颠覆!提示工程架构师颠覆AI提示系统用户行为预测传统
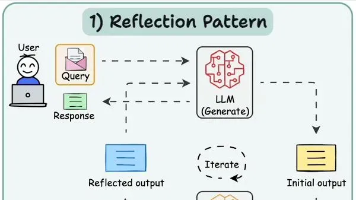
提示工程架构师是AI系统与用户意图之间的桥梁设计者,其核心使命是通过提示工程策略,使AI系统能够理解、推理和预测用户行为。LLM与提示工程专长:深入理解LLM原理,掌握提示设计模式(如Few-Shot Learning、Chain-of-Thought等)用户心理学与行为分析:理解用户决策过程、认知偏差和行为动机系统架构设计:设计支持动态提示生成、上下文管理和反馈循环的系统跨学科协作:与数据科学家
颠覆!提示工程架构师颠覆AI提示系统用户行为预测传统

引言:AI系统的"导航难题"与提示工程的颠覆性解决方案
在当今数字化时代,每一次用户与AI系统的交互都像是一次航行——用户带着需求启程,AI系统则需要精准预测用户的下一步行动,才能提供无缝的导航体验。从电商平台的商品推荐、智能客服的问题预判,到教育科技的个性化学习路径规划,用户行为预测已成为AI系统智能化程度的核心标志。
然而,传统用户行为预测方法正面临着前所未有的挑战。根据Gartner 2023年报告,尽管85%的企业投入资源开发用户行为预测系统,但仅有12%能够实现超过70%的预测准确率。这一巨大落差背后,是传统方法难以逾越的三座大山:
- 数据饥饿症:依赖大规模标注数据,在冷启动场景下性能骤降
- 上下文感知缺失:无法有效捕捉用户行为背后的复杂意图和环境因素
- 静态模型困境:难以适应用户行为模式的动态变化,更新迭代周期长
就在行业深陷这些困境之时,提示工程架构师(Prompt Engineering Architect)这一新兴角色横空出世,正以革命性的方式重塑AI提示系统中的用户行为预测范式。他们不只是提示词的编写者,更是AI系统与用户意图之间的"翻译官"和"导航员",通过精心设计的提示策略,使AI系统能够像人类专家一样理解、推理和预测用户行为。
本博客将带你深入探索这一颠覆性变革:从传统用户行为预测的原理与局限,到提示工程架构师如何运用提示工程、大语言模型(LLM)和上下文感知技术构建下一代预测系统。我们将通过数学建模、代码实战和真实案例,全方位展示这一变革的技术内核与商业价值。无论你是AI工程师、产品经理还是技术决策者,本文都将为你打开一扇通往AI系统智能化新纪元的大门。
第一章:传统用户行为预测的"阿喀琉斯之踵"
1.1 用户行为预测:AI系统的"第六感"
用户行为预测是指通过分析用户历史交互数据,预测其未来行为倾向的技术。在AI系统中,这一能力相当于赋予机器"第六感",使其能够:
- 预判需求:在用户明确表达前提供所需服务(如搜索引擎的自动补全)
- 个性化推荐:根据用户偏好推荐内容、商品或服务
- 异常检测:识别欺诈行为、系统滥用或用户困惑
- 流程优化:简化用户操作路径,减少交互摩擦
从技术本质看,用户行为预测是一种时序决策问题,核心在于从历史行为序列中提取模式,并推断未来状态。传统方法在过去十年中取得了显著进展,但随着AI系统复杂度提升和用户需求多元化,其局限性日益凸显。
1.2 传统方法的技术原理与数学基础
传统用户行为预测主要基于三类技术路径:统计模型、机器学习模型和深度学习模型。让我们逐一解析其原理、数学表达及固有局限。
1.2.1 统计模型:从概率分布到马尔可夫链
马尔可夫链模型(Markov Chain, MC)是最简单也最经典的行为预测方法之一。其核心假设是"无记忆性":未来状态仅取决于当前状态,与过去无关。
数学上,一个马尔可夫链由状态空间 ( S = {s_1, s_2, …, s_n} ) 和转移概率矩阵 ( P ) 定义,其中 ( P_{ij} = P(s_{t+1}=j | s_t=i) ) 表示从状态 ( i ) 转移到状态 ( j ) 的概率。
对于用户行为预测,状态通常代表用户操作(如点击、浏览、购买),转移概率通过历史数据估计:
Pij=Nij∑kNik P_{ij} = \frac{N_{ij}}{\sum_k N_{ik}} Pij=∑kNikNij
其中 ( N_{ij} ) 是从状态 ( i ) 转移到 ( j ) 的次数。
隐马尔可夫模型(Hidden Markov Model, HMM)则引入了隐藏状态,假设可观测行为由隐藏状态生成。其数学表达涉及两个概率分布:
- 状态转移概率:( a_{ij} = P(q_{t+1}=j | q_t=i) )
- 观测概率:( b_j(k) = P(o_t=k | q_t=j) )
HMM通过前向-后向算法(Forward-Backward Algorithm)进行参数估计和状态预测。
1.2.2 机器学习模型:从特征工程到序列分类
随着数据量增长,逻辑回归(Logistic Regression)、支持向量机(SVM)和随机森林(Random Forest)等机器学习模型被广泛应用于行为预测。这些方法将行为预测转化为分类或回归问题:
- 分类任务:预测用户是否会执行特定行为(如点击:1-点击,0-不点击)
- 回归任务:预测行为发生的概率或时间
以逻辑回归为例,对于用户行为序列 ( x = (x_1, x_2, …, x_m) ),通过特征工程提取特征向量 ( \phi(x) ),预测行为发生概率:
P(y=1∣ϕ(x))=σ(wTϕ(x)+b)=11+e−(wTϕ(x)+b) P(y=1 | \phi(x)) = \sigma(w^T \phi(x) + b) = \frac{1}{1 + e^{-(w^T \phi(x) + b)}} P(y=1∣ϕ(x))=σ(wTϕ(x)+b)=1+e−(wTϕ(x)+b)1
其中 ( \sigma ) 是sigmoid函数,( w ) 和 ( b ) 是模型参数。
1.2.3 深度学习模型:从RNN到注意力机制
深度学习的兴起推动了行为预测技术的发展,特别是循环神经网络(RNN)及其变体LSTM(Long Short-Term Memory)和GRU(Gated Recurrent Unit),能够直接处理序列数据:
