
【收藏必学】大模型时代重排序技术实战指南:从原理到代码,提升搜索相关性40%
本文系统介绍重排序模型技术,包括五大技术类别(交叉编码器、LLM重排序、混合架构、商业解决方案、传统排序方法)及其应用。详细分析现代搜索系统两阶段架构,提供实施最佳实践和性能优化策略,涵盖评估指标、技术选型框架及生产级服务架构。通过实际案例展示重排序技术可提升搜索相关性达40%,为工程师构建高效检索系统提供全方位技术指导。
在构建企业级搜索引擎时,工程师们经常面临这样的挑战:初始检索系统虽然能够返回大量潜在相关文档(通常在1000个左右),但真正符合用户需求的高质量结果往往被淹没在海量数据中,可能散布在结果列表的任意位置。这种现象在现代搜索引擎、推荐系统以及检索增强生成(RAG)应用中普遍存在,严重影响了用户体验和系统效率。
重排序模型作为信息检索领域的关键技术组件,能够有效解决这一问题。该技术通过对初步检索结果进行精确的相关性重新评估和排序,可显著提升搜索结果质量。根据实际部署经验,在企业级搜索系统中应用重排序模型可将搜索相关性指标提升高达40%,同时大幅改善用户满意度。本文将系统性地分析重排序模型的技术原理,深入探讨从传统学习排序方法到基于Transformer架构的前沿解决方案。
重排序模型的技术定义与核心价值
重排序模型是专门设计用于优化搜索结果排序的机器学习系统,其核心功能是根据查询与文档之间的相关性程度对候选结果进行重新排列。在信息检索系统架构中,重排序模型扮演着质量控制层的角色,将粗粒度的候选文档集合转换为精确排序的高质量结果列表。
从技术实现角度来看,重排序过程类似于多阶段筛选机制。在图书馆信息管理场景中,当用户查询"机器学习"相关书籍时,初始检索可能返回数百本包含相关术语的图书。重排序模型则如同领域专家,通过深度分析每本书籍的内容特征,综合考虑用户查询意图,最终将最具相关性的资源优先呈现给用户。
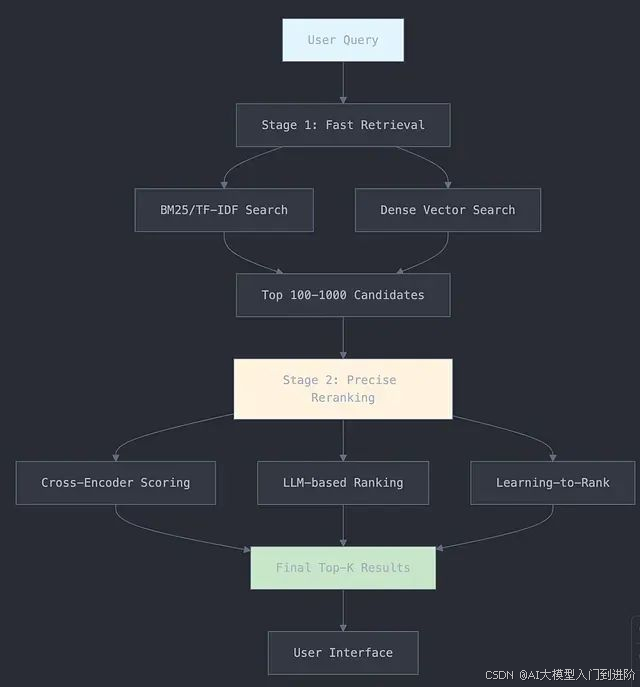

现代搜索系统的两阶段架构设计
当前主流的信息检索系统普遍采用两阶段架构模式,这种设计在效率与效果之间实现了最优平衡。第一阶段为检索阶段,采用高效率的算法快速从大规模文档库中筛选出潜在相关的候选集合,通常包含100到1000个文档。第二阶段为重排序阶段,运用复杂的机器学习模型对候选文档进行精确的相关性评估和排序优化。
这种架构设计的技术优势在于充分利用了不同算法的特性优势。检索阶段注重速度和召回率,采用相对简单但高效的算法;重排序阶段则专注于准确性和精确度,运用计算复杂度较高但效果卓越的深度学习模型。这种策略类似于先使用宽谱检测工具进行区域扫描,再运用精密仪器进行局部精确测量的工程方法论。
重排序模型的五大技术类别分析
1、交叉编码器架构
交叉编码器代表了当前重排序技术的最高准确性标准。该架构的核心创新在于对查询和候选文档进行联合编码处理,从而能够捕获传统方法无法识别的复杂语义交互模式。
技术实现机制:
# 交叉编码器评分核心算法
def cross_encoder_score(query, document, model):
# 使用特殊分隔符构建输入序列
input_text = f"[CLS] {query} [SEP] {document} [SEP]"
# 执行词元化和张量编码
tokens = tokenizer(input_text, return_tensors="pt")
# Transformer模型前向传播
outputs = model(**tokens)
# 提取相关性评分
relevance_score = outputs.logits[0]
return relevance_score.item()
# 重排序应用示例
query = "machine learning algorithms"
candidates = ["Neural networks for classification",
"Cooking recipes for pasta",
"Deep learning frameworks comparison"]
scores = []
for doc in candidates:
score = cross_encoder_score(query, doc, reranker_model)
scores.append((doc, score))
