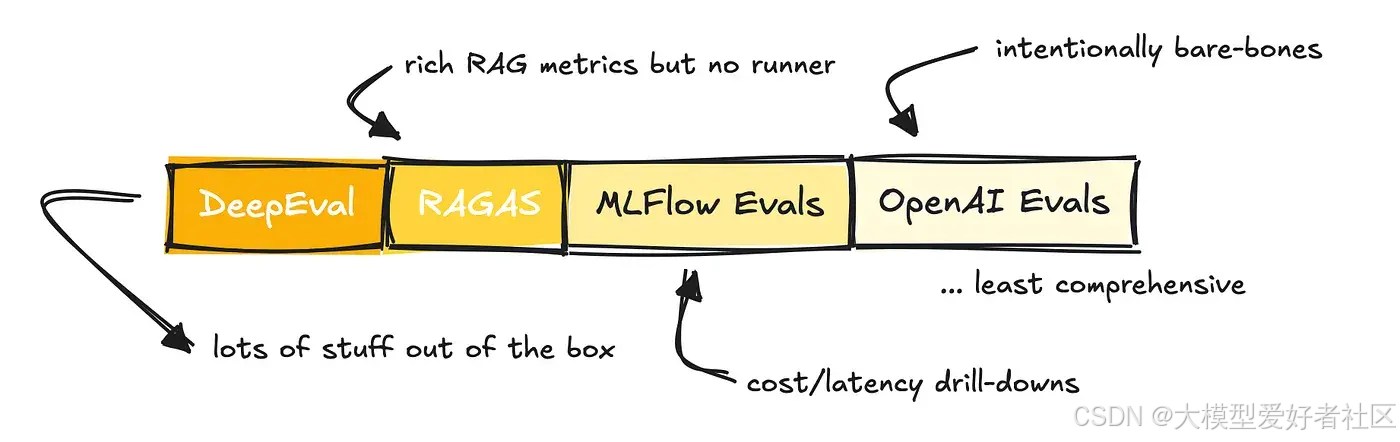
然而,需要提及的是,它们都提供了在您自己的数据集上运行评估的能力,以某种方式支持多轮对话、RAG 和智能体,支持 LLM 作为评判者,允许设置自定义指标,并且与 CI(持续集成)兼容。
如前所述,它们的区别在于全面性。
MLFlow 最初是为评估传统机器学习流程而构建的,因此它们为基于 LLM 的应用提供的指标数量较少。OpenAI 是一个非常轻量级的解决方案,它期望您自己设置指标,尽管他们提供了一个示例库来帮助您入门。
RAGAS 提供了相当多的指标,并且与 LangChain 集成,因此您可以轻松运行它们。
DeepEval 提供了许多开箱即用的功能,包括 RAGAS 指标。
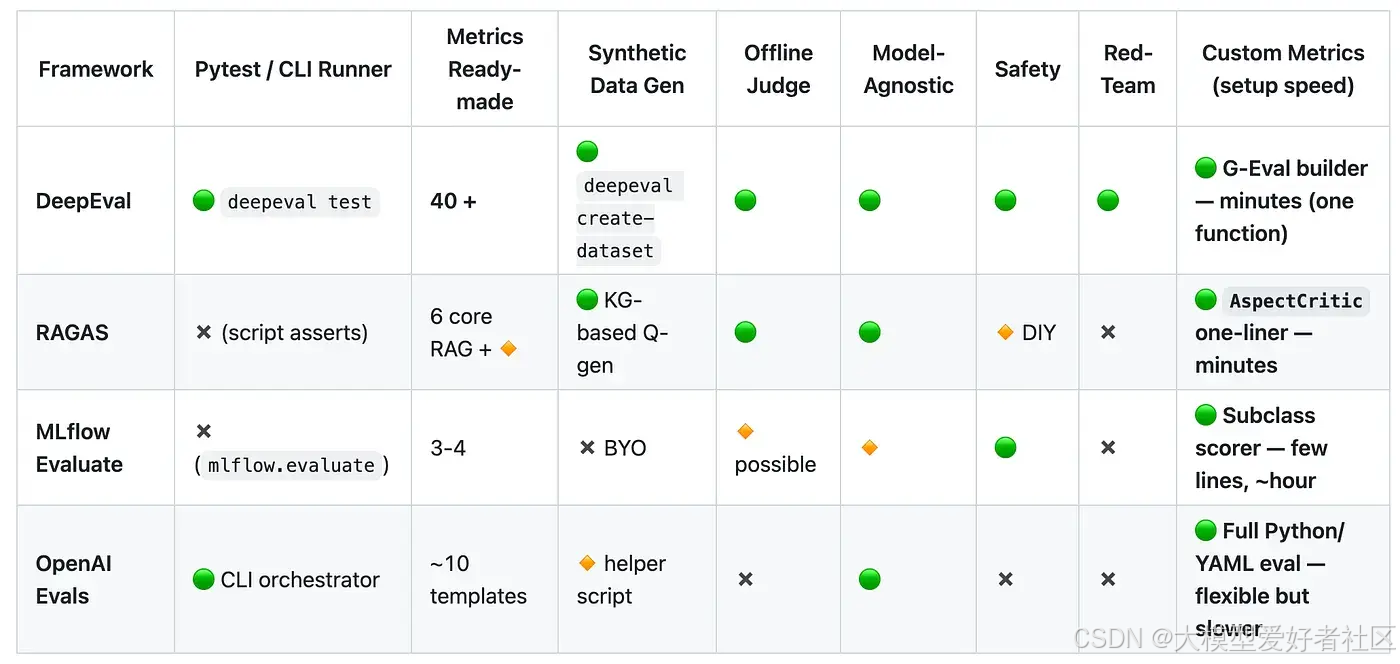
您可以在 GitHub 仓库中查看上表的代码。
如果我们审视所提供的指标,就能了解到这些解决方案的广泛程度。
值得注意的是,提供指标的人在命名上并不总是遵循标准。它们可能指的是同一事物,但称呼却不同。
例如,一个系统中的忠实度可能等同于另一个系统中的基础性。答案相关性可能等同于响应相关性,以此类推。
这给评估系统带来了大量不必要的困惑和复杂性。
尽管如此,DeepEval 凭借其超过 40 种可用指标脱颖而出,并提供了一个名为 G-Eval 的框架,该框架能帮助您快速设置自定义指标,从而成为从想法到可运行指标的最快途径。
OpenAI 的 Evals 框架更适合需要定制逻辑的场景,而不仅仅是需要快速判断时。