LSTM通过门控机制(输入门、遗忘门、输出门)解决RNN的梯度消失问题,其单元状态更新公式为:
it=σ(Wxixt+Whiht−1+bi)(输入门)ft=σ(Wxfxt+Whfht−1+bf)(遗忘门)ot=σ(Wxoxt+Whoht−1+bo)(输出门)C~t=tanh(WxCxt+WhCht−1+bC)(候选状态)Ct=ft⊙Ct−1+it⊙C~t(细胞状态)ht=ot⊙tanh(Ct)(隐藏状态) \begin{align*} i_t &= \sigma(W_{xi}x_t + W_{hi}h_{t-1} + b_i) \quad \text{(输入门)} \\ f_t &= \sigma(W_{xf}x_t + W_{hf}h_{t-1} + b_f) \quad \text{(遗忘门)} \\ o_t &= \sigma(W_{xo}x_t + W_{ho}h_{t-1} + b_o) \quad \text{(输出门)} \\ \tilde{C}_t &= \tanh(W_{xC}x_t + W_{hC}h_{t-1} + b_C) \quad \text{(候选状态)} \\ C_t &= f_t \odot C_{t-1} + i_t \odot \tilde{C}_t \quad \text{(细胞状态)} \\ h_t &= o_t \odot \tanh(C_t) \quad \text{(隐藏状态)} \end{align*} itftotC~tCtht=σ(Wxixt+Whiht−1+bi)(输入门)=σ(Wxfxt+Whfht−1+bf)(遗忘门)=σ(Wxoxt+Whoht−1+bo)(输出门)=tanh(WxCxt+WhCht−1+bC)(候选状态)=ft⊙Ct−1+it⊙C~t(细胞状态)=ot⊙tanh(Ct)(隐藏状态)
最终行为预测概率通常通过全连接层输出:
y^t=softmax(Woht+bo) \hat{y}_t = \text{softmax}(W_o h_t + b_o) y^t=softmax(Woht+bo)
近年来,Transformer架构也被应用于行为预测,其自注意力机制(Self-Attention)能够捕捉长序列中的依赖关系:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V Attention(Q,K,V)=softmax(dkQKT)V
其中 ( Q, K, V ) 分别是查询、键和值矩阵,( d_k ) 是键向量维度。
1.3 传统方法的四大核心局限
尽管传统方法在特定场景下表现良好,但它们共同面临着四个难以克服的"阿喀琉斯之踵":
1.3.1 数据饥饿与冷启动困境
传统模型严重依赖大规模标注数据,尤其是深度学习模型。根据经验法则,一个LSTM模型通常需要至少数千甚至数万用户的交互数据才能达到基本预测效果。这导致两大问题:
- 新用户/新系统冷启动:缺乏历史数据时预测效果急剧下降
- 数据稀疏性:长尾用户或低频行为的数据不足,难以建模
数学上,这源于传统模型的参数学习范式:模型参数需要通过数据拟合,数据不足导致参数估计偏差。以逻辑回归为例,当特征 ( \phi(x) ) 对应的样本稀少时,权重 ( w ) 的估计方差增大:
Var(w^)=(ΦTΦ)−1σ2 \text{Var}(\hat{w}) = (\Phi^T \Phi)^{-1} \sigma^2 Var(w^)=(ΦTΦ)−1σ2
其中 ( \Phi ) 是特征矩阵,当 ( \Phi^T \Phi ) 接近奇异矩阵(数据稀疏时),方差将趋于无穷大。
1.3.2 上下文感知能力缺失
传统模型处理上下文信息的能力有限:
- 马尔可夫链:仅考虑当前状态,忽略长期上下文
- RNN/LSTM:虽能处理序列,但对长程依赖捕捉能力有限,且难以建模非时序上下文(如用户设备、时间、地点)
- 特征工程依赖:上下文信息需手动设计为特征,难以全面捕捉复杂场景
例如,用户在"工作日早晨通勤时"和"周末晚上在家时"搜索相同关键词,意图可能截然不同,但传统模型往往无法区分这些情境差异。
1.3.3 静态模型与动态行为的矛盾
用户行为模式并非一成不变,而是随时间、场景和体验动态演变:
- 短期变化:用户兴趣的临时波动(如节假日购物行为)
- 中期变化:季节性偏好调整(如夏季对冷饮的偏好)
- 长期变化:用户生命周期阶段迁移(如从学生到职场人士)
传统模型通常是静态的,一旦训练完成,模型参数固定,难以适应行为模式变化。虽有在线学习(Online Learning)方法尝试解决这一问题,但面临概念漂移(Concept Drift)和模型稳定性的平衡难题。
1.3.4 可解释性与预测准确性的权衡
传统模型存在"黑箱困境":
- 简单模型(如逻辑回归、马尔可夫链)可解释性强,但表达能力有限
- 复杂模型(如深度神经网络)预测准确性高,但决策过程不透明
这在关键业务场景(如金融风控、医疗诊断)中带来严重问题:当预测出错时,无法追溯原因;当需要人工干预时,缺乏决策依据。
1.4 案例分析:传统推荐系统的行为预测失效
让我们通过一个电商推荐系统案例,具体看传统方法的局限性如何影响实际业务效果。
场景:某电商平台使用基于协同过滤(Collaborative Filtering, CF)和LSTM的混合模型预测用户购买行为。
问题表现:
- 新用户注册后,推荐列表充斥热门商品,缺乏个性化
- 当用户浏览类别A商品后突然查看类别B商品(如从"运动鞋"到"笔记本电脑"),系统仍持续推荐类别A
- 季节性商品(如防晒霜)在冬季仍被推荐给曾在夏季购买的用户
- 系统无法解释为什么推荐某商品,客服无法向用户解释推荐逻辑
技术根源:
- 协同过滤依赖用户-商品交互矩阵,新用户无数据(冷启动)
- LSTM虽能捕捉序列依赖,但无法理解"用户为朋友购买礼物"等情境意图
- 模型更新周期为每周一次,无法实时响应用户行为变化