# 按相关性分数降序排列
reranked_results = sorted(scores, key=lambda x: x[1], reverse=True)
主流的交叉编码器模型包括MS-MARCO交叉编码器,该模型基于Microsoft大规模查询-段落数据集训练,是段落重排序的主力工具;MonoT5作为基于T5架构的模型,专门用于查询-文档对的二元分类任务;DeBERTa-v3重排序器相比传统BERT架构具有显著的性能优势;ColBERTv2则在保持高精度的同时针对大规模推理场景进行了优化。
根据实际部署经验,MS-MARCO交叉编码器(特别是cross-encoder/ms-marco-MiniLM-L-6-v2变体)在英文文本重排序任务中展现出优异的准确性与效率平衡,已成功应用于日处理千万级查询的生产环境。
2、基于大型语言模型的重排序技术
大型语言模型的快速发展为重排序技术开辟了新的技术路径。这类方法充分利用GPT-4、T5等先进模型的强大推理能力,实现对查询-文档相关性的精细化判断。
import openai
def llm_rerank(query, documents, model="gpt-4"):
"""
基于GPT-4的文档重排序实现
"""
# 构建提示模板
docs_text = "\n".join([f"{i+1}. {doc}" for i, doc in enumerate(documents)])
prompt = f"""
查询:"{query}"
请根据相关性对以下文档进行排序(相关性最高的排在前面):
{docs_text}
请仅返回排序后的数字序号,用逗号分隔。
"""
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.1 # 设置低温度以确保排序一致性
)
# 解析排序结果
ranking = [int(x.strip()) - 1 for x in response.choices[0].message.content.split(",")]
# 重构文档序列
reranked_docs = [documents[i] for i in ranking]
return reranked_docs
# 应用实例
query = "偏远社区的可持续能源解决方案"
documents = [
"城市地区太阳能电池板安装技术指南",
"偏远地区风力发电微型电网系统",
"发展中国家传统烹饪方法研究",
"水力发电设施环境影响评估报告"
]
reranked = llm_rerank(query, documents)
print("重排序结果:", reranked)
当前主要的基于LLM的重排序解决方案包括Cohere重排序器,提供产业级API服务并具备最先进的重排序性能;RankT5和RankGen作为专门针对排序任务优化的T5模型变体;以及基于GPT-4提示工程的复杂相关性判断方案。
基于LLM的重排序器的技术优势在于其卓越的上下文理解能力、意图识别能力以及对查询与文档间复杂语义关系的精确建模。然而,这类方法的计算开销和成本投入通常高于传统技术路线,需要在性能提升与资源消耗之间进行权衡。
3、多阶段混合重排序架构
在生产环境中最为成功的系统通常采用多种重排序技术的组合策略,通过复杂的流水线架构实现效率与效果的双重优化。这种混合策略能够充分发挥不同算法的技术优势,在保证高质量结果的同时维持系统的响应速度。
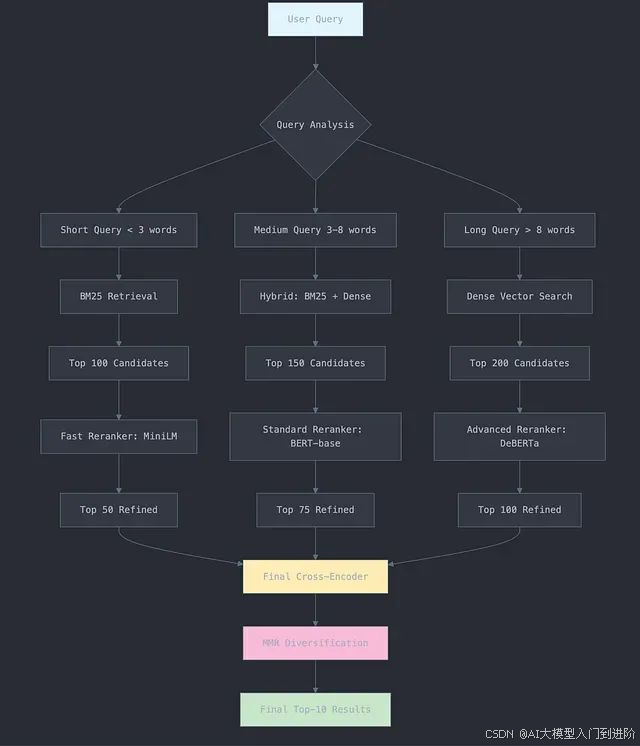
三阶段混合处理流程:
class HybridRerankingPipeline:
def __init__(self):
self.bm25_retriever = BM25Retriever()
self.dense_retriever = DenseRetriever()
self.cross_encoder = CrossEncoder('ms-marco-MiniLM-L-6-v2')
def search_and_rerank(self, query, corpus, top_k=10):
# 第一阶段:BM25快速检索
bm25_candidates = self.bm25_retriever.retrieve(query, corpus, top_k=100)
