【LINUX网络】HTTP服务器搭建完善+报头属性&状态码
本文介绍了HTTP协议的基本结构和实现简单HTTP服务器的关键概念。主要内容包括:1. HTTP代理服务器的功能与负载均衡原理;2. HTTP请求/响应报头的分类和常见属性(如Host、User-Agent等);3. HTTP状态码的分类和应用场景(重点解析301/302重定向);4. GET与POST方法的区别及动态资源处理;5. 实现动态资源请求处理的代码设计思路,包括路由注册机制和响应构建方
【LINUX网络】HTTP协议基本结构、搭建自己的HTTP简单服务器-CSDN博客
本文是基于自己用C原生接口搭建的HTTP服务器进行的进一步学习,建议读者先看前文。
下面基于HTTP协议的原理,理解几个概念:
1. 代理服务器
在之前的概念中,所有的数据、功能都集成于自己的http服务器上,但其实真正的情景远不止如此。如上图所示,大量的数据可能存在于若干个存储数据的“红色服务器”
我们的服务器,更大意义上是一种代理服务器,在客户端访问我们的服务器时,可能代理服务器会采用轮询等测率依次把获得数据(访问数据库)的任务交给“红色服务器”,减轻自己的任务量,提升整体效率。
同时,http代理服务器转发时还要兼顾负载均衡的任务,主要功能还包括如缓存、匿名浏览、安全过滤、访问控制和负载均衡,以及在企业网络、数据采集、跨国访问等方面的使用场景。有深入了解的读者
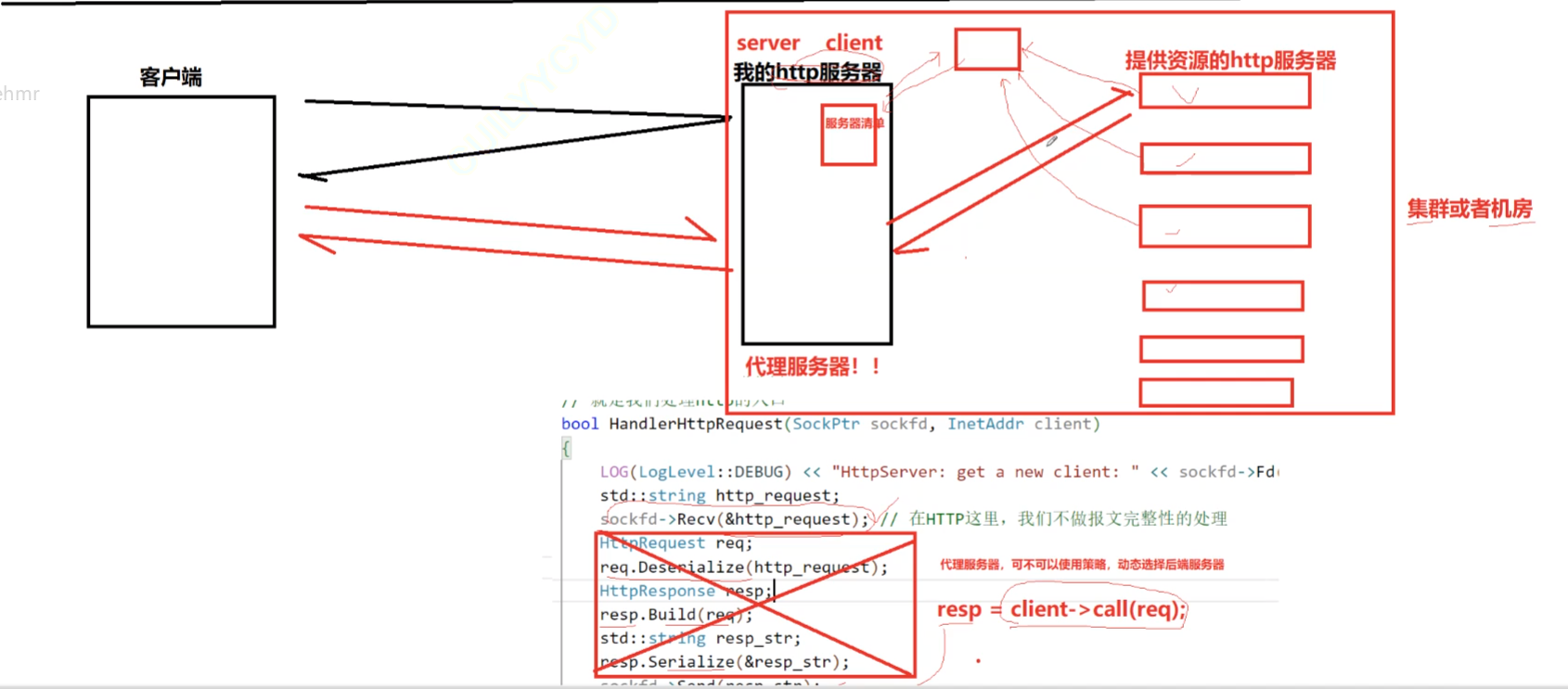
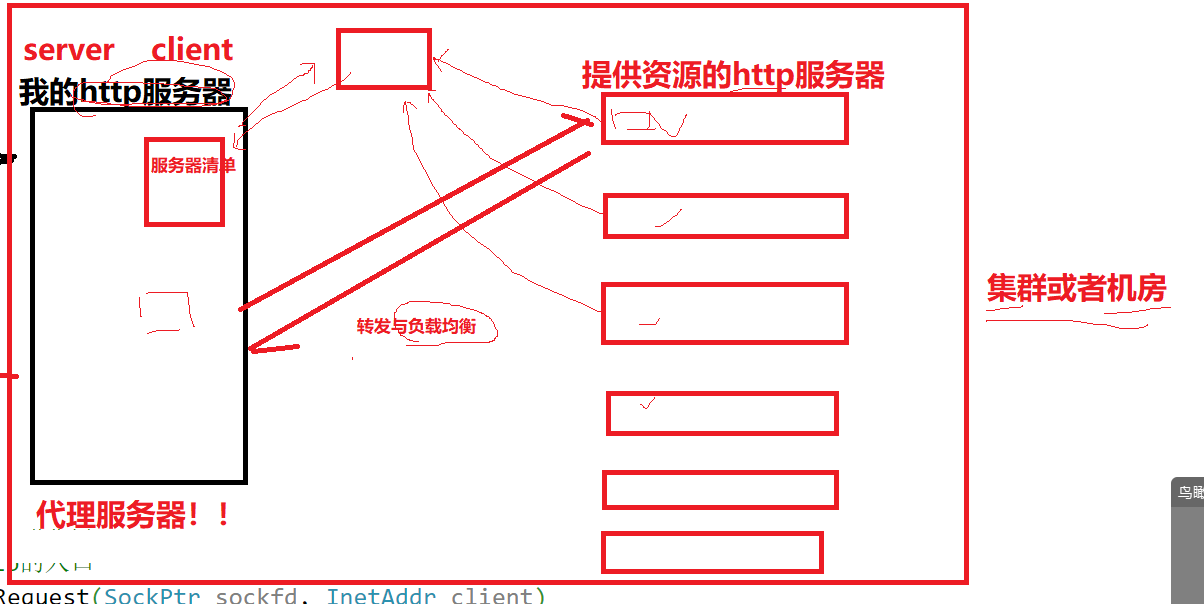
内网的转发与负载均衡,与操作系统中的文件系统部分也非常相似
总之,计算机想要提高效率都是靠封装一层缓存拉解决问题。
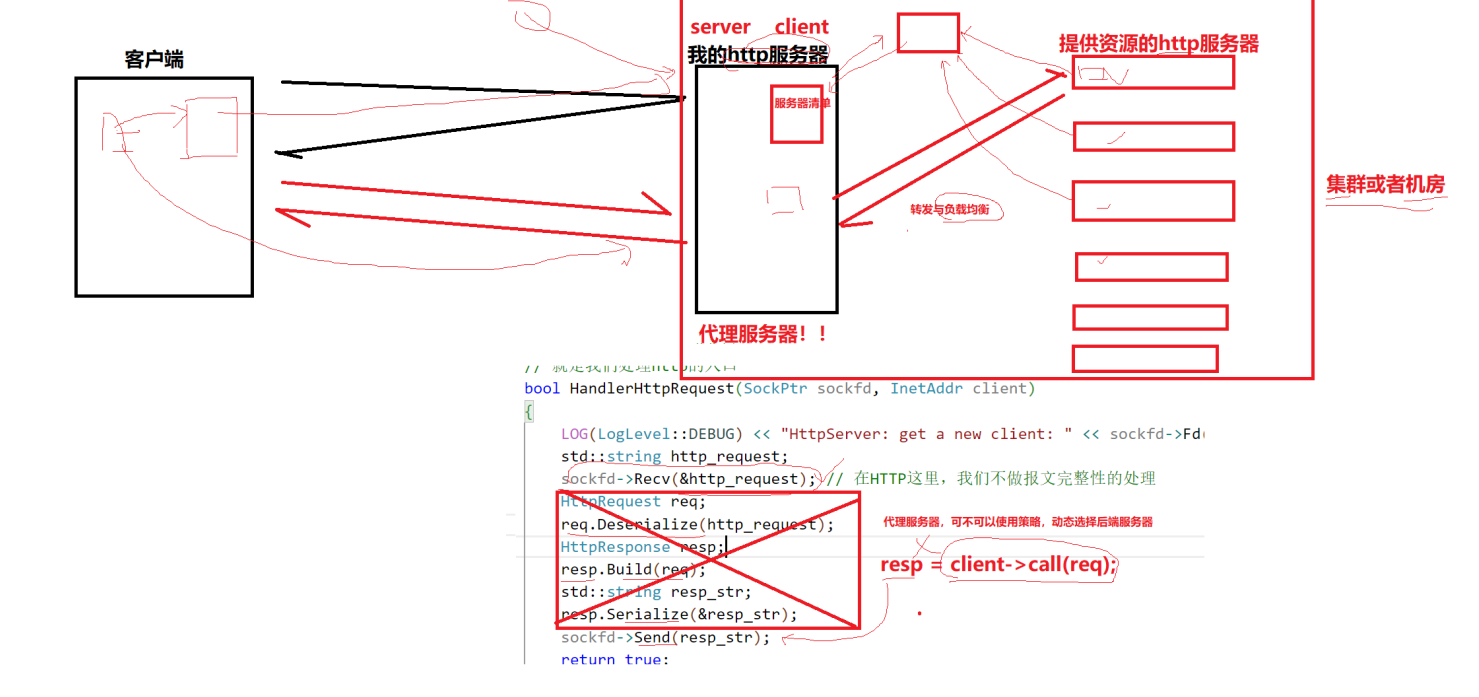
2. HTTP的报头属性
以上一文中我们实现的小小服务器为例子,可以解析出来浏览器发给了header中的内容。
其实真正的header中不止这部分请求报头,只是因为当前的网页请求很简单,所以对应的KV对也比较少。
HTTP报头主要分为请求报头和响应报头两种类型。由于这两种报头的属性结构完全相同,我们将首先以HTTP请求报头为例进行详细讲解,然后再通过HTTP响应报头来具体演示如何设置报头参数。(上一文中的Content-Type和Content-Length的设置其实就是在做这件事。)
请读者注意,实现demo的时候,名字一定要写一样的,不要写成Content_type或content_size等错误,一样的字段才能让HttpResponse的value值被成功设置。
常见的报头
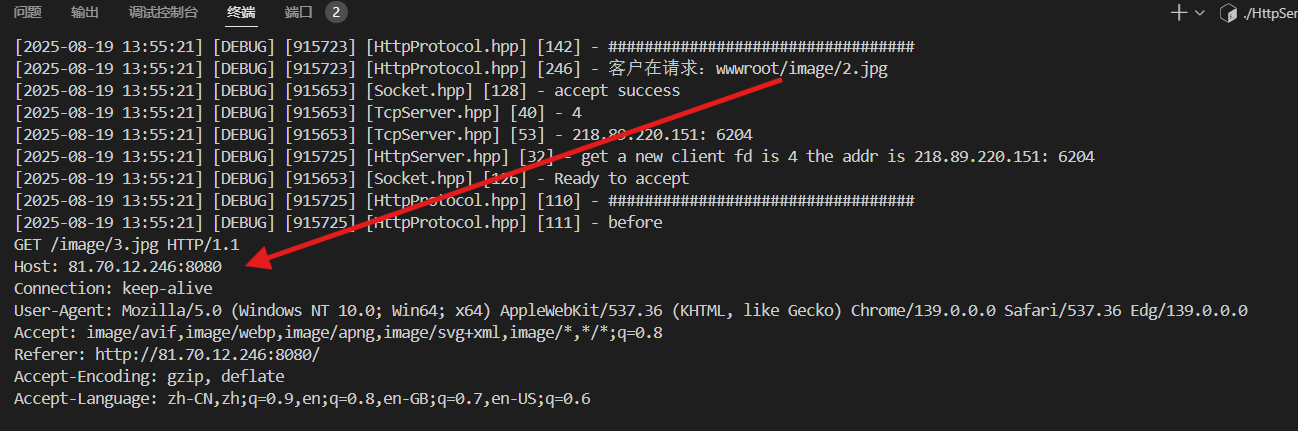
