大模型工具调用完全指南:Function Calling原理详解+代码实战,建议收藏
文章详细介绍了LLM的Function Calling功能,包括原理、执行流程和三种调用策略。通过代码示例展示了DeepSeek API和LangChain框架中的工具实现方法,重点讲解了Agent Tooling概念及提示链、路由、并行化等Workflow范式,帮助开发者构建高效的大模型应用。
LLM Function Calling
2023 年 6 月,OpenAI 推出 Function Calling API 功能,至今为止 Function Calling 已经是 LLM Provider 的标配。可以调用外部工具,成为了智能体的关键特征。
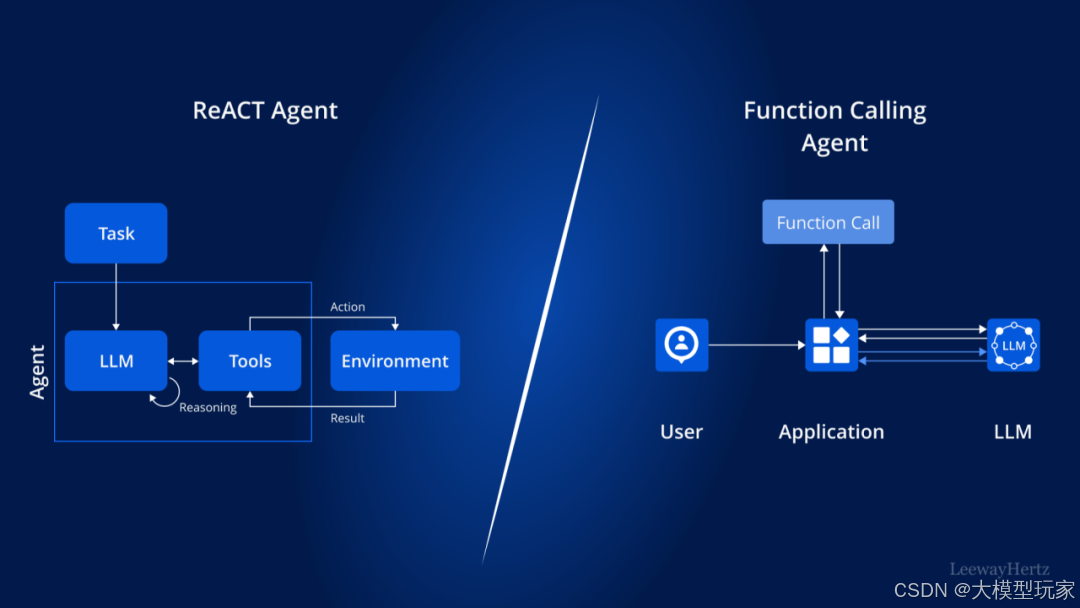
Function Calling 是 ReAct Tools Routing 的具体实现。使得 LLM App 可以定义自己的 Tools list,然后让 LLM 认识这些 Tools list,继而 LLM 可以根据 User Query 找到合适的 Tool 用于后续执行。但 ReAct 和 Function Calling 有着本质的区别,如下图所示。
执行流程
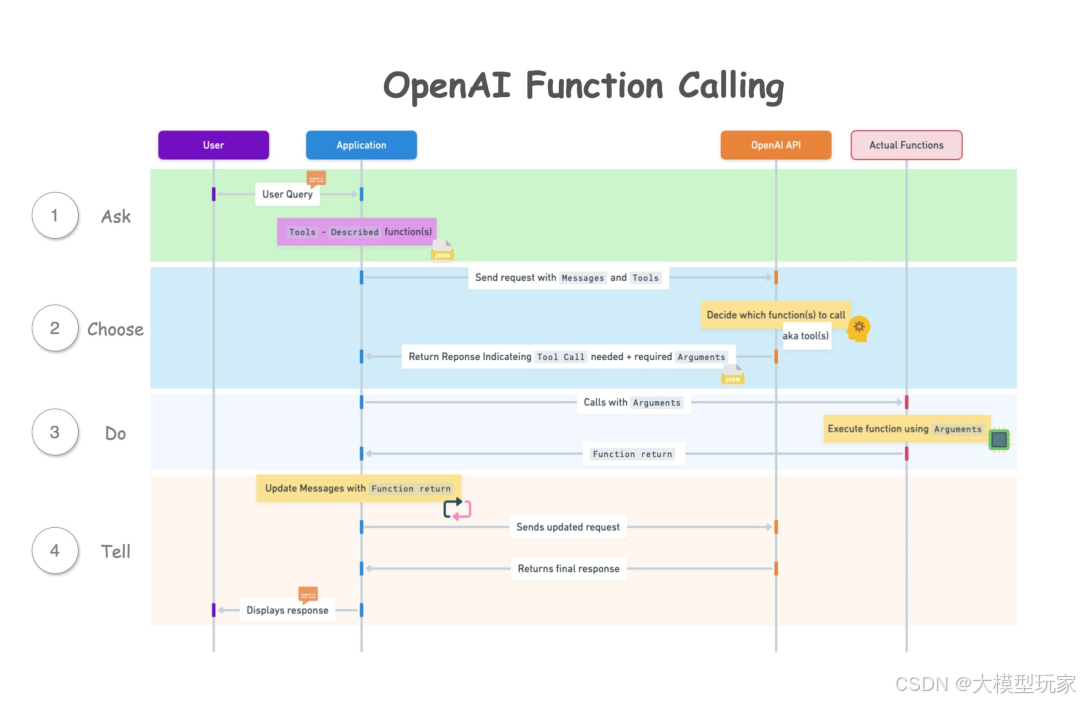
Function Calling API 的执行流程如下所示:
- app 维护 Message Context 发出 User Query 以及 app 所提供的 Tools。
- LLM 返回处理 Query 所需要用到的 Tools 和 Arguments。
- app 执行 Tools 或获得 Results。
- app 将 Tool Results 注入到 Message Context 中再次发送给 LLM。
- LLM 根据 User Query 和 Tool Results 最终返回 Response 给 app。
代码示例
这里使用的是 DeepSeek Function Calling API,文档见:https://api-docs.deepseek.com/zh-cn/guides/function_calling
import os
from dotenv import load_dotenv
load_dotenv(override=True)
import json
from openai import OpenAI
# 定义 tools 工具列表。
# 每个 tool 中都具有 function 类型的字典。
# 每个 function 中都有函数具体的 name、description 和 parmameters。
# name 和 description 非常重要,是 LLM 理解 function 作用的关键。
# parameters 定义了 function 能够接收的参数列表,包括 type 类型、properties 属性和 required 必选参数列表。
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of a location, the user should supply a location first.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"]
},
}
},
{
"type": "function",
"function": {
"name": "get_pizza_info",
"description": "Get name and price of a pizza of the restaurant",
"parameters": {
"type": "object",
"properties": {
"pizza_name": {
"type": "string",
"description": "The name of the pizza, e.g. Salami",
}
},
"required": ["pizza_name"]
},
}
},
]
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
client = OpenAI(api_key=DEEPSEEK_API_KEY, base_url="https://api.deepseek.com")
def send_messages(messages):
response = client.chat.completions.create(