- 深度神经网络的黑箱性质导致可解释性缺失
这个案例揭示了传统用户行为预测方法在面对动态、情境化、数据稀疏的真实世界场景时的无力感。正是这些痛点催生了提示工程架构师的崛起,他们带来了一种全新的思维方式和技术路径。
第二章:提示工程架构师:AI预测系统的"新物种"
2.1 从提示工程师到提示工程架构师
随着大语言模型(LLM)的普及,“提示工程师”(Prompt Engineer)已广为人知——他们通过设计提示词来引导LLM生成特定输出。然而,提示工程架构师是一个更复杂、更全面的角色,他们不仅懂提示设计,更具备系统思维、用户理解和架构设计能力。
2.1.1 角色定义与核心能力
提示工程架构师是AI系统与用户意图之间的桥梁设计者,其核心使命是通过提示工程策略,使AI系统能够理解、推理和预测用户行为。他们需要融合以下四大能力:
- LLM与提示工程专长:深入理解LLM原理,掌握提示设计模式(如Few-Shot Learning、Chain-of-Thought等)
- 用户心理学与行为分析:理解用户决策过程、认知偏差和行为动机
- 系统架构设计:设计支持动态提示生成、上下文管理和反馈循环的系统
- 跨学科协作:与数据科学家、产品经理和工程师合作,将业务需求转化为提示策略
2.1.2 与传统角色的区别
| 角色 | 核心关注点 | 工具/方法 | 输出物 |
|---|---|---|---|
| 数据科学家 | 模型优化与参数调优 | 统计分析、机器学习 | 预测模型、性能指标 |
| 提示工程师 | 提示词优化 | 提示模板、示例设计 | 高效提示词 |
| 提示工程架构师 | 系统级用户意图理解 | 提示策略、上下文管理、LLM集成 | 用户行为预测系统、提示工程框架 |
简而言之,提示工程架构师不只是"写提示词",而是设计基于提示的用户行为预测系统,将LLM的通用智能转化为特定场景的预测能力。
2.2 提示工程驱动的用户行为预测:核心原理
提示工程架构师颠覆传统预测方法的核心在于范式转变:从"数据驱动的参数学习"转向"知识驱动的推理预测"。具体而言,这一转变基于以下四大原理:
2.2.1 利用LLM的世界知识与推理能力
大语言模型通过预训练已内化了海量世界知识(World Knowledge)和推理模式(Reasoning Patterns)。提示工程架构师的关键洞察是:这些知识可被用于用户行为预测,减少对特定场景标注数据的依赖。
例如,当预测用户对"户外烧烤架"的购买意图时,LLM可利用其内置知识:
- 烧烤架通常在夏季、节假日需求增加
- 购买烧烤架的用户可能还需要木炭、烤叉等配件
- 居住在公寓的用户可能更倾向于小型电烤架
这些知识无需通过数据重新学习,而是通过精心设计的提示引导LLM应用到预测任务中。
2.2.2 上下文感知的动态提示生成
传统模型的输入是固定格式的特征向量,而提示工程架构师设计的系统能够生成动态提示,实时整合多种上下文信息:
用户当前行为: 浏览"户外烧烤架"商品页面
用户历史: 过去30天浏览过"露营装备"、"户外折叠桌椅"
时间上下文: 当前是6月15日(夏季),周六
用户属性: 住在带花园的独栋房屋,家庭用户
基于以上信息,预测用户接下来可能的行为(购买/收藏/查看评论/离开),并解释原因。
这种动态提示使AI系统能像人类顾问一样,综合多维度信息进行预测,而非局限于固定特征。
2.2.3 从行为序列到意图推理
传统方法将用户行为视为统计模式,而提示工程架构师将其视为意图表达(Intent Expression)。预测任务因此从"预测下一个行为"升级为"推断用户意图并预测实现意图的行为"。
这一转变的数学表达是从"行为序列预测"到"意图-行为映射":
传统方法:( P(a_{t+1} | a_1, a_2, …, a_t) )(行为序列概率)
提示工程方法:( P(a_{t+1} | I_t, C_t) ),其中 ( I_t = \text{Intent}(a_1,…,a_t, C_t) )(意图),( C_t )(上下文)
意图推理使系统能处理行为歧义(同一行为可能对应不同意图)和行为稀疏性(相似意图可通过不同行为表达)。
2.2.4 闭环反馈与提示迭代优化
提示工程架构师设计的系统包含闭环反馈机制:预测结果被用于优化未来提示,形成"预测-反馈-优化"的学习循环。这解决了传统模型静态性问题,使系统能适应用户行为变化。
数学上,这可表示为提示策略的迭代更新:
πk+1=πk+α∇πL(πk,fk) \pi_{k+1} = \pi_k + \alpha \nabla_\pi \mathcal{L}(\pi_k, f_k) πk+1=πk+α∇πL(πk,fk)
其中 ( \pi_k ) 是第k轮的提示策略,( f_k ) 是反馈信号(如预测准确率),( \alpha ) 是学习率,( \mathcal{L} ) 是损失函数。
2.3 提示工程预测系统的技术架构
提示工程架构师设计的用户行为预测系统通常包含五大核心组件,形成完整的预测闭环:
2.3.1 用户交互数据收集
收集多维度用户交互数据,包括:
- 行为数据:点击、浏览、搜索、购买、停留时间等
- 内容数据:用户查看的文本、图像、视频内容
- 上下文数据:时间、地点、设备、网络环境
- 反馈数据:用户对预测结果的显式反馈(如"不感兴趣")
这些数据通常通过前端埋点、API日志或专用追踪系统收集,存储在时序数据库(如InfluxDB、TimescaleDB)中。
2.3.2 上下文提取与预处理
从原始数据中提取结构化上下文特征(Context Features),如:
- 用户当前会话的行为序列
- 关键实体(如查看的商品ID、搜索关键词)
- 时间特征(如是否周末、是否节假日、时间段)
- 用户画像特征(如历史偏好、生命周期阶段)
预处理通常包括实体识别、意图分类和特征选择,可使用轻量级NLP模型(如BERT-base)或规则引擎实现。
2.3.3 动态提示生成器