Host: 81.70.12.246:8080 Connection: keep-alive User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0 Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8 Referer: http://81.70.12.246:8080/ Accept-Encoding: gzip, deflate Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
HOST:指定服务器的主机名和端口号,浏览器(客户端)通过这个报头告诉服务器它想访问的机器位置
Connection: keep-alive - 表示客户端希望与服务器保持连接,以便在同一连接上发送多个请求。还有个选项是close,表示请求/响应完成后,应立即关闭TCP连接。
User-Agent : 表示客户端的用户代理字符串,包含了浏览器和操作系统的信息
Accept: 表示客户端可以接受的 MIME类型
Accept-Encoding: gzip, deflate, br, zstd - 表示客户端可以接受的内容编码。这里表示客户端可以接受gzip、deflate、br和zstd编码的内容
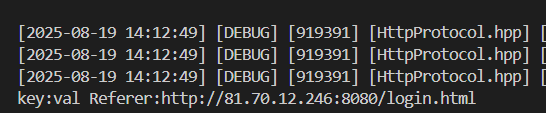
Accept-Language: en,zh-CN;q=0.9,zh;q=0.8,en-US;q=0.7 - 表示客户端可以接受的语言。这里表示客户端可以接受英语(en)、简体中文(zh-CN)、中文(zh)和美式英语(en-US)referer: 当前页面是从哪个页面跳转过来的;
再比如我现在从login界面跳转到rigister界面:
这个字段可能在以下情景中使用的比较多:自动跳转/自动弹框/想访问a不小心访问到B
对最重要的几个进行分类:
### HTTP报头属性说明与分类
- **Host**:客户端通过此字段告知服务器,所请求的资源位于哪个主机的哪个端口上。它是HTTP/1.1规范中唯一必须包含在请求中的字段,用于指定服务器的主机名和端口号。
- **User-Agent**:此字段声明用户的操作系统和浏览器版本信息,仅出现在请求中,用于向服务器表明客户端应用程序的相关信息。
- **Referer**:当用户从一个页面跳转到当前页面时,此字段会记录跳转来源页面的URL,仅出现在请求中。
- **Location**:此字段搭配3xx状态码使用(后文介绍),用于告知客户端接下来应访问的资源位置,仅出现在响应中。
- **Content-Type**:此字段表示数据的媒体类型,既可能出现在请求报头中,也可能出现在响应报头中。
- **Content-Length**:此字段表示实体主体的大小,既可能出现在请求报头中,也可能出现在响应报头中。
