
【论文阅读】LANGUAGE MODELS CAN LEARN FROM VERBAL FEEDBACK WITHOUT SCALAR REWARDS
大型语言模型通常通过来自人类或人工智能反馈的强化学习进行训练,然而这些方法往往将细致的反馈压缩为标量奖励,丢弃了其中丰富的信息并引发尺度失衡。我们建议将语言反馈视为一种条件信号。受文本到图像生成中语言先验的启发——该先验能通过未见提示产生新颖输出——我们提出反馈条件策略(FCP)。FCP 直接从回复-反馈对中学习,通过对离线数据的最大似然训练来近似反馈条件后验。我们进一步开发了一个在线自举阶段,在
语言模型能够从语言反馈中学习,而无需基于数值的奖励机制。
摘要
大型语言模型通常通过来自人类或人工智能反馈的强化学习进行训练,然而这些方法往往将细致的反馈压缩为标量奖励,丢弃了其中丰富的信息并引发尺度失衡。我们建议将语言反馈视为一种条件信号。受文本到图像生成中语言先验的启发——该先验能通过未见提示产生新颖输出——我们提出反馈条件策略(FCP)。FCP 直接从回复-反馈对中学习,通过对离线数据的最大似然训练来近似反馈条件后验。我们进一步开发了一个在线自举阶段,在该阶段中,策略在积极条件下生成回复并接收新的反馈以进行自我精修。这重新将反馈驱动的学习框架为条件生成而非奖励优化,为大型语言模型直接从语言反馈中学习提供了一种更具表现力的方式。
论文精读
Introduction
将语言反馈简化为标量奖励会带来若干局限:
- **信息损失:**标量奖励捕获的信息远少于语言反馈/批评,且往往难以解释。例如,批评“回答冗余但正确”与“回答简洁但有很多拼写错误”都可能被映射为 0.8 的奖励,尽管它们描述了截然不同的回答模式。此外,(生成式)奖励模型生成的语言化思考通常作为中间输出被丢弃,仅保留最终标量用于强化学习训练。
- **歧义性:**语言反馈,尤其是来自人类用户的反馈,往往混杂(同时包含优点与缺点)、带有情绪或不确定性,例如“我太开心了”或“我不确定,或许再试一次?”。这类反馈远比纯粹的正向或负向信号常见,并蕴含多样的学习线索以及对用户交互风格的理解。将这些反馈映射为标量可能含糊或武断。 (感觉和信息损失属于一种)
- **跨任务奖励尺度失衡:**在多任务训练(如数学、代码、科学、游戏)中,难以维持一致的奖励尺度。在简单数学题上获得正向反馈远比在具有挑战性的编程或游戏任务中容易,这导致不同领域间奖励失衡,并引入学习过程的偏差。(这是如何解决的?)
长期以来,标量化一直被视为不可避免,用于弥合语言反馈与强化学习所需的数值信号之间的鸿沟。然而,随着大规模语言预训练的兴起,这一观点正在被重新审视(Yao,2025)。大语言模型蕴含强大的常识和语言先验,这提示了一种新范式:将语言反馈视为头等训练信号,而非强行将其压缩为标量形式。
毕竟,大型语言模型已经表现出对口头反馈的隐含理解能力。在具身任务中,它们通过将人类用户、外部批评或工具调用的反馈提示整合进上下文,并据此迭代式地优化回答(Wang 等,2025b;Novikov 等,2025)。这表明 LLM 能够处理口头反馈,但仅是以隐含方式,通过一个潜藏的“mental model”,而并未把理解转化为显式的标量奖励。因此,关键问题在于如何将这些反馈提炼为训练信号,使其直接提升模型性能,而非在测试阶段依赖低效的多轮试错。