# 第二阶段:密集向量语义检索
dense_candidates = self.dense_retriever.retrieve(query, corpus, top_k=100)
# 候选结果融合与去重
all_candidates = self.merge_candidates(bm25_candidates, dense_candidates)
# 第三阶段:交叉编码器精确重排序
reranked_results = self.cross_encoder.rerank(query, all_candidates)
return reranked_results[:top_k]
def merge_candidates(self, list1, list2):
"""多检索器结果融合算法"""
seen = set()
merged = []
# 交替合并以保持结果多样性
for i in range(max(len(list1), len(list2))):
if i < len(list1) and list1[i]['id'] not in seen:
merged.append(list1[i])
seen.add(list1[i]['id'])
if i < len(list2) and list2[i]['id'] not in seen:
merged.append(list2[i])
seen.add(list2[i]['id'])
return merged[:50] # 限制最终重排序候选数量
高级混合技术包括最大边际相关性(MMR)算法,该算法在保证相关性的同时优化结果多样性以避免信息冗余;集成重排序技术通过融合多个重排序模型的预测结果提升整体性能;级联重排序策略则通过先应用计算效率高的模型进行初步筛选,再使用复杂模型进行精确排序,实现计算资源的优化配置。
实际评估数据表明,混合方法相比单一技术路线通常能够实现15-25%的性能提升。关键在于根据具体应用场景的需求特点,在响应速度与排序精度之间找到最优平衡点。
4、商业化和领域专用重排序解决方案
对于寻求快速部署重排序功能而非从零开发的技术团队,市场上提供了多种成熟的商业化解决方案,这些产品经过大规模生产环境验证,具备较高的稳定性和可靠性。
企业级解决方案主要包括Microsoft Azure认知搜索服务,该平台为大规模网络应用提供内置的语义重排序功能;Amazon Kendra作为综合性企业搜索平台的核心组件,集成了智能重排序算法;Google Cloud Vertex Search充分利用Google在搜索技术领域的深厚积累,为定制化应用提供专业服务;而Vespa.ai则作为开源平台,提供了高度可配置的重排序能力。
Cohere重排序API集成实现:
import cohere
co = cohere.Client('your-api-key')
def cohere_rerank(query, documents, top_k=5):
"""
基于Cohere重排序API的生产级实现
"""
response = co.rerank(
model='rerank-english-v2.0',
query=query,
documents=documents,
top_k=top_k,
return_documents=True
)
reranked_docs = []
for result in response.results:
reranked_docs.append({
'document': result.document.text,
'relevance_score': result.relevance_score,
'index': result.index
})
return reranked_docs
# 应用示例
query = "气候变化缓解策略"
docs = [
"发展中国家可再生能源技术推广应用",
"碳捕获与封存技术发展现状",
"巧克力曲奇制作工艺详解",
"森林生态保护与植被恢复工程"
]
results = cohere_rerank(query, docs)
for i, result in enumerate(results):
print(f"{i+1}. {result['document']} (相关性评分: {result['relevance_score']:.3f})")
5、传统学习排序模型体系