model="deepseek-reasoner", # function calling 场景中建议使用推理型 LLM。
messages=messages,
tools=tools # 传递 tools 列表,表示使用 function calling API。
)
return response.choices[0].message
def get_pizza_info(pizza_name: str):
pizza_info = {
"name": pizza_name,
"price": "10.99",
}
return json.dumps(pizza_info)
# 一、使用天气查询 tool。
# 1. app 询问问题
messages = [{"role": "user", "content": "What's the weather in Beijing, China?"}]
message1 = send_messages(messages)
print(f"User>\t {message1.content}")
# 2. LLM 返回解答问题所需要使用的 tool
tool = message1.tool_calls[0]
# 3. app 调用 LLM 返回的 tool 并获得 result 结果
tool_result = "24℃" # mock get_weather function
# 4. 将 tool result 注入 context,并且要求与 tool id 关联起来
messages.append(message1)
messages.append({"role": "tool", "tool_call_id": tool.id, "content": tool_result})
# 5. 由 LLM 最终生成 resp
message2 = send_messages(messages)
print(f"Model>\t {message2.content}")
# 二、使用价格查询 tool。
# 1. app 询问问题
messages = [{"role": "user", "content": "How much does pizza salami cost?"}]
message3 = send_messages(messages)
print(f"User>\t {message3.content}")
# 2. LLM 返回解答问题所需要使用的 tool,包括 function name、arguments 等信息
tool = message3.tool_calls[0]
pizza_name = json.loads(tool.function.arguments).get("pizza_name")
# 3. app 调用 LLM 返回的 tool 并获得 result 结果
function_response = get_pizza_info(pizza_name=pizza_name)
# 4. 将 tool result 注入 context,并且要求与 tool id 关联起来
messages.append(message3)
messages.append({"role": "tool", "tool_call_id": tool.id, "content": function_response})
# 5. 由 LLM 最终生成 resp
message4 = send_messages(messages)
print(f"Model>\t {message4.content}")

tool_choice 参数
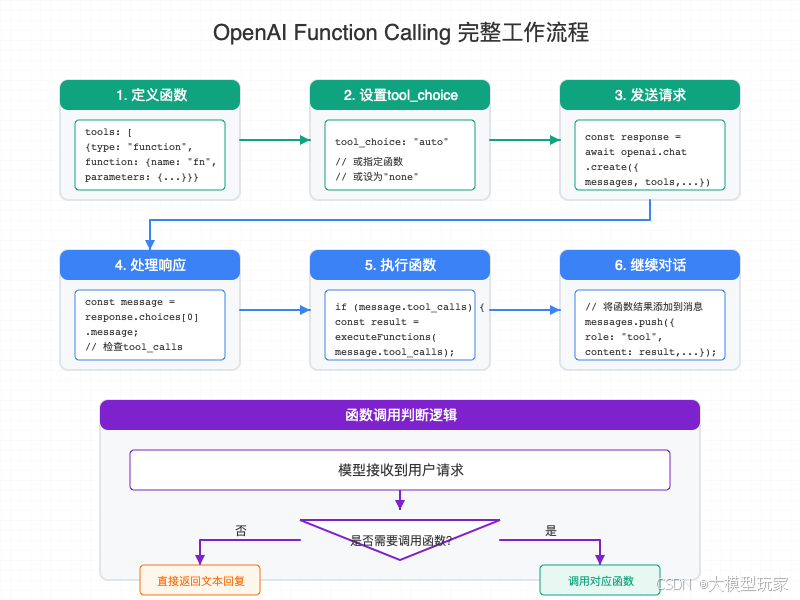
更细节的,还可以在调用 Function Calling API 的时候设置 tool_choice 参数,它指示了 LLM 选择 Tools 的策略。具有以下 3 中策略。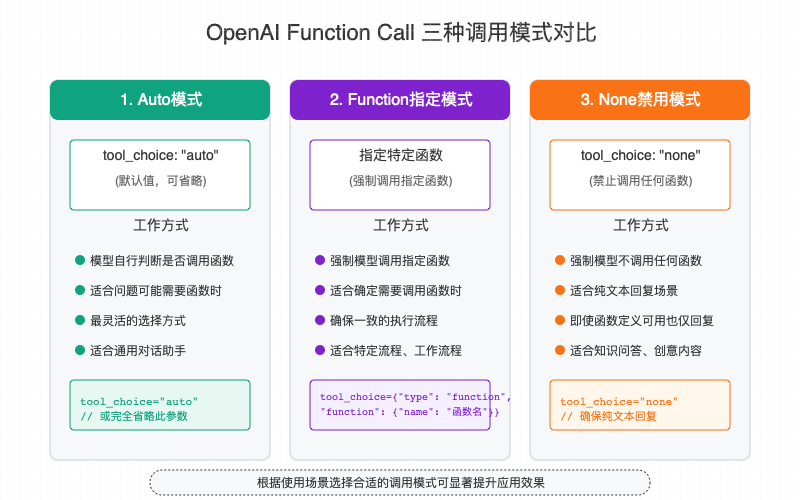
- auto 自动模式(默认):模型会根据用户的输入内容自行判断是否需要调用函数。这是最灵活的设置方式,适合通用型助手应用。
const response = await openai.chat.completions.create({
model: "gpt-4-turbo",
messages: [
{ role: "user", content: "今天北京的天气怎么样?" }
],
tools: [],
tool_choice: "auto"
});
- 强制指定函数模式:将tool_choice设置为一个包含函数名称的对象。这种模式会强制模型调用指定的函数,无论用户输入内容是什么。适用于特定功能的工作流程。