为此,我们提出学习一种反馈条件策略(FCP)πθ(o|x, c) ∝ πref(o|x) · penv(c|x, o),其中 πref(o|x) 是给定指令 x 时生成响应 o 的参考策略,penv(c|x, o) 是环境反馈 c 的分布。直观上,FCP 根据每个响应 o 引发观测反馈 c 的可能性对参考策略进行重新加权。以正面反馈 c+ 为条件,可得 πθ(o|x, c+) ∝ πref(o|x) · penv(c+|x, o),从而提升生成那些更可能获得正面反馈的响应的概率。通过这种方式,FCP 学习一个后验分布,将来自 πref 的先验知识与语言反馈相融合,使其能够处理包括混合反馈在内的多种形式反馈,如图 1 所示。

在训练了一个以任意反馈 c 为条件的离线 FCP πθ(o|x, c) ∝ πref(o|x) · penv(c|x, o) 之后,我们通过在线自举进一步提升其性能。具体而言,我们通过对行为策略 πθ(o|x, c+)(以正面反馈为目标的条件下)进行采样生成 rollout,并用来自 penv 的新反馈重新标注,从而迭代地强化策略。
我们的初步实验表明,FCP 在不依赖验证器、标量转换或数据过滤的情况下,能够匹配甚至超越诸如离线 RFT(Dong 等,2023)和在线 GRPO(Shao 等,2024)等强标量基线。这展示了一个简单且可扩展的框架,既保留了语言反馈的丰富性,又避免了基于规则验证器的稀缺性和 Reward Hacking 的风险。尽管我们当前的实现较为朴素,但先进的训练技术有望进一步提升 FCP 的性能。受篇幅限制,相关工作推迟至附录 B。
方法
传统的强化学习方法通过增加获得“良好”反馈的响应的权重,同时降低获得“不良”反馈的响应的权重来训练策略。从概率角度看,强化学习可被视为学习期望获得良好反馈(即高奖励)的响应的后验分布(Peters & Schaal, 2007;Peng et al., 2019;Rafailov et al., 2023)。区分何为良好或不良通常需要精心设计的奖励函数或详细的评分标准以生成标量信号,这导致了第1节中讨论的局限性。
方法受文本到图像生成中语言先验的启发,在该任务中,模型通过混合字幕组合未见提示(图4)。类似地,语言先验可使大语言模型吸收多样化的语言反馈,并产生超越标量强化的高质量响应(图1)。鉴于大语言模型已表现出隐式反馈理解,我们直接在其上进行训练:
- 先离线初始化一个反馈条件策略(FCP)(第2.1节)
- 再在线提升性能(第2.2节)。
离线训练:初始化反馈条件策略
我们首先定义一个参考策略模型 πref,该模型接收输入指令 x 并生成响应 o ∼ πref(·|x)。随后,响应 o 与环境进行单轮交互,环境提供语言反馈 c ∼ penv(·|x, o)。
参考策略 πref 可以表示基础模型、指令微调模型或推理模型,响应 o 可包含思维过程及最终答案。
环境 penv 可由人类用户或生成式奖励模型构成。
在离线设置中,响应由 πref 收集,我们定义响应-反馈对的联合分布为 Poff(o, c|x) ≜ πref(o|x) · penv(c|x, o),并由此导出反馈条件下的后验分布:
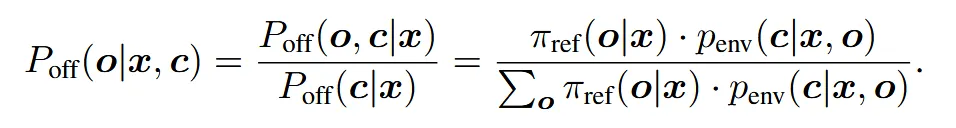