根据上下文特征动态生成预测提示,是系统的"大脑"。提示工程架构师需设计提示模板(Prompt Template)和提示策略(Prompt Strategy),使生成的提示能够:
- 清晰定义预测任务和输出格式
- 有效整合上下文信息
- 引导LLM应用相关知识和推理能力
- 生成可解释的预测结果
提示生成器通常实现为模板引擎(如Jinja2)与规则引擎的组合,根据不同场景动态调整提示内容。
2.3.4 LLM与推理引擎
负责执行提示并生成预测结果的核心组件,通常包括:
- LLM选择器:根据任务复杂度和延迟要求选择合适的LLM(如GPT-4用于复杂推理,Llama 2-7B用于实时预测)
- 推理调度器:管理LLM调用队列、缓存重复请求、处理速率限制
- 输出解析器:将LLM生成的自然语言转换为结构化预测结果(如JSON格式的行为概率分布)
2.3.5 提示策略优化器
通过反馈信号持续优化提示策略的组件,核心技术包括:
- A/B测试框架:比较不同提示模板的预测效果
- 强化学习:基于反馈信号(如点击率、转化率)优化提示参数
- 提示挖掘:从高质量预测案例中提取有效提示模式
优化器使系统能够自适应用户行为变化,不断提升预测准确性。
2.4 颠覆传统的五大技术优势
与传统方法相比,提示工程架构师设计的预测系统具有以下五大优势,彻底改变了用户行为预测的技术格局:
2.4.1 冷启动能力:零数据预测
传统模型在缺乏数据时表现极差,而提示工程系统可利用LLM的先验知识实现"零数据预测"。例如,为新电商平台设计的预测系统,无需历史交易数据,即可基于LLM对商品属性、季节因素和用户行为模式的理解进行初步预测。
数学上,这相当于在传统模型的预测概率中引入先验分布 ( P(a | K) ),其中 ( K ) 是LLM的世界知识:
P(a∣D,K)=P(D∣a,K)P(a∣K)P(D∣K) P(a | D, K) = \frac{P(D | a, K) P(a | K)}{P(D | K)} P(a∣D,K)=P(D∣K)P(D∣a,K)P(a∣K)
当数据 ( D ) 稀缺时,后验概率 ( P(a | D, K) ) 主要由先验 ( P(a | K) ) 决定,而LLM提供了高质量的先验知识。
2.4.2 上下文理解:从"行为"到"意图"
提示工程系统能理解复杂上下文,包括:
- 多模态信息(文本、图像、用户行为的组合)
- 长期与短期上下文的结合
- 隐含的情境信息(如用户浏览商品时的犹豫表现)
例如,当用户在手机上反复比较两款价格相近的笔记本电脑时,系统可推断其"决策困难"状态,预测需要"产品对比"或"专家建议"的辅助功能,而非直接预测购买行为。
2.4.3 动态适应:实时响应行为变化
传统模型更新周期长(通常天或周级别),而提示工程系统可实现实时适应:
- 提示策略可即时调整,无需重新训练模型
- 可根据用户近期行为快速更新上下文理解
- 支持A/B测试新的预测逻辑,几分钟内评估效果
这一优势使系统能有效应对季节性变化、突发事件或用户兴趣转移。
2.4.4 可解释性:预测+原因
传统黑箱模型只能提供"是什么"的预测,而提示工程系统可同时提供"为什么"的解释。例如:
{
"predicted_behavior": "purchase",
"confidence": 0.85,
"explanation": "用户已连续3天浏览户外烧烤架,当前是夏季周末,且用户历史上在类似情境下购买过户外用品。预测用户今天有85%的概率完成购买。"
}
这种预测+解释的输出格式不仅提升用户信任,也为人工干预提供了依据。
2.4.5 知识注入:灵活整合领域知识
提示工程架构师可通过提示轻松注入领域知识(Domain Knowledge)和业务规则(Business Rules),无需修改模型或重新训练。例如:
- 在金融风控场景:“预测用户是否为欺诈交易时,请考虑以下规则:异地登录且大额转账的欺诈风险增加50%”
- 在教育科技场景:“预测学生是否需要提示时,如果问题涉及微积分且学生过去3次同类问题答错,提示需求增加”
这种知识注入能力使系统能快速适应特定领域的专业要求。
第三章:数学建模:提示工程预测系统的理论基础
3.1 提示工程预测的概率框架
提示工程架构师设计的用户行为预测系统虽基于LLM,但其背后仍有坚实的数学基础。我们可将其建模为贝叶斯推理过程,其中提示扮演着"知识先验"和"推理引导"的双重角色。
3.1.1 基于提示的行为预测概率模型
从贝叶斯角度,用户行为预测可表示为:
P(at+1∣Ht,Ct,P)=P(at+1,Ht,Ct∣P)P(Ht,Ct∣P) P(a_{t+1} | H_t, C_t, P) = \frac{P(a_{t+1}, H_t, C_t | P)}{P(H_t, C_t | P)} P(at+1∣Ht,Ct,P)=P(Ht,Ct∣P)P(at+1,Ht,Ct∣P)
其中:
- ( a_{t+1} ):预测的未来行为
- ( H_t ):用户历史行为序列(( a_1, a_2, …, a_t ))
- ( C_t ):当前上下文(时间、地点、设备等)
- ( P ):提示(Prompt)
通过贝叶斯法则展开,可得:
P(at+1∣Ht,Ct,P)∝P(Ht,Ct∣at+1,P)P(at+1∣P) P(a_{t+1} | H_t, C_t, P) \propto P(H_t, C_t | a_{t+1}, P) P(a_{t+1} | P) P(at+1∣Ht,Ct,P)∝P(Ht,Ct∣at+1,P)P(at+1∣P)
其中:
- ( P(a_{t+1} | P) ):提示引导的先验概率(LLM的知识)
- ( P(H_t, C_t | a_{t+1}, P) ):似然概率(给定未来行为和提示,观察到历史行为和上下文的概率)
提示工程架构师的核心任务是设计 ( P ),使LLM能准确估计这两个概率项,从而得到最优预测 ( \hat{a}_{t+1} = \arg\max_a P(a | H_t, C_t, P) )。