在深度学习变革浪潮到来之前,传统的学习排序(Learning to Rank, LTR)模型在重排序领域占据主导地位。这些经典方法在特定场景下仍具有重要价值,特别是在需要特征可解释性或计算资源受限的应用环境中。
主要的学习排序算法包括RankNet,这是一种基于神经网络的方法,采用成对比较损失函数进行优化;LambdaMART结合了梯度提升决策树与排序指标直接优化的技术特点;XGBoost LTR则提供了内置排序目标函数的树模型实现方案。
import lightgbm as lgb
import numpy as np
class LambdaMARTReranker:
def __init__(self):
self.model = None
def prepare_features(self, query, documents):
"""查询-文档特征工程实现"""
features = []
for doc in documents:
feature_vector = [
self.calculate_bm25_score(query, doc),
self.calculate_tfidf_similarity(query, doc),
len(doc.split()), # 文档词汇数量
self.calculate_exact_matches(query, doc),
self.calculate_jaccard_similarity(query, doc)
]
features.append(feature_vector)
return np.array(features)
def train(self, training_data):
"""LambdaMART模型训练流程"""
X_train, y_train, groups = self.prepare_training_data(training_data)
train_data = lgb.Dataset(X_train, label=y_train, group=groups)
params = {
'objective': 'lambdarank',
'metric': 'ndcg',
'ndcg_eval_at': [1, 3, 5, 10],
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9
}
self.model = lgb.train(params, train_data, num_boost_round=100)
def rerank(self, query, documents):
"""基于训练模型的文档重排序"""
features = self.prepare_features(query, documents)
scores = self.model.predict(features)
# 按预测相关性分数降序排列
scored_docs = list(zip(documents, scores))
reranked = sorted(scored_docs, key=lambda x: x[1], reverse=True)
return [doc for doc, score in reranked]
实际应用案例与性能分析
某生物医学研究平台采用MonoT5模型构建了专门的科学文献重排序系统:
# 生物医学领域专用重排序管道
class BiomedicalReranker:
def __init__(self):
self.monot5 = MonoT5('castorini/monot5-base-msmarco')
self.citation_network = CitationNetworkAnalyzer()
def rerank_papers(self, query, papers):
# MonoT5基础重排序
t5_scores = self.monot5.rerank(query, papers)
# 基于引文网络的权威性增强
for i, paper in enumerate(papers):
citation_boost = self.citation_network.calculate_authority_score(paper)
t5_scores[i] *= (1 + citation_boost * 0.1)
