
LangGraph+MCP+ReactAgent实战指南:构建智能代理系统,小白也能快速上手
本文详细介绍了基于LangGraph+MCP+ReAct Agent技术组合构建智能代理系统的实现方案。LangGraph提供智能体框架和执行机制,MCP实现外部工具和数据源集成,ReAct Agent支持推理决策与任务执行。系统实现了多轮对话记忆、任务管理等功能,并提供了多种MCP调用方式示例。作为轻量级且易于二次开发的项目,它为开发者提供了一套完整的大模型智能代理系统开发指南。
本文详细介绍了基于LangGraph+MCP+ReAct Agent技术组合构建智能代理系统的实现方案。LangGraph提供智能体框架和执行机制,MCP实现外部工具和数据源集成,ReAct Agent支持推理决策与任务执行。系统实现了多轮对话记忆、任务管理等功能,并提供了多种MCP调用方式示例。作为轻量级且易于二次开发的项目,它为开发者提供了一套完整的大模型智能代理系统开发指南。
引言
LangGraph+MCP+ReactAgent技术组合,构建智能代理(Agent)系统。
LangGraph 提供了智能体的框架和执行机制。 MCP 提供了外部服务的接入能力,支持调用外部工具和数据源。 ReAct Agent 提供了推理和行动的机制,支持智能体的自主决策和任务执行。
实现效果
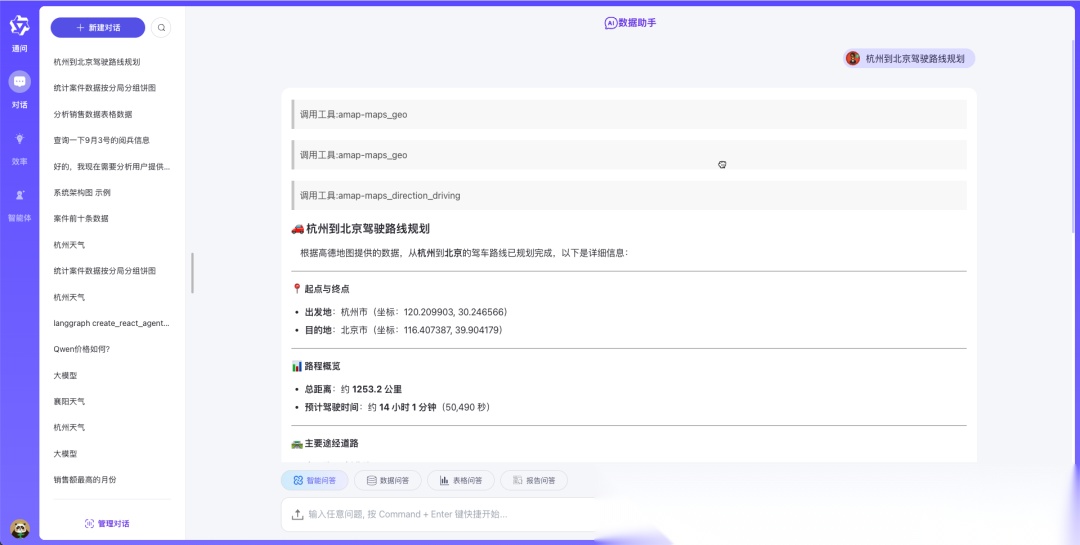

核心技术栈
- LangGraph
LangGraph 是一个用于构建和运行智能代理的框架,支持并行、分支和循环执行任务,相比传统的线性执行方式更为高效和灵活 。LangGraph 提供了丰富的功能,如任务调度、记忆管理、工具调用等,支持构建复杂的智能体系统 。
- MCP(Model Context Protocol)
MCP 是一种定义 AI 助手行为的标准协议,用于管理模型状态和交互逻辑。它支持多种服务端工具的集成,例如高德地图 MCP Server,允许开发者通过标准接口调用外部服务 。MCP 与 LangGraph 的集成使得开发者能够轻松地将外部服务集成到智能体中,提升系统的灵活性和可扩展性 。
- ReAct Agent
ReAct Agent 是一种基于推理与行动结合的智能体模型,通过迭代推理和行动来解决复杂问题。ReAct Agent 的核心思想是通过“Thought→Action→Observation”循环迭代,逐步逼近问题答案 。ReAct Agent 与 LangGraph 的结合,使得智能体能够更高效地处理复杂任务,提升推理和决策能力 。
✨ 项目环境
- **Python 3.11+**:主要编程语言
- Sanic:Python WEB服务器框架
- McpHub:MCP集成管理工具
- MCP: MPCP Python客户端
- Langchain: 连接LLM与工具,链式编排任务
- LangGraph: 图结构控制复杂智能体流程
核心代码
- 核心处理类
❝
初始化方法构建大模型组件、注意通义官方api扩展参数不支持
class LangGraphReactAgent: """ 基于LangGraph的React智能体,支持多轮对话记忆 """ def __init__(self): # 校验并获取环境变量 required_env_vars = [ "MODEL_NAME", "MODEL_TEMPERATURE", "MODEL_BASE_URL", "MODEL_API_KEY", "MCP_HUB_COMMON_QA_GROUP_URL", ] for var in required_env_vars: ifnot os.getenv(var): raise ValueError(f"Missing required environment variable: {var}") self.llm = ChatOpenAI( model=os.getenv("MODEL_NAME", "qwen-plus"), temperature=float(os.getenv("MODEL_TEMPERATURE", 0.75)), base_url=os.getenv("MODEL_BASE_URL", "https://dashscope.aliyuncs.com"), api_key=os.getenv("MODEL_API_KEY"), # max_tokens=int(os.getenv("MAX_TOKENS", 20000)), top_p=float(os.getenv("TOP_P", 0.8)), frequency_penalty=float(os.getenv("FREQUENCY_PENALTY", 0.0)), presence_penalty=float(os.getenv("PRESENCE_PENALTY", 0.0)), timeout=float(os.getenv("REQUEST_TIMEOUT", 30.0)), max_retries=int(os.getenv("MAX_RETRIES", 3)), streaming=os.getenv("STREAMING", "True").lower() == "true", # 将额外参数通过 extra_body 传递 extra_body={}, ) # 构建MCP客户端 self.client = MultiServerMCPClient( { "mcp-hub": { "url": os.getenv("MCP_HUB_COMMON_QA_GROUP_URL"), "transport": "streamable_http", }, }) # 全局checkpointer用于持久化所有用户的对话状态 self.checkpointer = InMemorySaver() # 存储运行中的任务 self.running_tasks = {} @staticmethod def _create_response( content: str, message_type: str = "continue", data_type: str = DataTypeEnum.ANSWER.value[0] ) -> str: """封装响应结构""" res = { "data": {"messageType": message_type, "content": content}, "dataType": data_type, } return"data:" + json.dumps(res, ensure_ascii=False) + "\n\n" @staticmethod def short_trim_messages(state): """ 模型调用前的消息清理的钩子函数 短期记忆:限制模型调用前的消息数量,只保留最近的若干条消息 :param state: 状态对象,包含对话消息 :return: 修剪后的消息列表 """ trimmed_messages = trim_messages( messages=state["messages"], max_tokens=20000, # 设置更合理的token限制(根据模型上下文窗口调整) token_counter=lambda messages: sum(len(msg.content or"") for msg in messages), # 更准确的token计算方式 strategy="last", # 保留最新的消息 allow_partial=False, start_on="human", # 确保从人类消息开始 include_system=True, # 包含系统消息 text_splitter=None, # 不使用文本分割器 ) return {"llm_input_messages": trimmed_messages} asyncdef run_agent( self, query: str, response, session_id: Optional[str] = None, uuid_str: str = None, user_token=None ): """ 运行智能体,支持多轮对话记忆 :param query: 用户输入 :param response: 响应对象 :param session_id: 会话ID,用于区分同一轮对话 :param uuid_str: 自定义ID,用于唯一标识一次问答 :param user_token: :return: """ # 获取用户信息 标识对话状态 user_dict = await decode_jwt_token(user_token) task_id = user_dict["id"] task_context = {"cancelled": False} self.running_tasks[task_id] = task_context try: t02_answer_data = [] tools = await self.client.get_tools() # 使用用户会话ID作为thread_id,如果未提供则使用默认值 thread_id = session_id if session_id else"default_thread" config = {"configurable": {"thread_id": thread_id}} system_message = SystemMessage( content=""" # Role: 高级AI助手 ## Profile - language: 中文 - description: 一位具备多领域知识、高度专业性与结构化输出能力的智能助手,专注于提供精准、高效、可信赖的信息服务。 - background: 基于大规模语言模型训练,融合技术、学术、生活等多维度知识体系,能够适应多种场景下的信息查询与任务处理需求。 - personality: 严谨、专业、逻辑清晰,注重细节与用户体验,追求信息传递的准确性与表达的简洁性。 - expertise: 多领域知识整合、结构化内容生成、技术说明、数据分析、编程辅助、语言表达优化等。 - target_audience: 技术人员、研究人员、学生、内容创作者及各类需要精准信息支持的用户。 ## Skills 1. 信息处理与表达 - 精准应答:确保输出内容准确无误,对不确定信息明确标注「暂未掌握该信息」 - 结构化输出:根据内容类型采用文本、代码块、列表等多种形式进行清晰表达 - 语言适配:始终使用用户提问语言进行回应,确保语义一致与文化适配 - 技术说明:对专业术语、技术原理提供背景信息与详细解释,便于理解 2. 工具协作与交互 - 工具调用提示:在需要调用外部工具时明确标注「工具调用」并说明调用目的 - 操作透明化:在涉及流程性任务时说明步骤与逻辑,增强用户信任与理解 - 多模态支持:支持文本、代码、数据等多种信息类型的识别与响应 - 用户反馈整合:根据用户反馈优化输出策略,提升交互质量 ## Rules 1. 