- **Cookie**:用于在客户端存储少量信息,通常用于实现会话(session)功能。客户端会通过此字段发送之前服务器存储的Cookie信息,仅出现在请求中。关于Cookie和Session的详细内容将在后续章节中讲解。
- **Set-Cookie**:此字段用于服务器指示客户端保存Cookie,仅出现在响应中,需要与客户端的Cookie配合使用,具体介绍将在后续Cookie章节中展开。
### 常见报头属性分类
- **只出现在请求报头中**
- **Host**:HTTP/1.1规范中唯一必须包含在请求中的字段,用于指定服务器的主机名和端口号。
- **User-Agent**:表示客户端应用程序的信息,仅出现在请求中。
- **Referer**:表示用户从哪个页面链接过来的,仅出现在请求中。
- **Cookie**:客户端发送之前服务器存储的Cookie信息,仅出现在请求中。- **只出现在响应报头中**
- **Location**:主要配合3xx重定向状态码使用,仅出现在响应中。
- **Set-Cookie**:用于服务器指示客户端保存Cookie,仅出现在响应中,需搭配客户端的Cookie使用,具体介绍见后续Cookie章节。- **可能同时出现在请求或响应报头中**
- **Content-Type**:表示实体的媒体类型,既可能出现在请求报头中,也可能出现在响应报头中。
- **Content-Length**:表示实体主体的大小,既可能出现在请求报头中,也可能出现在响应报头中。
3. HTTP状态码_status_code
状态码分成五个类型,分别对应不同的数字开头
100 Continue : 客户端发送了一个带有
Expect: 100-continue头部的请求,服务器响应此状态码(发送)表示客户端可以继续发送请求体,比如上传大文件时,不可能一次性传完,可能会分多次请求。200 OK:请求成功,服务器返回了请求的数据。
4XX 都称之为Client Error,比如客户端进行了非法请求
404 Not Found:服务器无法找到请求的资源
5XX Server Error(服务器错误状态码,表示当前的服务器有错
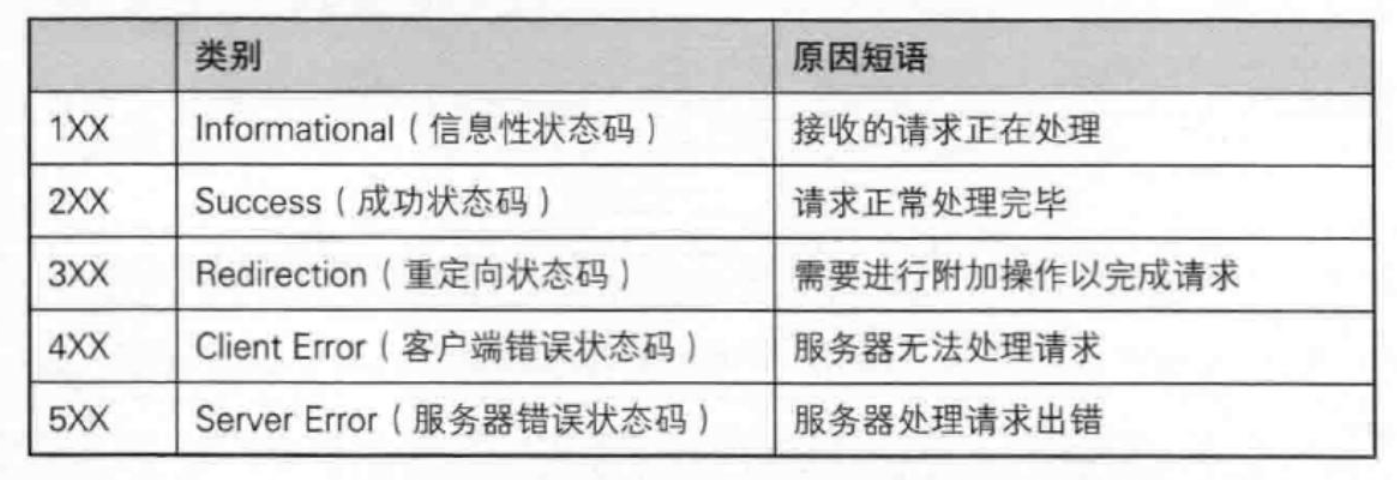
状态码 含义 应用场景 100 Continue 上传大文件时,服务器通知客户端继续上传 200 OK 访问网站首页时,服务器返回网页内容 201 Created 发布新文章后,服务器返回创建成功信息 204 No Content 删除文章后,服务器返回"无内容"表示操作成功 301 Moved Permanently 网站更换域名时自动跳转;搜索引擎更新链接时使用 302 Found/See Other 用户登录成功后重定向到个人主页 304 Not Modified 浏览器缓存未修改资源时返回 400 Bad Request 