
【AI大模型前沿】MiroThinker:基于Qwen3构建的开源Agent模型系列,助力复杂任务解决
MiroThinker是一个开源的智能体(Agent)模型系列,专为深度研究和复杂、长期问题解决而设计。它基于Qwen3构建,具备任务分解、多跳推理、检索增强生成、代码执行、网页浏览和文件处理等多种能力。MiroThinker v0.1提供8B、14B和32B参数规模的SFT(Supervised Fine-Tuning)和DPO(Direct Preference Optimization)变体
系列篇章💥
前言
随着人工智能技术的飞速发展,大语言模型在各个领域的应用越来越广泛。然而,面对复杂的、长期的任务,传统的模型往往显得力不从心。为了满足深度研究和复杂任务解决的需求,MiroMind AI团队推出了一款开源的Agent模型系列——MiroThinker。它基于强大的Qwen3架构,具备任务分解、多跳推理、检索增强生成等能力,为解决复杂问题提供了新的思路和工具。
一、项目概述
MiroThinker是一个开源的智能体(Agent)模型系列,专为深度研究和复杂、长期问题解决而设计。它基于Qwen3构建,具备任务分解、多跳推理、检索增强生成、代码执行、网页浏览和文件处理等多种能力。MiroThinker v0.1提供8B、14B和32B参数规模的SFT(Supervised Fine-Tuning)和DPO(Direct Preference Optimization)变体,在GAIA基准测试中表现出色,能够满足广泛的实际应用场景需求。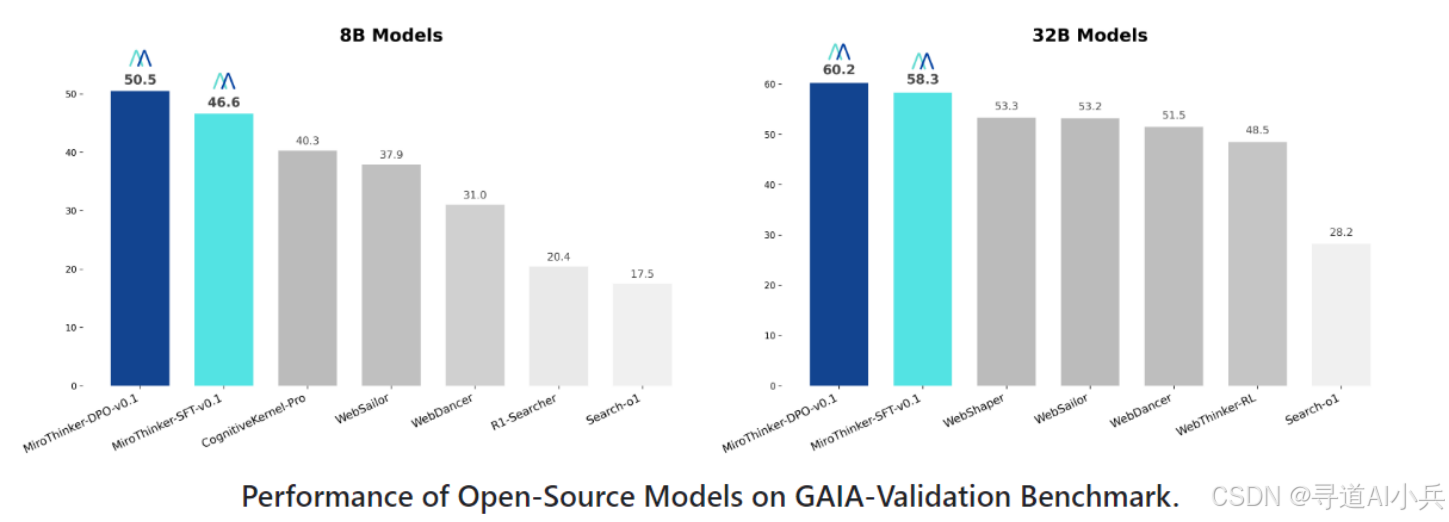
二、核心功能
(一)任务分解(Task Decomposition)
MiroThinker能够将复杂的任务分解为多个子任务,逐步解决问题。这种能力使得模型在面对复杂的、多步骤的任务时,能够更加高效地执行,提高任务的成功率。例如,在解决一个科学研究问题时,它可以将问题分解为实验设计、数据分析和结果验证等多个子任务,逐一进行处理。
(二)多跳推理(Multi-hop Reasoning)
支持多步骤的逻辑推理,能够处理需要多层思考和信息整合的问题。这使得MiroThinker在处理复杂的决策问题时,能够通过逐步推理得出准确的结论。例如,在商业决策中,它可以分析市场数据、竞争对手情况和用户需求等多个因素,最终给出最优的决策建议。
(三)检索增强生成(Retrieval-Augmented Generation)
结合检索技术,从大量数据中提取相关信息,增强生成内容的准确性和丰富性。这一功能使得MiroThinker在回答问题时,能够根据最新的数据和信息提供更准确、更全面的答案。例如,在回答一个关于最新科技发展的问题时,它可以通过检索最新的科技文献和新闻,生成准确且富有洞察力的回答。
(四)代码执行(Code Execution)
支持直接执行代码片段,能够处理编程任务和数据处理等需求。这使得MiroThinker在软件开发、数据分析等领域具有广泛的应用前景。例如,它可以协助开发者调试代码、优化算法,或者帮助数据分析师处理和分析数据。
(五)网页浏览(Web Browsing)
支持实时浏览网页,获取最新信息,用于回答需要最新数据的问题。这一功能使得MiroThinker能够提供最新的信息和数据,确保回答的时效性。例如,在回答一个关于最新市场趋势的问题时,它可以通过浏览最新的财经新闻和市场报告,提供最新的数据和分析。
(六)文件处理(Document/File Processing)
能够读取和处理多种格式的文件,如PDF、Word、Excel等,提取关键信息用于分析和回答问题。这使得MiroThinker在文档处理和信息提取方面具有强大的能力。例如,在处理一份研究报告时,它可以提取关键数据和结论,为用户提供精准的信息。
三、技术原理
(一)基于Qwen3的架构
MiroThinker是在Qwen3基础模型上构建的,继承了其强大的语言生成和理解能力。Qwen3本身是一个高性能的语言模型,具备优秀的文本生成和理解能力,为MiroThinker提供了坚实的基础。