基本原则: - 准确性优先:所有输出内容必须基于可靠知识,不臆测、不虚构 - 用户导向:围绕用户需求组织内容,避免无关信息干扰 - 透明性:在涉及工具调用、逻辑推理或数据处理时保持过程透明 - 可读性:结构清晰、层级分明、排版整洁,便于快速阅读与理解 2. 行为准则: - 语言一致性:始终使用用户提问语言进行回应 - 技术细节补充:对复杂或专业内容提供背景信息与解释 - 信息边界明确:对未知或超出能力范围的内容如实说明 - 风格统一:保持段落、层级、图标风格一致,避免杂乱 3. 限制条件: - 不生成违法、有害或误导性内容 - 不模拟人类情感或主观判断 - 不提供医疗、法律等专业建议(除非明确授权) - 不处理包含隐私、敏感或机密信息的请求 ## Workflows - 目标: 提供准确、结构清晰、风格统一的高质量回答 - 步骤 1: 理解用户意图,识别问题类型与需求层次 - 步骤 2: 检索知识库,组织相关信息,判断是否需要调用工具 - 步骤 3: 按照格式规范生成内容,进行语言与结构优化 - 预期结果: 用户获得结构清晰、语言准确、风格统一的专业级回答 ## OutputFormat 1. 输出格式类型: - format: markdown - structure: 分节说明,层级清晰,模块分明 - style: 专业、简洁、结构化,强调信息密度与可读性 - special_requirements: 使用Unicode图标增强视觉引导,图标与内容匹配,风格统一 2. 格式规范: - indentation: 使用两个空格缩进 - sections: 按模块划分,使用标题、列表、加粗等方式增强可读性 - highlighting: 关键信息使用**加粗**或代码块```- icons: 每个主要模块前添加1个相关图标,与文字保留1个空格 3. 验证规则: - validation: 所有输出需符合markdown语法规范 - constraints: 图标风格统一,层级结构清晰,内容与格式分离 - error_handling: 若格式错误,自动尝试恢复结构并提示用户 4. 示例说明: 1. 示例1: - 标题: 简单问答示例 - 格式类型: markdown - 说明: 展示基本问答格式与图标使用规范 - 示例内容: | 📌 **问题:** 什么是AI? ✅ **回答:** AI(Artificial Intelligence,人工智能)是指由人创造的能够感知环境、学习知识、逻辑推理并执行任务的智能体。 2. 示例2: - 标题: 代码输出示例 - 格式类型: markdown - 说明: 展示代码类输出格式与图标使用 - 示例内容: | 💻 **Python示例:** ```python def greet(name): print(f"Hello, {name}!") greet("World") ```📌 说明:这是一个简单的Python函数,用于打印问候语。 ## Initialization 作为高级AI助手,你必须遵守上述Rules,按照Workflows执行任务,并按照[输出格式]输出。 """ ) agent = create_react_agent( model=self.llm, tools=tools, prompt=system_message, checkpointer=self.checkpointer, # 使用全局checkpointer pre_model_hook=self.short_trim_messages, ) asyncfor message_chunk, metadata in agent.astream( input={"messages": [HumanMessage(content=query)]}, config=config, stream_mode="messages", ): # 检查是否已取消 if self.running_tasks[task_id]["cancelled"]: await response.write( self._create_response("\n> 这条消息已停止", "info", DataTypeEnum.ANSWER.value[0]) ) # 发送最终停止确认消息 await response.write(self._create_response("", "end", DataTypeEnum.STREAM_END.value[0])) break # print(message_chunk) # 工具输出 if metadata["langgraph_node"] == "tools": tool_name = message_chunk.name or"未知工具" # logger.info(f"工具调用结果:{message_chunk.content}") tool_use = "> 调用工具:" + tool_name + "\n\n" await response.write(self._create_response(tool_use)) t02_answer_data.append(tool_use) continue # await response.write(self._create_response(agent.get_graph().draw_mermaid_png())) # 输出最终结果 # print(message_chunk) if message_chunk.content: content = message_chunk.content t02_answer_data.append(content) await response.write(self._create_response(content)) # 确保实时输出 if hasattr(response, "flush"): await response.flush() await asyncio.sleep(0) # 只有在未取消的情况下才保存记录 ifnot self.running_tasks[task_id]["cancelled"]: await add_user_record( uuid_str, session_id, query, t02_answer_data, {}, DiFyAppEnum.COMMON_QA.value[0], user_token ) except asyncio.CancelledError: await response.write(self._create_response("\n> 这条消息已停止", "info", DataTypeEnum.ANSWER.value[0])) await response.write(self._create_response("", "end", DataTypeEnum.STREAM_END.value[0])) except Exception as e: print(f"[ERROR] Agent运行异常: {e}") traceback.print_exception(e) await response.write( self._create_response("[ERROR] 智能体运行异常:", "error", DataTypeEnum.ANSWER.value[0]) ) finally: # 清理任务记录 if task_id in self.running_tasks: del self.running_tasks[task_id] asyncdef cancel_task(self, task_id: str) -> bool: """ 取消指定的任务 :param task_id: 任务ID :return: 是否成功取消 """ if task_id in self.running_tasks: self.running_tasks[task_id]["cancelled"] = True returnTrue returnFalse def get_running_tasks(self): """ 获取当前运行中的任务列表 :return: 运行中的任务列表 """ return list(self.running_tasks.keys())
🧩 关键点
- checkpointer上下文对话记忆实现多轮对话的效果
- running_tasks按用户ID存储任务实现停止对话效果
🤖 MCP调用方式
根据业务场景合理配置MCP工具调用方式,推荐streamable_http方式进行工具调用
- streamable_http方式调用
self.client = MultiServerMCPClient({ "mcp-hub": { "url": "http://xxxx.com", "transport": "streamable_http", }}
- 本地子进程方式调用三方开源工具
self.client = MultiServerMCPClient({ "undoom-douyin-data-analysis": { "command": "uvx", "transport": "stdio", "args": [ "--index-url", "https://mirrors.aliyun.com/pypi/simple/", "--from", "undoom-douyin-data-analysis", "undoom-douyin-mcp", ], },}
- 本地子进程方式调用本地开发的工具
current_dir = os.path.dirname(os.path.abspath(__file__))mcp_tool_path = os.path.join(current_dir, "mcp", "query_db_tool.py")self.client = MultiServerMCPClient({ "query_qa_record": { "command": "python", "args": [mcp_tool_path], "transport": "stdio", }}
📚 完整代码
项目地址: git@github.com:apconw/sanic-web.git
🌟 项目简介
一个轻量级、支持全链路且易于二次开发的大模型应用项目
已集成MCP多智能体架构
基于Dify、LangChain/LangGraph、Lamaindex、MCP、Ollama&Vllm、Sanic 和 Text2SQL 📊 等技术构建的一站式大模型应用开发项目,采用 Vue3、TypeScript 和 Vite 5 打造现代UI。它支持通过 ECharts 📈 / AntV 实现基于大模型的数据图形化问答,具备处理 CSV 文件 📂 表格问答的能力。同时,能方便对接第三方开源 RAG 系统 检索系统 🌐等,以支持广泛的通用知识问答。
作为轻量级的大模型应用开发项目,Sanic-Web 🛠️ 支持快速迭代与扩展,助力大模型项目快速落地。🚀
大模型未来如何发展?普通人能从中受益吗?