3.1.2 提示作为概率分布的"修正器"
传统模型的先验通常是简单的均匀分布或经验分布,而提示工程架构师通过设计提示 ( P ),可以定制先验分布 ( P(a | P) ),将领域知识、业务规则和上下文信息编码为概率偏见。
数学上,提示可视为对基础分布 ( P_0(a) )(LLM无提示时的行为分布)的修正:
P(a∣P)=P0(a)exp(λ⋅U(a,P))Z(P) P(a | P) = \frac{P_0(a) \exp(\lambda \cdot U(a, P))}{Z(P)} P(a∣P)=Z(P)P0(a)exp(λ⋅U(a,P))
其中:
- ( U(a, P) ):提示 ( P ) 对行为 ( a ) 的效用函数(Utility Function)
- ( \lambda ):提示强度参数(控制提示对分布的影响程度)
- ( Z§ ):归一化常数,确保 ( \sum_a P(a | P) = 1 )
例如,当提示包含"夏季烧烤架需求增加"时,( U(\text{purchase_grill}, P) ) 将取较高值,使 ( P(\text{purchase_grill} | P) ) 增大。
3.2 提示工程中的序列行为建模
用户行为本质上是时间序列数据,提示工程架构师需设计特殊提示策略来捕捉序列中的依赖关系。我们提出两种数学模型:提示增强的马尔可夫链和提示引导的注意力模型。
3.2.1 提示增强的马尔可夫链(Prompt-Enhanced Markov Chain, PEMC)
传统马尔可夫链的转移概率 ( P(a_{t+1} | a_t) ) 仅依赖当前行为,而PEMC通过提示将上下文和历史行为融入转移概率:
P(at+1∣at,H1:t−1,Ct,P)=fLLM(Ptemplate(at,H1:t−1,Ct)) P(a_{t+1} | a_t, H_{1:t-1}, C_t, P) = f_{\text{LLM}}(P_{\text{template}}(a_t, H_{1:t-1}, C_t)) P(at+1∣at,H1:t−1,Ct,P)=fLLM(Ptemplate(at,H1:t−1,Ct))
其中 ( P_{\text{template}} ) 是提示模板,( f_{\text{LLM}} ) 是LLM的概率输出函数。
一个具体的提示模板示例:
当前行为: {{a_t}} (浏览烧烤架商品页面)
历史行为: {{H_{1:t-1}}} (搜索"户外烹饪设备", 浏览"便携式烤炉")
上下文: {{C_t}} (周六下午, 位于郊区)
基于以上信息,用户下一步可能的行为是(A. 查看商品详情 B. 添加到购物车 C. 返回搜索 D. 查看评论)?请给出每个选项的概率。
LLM处理此提示后,将输出一个概率分布 ( P(a_{t+1} | \cdot) ),作为PEMC的转移概率。
与传统MC相比,PEMC的优势在于:
- 转移概率动态依赖完整历史和上下文,突破"无记忆性"限制
- 可通过提示注入外部知识(如"周六下午购物意愿更高")
- 无需预计算转移矩阵,可实时适应新行为类型
3.2.2 提示引导的注意力模型(Prompt-Guided Attention Model, PGAM)
对于长序列行为预测,提示工程架构师可设计提示引导LLM的注意力机制,关注序列中的关键行为和上下文:
αi(t)=Attention(Pquery,hi) \alpha_i^{(t)} = \text{Attention}(P_{\text{query}}, h_i) αi(t)=Attention(Pquery,hi)
其中:
- ( \alpha_i^{(t)} ):第i个历史行为的注意力权重
- ( P_{\text{query}} ):提示生成的查询向量(如"找出影响用户购买决定的关键行为")
- ( h_i ):第i个历史行为的表示向量
最终行为预测概率为:
P(at+1∣Ht,Ct,P)=softmax(Wo(∑i=1tαi(t)hi)+bo) P(a_{t+1} | H_t, C_t, P) = \text{softmax}(W_o (\sum_{i=1}^t \alpha_i^{(t)} h_i) + b_o) P(at+1∣Ht,Ct,P)=softmax(Wo(i=1∑tαi(t)hi)+bo)
提示引导的注意力使系统能:
- 自动识别序列中的关键行为(如"价格比较"、“优惠券查看”)
- 忽略噪声行为(如误点击)
- 根据上下文动态调整注意力权重(如在促销日更关注"折扣信息查看"行为)
3.3 提示工程优化的数学表达
提示策略优化是提升预测性能的关键,可建模为目标函数最大化问题。设预测系统的目标是最大化预期奖励 ( R )(如点击率、转化率),则优化问题为:
maxP∈PE[R∣P] \max_{P \in \mathcal{P}} \mathbb{E}[R | P] P∈PmaxE[R∣P]
其中 ( \mathcal{P} ) 是可能的提示空间。
3.3.1 基于梯度的提示优化
当提示可参数化表示时(如连续嵌入空间中的提示向量),可使用梯度下降法优化:
P∗=argmaxPE[R∣P] P^* = \arg\max_P \mathbb{E}[R | P] P∗=argPmaxE[R∣P]
∇PE[R∣P]=∫∇PP(a∣P)R(a)da \nabla_P \mathbb{E}[R | P] = \int \nabla_P P(a | P) R(a) da ∇PE[R∣P]=∫∇PP(a∣P)R(a)da
实际中,这可通过提示调优(Prompt Tuning)实现:冻结LLM参数,仅优化提示嵌入向量。数学上,提示嵌入 ( \theta_P ) 通过以下损失函数优化:
L(θP)=−E[logP(a∣prompt(θP),H,C)⋅R(a)] \mathcal{L}(\theta_P) = -\mathbb{E}[\log P(a | \text{prompt}(\theta_P), H, C) \cdot R(a)] L(θP)=−E[logP(a∣prompt(θP),H,C)⋅R(a)]