表单提交格式错误导致请求失败 401 Unauthorized 访问需登录页面时未认证或认证失败 403 Forbidden 尝试访问无权限查看的页面 404 Not Found 访问不存在的网页链接 500 Internal Server Error 服务器崩溃或数据库错误导致页面加载失败 502 Bad Gateway 代理服务器无法从上游服务器获取有效响应 503 Service Unavailable 服务器维护或过载时暂时无法处理请求
在讲3xx对应的重定向之前,给读者记录点小背景:
拥有流量入口的服务器叫搜索引擎(这就是感觉小时候都是百度一家独大的原因),浏览器在商业价值上是仅次于操作系统的(浏览器可以内置很多内容),所以会有很多公司开发了浏览器,每个浏览器都可能有细微的差异,导致前端工程师需要考虑每一种浏览器是否兼容,所以在大量的浏览器中,对于返回码的应答不一定百分百关心,因为每一种服务器的返回可能不会完全一样,但是一定大差不差,所以不用特别纠结于一种浏览器的返回的状态码
Location重定向
其中了解价值最大的莫过于302和301 :
状态码 含义 是否为临时重定向 应用场景 301 Moved Permanently 否(永久重定向) 网站更换域名时自动跳转;<br>搜索引擎更新网站链接时使用 302 Found / See Other 是(临时重定向) 用户登录成功后重定向到个人首页 HTTP 状态码 301(永久重定向)和 302(临时重定向)都需要使用 Location 头部。以下是具体说明:
HTTP 状态码 301(永久重定向)
- 表示请求的资源已永久迁移至新位置
- 服务器会在响应中包含 Location 头部,指明资源的新 URL
- 浏览器会自动重定向到该地址并缓存此重定向
- 示例响应头:
HTTP/1.1 301 Moved Permanently Location: https://www.new-url.comHTTP 状态码 302(临时重定向)
- 表示请求的资源临时迁移至新位置
- 服务器同样会返回 Location 头部指明新 URL
- 浏览器会临时使用新地址但不会缓存该重定向
- 示例响应头:
HTTP/1.1 302 Found Location: https://www.new-url.com
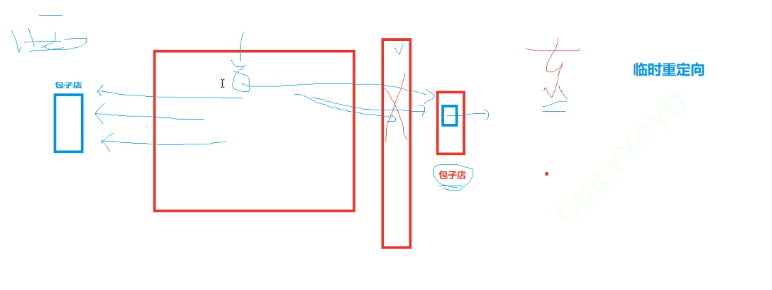
临时重定向和永久重定向的区别,就好像一家店铺是“道路维修,暂时搬迁至xxx”和“门店已搬迁至xxx”
临时:先去原地址,再去新地址。
永久:直接去新地址。
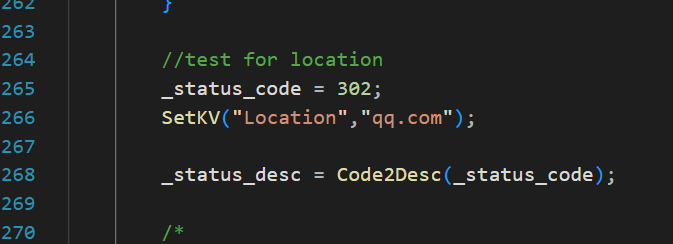
测试如下:
确实成功重定向了,只不过未能成功打开:
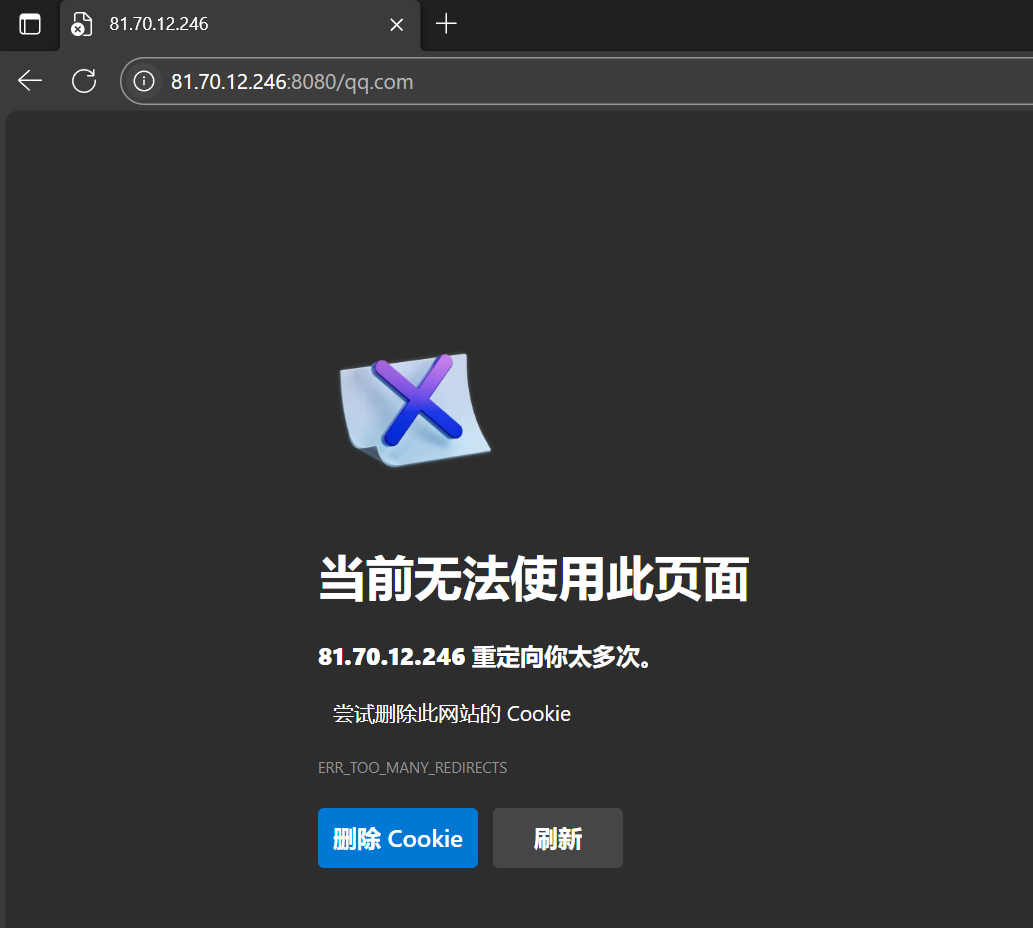