const response = await openai.chat.completions.create({
model: "gpt-4-turbo",
messages: [
{ role: "user", content: "我想了解天气情况" }
],
tools: [],
tool_choice: {
type: "function",
function: { name: "get_weather" }
}
});
- none 禁用模式:模型会被禁止调用任何函数,只生成文本回复。即使您在请求中定义了函数,模型也不会调用它们。适用于纯知识问答。
const response = await openai.chat.completions.create({
model: "gpt-4-turbo",
messages: [
{ role: "user", content: "今天北京的天气怎么样?" }
],
tools: [],
tool_choice: "none"
});
应用建议
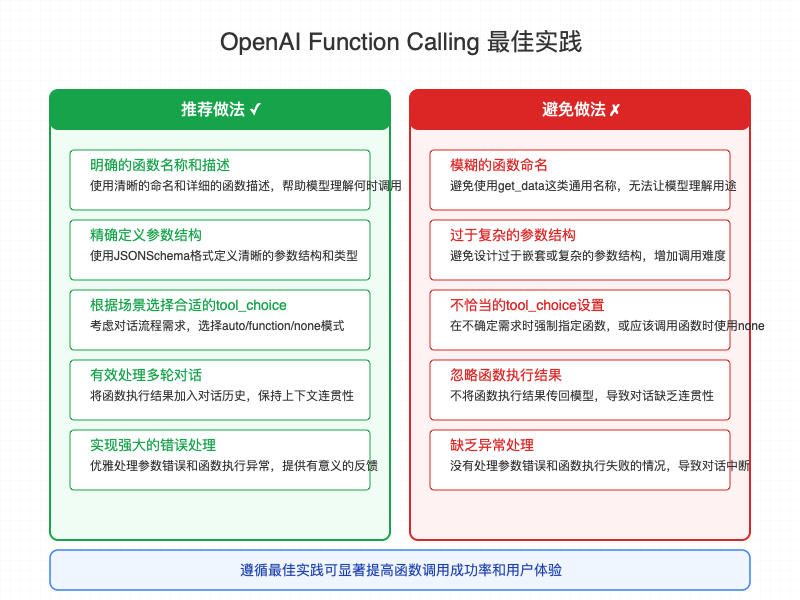
-
函数设计原则:
-
明确的 func_name:使用描述性强的函数名,如 get_weather 比 get_data 更清晰。
-
详细的 description:为每个函数提供准确的描述,帮助模型理解何时应该调用它。
-
结构化的参数:使用J SON Schema 定义清晰的参数结构和类型。
-
合理的必填项:只将真正必要的参数标记为 required。
-
错误处理机制:
-
参数验证:在实际函数中验证参数,处理缺失或不符合要求的情况。
-
优雅降级:当函数执行失败时,提供有意义的错误信息。
-
重试机制:对于网络请求等不稳定操作,实现适当的重试逻辑。
-
多轮对话优化设计:
-
保存函数结果:将函数结果作为消息保存在对话历史中。
-
tool_id 关联:让 LLM 理解 Tools 的请求和执行结果。
-
上下文管理:有效管理对话历史长度,保留关键信息。
-
状态跟踪:跟踪对话状态,避免重复函数调用。
LangChain Function Calling
使用 bulid-in tools
LangChain 几乎是最早支持 OpenAI Function Calling 的框架,并内置了非常多的实用工具,开发者可以快速调用这些工具完成更加复杂工作流的开发。
https://python.langchain.com/docs/integrations/tools/
在这里插入图片描述
使用 build-in tools 非常简单,只需要安装包并引用即可。
- 安装:
$ uv pip install langchain-experimental
- tools 的具体示例可以查看官方文档,以 Python REPL Tool 为例:https://python.langchain.com/docs/integrations/tools/python/
import os
import time
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.getenv("DEEPSEEK_API_KEY")
from langchain.chat_models import init_chat_model
from langchain_core.tools import Tool
from langchain_experimental.utilities import PythonREPL
python_repl = PythonREPL()
tool = Tool(
name="python_repl",
description="A Python shell. Use this to execute python commands. Input should be a valid python command. If you want to see the output of a value, you should print it out with `print(...)`.",
func=python_repl.run,
)
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
llm_with_tools = model.bind_tools([tool])
response = llm_with_tools.invoke("帮我用 python 计算 1+1 等于几?")