3.3.2 基于强化学习的提示策略优化
对于离散提示空间(如不同提示模板),可使用强化学习(RL)优化提示策略 ( \pi(P | H, C) )(给定历史和上下文选择提示的策略)。
目标是最大化累积奖励:
J(π)=Eπ[RT]=Eπ[∑t=1Tγt−1Rt] J(\pi) = \mathbb{E}_{\pi}[R_T] = \mathbb{E}_{\pi}[\sum_{t=1}^T \gamma^{t-1} R_t] J(π)=Eπ[RT]=Eπ[t=1∑Tγt−1Rt]
其中 ( \gamma ) 是折扣因子,( R_t ) 是第t步的即时奖励。
常用的算法包括策略梯度(Policy Gradient)和Q-学习(Q-Learning)。例如,策略梯度更新公式为:
∇θJ(θ)=Eπθ[∇θlogπθ(P∣H,C)⋅Qπ(P,H,C)] \nabla_\theta J(\theta) = \mathbb{E}_{\pi_\theta}[\nabla_\theta \log \pi_\theta(P | H, C) \cdot Q^\pi(P, H, C)] ∇θJ(θ)=Eπθ[∇θlogπθ(P∣H,C)⋅Qπ(P,H,C)]
其中 ( Q^\pi(P, H, C) ) 是状态-动作值函数,表示在给定历史 ( H )、上下文 ( C ) 时使用提示 ( P ) 的预期累积奖励。
3.4 不确定性量化与置信度估计
提示工程架构师不仅关注预测准确性,还需评估预测的不确定性(Uncertainty),以:
- 避免过度自信的错误预测
- 决定何时需要人工干预
- 优化资源分配(如将高不确定性预测分配给专家处理)
3.4.1 提示引导的不确定性量化
通过设计特定提示,可引导LLM生成行为概率分布而非单点预测:
请为以下用户行为预测提供概率分布,总和为100%:
1. 购买烧烤架: ___%
2. 查看用户评论: ___%
3. 比较其他品牌: ___%
4. 离开页面: ___%
LLM输出的概率分布 ( P(a | P) ) 可用于计算预测熵(Predictive Entropy),量化不确定性:
H(P)=−∑aP(a∣P)logP(a∣P) H(P) = -\sum_a P(a | P) \log P(a | P) H(P)=−a∑P(a∣P)logP(a∣P)
熵值越高,预测不确定性越大。例如,均匀分布 ( P(a) = 0.25 ) 对所有行为的熵为 ( H = -\sum 0.25 \log 0.25 = 2 \log 2 \approx 1.386 ),表示高度不确定;而确定性分布 ( P(a^*) = 1 ) 的熵为0。
3.4.2 贝叶斯提示工程(Bayesian Prompt Engineering)
更高级的方法是贝叶斯提示工程,通过多个相关提示生成后验分布:
P(a∣P1,P2,...,PK)=1K∑k=1KP(a∣Pk) P(a | P_1, P_2, ..., P_K) = \frac{1}{K} \sum_{k=1}^K P(a | P_k) P(a∣P1,P2,...,PK)=K1k=1∑KP(a∣Pk)
其中 ( P_1, …, P_K ) 是围绕同一预测任务的不同提示(如措辞变化、强调不同上下文)。这种方法通过提示多样性(Prompt Diversity)捕捉认知不确定性,类似于贝叶斯模型平均(Bayesian Model Averaging)。
例如,对于烧烤架购买预测,可设计K个提示,每个强调不同上下文(时间、历史行为、季节因素),然后平均其输出概率得到更稳健的预测分布。
第四章:项目实战:构建提示工程驱动的用户行为预测系统
4.1 项目概述与目标
在本章中,我们将从零开始构建一个提示工程驱动的用户行为预测系统,预测电商平台用户的购买意图。通过这个实战项目,你将掌握提示工程架构师的核心技能:提示设计、LLM集成、上下文管理和系统评估。
项目目标:预测用户在浏览商品页面后的下一步行为,包括:
- 购买商品(Purchase)
- 添加到购物车(Add to Cart)
- 查看评论(View Reviews)
- 离开页面(Leave)
技术栈:
- 后端框架:Python 3.9+, FastAPI
- LLM集成:LangChain, OpenAI API (GPT-4)
- 数据处理:Pandas, NumPy
- 数据库:SQLite (存储用户行为数据)
- 前端演示:Gradio (快速构建交互界面)
- 评估工具:Scikit-learn (计算准确率、F1分数)
4.2 开发环境搭建
让我们一步一步搭建开发环境:
4.2.1 创建虚拟环境并安装依赖
# 创建虚拟环境
python -m venv prompt-behavior-env
source prompt-behavior-env/bin/activate # Linux/Mac
# 或
prompt-behavior-env\Scripts\activate # Windows
# 安装依赖包
pip install fastapi uvicorn langchain openai pandas numpy scikit-learn gradio python-dotenv
4.2.2 配置API密钥与环境变量
创建.env文件,存储敏感信息:
OPENAI_API_KEY=your_openai_api_key_here
DATABASE_URL=sqlite:///user_behavior.db
LLM_MODEL=gpt-4 # 或 gpt-3.5-turbo 用于更快/更便宜的开发
LOG_LEVEL=INFO
4.2.3 项目结构设计
prompt-behavior-prediction/
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPI应用入口