因为服务器可能出于自身安全考虑,不允许这样不停的重定向。因为当前的代码是硬编码,一次重定向失败,无论如何都会返回302,然后就会一直死循环。

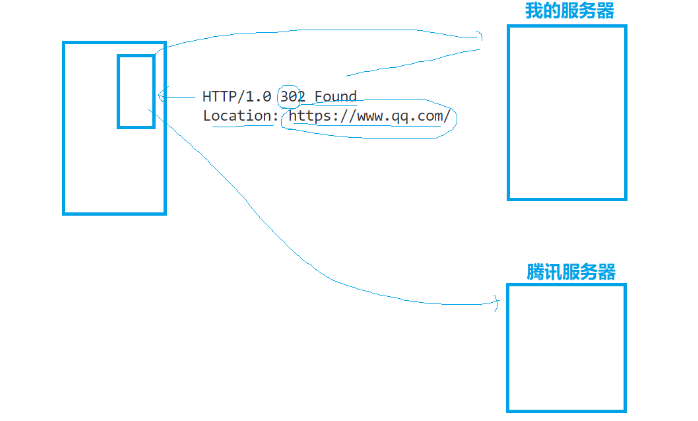
简易理解重定向的过程
发现_status_code是302,就会自动发起二次请求,即重定向,走到重定向的地址去
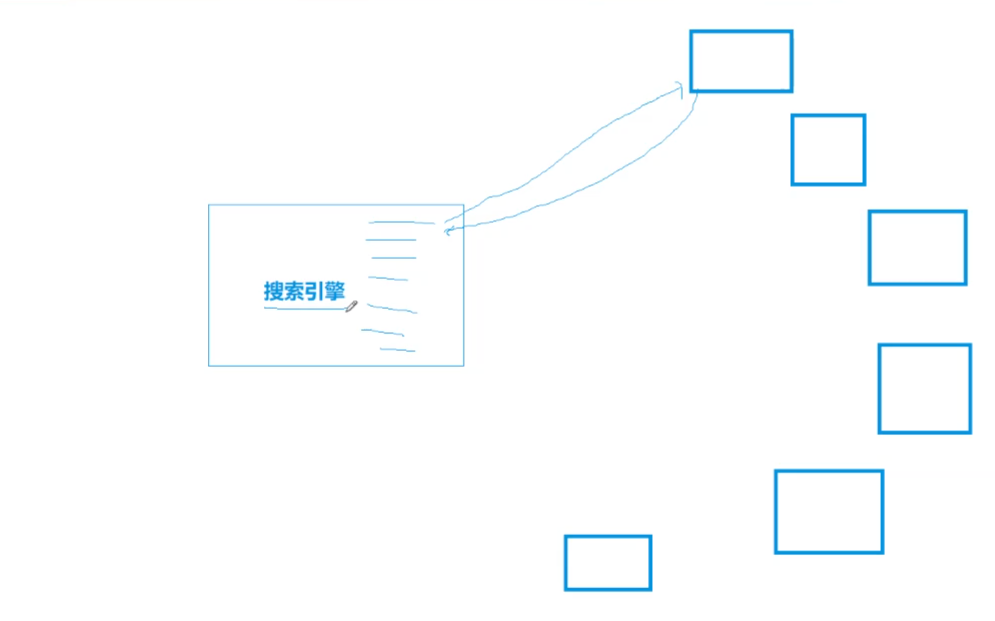
而对于301,更多的应用场景是搜索引擎:
首先是最简单最简单的爬虫原理:
网络爬虫通过解析HTML中的
<a>标签提取链接,从而发现并抓取新的网页。这个过程是递归进行的:从初始页面出发,不断提取新链接并访问,逐步扩展抓取范围。
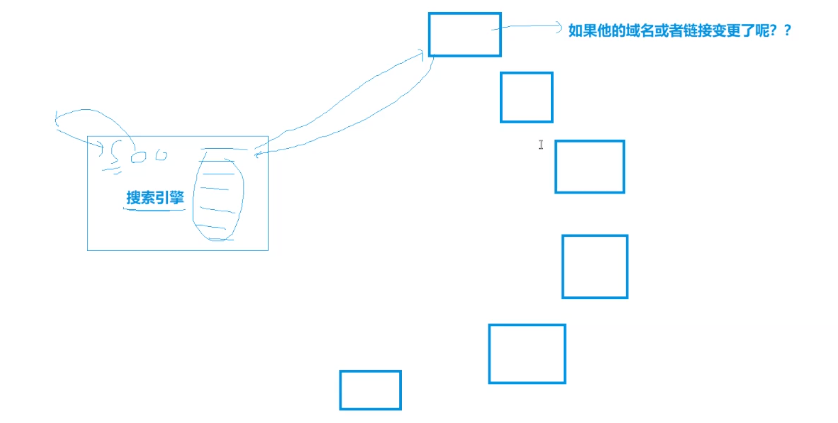
另外,对于搜索引擎来说,需要不停的去爬各个网站以获取信息,但是网站成千上万,也会出现变更域名的情况。
此时就能体现301重定向的作用:
当网站变更域名或URL时,搜索引擎通过301永久重定向机制来更新索引。这种重定向主要服务于搜索引擎,确保它们能够追踪到网站的最新地址。
所以,301主要是给搜索引擎做的。
搜索引擎会定期进行爬取和索引更新,以保持信息的时效性。大多数网站都欢迎搜索引擎爬取,因为这会提高网站在搜索结果中的可见度。
其实还有很多其他的重定向,在此记录如下:
“临时重定向”
302 Found - 最常用的临时重定向状态码
303 See Other - 特别用于将POST请求重定向到GET请求
307 Temporary Redirect - 临时重定向,但严格保持原始请求方法不变
“永久重定向”301 Moved Permanently - 资源已永久移动到新位置
308 Permanent Redirect - 永久重定向,但严格保持原始请求方法不变
“其他重定向”300 Multiple Choices - 表示请求有多个可能的响应
304 Not Modified - 缓存重定向,表示资源未修改
4. HTTP的请求方法
首先理解一下什么是表单:
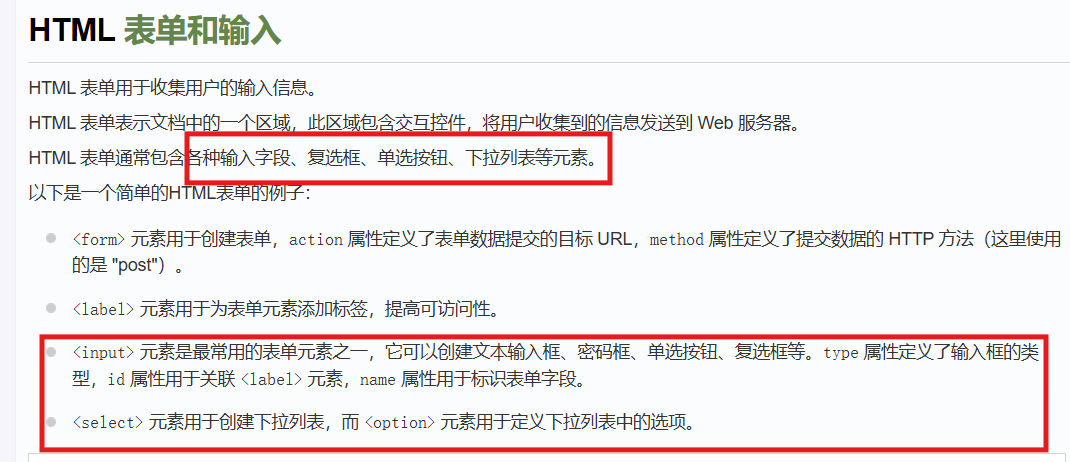
对于一个HTTP的请求(Request),排在第一位的数据就是http方法,是用于指定客户端希望对资源执行的操作类型。这些方法定义了HTTP请求的行为,是HTTP协议的核心组成部分。
稍微常见一点的四种:
GET:请求指定的资源。GET方法应该只用于获取数据,并且不会对服务器上的数据产生任何影响。
POST:向指定的资源提交要被处理的数据,通常用于表单提交或者上传文件。数据被包含在请求的主体中。
PUT:将请求主体中的实体数据更新到指定的资源,如果该资源不存在,则创建新资源。
DELETE:删除指定的资源
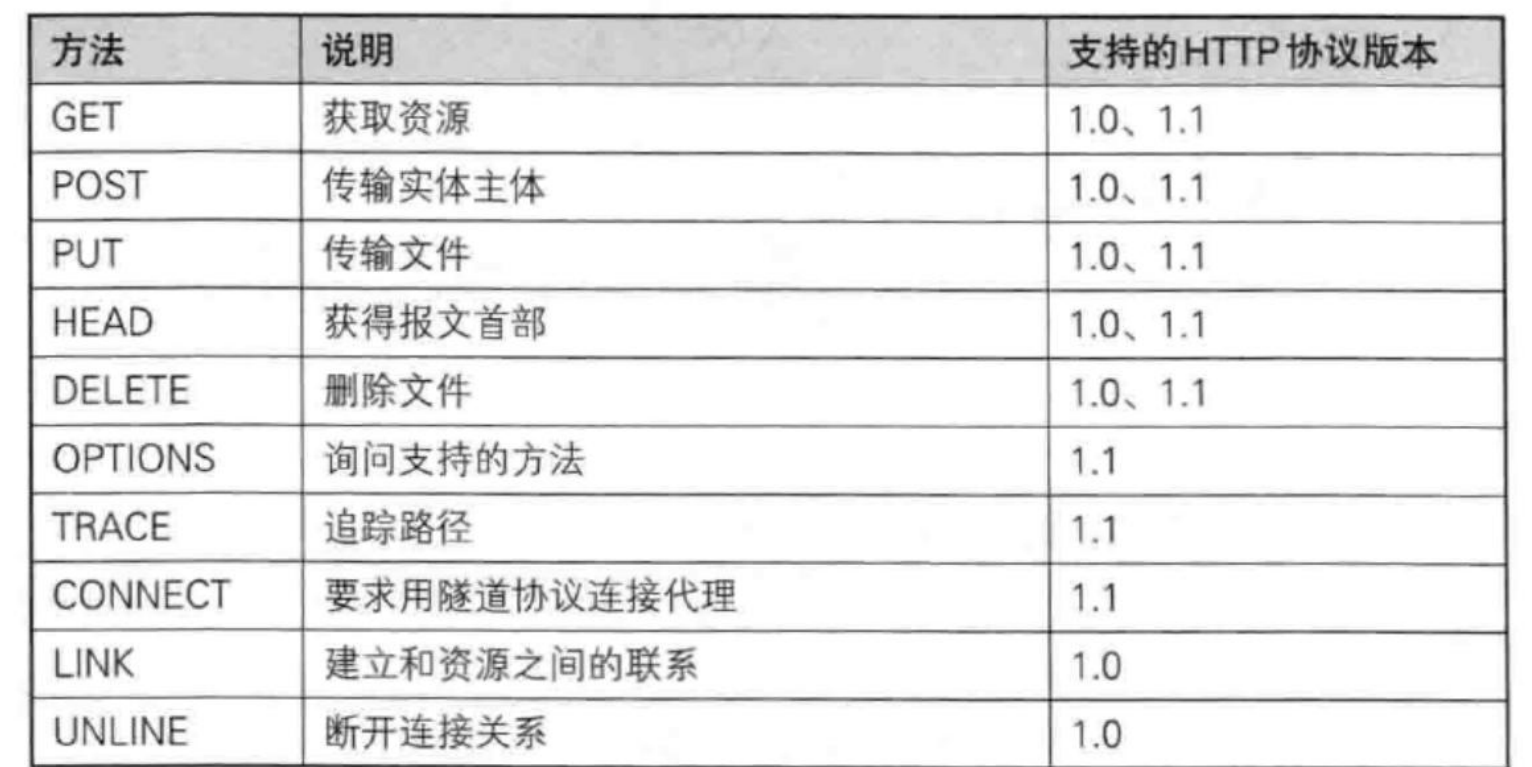