# 最终排序结果生成
return self.rank_by_scores(papers, t5_scores)
该系统实现了研究人员满意度评分提升50%、相关文献发现时间缩短60%、跨学科论文发现率增长45%的综合效果。
系统实施的最佳实践与性能优化
批量处理优化策略
def efficient_cross_encoder_reranking(query, documents, batch_size=32):
"""优化GPU资源利用的批量文档处理"""
all_scores = []
for i in range(0, len(documents), batch_size):
batch_docs = documents[i:i+batch_size]
batch_inputs = [(query, doc) for doc in batch_docs]
# 批量推理执行
batch_scores = cross_encoder.predict(batch_inputs)
all_scores.extend(batch_scores)
return all_scores
缓存机制设计
from functools import lru_cache
@lru_cache(maxsize=10000)
def cached_rerank(query, doc_hash):
"""重复查询-文档对的结果缓存机制"""
return expensive_reranking_function(query, doc_hash)
评估体系与性能指标
技术性能评估
标准化折扣累积增益(NDCG)作为排序质量的核心评估指标:
def calculate_ndcg(relevance_scores, k=10):
"""NDCG@k排序评估指标计算"""
def dcg(scores):
return sum([(2**score - 1) / np.log2(i + 2)
for i, score in enumerate(scores[:k])])
actual_dcg = dcg(relevance_scores)
ideal_dcg = dcg(sorted(relevance_scores, reverse=True))
return actual_dcg / ideal_dcg if ideal_dcg > 0 else 0.0
平均倒数排名(MRR)用于评估首个相关结果的排序位置:
def calculate_mrr(rankings):
"""多查询场景下的平均倒数排名计算"""
reciprocal_ranks = []
for ranking in rankings:
for i, is_relevant in enumerate(ranking):
if is_relevant:
reciprocal_ranks.append(1.0 / (i + 1))
break
else:
reciprocal_ranks.append(0.0)
return sum(reciprocal_ranks) / len(reciprocal_ranks)
业务影响度量
除技术指标外,关键业务指标包括点击率(CTR)、相关结果发现时间、用户满意度评分以及任务完成率。实践经验表明,NDCG@10指标每提升0.05通常对应用户满意度增长10-15%。然而,业务指标始终应作为重排序系统成功的最终评判标准。
技术选型与决策框架
应用规模分层策略
对于月查询量低于100万的中小型应用,推荐采用MS-MARCO等成熟的交叉编码器模型,备选方案为Cohere API以简化开发复杂度,预算受限情况下可考虑开源T5基础模型。
针对月查询量超过100万的大规模应用,建议采用BM25初检索、密集向量检索、交叉编码器精排的三阶段混合架构,高级方案可选择ColBERTv2以实现规模化高效处理,企业级部署可考虑Azure、AWS、GCP等云服务平台的商业解决方案。
专业领域应用的最佳实践是在领域特定数据集上对现有模型进行微调优化,替代方案为结合领域特征的LambdaMART模型,前沿技术可探索GPT-4的少样本学习能力。
生产级重排序服务架构
from flask import Flask, request, jsonify
import asyncio
import aiohttp
class ProductionRerankingService:
def __init__(self):
self.app = Flask(__name__)
self.cross_encoder = self.load_model()
self.setup_routes()
def load_model(self):
"""生产环境模型加载与优化"""
model = CrossEncoder('ms-marco-MiniLM-L-6-v2')
# 启用FP16精度优化以提升推理速度
model.model.half()
return model
def setup_routes(self):
@self.app.route('/rerank', methods=['POST'])
def rerank_endpoint():
data = request.json
query = data.get('query')
documents = data.get('documents', [])
top_k = data.get('top_k', 10)
try:
# 请求参数验证
if not query or not documents:
return jsonify({'error': 'Missing query or documents'}), 400
# 执行文档重排序
scores = self.cross_encoder.predict([(query, doc) for doc in documents])
# 生成排序结果
ranked_results = [
{'document': doc, 'score': float(score)}
for doc, score in sorted(zip(documents, scores),
key=lambda x: x[1], reverse=True)[:top_k]
]
return jsonify({
'reranked_results': ranked_results,
'query': query,
'total_documents': len(documents)
})
except Exception as e:
return jsonify({'error': str(e)}), 500
def run(self, host='0.0.0.0', port=5000):
self.app.run(host=host, port=port, threaded=True)
# 服务启动入口
if __name__ == "__main__":
service = ProductionRerankingService()
service.run()
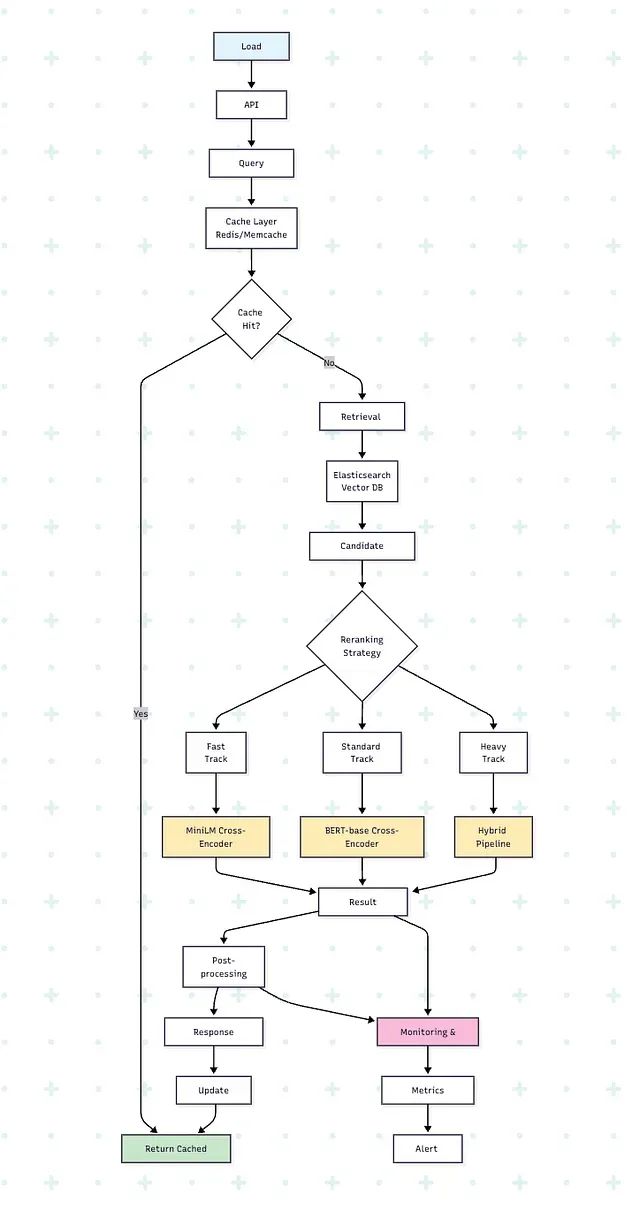
技术问答与解决方案
重排序实施的性能提升预期:相关性评估指标如NDCG@10的典型改进幅度为15-40%,具体效果取决于基线系统的现状。从基础关键词匹配向语义重排序转型通常能够获得最显著的收益。
计算资源开销评估:交叉编码器对50-100个候选文档的重排序处理通常增加100-500毫秒的查询延迟。相比纯检索系统,整体计算需求预计增长2-4倍。
自研与预训练模型的选择策略:建议优先采用MS-MARCO交叉编码器等成熟的预训练模型。仅在拥有超过1万对标注查询-文档数据且存在明确领域特化需求时,才考虑自主训练模型。
多语言处理方案:推荐使用mMARCO、E5-multilingual等多语言预训练模型。为获得最优性能,建议在特定语言对数据上进行微调优化。
总结
重排序模型技术作为信息检索系统性能提升的关键技术手段,为各类搜索和检索应用提供了从交叉编码器的高精度处理到大型语言模型灵活适应能力的全方位解决方案。
本文的核心技术要点包括:优先采用经过验证的模型如MS-MARCO交叉编码器进行系统构建;建立涵盖技术指标(NDCG、MRR)和业务指标(CTR、满意度)的综合评估体系;将重排序视为需要基于用户反馈持续优化的动态系统;通过多种技术方法的有机结合实现效果最大化;在系统设计时充分考虑计算成本、开发周期和维护复杂度等工程因素。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐


 41
41 0
0- 0



 已为社区贡献208条内容
已为社区贡献208条内容

所有评论(0)