令 c+ 表示纯粹的正面反馈,c− 表示纯粹的负面反馈。混合反馈可近似表示为 c = (c+, c−),而中性或不确定的反馈可能两者都不是。例如,若我们以正面反馈 c+ 为条件,针对编码指令 x 的反馈为“生成的代码在功能上正确、高效且简洁”,则 Poff(o|x, c+) ∝ πref(o|x) · penv(c+|x, o),该式倾向于选择更有可能引发正面反馈的响应 o。
尽管 Poff(o|x, c+) ∝ πref(o|x) · penv(c+|x, o) 看似是我们所寻求的最优策略,但由于 penv(c+|x, o) 仅在完整响应 o 生成后才被定义,因此无法逐阶段指导生成过程,故不能直接对其进行采样。因此,我们的目标是学习一个能够逼近 Poff(o|x, c+) 的策略。根据 Rafailov 等人(2023)的研究,我们证明了 Poff(o|x, c+) 是以 log penv(c+|x, o) 为奖励函数的 KL 约束奖励最大化问题的最优解: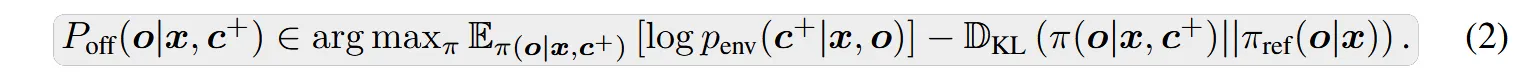
在环境提供可验证奖励的特殊情况下,即对于正确响应 o+ 有 penv(c+|x, o+) = 1,对于错误响应 o− 有 penv(c+|x, o−) = 0,我们可以证明 Poff(o|x, c+) 退化为一个无 KL 正则化的 0-1 二值奖励最大化问题的最优解:
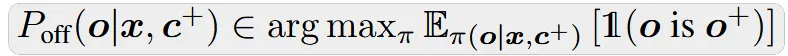
另一种学习目标。在更一般的场景中,特别是当反馈来自人类用户时,求解公式(2)通常是难以处理的。这是因为我们只能从 penv 中进行采样,而无法精确计算对数似然 log penv(c+|x, o)。注意,公式(2)中的目标等价于最小化 π(o|x, c+) 与 Poff(o|x, c+) 之间的逆KL散度:
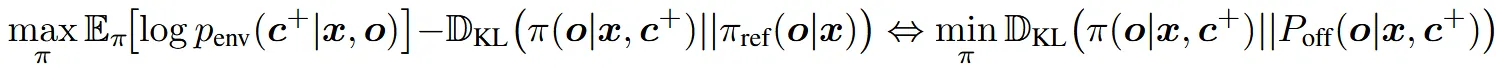
该式由公式(7)推导得出。为了避免在反向KL散度中计算log penv(c+|x, o)时出现难以处理的问题,我们转而提出最小化π(o|x, c+)与Poff(o|x, c+)之间的前向KL散度。然而在实践中,我们只能从penv(c|x, o)获得反馈,若无精心设计的评分标准或过滤机制,则无法仅从正向反馈的受限子集penv(c+|x, o)中进行采样。为解决此问题,我们对目标进行了推广:不再仅仅近似Poff(o|x, c+),而是学习近似Poff(o|x, c),即直接以任意反馈c作为条件。
具体而言,我们提出通过最小化πθ(o|x, c)与Poff(o|x, c)之间关于o的期望前向KL散度,来学习一个反馈条件策略(FCP)πθ(o|x, c):
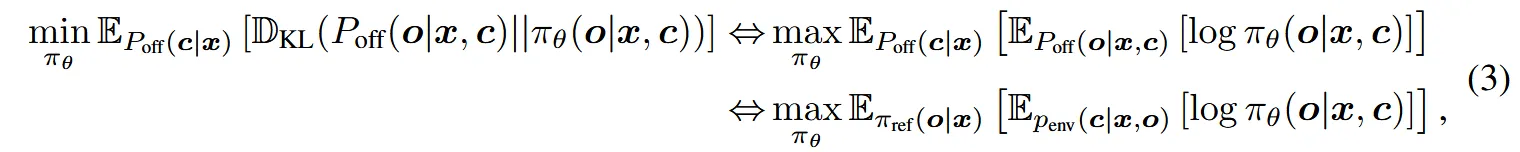
其中第二个等式源于恒等式 Poff(c|x) · Poff(o|x, c) = Poff(o, c|x) = πref(o|x) · penv(c|x, o)。公式(3)中的该目标函数退化为最大似然训练,可直接利用来自 πref(o|x) 和 penv(c|x, o) 收集的数据进行实现和优化,如算法1所述。其最优解在 Poff(c|x) 的支撑集上满足 πθ∗(o|x, c) = Poff(o|x, c)。值得注意的是,我们的方法无需显式区分正向反馈 c+ 与负向反馈 c−;大语言模型中嵌入的语言先验能够隐式地解释并融合来自多种反馈形式(包括图1所示的混合反馈)的信息。在测试阶段,用户可指定期望的正向反馈 c+,并通过 πθ(o|x, c+) 生成响应。