│ ├── database.py # 数据库连接与模型
│ ├── prompt_engine.py # 提示生成与优化
│ ├── llm_service.py # LLM调用服务
│ ├── behavior_tracker.py # 用户行为跟踪
│ └── api/ # API路由
│ ├── __init__.py
│ └── predict.py # 预测接口
├── data/ # 示例数据
│ └── user_behavior_sample.csv
├── notebooks/ # Jupyter notebooks
│ └── exploratory_analysis.ipynb
├── tests/ # 单元测试
├── .env # 环境变量
├── requirements.txt # 依赖列表
└── README.md
4.3 数据收集与预处理
用户行为数据是预测系统的输入基础,我们需要设计数据模型并实现数据收集功能。
4.3.1 数据模型设计
在app/database.py中定义用户行为数据模型:
from sqlalchemy import create_engine, Column, Integer, String, Float, DateTime, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from datetime import datetime
import os
from dotenv import load_dotenv
load_dotenv()
DATABASE_URL = os.getenv("DATABASE_URL")
engine = create_engine(DATABASE_URL, connect_args={"check_same_thread": False})
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
class User(Base):
"""用户模型"""
__tablename__ = "users"
id = Column(Integer, primary_key=True, index=True)
user_id = Column(String, unique=True, index=True) # 匿名用户ID
created_at = Column(DateTime, default=datetime.utcnow)
class Product(Base):
"""商品模型"""
__tablename__ = "products"
id = Column(Integer, primary_key=True, index=True)
product_id = Column(String, unique=True, index=True)
category = Column(String, index=True) # 商品类别
price = Column(Float)
name = Column(String) # 商品名称
class UserBehavior(Base):
"""用户行为模型"""
__tablename__ = "user_behaviors"
id = Column(Integer, primary_key=True, index=True)
user_id = Column(String, ForeignKey("users.user_id"))
product_id = Column(String, ForeignKey("products.product_id"))
behavior_type = Column(String) # "view", "search", "add_to_cart", "purchase", "review"
timestamp = Column(DateTime, default=datetime.utcnow)
duration = Column(Float) # 行为持续时间(秒)
context = Column(String) # JSON格式的上下文信息(设备、时间、位置等)
# 创建数据库表
Base.metadata.create_all(bind=engine)
4.3.2 行为跟踪实现
在app/behavior_tracker.py中实现用户行为跟踪功能:
from datetime import datetime
from typing import Dict, Optional
import json
from .database import SessionLocal, User, Product, UserBehavior
class BehaviorTracker:
def __init__(self):
self.db = SessionLocal()
def track_behavior(
self,
user_id: str,
product_id: str,
behavior_type: str,
duration: Optional[float] = None,
context: Optional[Dict] = None,
product_category: Optional[str] = None,
product_price: Optional[float] = None,
product_name: Optional[str] = None
):
"""
跟踪用户行为并保存到数据库
Args:
user_id: 用户唯一标识
product_id: 商品ID
behavior_type: 行为类型 ("view", "search", "add_to_cart", "purchase", "review")
duration: 行为持续时间(秒)