print(response)
执行结果:
> response.content
'我来帮你用Python计算1+1等于几。'
> response.additional_kwargs
{'tool_calls': [{'id': 'call_00_4cLmKlfjSAPljlGwS5Rp5Hm2',
'function': {'arguments': '{"__arg1": "print(1 + 1)"}',
'name': 'python_repl'},
'type': 'function',
'index': 0}],
'refusal': None}
可见 LLM 返回的 AIMessage response 中的 additional_kwargs 记录了 LLM 返回的需要执行的 fun_name 和 arguments。后续 app 只需要执行即可。
使用自定义 tools
更多的场景中,我们需要自定义大量的 Tools。LangChain 也提供了简洁的 @tool 语法糖来定义一个 Tools,极大地简化开发的复杂度。下面以自定义的从 OpenWeather API 获取实时天气数据工具为例。https://home.openweathermap.org/api_keys
首先测试自定义 tool 是可用的,例如:
import os
import requests
import json
from dotenv import load_dotenv
load_dotenv()
def get_weather(local):
"""
查询即时天气函数
:param local: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则local参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息。
"""
# Step1. 构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step2. 设置查询参数
params = {
"q": local,
"appid": os.getenv("OPENWEATHER_API_KEY"), # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step3. 发送 GET 请求
response = requests.get(url, params=params)
# Step4. 解析响应
data = response.json()
return json.dumps(data)
get_weather("Beijing")
执行输出:
'{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 501, "main": "Rain", "description": "\\u4e2d\\u96e8", "icon": "10d"}], "base": "stations", "main": {"temp": 11.95, "feels_like": 11.42, "temp_min": 11.95, "temp_max": 11.95, "pressure": 1019, "humidity": 85, "sea_level": 1019, "grnd_level": 1014}, "visibility": 10000, "wind": {"speed": 1.58, "deg": 172, "gust": 1.57}, "rain": {"1h": 1.15}, "clouds": {"all": 100}, "dt": 1760086305, "sys": {"country": "CN", "sunrise": 1760048346, "sunset": 1760089412}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}'
然后将自定义 tool 集成到 LangChain 中。
import os
import requests
import json
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.getenv("DEEPSEEK_API_KEY")
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.output_parsers.openai_tools import JsonOutputKeyToolsParser
# 自定义工具
@tool
def get_weather(local):
"""
查询即时天气函数
:param local: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则local参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息。
"""
# Step1. 构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step2. 设置查询参数
params = {
"q": local,
"appid": os.getenv("OPENWEATHER_API_KEY"), # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step3. 发送 GET 请求
response = requests.get(url, params=params)
# Step4. 解析响应
data = response.json()
return json.dumps(data)
# 将自定义 tools 和 llm 进行绑定
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
tools = [get_weather]
llm_with_tools = model.bind_tools(tools)