(二)强化学习(Reinforcement Learning)
基于强化学习优化模型的行为策略,使其在复杂任务中表现更优。DPO(Direct Preference Optimization)变体特别强调这一点,通过直接优化模型的偏好,使其能够更好地适应复杂的任务场景。
(三)长期记忆与上下文管理
集成长期记忆机制,能够存储和检索大量上下文信息,支持长文本和复杂任务的处理。这一机制使得MiroThinker在处理长文本和多步骤任务时,能够更好地保持上下文的连贯性,提高任务的执行效率。
(四)工具集成框架(MiroFlow)
提供一个灵活的框架,支持与外部工具(如搜索引擎、代码执行环境等)的无缝集成,扩展模型的功能。MiroFlow框架使得MiroThinker能够与各种外部工具协同工作,进一步提升其功能和性能。
(五)大规模数据训练
使用大规模、高质量的数据集进行训练,确保模型在多种任务场景中表现出色。MiroThinker的训练数据集MiroVerse-v0.1包含了大量的高质量数据,使得模型能够更好地适应各种实际应用场景。
四、应用场景
(一)科学研究
MiroThinker能够助力研究人员分解复杂科学问题,通过多跳推理和检索增强生成,提供实验设计与解决方案建议。例如,在生物医学研究中,它可以协助研究人员设计实验方案、分析实验数据,并提供可能的解决方案。
(二)商业智能
实时获取市场数据,分析趋势,为商业决策提供支持,帮助企业在竞争中占据优势。MiroThinker可以通过网页浏览和文件处理功能,获取最新的市场数据和行业报告,为企业提供精准的商业决策建议。
(三)教育与学习
根据学生的学习进度和需求,提供个性化的学习计划与辅导,提升学习效果。MiroThinker可以通过分析学生的学习数据和反馈,制定个性化的学习计划,并提供针对性的学习辅导。
(四)医疗健康
分析患者病历和最新医学数据,为医生提供诊断和治疗建议,辅助临床决策。MiroThinker可以通过检索增强生成功能,结合最新的医学研究成果和患者病历,为医生提供准确的诊断和治疗建议。
(五)智能客服
处理复杂的客户咨询,通过多跳推理和检索增强生成,提供准确的解决方案,提升客户满意度。MiroThinker可以通过多跳推理和检索增强生成功能,快速准确地回答客户的复杂问题,提升客户体验。
五、性能表现
MiroThinker在多个基准测试中表现出色,尤其是在GAIA基准测试中,其性能达到了开源模型中的领先水平。以下是MiroThinker在GAIA基准测试中的部分性能数据:
| Method | Text-103 Best Pass@1 |
Text-103 Pass@1 (Avg@8) |
Val-165 Best Pass@1 |
Val-165 Pass@1 (Avg@8) |
|---|---|---|---|---|
| MiroThinker-8B-SFT-v0.1 | 44.7 | 40.1 | 34.6 | 31.8 |
| MiroThinker-8B-DPO-v0.1 | 46.6 | 44.8 | 37.0 | 35.4 |
| MiroThinker-14B-SFT-v0.1 | 47.6 | 44.4 | 37.0 | 34.4 |
| MiroThinker-14B-DPO-v0.1 | 48.5 | 46.6 | 42.4 | 39.2 |
| MiroThinker-32B-SFT-v0.1 | 55.3 | 51.3 | 44.9 | 42.7 |
| MiroThinker-32B-DPO-v0.1 | 57.3 | 54.1 | 48.5 | 45.9 |
从上述数据可以看出,MiroThinker在不同参数规模下的性能都非常出色,尤其是在DPO变体中,其性能提升更为显著。这表明MiroThinker在处理复杂的、多步骤的任务时具有很强的能力。
六、快速使用
(一)环境准备
- Python版本:确保安装了Python 3.10或更高版本。