context: 上下文信息字典(设备、时间、位置等)
product_category: 商品类别(首次出现时使用)
product_price: 商品价格(首次出现时使用)
product_name: 商品名称(首次出现时使用)
"""
# 确保用户存在
db_user = self.db.query(User).filter(User.user_id == user_id).first()
if not db_user:
db_user = User(user_id=user_id)
self.db.add(db_user)
self.db.commit()
# 确保商品存在
db_product = self.db.query(Product).filter(Product.product_id == product_id).first()
if not db_product and product_category and product_price and product_name:
db_product = Product(
product_id=product_id,
category=product_category,
price=product_price,
name=product_name
)
self.db.add(db_product)
self.db.commit()
# 保存行为
behavior = UserBehavior(
user_id=user_id,
product_id=product_id,
behavior_type=behavior_type,
duration=duration,
context=json.dumps(context) if context else None,
timestamp=datetime.utcnow()
)
self.db.add(behavior)
self.db.commit()
self.db.refresh(behavior)
return behavior
def get_user_history(self, user_id: str, limit: int = 10) -> Dict:
"""获取用户历史行为"""
behaviors = self.db.query(UserBehavior).filter(
UserBehavior.user_id == user_id
).order_by(
UserBehavior.timestamp.desc()
).limit(limit).all()
history = []
for b in behaviors:
product = self.db.query(Product).filter(Product.product_id == b.product_id).first()
history.append({
"behavior_type": b.behavior_type,
"product_id": b.product_id,
"product_name": product.name if product else None,
"product_category": product.category if product else None,
"timestamp": b.timestamp.isoformat(),
"duration": b.duration,
"context": json.loads(b.context) if b.context else None
})
# 按时间升序排列(最早的在前)
return {"history": sorted(history, key=lambda x: x["timestamp"])}
def close(self):
self.db.close()
4.4 提示工程核心模块实现
提示生成器是系统的核心,我们在app/prompt_engine.py中实现:
from datetime import datetime
from typing import Dict, List, Optional
import json
class PromptEngine:
"""提示工程引擎,负责生成预测用户行为的提示"""
def __init__(self):
# 加载提示模板
self.templates = self._load_templates()
def _load_templates(self) -> Dict[str, str]:
"""加载不同场景的提示模板"""
return {
"purchase_intent_prediction": """
任务:预测电商用户浏览商品后的下一步行为。
用户当前行为:
- 商品ID:{{product_id}}
- 商品名称:{{product_name}}
- 商品类别:{{product_category}}
- 商品价格:{{product_price}}
- 浏览时长:{{browsing_duration}}秒
- 当前时间:{{current_time}}
用户历史行为:
{{user_history}}
上下文信息:
- 设备类型:{{device_type}}
- 一周中的哪一天:{{day_of_week}}
- 是否节假日:{{is_holiday}}
可能的下一步行为:
1. 购买商品(Purchase)
2. 添加到购物车(Add to Cart)
3. 查看评论(View Reviews)
4. 离开页面(Leave)
请分析用户意图并预测下一步行为。要求输出:
1. 每个行为的概率(总和

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐

 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)