# 创建第一条 chain,用于从 OpenWeather API 获取 local 的事实天气数据,最终以 JSON 格式输出
parser = JsonOutputKeyToolsParser(key_name=get_weather.name, first_tool_only=True)
get_weather_chain = llm_with_tools | parser | get_weather
# 创建第二条 chain,用于将 JSON 输出转换为自然语言输出。
output_prompt = PromptTemplate.from_template(
"""你将收到一段 JSON 格式的天气数据,请用简洁自然的方式将其转述给用户。
以下是天气 JSON 数据:
'''json
{weather_json}
'''
请将其转换为中文天气描述,例如:
“北京当前天气晴,气温为 23°C,湿度 58%,风速 2.1 米/秒。”
只返回一句话描述,不要其他说明或解释。"""
)
output_chain = output_prompt | model | StrOutputParser()
# 将 chain1 和 chain2 连接起来,最终完成 tools 执行和输出。
full_chain = get_weather_chain | output_chain
response = full_chain.invoke("请问北京今天的天气如何?")
print(response)
执行输出:
北京当前有中雨,气温约12°C,体感温度11°C,湿度85%,风速1.58米/秒。
Agent Tooling = ToolCalling Agent + AgentExecutor
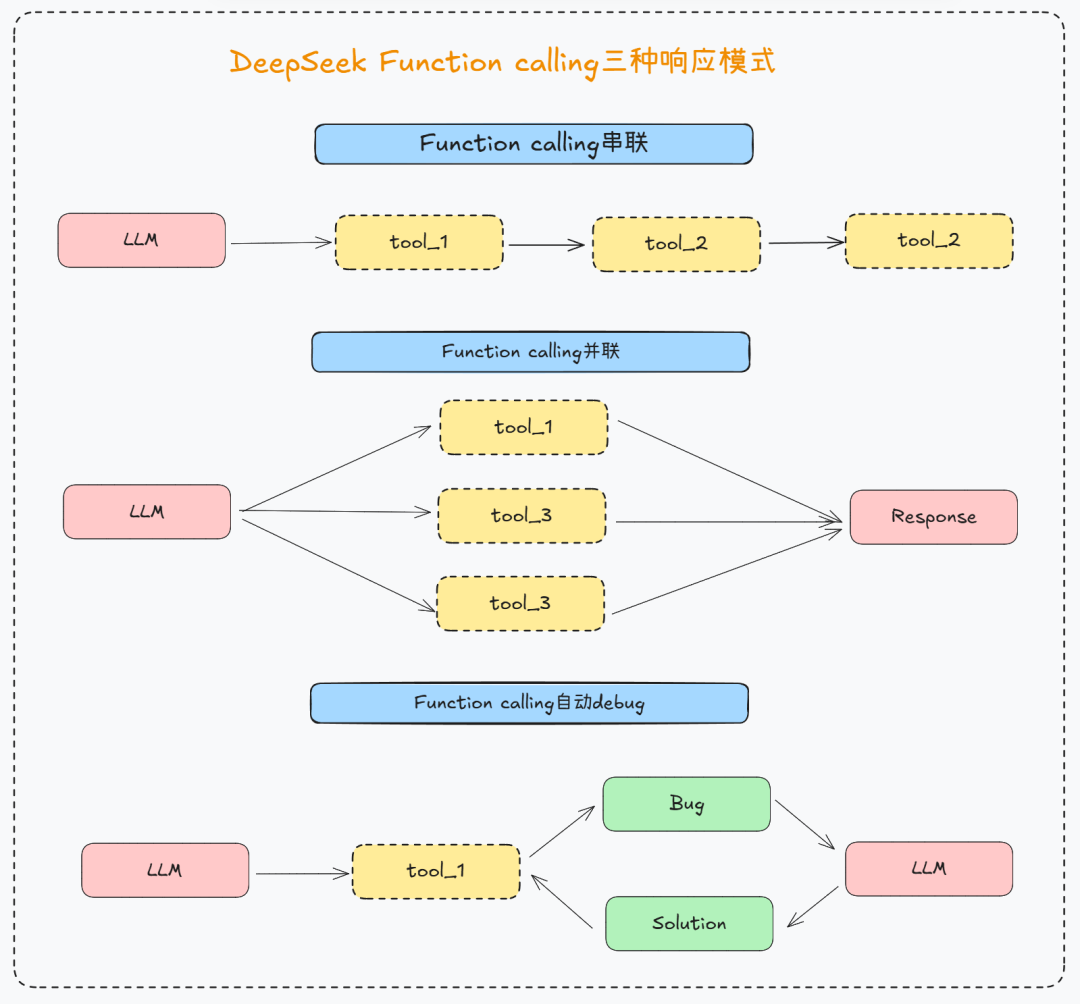
上文中我们采用了将 tools 和 model 进行 binding 的方式来实现 Function Calling,但从代码可以看出,之间需要开发者处理非常复杂 Tool Calling 和 Message Updating 逻辑,显然不便于开发者快速构建一个高效的智能体应用。尤其在 LLM Provider 支持了越来越多种类的 Function Calling 特性的情况下,下图以 DeepSeek 为例,其支持 3 种典型的 Function Calling 推理模式。
- Function Calling 串联
- Function Calling 并联
- Function Calling 自动 debug
对此,LangChain 抽象了高级别的 Agent Tooling 概念,由 ToolCalling Agent 和 Agent Executor 组成:
- ToolCalling Agent:通过 create_tool_calling_agent 接口创建一个专用于 ToolCalling 工具调用的 Agent 对象(工具调用代理)。
- AgentExecutor:用于自动化地完成 Agent 的负责个 ToolCalling 执行流程并返回最终结果。
Agent Tooling 使得开发者无需再编写繁杂的 Tool Calling 和 Message Updating 逻辑,这些工作都被包装到几行代码中。如下代码示例:
import os
import requests
import json
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.getenv("DEEPSEEK_API_KEY")
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
from langchain.agents import create_tool_calling_agent
from langchain_core.prompts import ChatPromptTemplate
from langchain.agents import AgentExecutor
# 自定义工具
@tool
def get_weather(local):
"""
查询即时天气函数
:param local: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\
注意,中国的城市需要用对应城市的英文名称代替,例如如果需要查询北京市天气,则local参数需要输入'Beijing';
:return:OpenWeather API查询即时天气的结果,具体URL请求地址为:https://api.openweathermap.org/data/2.5/weather\
返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息。
"""
# Step1. 构建请求
url = "https://api.openweathermap.org/data/2.5/weather"
# Step2. 设置查询参数
params = {
"q": local,
"appid": os.getenv("OPENWEATHER_API_KEY"), # 输入API key
"units": "metric", # 使用摄氏度而不是华氏度
"lang":"zh_cn" # 输出语言为简体中文
}
# Step3. 发送 GET 请求
response = requests.get(url, params=params)
# Step4. 解析响应
data = response.json()
return json.dumps(data)
# 创建 ToolCalling Agent 对象
prompt = ChatPromptTemplate.from_messages([
("system", "你是天气助手,请根据用户的问题,给出相应的天气信息"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"), # prompt template 要注意添加 placeholder 占位符,AgentExecutor 会自动完成 Message Updating。