其实一共有9-10种方法,但是最常用的只有GET和POST方法会被暴露出来,
90%的网站只暴露出来GET和POST(为了安全):
比如PUT方法,大部分网站不允许客户端无限制的上传。如果恶意客户端不停的传,传满了,服务器就崩了。
DELETE方法,直接让客户端删文件(直接删库跑路,服务器不全完蛋了)
OPTION方法,让客户端可以看清楚漏洞
有了以上理解之后,再来理解什么是动态资源、静态资源
动态资源与静态资源
在上面以及之前两节中,服务器都是向客户端直接响应字符串或者一个静态资源(图片网页视频音频、js、css),但是有的时候不只有静态资源,还有很多的动态资源,例如在表单提交时
form标签内的action字段的值(数据提供的URL)就是对应的一个动态资源

表单提供的就是一种交互式的资源:比如需要你输入账号密码等等......
正如上文所说,表单中的input就是干这个工作的。
input会被浏览器解释成一个个的输入框。
自动把action后面的内容放到ip+port的后面,形成的表单(form)就会发送给上面的地址
此时的提交方法是method = post


所以,对于动态资源的理解,其实不是浅层的传统中文意义上的“资源”,动态资源可以是一个接口、几种方法:
URI传过来不一定必须要返回一个具体的文件,URI也可能是希望我的服务器调用几个接口
比如,表单提交的过程种,URL请求的其实是服务器对这个数据进行处理的方法,希望后端去处理这个数据而不是提供数据。
之前有了解URL和URI区别的朋友也应该有了解过,URL是一个资源定位器,但是大部分时候我们更喜欢称之为URI,就是因为不是每一次都要去定义一个资源,有的时候一个identify更能满足广义的描述。
静态资源和动态资源的利用密不可分,联系紧密,比如进行一个登录,就是先返回了界面的html这个静态资源,通过前端输入账号密码之后,再用带问号的http请求去执行这个对应的接口
进一步学习GET和POST方法
一句话来说,GET就是把远端的资源拿下来; POST就是把参数上传。但其实GET也可以用于上传参数,下面通过实验来观察:
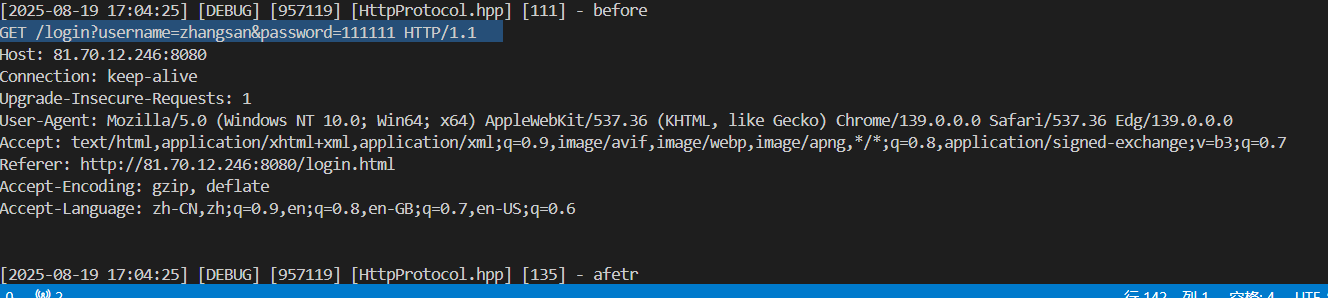
先把之前的网页的登录界面的一个表单的提交方法改成GET
请仔细观察这次的URI
GET 后面的参数就是我们在登录界面输入的内容,直接在?后作为参数被传递了
并且HttpRequest的body是空的:
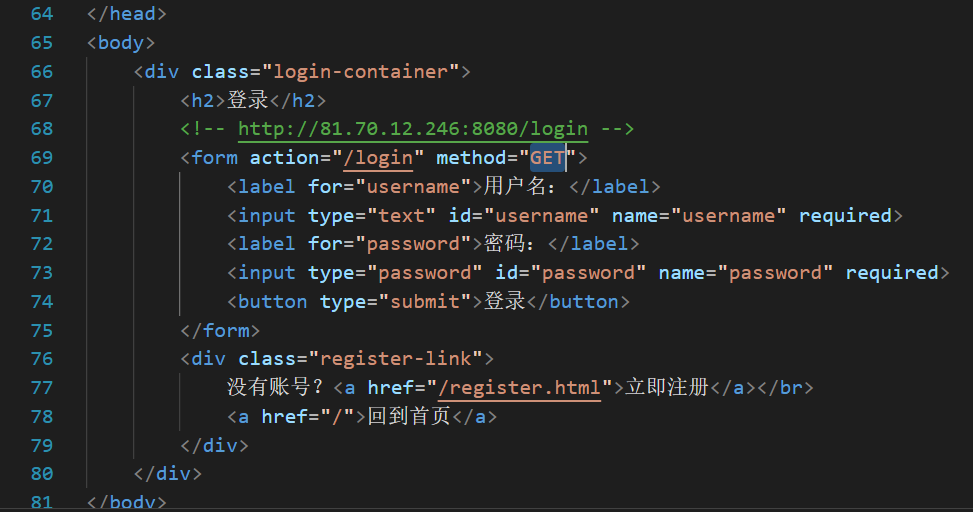
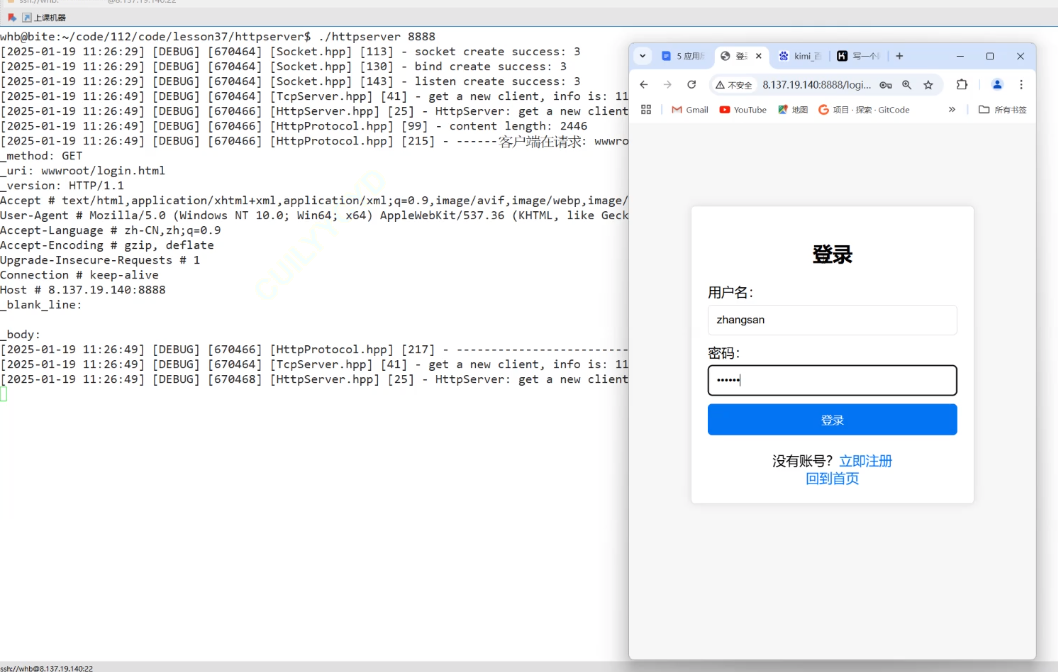
发现GET的第一个特点,参数直接在URI种传递。
再看看POST,同样的由客户端发动登录
参数不再出现在URI中,而是通过body传输。
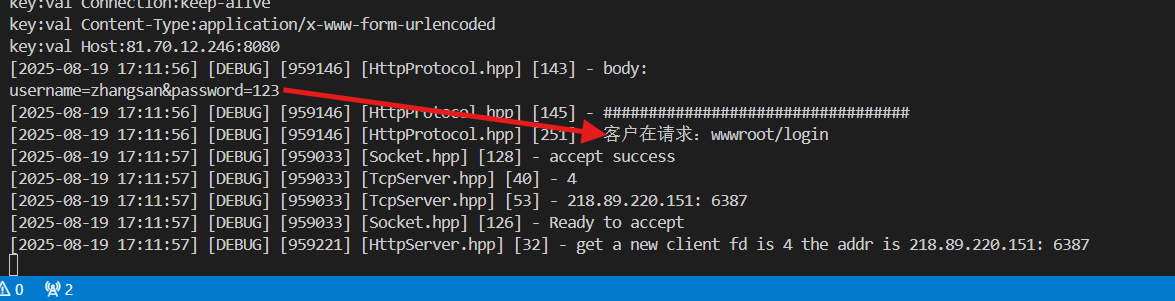