根据 DeepEval 团队的说法,自定义指标是开发者设置最多的内容,因此不要纠结于谁提供了什么指标。您的用例将是独特的,评估方式也将如此。
那么,在什么情况下应该使用哪一个呢?
当您需要为 RAG 管道使用专业指标且设置最少时,请选择 RAGAS。当您想要一个完整、即用型评估套件时,请选择 DeepEval。
如果您已经投入了 MLFlow 或者更喜欢内置的跟踪和 UI 功能,那么 MLFlow 是一个不错的选择。OpenAI 的 Evals 框架最为基础,因此如果您已经使用 OpenAI 基础设施并希望获得灵活性,这是最佳选择。
最后,DeepEval 还通过其 DeepTeam 框架提供红队服务,该框架能够自动化地对 LLM 系统进行对抗性测试。市面上也有其他框架可以做到这一点,尽管可能没有这么全面。
我将来必须对 LLM 系统的对抗性测试和提示注入做一些研究。这是一个有趣的话题。
一些笔记
数据集业务是一项利润丰厚的业务,因此我们现在能够使用其他 LLMs 来标注数据或评分测试,这真是个好消息。
然而,LLM 评判并非万能,您设置的评估可能会有些不稳定,就像您构建的任何其他 LLM 应用一样。根据互联网上的信息,大多数团队和公司每隔几周就会进行人工抽样审核,以保持真实性。
为你的应用设置的指标很可能是定制的,因此,尽管我已经让你了解了很多指标,但你很可能会自己构建一些东西。
了解标准做法总是好的。
希望这无论如何都具有教育意义。
如果你喜欢这篇文章,一定要阅读我关于智能体框架或构建高级 RAG 智能体的其他文章。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)