
大模型工程化之路:分层架构设计与落地实践(值得收藏)!大模型应用
文章提出企业AI能力应采用分层架构,分为开发工具链层、平台与流水线层、运营治理层和算力框架支撑层。这种架构能明确职责、促进复用、便于治理。文章提供了从POC验证到规模化复制的三步落地路线,强调了数据版本管理、成本控制和业务KPI评估的重要性,旨在将模型研究成果转化为持续的业务价值。
简介
文章提出企业AI能力应采用分层架构,分为开发工具链层、平台与流水线层、运营治理层和算力框架支撑层。这种架构能明确职责、促进复用、便于治理。文章提供了从POC验证到规模化复制的三步落地路线,强调了数据版本管理、成本控制和业务KPI评估的重要性,旨在将模型研究成果转化为持续的业务价值。
如果把企业的 AI 能力比作一棵树,根在算力与架构,干是平台与流程,枝叶则是面向业务的场景应用。很多团队卡在「模型做得不错,但上不去线」的节点,问题往往不是算法本身,而是缺少一套把能力标准化、可复用、可运营的工程化体系。本文把一套实践性强、能直接用作落地参考的分层架构方法写清楚,给产品、研发与运维一个共同的落地语言和路线图。
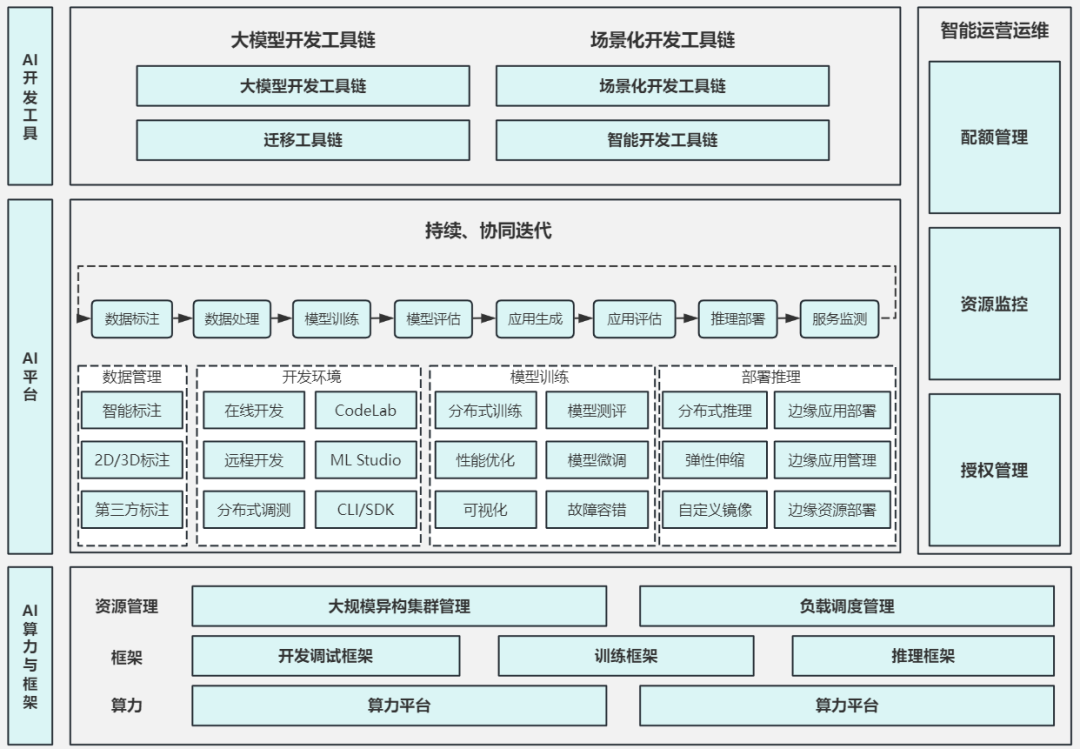
一、为什么需要分层架构?少而精的三个理由
- 职责清晰,降低协同成本:把模型研发、场景化开发、部署运维分层,能让不同团队聚焦自己能做好的事。
- 复用和可扩展:模块化组件(训练流水线、模型仓库、推理服务)在多个业务线之间复用,复制成功变得简单。
- 可观测、可治理:把监控、配额、权限、数据血缘放到平台层,业务使用不再靠口头约定,发生问题可以快速回溯与定位。
二、一个落地友好的分层视角(便于直接复刻)
我们把整个能力分为四个角色明确的层次:开发工具链层、平台与流水线层、运营治理层、以及底层算力与框架支撑。下面按「谁做什么、怎么做」讲清楚每一层该具备的能力,以及实操建议。
1)开发工具链层:把探索变成可复用的能力包
面向两类开发者:模型研究者和场景开发者。要提供的工具包括:
- 大模型开发工具链:支持分布式训练、性能剖析、训练可视化、自动混合精度等,提高训练效率与成本可控性。
- 场景化开发工具链:快速从通用模型落地到客服、合同审阅、商品识别等场景,包括策略管理、后处理、规则引擎。
- 迁移/优化工具链:微调、蒸馏、量化、格式转换(如 ONNX/TorchScript)等,保证模型能部署到云端、边缘或移动端。
- 智能辅助工具:自动标注、数据增强、AutoML、超参搜索,降低探索成本。
实操建议:把这些工具通过 SDK/CLI/可视化平台开放给业务团队,同时保留脚本化接口便于 CI 自动化。
2)平台与流水线层:把实验变成可重复的生产流程
核心是把模型生命周期工程化,形成一条清晰的从数据到服务的流水线:
- 数据管道与标注体系:智能预标注+人工审核、2D/3D/语音的标注能力、第三方标注接入与质量抽检、数据血缘与版本管理。
- 开发环境与实验管理:在线 Notebook、远程开发、分布式调测、CodeLab/ML Studio、CLI/SDK 等,强化可复现性和协作能力。
- 训练与评估模块:分布式训练、性能优化、可视化监控、模型微调、自动化评估与回归测试、故障恢复与检查点管理。
- 应用生成与评估:把模型能力封装成 API/微服务,结合 AB 测试与端到端业务指标评估。
- 推理与部署:支持分布式推理、弹性伸缩、自定义容器镜像、边缘部署与管理(离线/低带宽场景)。
- 服务监控:响应时间、错误率、输入分布漂移、模型精度衰退与日志链路监控。