])
model = init_chat_model(model="deepseek-chat", model_provider="deepseek")
tools = [get_weather]
agent = create_tool_calling_agent(model, tools, prompt)
# 使用 AgentExecutor 执行这个 Agent
# Tool Callig 和 Message Updating 由 AgentExecutor 自动完成。
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
response = agent_executor.invoke({"input": "请问今天北京的天气怎么样?"})
# 直接返回最终 Response,无需编写 OutParser 代码
print(response)
执行输出:
> Entering new AgentExecutor chain...
Invoking: `get_weather` with `{'local': 'Beijing'}`
responded: 我来帮您查询今天北京的天气情况。
{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 502, "main": "Rain", "description": "\u5927\u96e8", "icon": "10n"}], "base": "stations", "main": {"temp": 11.25, "feels_like": 10.81, "temp_min": 11.25, "temp_max": 11.25, "pressure": 1020, "humidity": 91, "sea_level": 1020, "grnd_level": 1015}, "visibility": 7591, "wind": {"speed": 0.57, "deg": 105, "gust": 0.87}, "rain": {"1h": 5.91}, "clouds": {"all": 100}, "dt": 1760099556, "sys": {"country": "CN", "sunrise": 1760048346, "sunset": 1760089412}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}根据查询结果,今天北京的天气情况如下:
**天气状况**:大雨
**当前温度**:11.25°C
**体感温度**:10.81°C
**湿度**:91%(非常潮湿)
**气压**:1020 hPa
**风速**:0.57 m/s(微风)
**能见度**:7591米
**降雨量**:过去1小时降雨量5.91毫米
**温馨提示**:
- 今天北京有大雨,建议您外出时携带雨具
- 温度较低且湿度很高,体感温度只有10.81°C,请注意保暖
- 能见度一般,雨天出行请注意交通安全
> Finished chain.
{'input': '请问今天北京的天气怎么样?', 'output': '根据查询结果,今天北京的天气情况如下:\n\n**天气状况**:大雨\n**当前温度**:11.25°C\n**体感温度**:10.81°C\n**湿度**:91%(非常潮湿)\n**气压**:1020 hPa\n**风速**:0.57 m/s(微风)\n**能见度**:7591米\n**降雨量**:过去1小时降雨量5.91毫米\n\n**温馨提示**:\n- 今天北京有大雨,建议您外出时携带雨具\n- 温度较低且湿度很高,体感温度只有10.81°C,请注意保暖\n- 能见度一般,雨天出行请注意交通安全'}
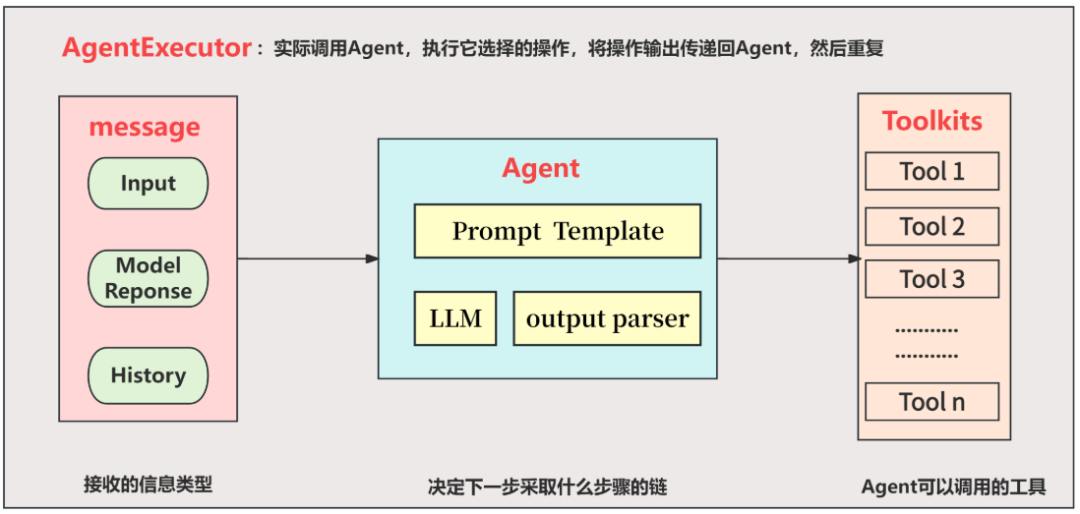
AgentExecutor 是 Agent Tooling 的 “大脑”,支持自动化地完成 Message -> Agent -> Toolkits 这 3 方面的内容。更详细的,其会自动化完成包括:拆解子任务,然后根据这些子任务在工具库中找到相应的工具,提取工具名称及所需参数,然后自动执行这些工具,得到执行结果,将执行结果更新到 Message,再请求 LLM 并最终返回。
- 自动化处理 Message Updating,包括:User input、Model Response、Conversation History。
- 自动化处理 Tool Calling,包括:拆解子任务、调用 Tools、处理 Tool Results 并处理最终输出结果。
Workflow 基本范式
除了简化代码编写,LangChain Agent Tooling 还实现了一些 Workflow 范式。常见的 Workflow 范式包括以下几类,指导开发者根据不同的应用场景编写合理的代码逻辑。
提示链(Prompt chaining)
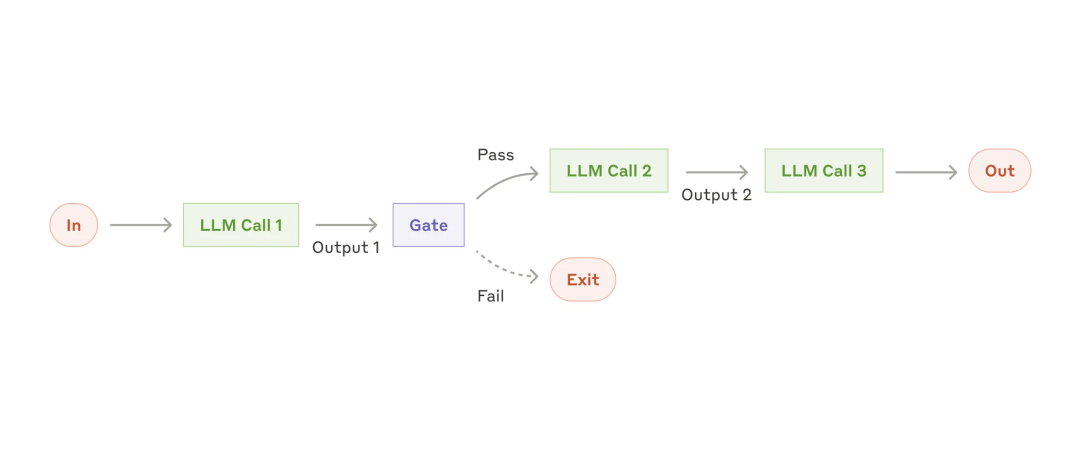
提示链(Prompt chaining)范式:
- 将任务分解为一系列子任务并顺序执行,前一个 LLM call 的 output 作为后一个 LLM call 的 input。
- 可以在中间任意 step 添加 Checkpoint 检查点,如图中的 Gate。检查以确保处理过程仍在正轨上。
- 将一个大任务,拆解为多个子任务,每个子任务分别与 LLM 交互,具有准确率更高、延迟更低的优势。
应用场景:适用于能干净地将任务分解为固定子任务的场景。 应用案例:生成营销文案。首先编写文档大纲,确保大纲符合某些标准,然后根据大纲编写文档,最后将其翻译成不同的语言。
路由(Routing)
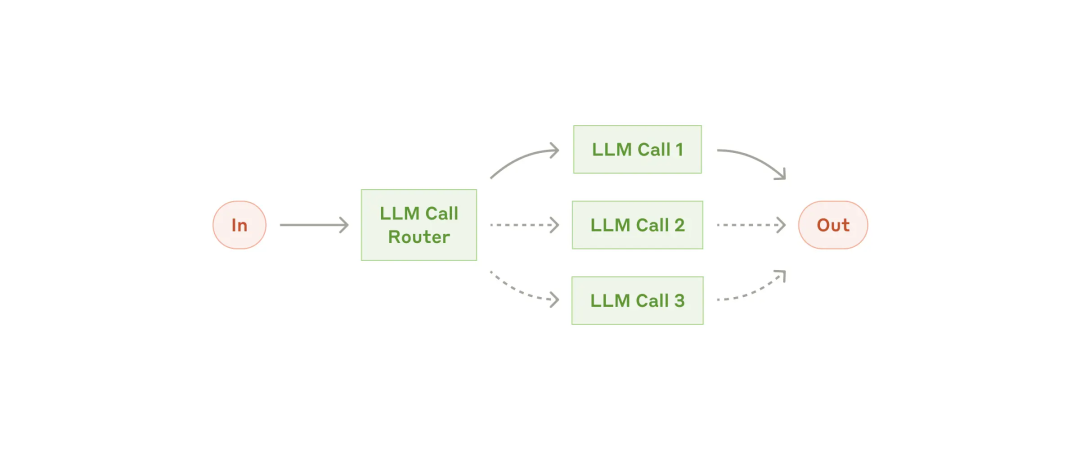
路由(Routing)范式:
- 通过 LLM Call Router 对 Input 进行分类,并将其转发到专门的后续任务(specialized followup task)。
- 还可以将不同的问题转发给不同的 LLM 进行处理,例如将简单问题路由到小模型处理,将复杂问题路由到更强大的模型处理。以优化成本和速度。
应用场景:适用于具有不同类别的复杂任务,前提是能够准确分类。同理,讲一个负责的任务这些类别分开处理时,都能得到更好的效果。 应用案例:智能客服。将不同类型的用户问题(一般问题、请求退款、技术支持)转发到不同的下游任务处理,具有更专注和模块化的 Model、Prompts 和 Tools。
并行化(Parallelization)
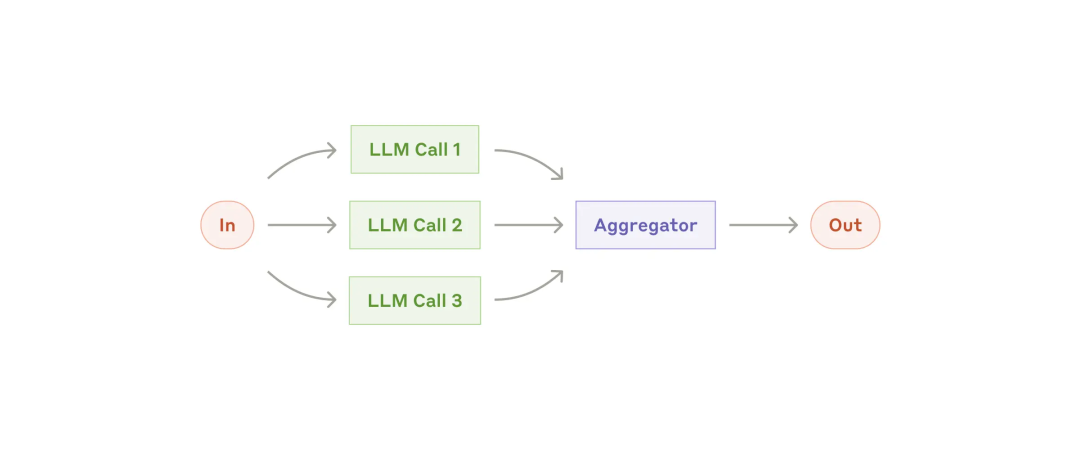
在这里插入图片描述
并行化(Parallelization)范式:多个任务同时进行,然后对输出进行聚合处理。
应用场景:
- 性能场景:类似 MapReduce,将任务分解为独立的子任务并行运行,最后对输出进行聚合,提升效率。
- 输出验证场景:同时生成多个相同问题的输出,然后进行 Voting(投票)或 Validate(验证),交叉验证输出的可靠性。
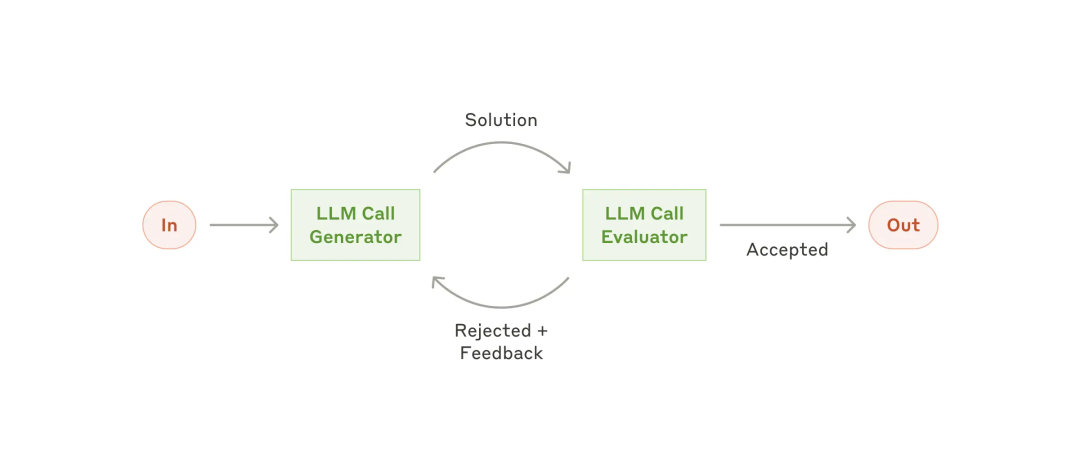
评估者-优化者(Evaluator-optimizer)
在这里插入图片描述
评估者-优化者(Evaluator-optimizer)范式:一个 LLM call 负责生成响应,而另一个 LLM call 负责评估和反馈,形成一个闭环。
应用场景:适用于有明确的评估标准,并且迭代式改进确实有效的场景。 应用案例:
- 文学翻译。承担翻译任务的 LLM 可能没有捕捉到细微差别,但承担评估任务的 LLM 可以提供有用的批评。
- 深度研究。需要多轮搜索和分析以收集全面信息,评估者决定是否需要进一步搜索。
并行化调用代码示例
修改上述例子的 User Query,要求查询 2 个城市的天气。
response = agent_executor.invoke({"input": "请问今天北京和杭州的天气怎么样,哪个城市更热?"})
print(response)
此时 AgentExecutor 会自动启用并行化 Workflow 范式。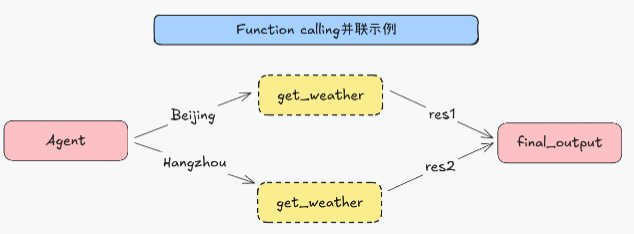
执行结果:
> Entering new AgentExecutor chain...
Invoking: `get_weather` with `{'local': 'Beijing'}`
responded: 我来帮您查询北京和杭州的天气情况,然后比较哪个城市更热。
{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 501, "main": "Rain", "description": "\u4e2d\u96e8", "icon": "10n"}], "base": "stations", "main": {"temp": 11.26, "feels_like": 10.77, "temp_min": 11.26, "temp_max": 11.26, "pressure": 1019, "humidity": 89, "sea_level": 1019, "grnd_level": 1014}, "visibility": 10000, "wind": {"speed": 0.75, "deg": 155, "gust": 0.61}, "rain": {"1h": 1.41}, "clouds": {"all": 100}, "dt": 1760112094, "sys": {"country": "CN", "sunrise": 1760134807, "sunset": 1760175719}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
Invoking: `get_weather` with `{'local': 'Hangzhou'}`
responded: 我来帮您查询北京和杭州的天气情况,然后比较哪个城市更热。
{"coord": {"lon": 120.1614, "lat": 30.2937}, "weather": [{"id": 800, "main": "Clear", "description": "\u6674", "icon": "01n"}], "base": "stations", "main": {"temp": 25.73, "feels_like": 26.6, "temp_min": 25.73, "temp_max": 25.73, "pressure": 1013, "humidity": 86, "sea_level": 1013, "grnd_level": 1011}, "visibility": 10000, "wind": {"speed": 1.31, "deg": 357, "gust": 1.77}, "clouds": {"all": 0}, "dt": 1760111956, "sys": {"country": "CN", "sunrise": 1760133508, "sunset": 1760175212}, "timezone": 28800, "id": 1808926, "name": "Hangzhou", "cod": 200}根据查询结果,我来为您对比两个城市的天气情况:
**北京天气:**
- 温度:11.26°C
- 体感温度:10.77°C
- 天气状况:中雨
- 湿度:89%
- 气压:1019 hPa
**杭州天气:**
- 温度:25.73°C
- 体感温度:26.60°C
- 天气状况:晴天
- 湿度:86%
- 气压:1013 hPa
**温度对比:**
杭州(25.73°C)明显比北京(11.26°C)更热,温差达到14.47°C。杭州的温度更温暖舒适,而北京则相对较冷且有降雨。
**结论:** 杭州比北京更热。
> Finished chain.