**备注 I:**为何使用 Poff(c|x)?在公式 (3) 中,关于 c 的期望是相对于 Poff(c|x) 计算的。原则上,可以使用任意其他分布 p(c|x),最优解 πθ∗(o|x, c) = Poff(o|x, c) 在支撑集 supp(p(·|x)) 上保持不变。我们采用 Poff(c|x) 主要出于两个原因:(i)其支撑集 supp(Poff(·|x)) = S o∈supp(πref(·|x)) supp(penv(·|x, o)) 覆盖了收集离线数据时可能遇到的所有反馈;(ii)它作为一种补偿分布,将难以处理的后验期望 Poff(o|x, c) 转化为易于处理的联合期望 Poff(o, c|x) = πref(o|x) · penv(c|x, o),便于进行采样。
**注释二:FCP 作为逆向动力学。我们注意到,本文在公式 (3) 中的 FCP 学习与逆向动力学建模一致(Brandfonbrener 等,2023),这与将监督微调(SFT)**视为行为克隆、批判微调(CFT)(Wang 等,2025a)视为正向动力学的观点相辅相成。该类比的详细讨论见附录 A.2。

在线训练:通过正向反馈条件化进行自举
我们将通过求解公式(3)中的离线问题得到的模型记为πθoff(o|x, c),该模型能够根据任意用户定义的反馈c生成响应。基于此模型,我们进一步进行在线训练,通过显式地以正向反馈c+为条件来提升性能。具体而言,我们使用来自πθt(o|x, c+)的 rollout 迭代更新参数θt+1,其中t ∈ N,且θ0 = θoff由离线解初始化,如算法2所述。
形式上,我们定义联合分布 Pθt (o, c, c+|x) ≜ puser(c+|x) · πθt (o|x, c+) · penv(c|x, o),其中 puser(c+|x) 表示用户指定的期望正向反馈的分布(固定或可训练)。相应的反馈条件后验为
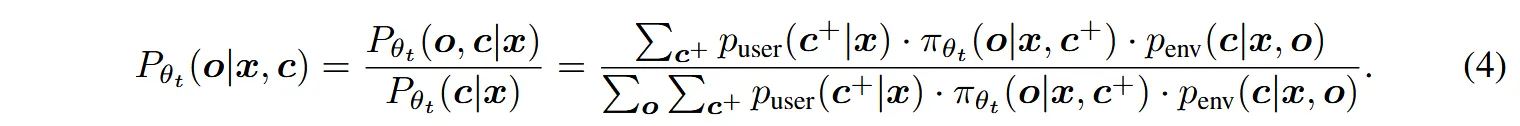
基于θt(梯度在θt处停止)更新θt+1的优化目标是:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
直觉上,在每一轮训练t中(不同于轮次内进行的第s步梯度更新),当前模型πθt以c+为条件采样候选的正面响应。然后,这些响应由环境重新标注新的反馈c。通过连续多轮训练,**模型学习识别那些以c+为条件却未能产生正面评价的情况,同时强化那些与预期反馈一致的响应。**这一迭代过程实现了模型的自我引导,逐步增强与用户指定的正面反馈的对齐程度。此外,根据Lanchantin等(2025)的方法,轮次之间的梯度步数S可以灵活调整,从而使该方法能够在完全在线与半在线训练之间进行插值。

更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)