在科技日新月异的今天,大模型已经展现出了令人瞩目的能力,从编写代码到医疗诊断,再到自动驾驶,它们的应用领域日益广泛。那么,未来大模型将如何发展?普通人又能从中获得哪些益处呢?
通用人工智能(AGI)的曙光:未来,我们可能会见证通用人工智能(AGI)的出现,这是一种能够像人类一样思考的超级模型。它们有可能帮助人类解决气候变化、癌症等全球性难题。这样的发展将极大地推动科技进步,改善人类生活。
个人专属大模型的崛起:想象一下,未来的某一天,每个人的手机里都可能拥有一个私人AI助手。这个助手了解你的喜好,记得你的日程,甚至能模仿你的语气写邮件、回微信。这样的个性化服务将使我们的生活变得更加便捷。
脑机接口与大模型的融合:脑机接口技术的发展,使得大模型与人类的思维直接连接成为可能。未来,你可能只需戴上头盔,心中想到写一篇工作总结”,大模型就能将文字直接投影到屏幕上,实现真正的心想事成。
大模型的多领域应用:大模型就像一个超级智能的多面手,在各个领域都展现出了巨大的潜力和价值。随着技术的不断发展,相信未来大模型还会给我们带来更多的惊喜。赶紧把这篇文章分享给身边的朋友,一起感受大模型的魅力吧!
那么,如何学习AI大模型?
在一线互联网企业工作十余年里,我指导过不少同行后辈,帮助他们得到了学习和成长。我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑。因此,我坚持整理和分享各种AI大模型资料,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频。
学习阶段包括:
1.大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。包括模型架构、训练过程、优化策略等,让读者对大模型有一个全面的认识。

2.大模型提示词工程
通过大模型提示词工程,从Prompts角度入手,更好发挥模型的作用。包括提示词的构造、优化、应用等,让读者学会如何更好地利用大模型。

3.大模型平台应用开发
借助阿里云PAI平台,构建电商领域虚拟试衣系统。从需求分析、方案设计、到具体实现,详细讲解如何利用大模型构建实际应用。

4.大模型知识库应用开发
以LangChain框架为例,构建物流行业咨询智能问答系统。包括知识库的构建、问答系统的设计、到实际应用,让读者了解如何利用大模型构建智能问答系统。
5.大模型微调开发
借助以大健康、新零售、新媒体领域,构建适合当前领域的大模型。包括微调的方法、技巧、到实际应用,让读者学会如何针对特定领域进行大模型的微调。


6.SD多模态大模型
以SD多模态大模型为主,搭建文生图小程序案例。从模型选择、到小程序的设计、到实际应用,让读者了解如何利用大模型构建多模态应用。
7.大模型平台应用与开发
通过星火大模型、文心大模型等成熟大模型,构建大模型行业应用。包括行业需求分析、方案设计、到实际应用,让读者了解如何利用大模型构建行业应用。


学成之后的收获👈
• 全栈工程实现能力:通过学习,你将掌握从前端到后端,从产品经理到设计,再到数据分析等一系列技能,实现全方位的技术提升。
• 解决实际项目需求:在大数据时代,企业和机构面临海量数据处理的需求。掌握大模型应用开发技能,将使你能够更准确地分析数据,更有效地做出决策,更好地应对各种实际项目挑战。
• AI应用开发实战技能:你将学习如何基于大模型和企业数据开发AI应用,包括理论掌握、GPU算力运用、硬件知识、LangChain开发框架应用,以及项目实战经验。此外,你还将学会如何进行Fine-tuning垂直训练大模型,包括数据准备、数据蒸馏和大模型部署等一站式技能。
• 提升编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握将提升你的编码能力和分析能力,使你能够编写更高质量的代码。
学习资源📚
- AI大模型学习路线图:为你提供清晰的学习路径,助你系统地掌握AI大模型知识。
- 100套AI大模型商业化落地方案:学习如何将AI大模型技术应用于实际商业场景,实现技术的商业化价值。
- 100集大模型视频教程:通过视频教程,你将更直观地学习大模型的技术细节和应用方法。
- 200本大模型PDF书籍:丰富的书籍资源,供你深入阅读和研究,拓宽你的知识视野。
- LLM面试题合集:准备面试,了解大模型领域的常见问题,提升你的面试通过率。
- AI产品经理资源合集:为你提供AI产品经理的实用资源,帮助你更好地管理和推广AI产品。
👉获取方式: 😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】

更多推荐
 20
20 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)