GET和POST的区别:
GET参数通过URL传递,POST通过请求体传递
GET:参数附加在URL后面,以键值对的形式出现,多个参数之间用
&连接。例如:http://example.com?name=Kimi&age=30。POST:参数包含在请求体中,对URL不可见。这使得POST可以发送大量数据,并且可以包含非ASCII字符。
GET请求有长度限制,POST没有严格限制
GET:由于参数通过URL传递,受到URL长度限制(通常由浏览器和服务器决定,但一般不超过2KB)。这意味着GET请求能发送的数据量有限。
POST:参数通过请求体传递,理论上没有长度限制(取决于服务器配置和网络环境)。这使得POST可以发送大量数据,如文件上传。
GET请求可被缓存,POST通常不缓存
GET:由于GET请求的结果通常不依赖于用户状态,因此可以被缓存,以提高性能和减少服务器负载。浏览器和代理服务器可能会缓存GET请求的结果。
POST:由于POST请求通常用于修改服务器状态(如表单提交),因此结果依赖于用户状态,通常不会被缓存。这确保了每次POST请求都能得到最新的结果。
GET相对不安全,POST相对更私密
GET:由于参数通过URL传递,可能会在浏览器历史记录、服务器日志中留下敏感信息,如用户名、密码等。此外,GET请求可以被书签化,这意味着敏感操作可以被意外地重复执行。
POST:由于参数通过请求体传递,不会在URL中暴露敏感信息,相对更安全。然而,POST请求的数据仍然可能被拦截(如通过中间人攻击),因此仍然需要使用HTTPS等加密措施来保护数据安全。
GET具有幂等性,POST通常非幂等
GET:幂等性意味着多次执行相同的GET请求,结果总是相同的,不会改变服务器状态。例如,多次获取同一资源,服务器状态不会改变。
POST:非幂等性意味着多次执行相同的POST请求,可能会多次修改服务器状态。例如,多次提交表单可能会导致多次创建相同的记录。这使得POST请求的结果可能因执行次数而异。
在参数传递功能方面,GET方法确实不如POST完善。POST通过请求体传输数据,不仅支持更长的文本内容,而且安全性更高,能避免将敏感信息直接暴露在URL中。
不过需要说明的是,POST只是相对更私密。由于当前数据传输都是明文的,使用抓包工具依然可以完整获取请求内容,包括请求体中的数据。
内容回顾:
之前的百度的URL里,有一个/s,后面才接的是各种参数,由此可以推出,表单上的action写的就是s,会把action后面的内容自动放到ip+port处去
之前的代码中,永远都是提供静态资源,今天要改写代码,让代码拥有操作动态资源的能力
5. DEMO CODE
-----------------------记录完成demo代码中的过程与遇到的困难
处理动态资源及其请求