实操建议:优先把数据与模型版本管理做起来;没有版本控制的模型永远难以稳定运营。
3)运营治理层:把成本、合规与安全纳入体系化管理
企业级必须的三把“阀门”:
- 配额管理:按组织/项目/模型做算力与调用配额,防止费用失控并支持成本中心计费。
- 资源监控:实时监控 GPU/CPU/网络/存储,支持告警与容量预测。
- 授权与审计:用户权限、数据访问、模型使用记录、操作审计,满足合规与安全审查。
实操建议:从第一天开始建立最小权限策略与调用审计,发生问题才有办法追责与修复。
4)算力与框架支撑层:把性能和成本打到一个平衡点
底座决定成本效率和可扩展性,需要考虑:
- 异构算力管理:CPU/GPU/TPU/NPU 等资源池化与任务亲和策略。
- 负载调度与弹性伸缩:任务排队、优先级、弹性扩缩容,保证训练与推理峰值期间的服务质量。
- 统一的训练/推理框架支持:兼容主流深度学习框架,提供企业级优化实现。
刚开始可以选择云上托管与弹性伸缩,成熟后再评估自建混合机房以降低长期成本。
三、数据类型与工程细节:不要把「数据」当成黑盒
企业的输入非常多元:文本、结构化表格、图像/视频、2D/3D 点云、语音、传感器流。对每种类型都要有可复用的处理流水线:采集→清洗→脱敏→特征化→标注→切分→版本化。关键原则:可追溯、可回滚、可审计。
四、三步走落地路线(实战清单)
- 验证场景价值(POC):用预训练模型做快速验证,聚焦一个明确的 KPI(如客服自动回复率提升、合同审核效率提升)。
- 搭建可复用平台能力:上线数据流水线、训练流水线、模型仓库与监控面板,建立模型版本管理与回滚机制。
- 规模化复制与治理:将成功案例复制到其他业务线,落实配额管理、权限审计与成本分摊。
每一步配套小目标:POC <14 天、平台基础能力 3 个月、规模复制 6–12 个月。根据团队规模调整节奏。
五、常见坑与可行的治理策略
- 只看模型指标,不看业务 KPI:上线前必须设计端到端的业务验证,模型 AUC 高不等于业务提升。
- 数据合规被动:从数据采集环节就设限,自动脱敏、权限控制与审计。
- 没有成本意识:GPU 是有限资源,设置配额、定价并监控使用。
- 版本地狱:代码、模型、数据都必须强制版本化并支持回滚。
解决之道在于「制度 + 平台 + 文化」三位一体:把好的流程写进平台,写进 SLO,并形成日常检查与责任人。
六、一个小案例(把概念落地成可复刻的操作)
假设你负责把合同审阅自动化做成产品:
- POC(2 周):用预训练模型做关键词抽取 + 简单分类,评估自动拦截率与减少人工时长。
- 平台化(2–3 个月):把数据标注流程、微调流水线、模型仓库做成组件,开放 API 给法务系统;上线监控,检测模型输出是否有偏差。
- 复制(6 个月):把相同模式的“审阅模板”复制到采购合同、合作协议等,配额与权限由法务中心统筹。
从单点工具变成法务中台能力,每新增一个合同类型的迭代成本显著下降。
七、总结
我们要的是把「能力」变成「产品」,成功不是把最先进的模型丢进业务里,而是把模型能力工程化、平台化并纳入治理机制。把责任、度量与工具标准化,才能把一次性的研究成果转化为持续的业务价值。若你正在准备把某个场景推上生产线,可以把你的场景、当前卡点发给我——我可以帮你把落地步骤拆成可执行的周计划,或者给出对应的管线与监控模板。
八、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

更多推荐
 15
15 0
0- 0



 已为社区贡献317条内容
已为社区贡献317条内容

所有评论(0)