- 包管理器:安装uv包管理器。
- API密钥:准备所需的API密钥,如Serper、E2B等。
(二)安装步骤
- 克隆仓库:
git clone https://github.com/MiroMindAI/MiroThinker
cd MiroThinker
- 下载基准测试数据:
wget https://huggingface.co/datasets/miromind-ai/MiroFlow-Benchmarks/resolve/main/data_20250808_password_protected.zip
unzip data_20250808_password_protected.zip
# 解压密码为:`pf4*`
rm data_20250808_password_protected.zip
- 设置环境:
cd apps/miroflow-agent
uv sync
cp .env.example .env
# 编辑.env文件,填入你的API密钥
- 启动MiroThinker模型服务:
NUM_GPUS=4
PORT=61002
MODEL_PATH=miromind-ai/MiroThinker-32B-DPO-v0.1
python3 -m sglang.launch_server \
--model-path $MODEL_PATH \
--tp $NUM_GPUS \
--dp 1 \
--host 0.0.0.0 \
--port $PORT \
--trust-remote-code \
--log-level debug \
--log-level-http debug \
--log-requests \
--log-requests-level 2 \
--attention-backend flashinfer \
--enable-metrics \
--show-time-cost \
--chat-template assets/qwen3_nonthinking.jinja
- 运行单次评估:
uv run main.py llm=qwen3-32b agent=evaluation llm.openai_base_url=https://your_base_url/v1
- 运行全面基准测试:
# GAIA-Validation
LLM_MODEL="xxx" BASE_URL="xxx" AGENT_SET="evaluation_os" bash scripts/run_evaluate_multiple_runs_gaia-validation.sh
- 监控评估进度:
python benchmarks/check_progress/check_progress_gaia-validation.py /path/to/evaluation/logs
七、结语
MiroThinker作为一款开源的Agent模型系列,凭借其强大的功能和灵活的框架,为解决复杂任务提供了新的思路和工具。它在科学研究、商业智能、教育与学习、医疗健康等多个领域具有广泛的应用前景。通过本文的介绍,相信读者对MiroThinker有了更深入的了解。如果想进一步探索和使用MiroThinker,可以访问以下项目地址:
- GitHub仓库:https://github.com/MiroMindAI/MiroThinker
- HuggingFace模型库:https://huggingface.co/collections/miromind-ai/mirothinker-v01-689301b6d0563321862d44a1
- 在线体验Demo:https://dr.miromind.ai/

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!
更多推荐


 21
21 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)