{'input': '请问今天北京和杭州的天气怎么样,哪个城市更热?', 'output': '根据查询结果,我来为您对比两个城市的天气情况:\n\n**北京天气:**\n- 温度:11.26°C\n- 体感温度:10.77°C\n- 天气状况:中雨\n- 湿度:89%\n- 气压:1019 hPa\n\n**杭州天气:**\n- 温度:25.73°C\n- 体感温度:26.60°C\n- 天气状况:晴天\n- 湿度:86%\n- 气压:1013 hPa\n\n**温度对比:**\n杭州(25.73°C)明显比北京(11.26°C)更热,温差达到14.47°C。杭州的温度更温暖舒适,而北京则相对较冷且有降雨。\n\n**结论:** 杭州比北京更热。'}
提示链条串行化调用代码示例
在上述示例的基础上再添加一个任务,要求把查询的结果写入文件。
@tool
def write_file(content):
"""
将指定内容写入本地文件。
:param content: 必要参数,字符串类型,用于表示需要写入文档的具体内容。
:return:是否成功写入
"""
return "已成功写入本地文件。"
tools = [get_weather, write_file]
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是天气助手,请根据用户的问题,给出相应的天气信息,如果用户需要将查询结果写入文件,请使用 write_file 工具。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
response = agent_executor.invoke({"input": "查一下北京和杭州现在的温度,并将结果写入本地的文件中。"})
print(response)
AgentExecutor 会自动添加一个 Tool Calling 到串行的任务链中。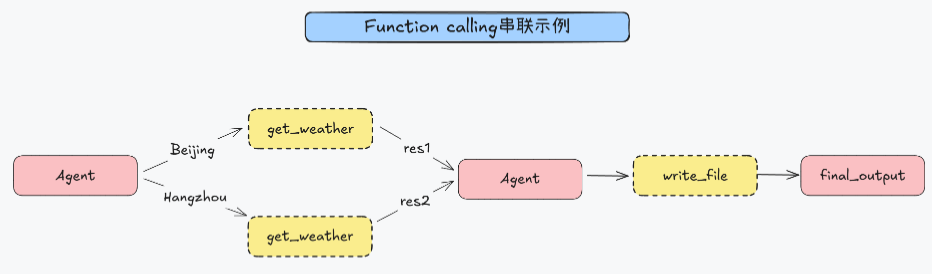
执行结果:
> Entering new AgentExecutor chain...
Invoking: `get_weather` with `{'local': 'Beijing'}`
{"coord": {"lon": 116.3972, "lat": 39.9075}, "weather": [{"id": 500, "main": "Rain", "description": "\u5c0f\u96e8", "icon": "10n"}], "base": "stations", "main": {"temp": 11.26, "feels_like": 10.77, "temp_min": 11.26, "temp_max": 11.26, "pressure": 1019, "humidity": 89, "sea_level": 1019, "grnd_level": 1014}, "visibility": 10000, "wind": {"speed": 0.75, "deg": 155, "gust": 0.61}, "rain": {"1h": 0.34}, "clouds": {"all": 100}, "dt": 1760112418, "sys": {"country": "CN", "sunrise": 1760134807, "sunset": 1760175719}, "timezone": 28800, "id": 1816670, "name": "Beijing", "cod": 200}
Invoking: `get_weather` with `{'local': 'Hangzhou'}`
{"coord": {"lon": 120.1614, "lat": 30.2937}, "weather": [{"id": 800, "main": "Clear", "description": "\u6674", "icon": "01n"}], "base": "stations", "main": {"temp": 25.75, "feels_like": 26.6, "temp_min": 25.75, "temp_max": 25.75, "pressure": 1013, "humidity": 85, "sea_level": 1013, "grnd_level": 1011}, "visibility": 10000, "wind": {"speed": 1.31, "deg": 357, "gust": 1.77}, "clouds": {"all": 0}, "dt": 1760112307, "sys": {"country": "CN", "sunrise": 1760133508, "sunset": 1760175212}, "timezone": 28800, "id": 1808926, "name": "Hangzhou", "cod": 200}
Invoking: `write_file` with `{'content': '北京和杭州当前温度查询结果\n\n北京天气情况:\n- 城市:北京\n- 温度:11.26°C\n- 体感温度:10.77°C\n- 天气状况:小雨\n- 湿度:89%\n- 气压:1019 hPa\n- 风速:0.75 m/s\n- 可见度:10000米\n\n杭州天气情况:\n- 城市:杭州\n- 温度:25.75°C\n- 体感温度:26.60°C\n- 天气状况:晴\n- 湿度:85%\n- 气压:1013 hPa\n- 风速:1.31 m/s\n- 可见度:10000米\n\n查询时间:2025年10月10日'}`
responded: 现在我将查询到的天气信息整理并写入本地文件:
已成功写入本地文件。我已经为您查询了北京和杭州的当前温度,并将结果写入本地文件。
查询结果如下:
- **北京**:当前温度11.26°C,天气状况为小雨
- **杭州**:当前温度25.75°C,天气状况为晴
两地温差较大,北京较冷(11.26°C),而杭州相对温暖(25.75°C)。详细的天气信息已成功保存到本地文件中。
> Finished chain.
{'input': '查一下北京和杭州现在的温度,并将结果写入本地的文件中。', 'output': '我已经为您查询了北京和杭州的当前温度,并将结果写入本地文件。\n\n查询结果如下:\n- **北京**:当前温度11.26°C,天气状况为小雨\n- **杭州**:当前温度25.75°C,天气状况为晴\n\n两地温差较大,北京较冷(11.26°C),而杭州相对温暖(25.75°C)。详细的天气信息已成功保存到本地文件中。'}
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐


 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)