post方法body不为空,get方法的URL带有?,说明都是需要交互式设置的;
如果只是请求一般的静态资源,就是原来的步骤。
有参数,就去交互式设计;无参数,就走Build的老路,请求静态资源,构建好之后直接准备Serialize

现在的问题是,当有参数需要请动态资源时,不同的请求一般对应着不一样的动态资源。
1、需要使用一个容器(如哈希表)来把对应的请求和动态资源对应起来(此时的动态资源默认就是方法接口)
2、由1得,请求要和动态资源对应起来,那么相对来说一定是POST方法更简单,因为POST方法的URI更简单明了,更适合直接提取出来作为参数
最后,就希望我们的调用方式可以是:
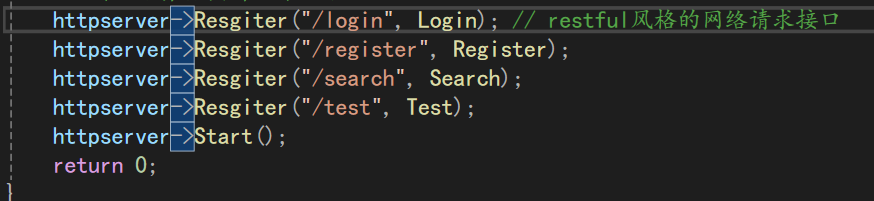
这里就涉及到了一种RESTful风格的网络接口设计的概念:
每个路由都与一个处理函数(如
Login、Register、Search、Test)关联,这些函数定义了当特定路由被请求时应该执行的操作。这种设计符合RESTful接口的原则,因为它提供了一种统一的方式来访问和操作资源,并且每个请求都包含了执行操作所需的所有信息。这样,到时候发起访问的URI其实就是wwwroot/login或者wwwroot/Register,简洁明了。
现在的Build是一种请求静态资源并且构造返回的Response的办法,我们只不过是要多实现点请求动态资源的版本
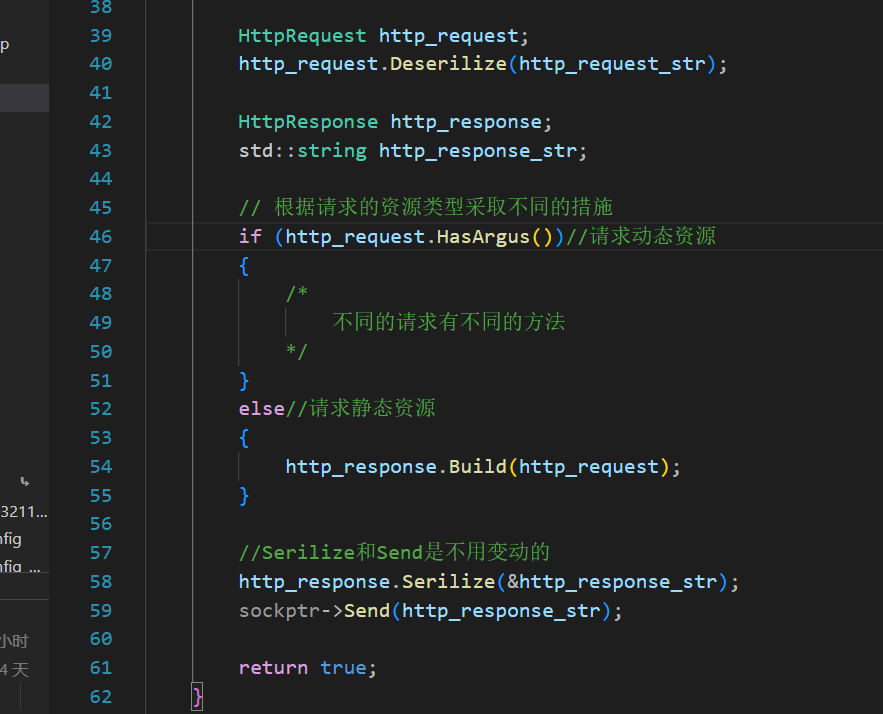
所以对于需要参数的交互式方法来说,现在需要想办法去获得参数:
我们设计成一个unordered_map,用函数名和解析后的uri依次对应。
using handler_argus_req = std::function<void(HttpRequest &req, HttpResponse *rep)>;这个函数的目的就是去构建一个response,和build同级、同层次
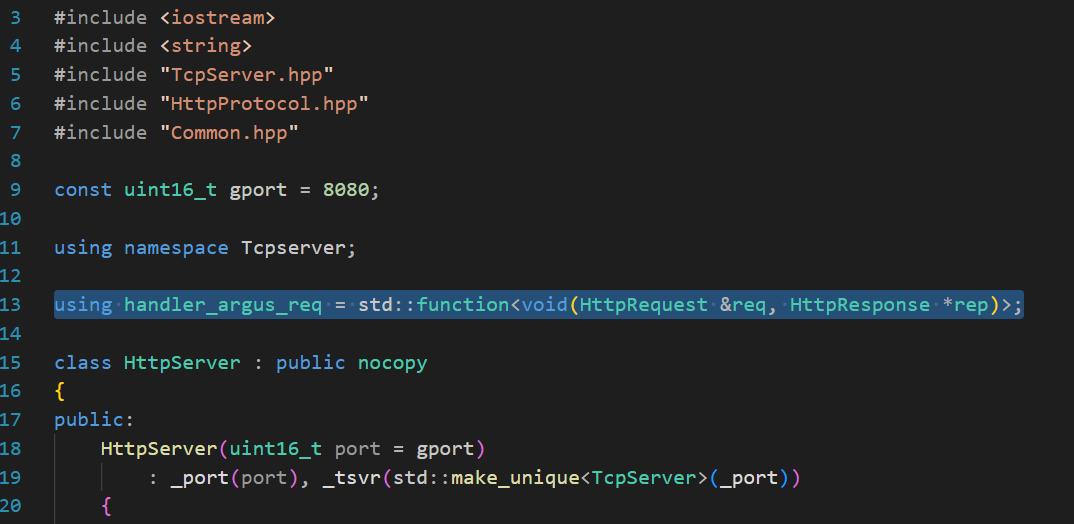
所以,还需要一个注册方法,能把函数和URI都注册进入map
//动态资源的服务对照表 std::unordered_map<std::string,handler_argus_req> _route;//功能路由void Register(std::string funcname,handler_argus_req& func) { _route.insert(std::make_pair(funcname,func)); }
一点代码细节:Url()接口返回的是一个加入了wwwroot的接口,而现在我们只需要从解析上解析下来的那个“方法名字”,也就是说:
_url是wwwroot/login
_Method_Url是/login
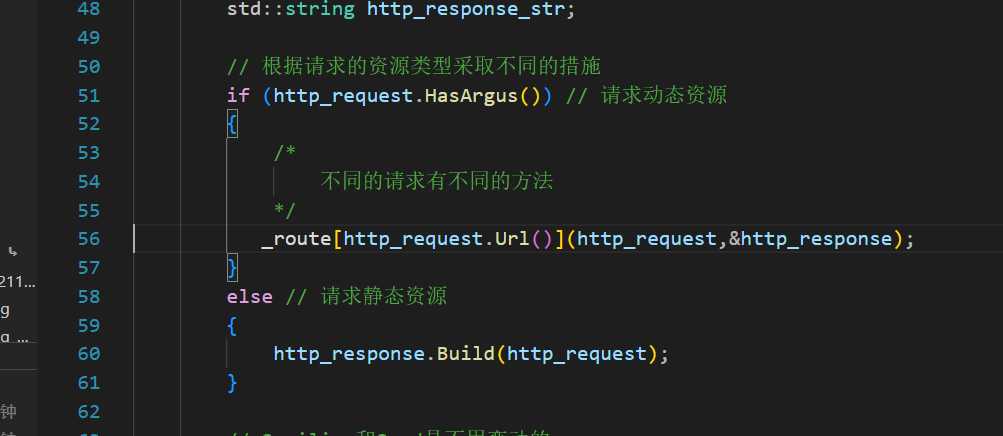

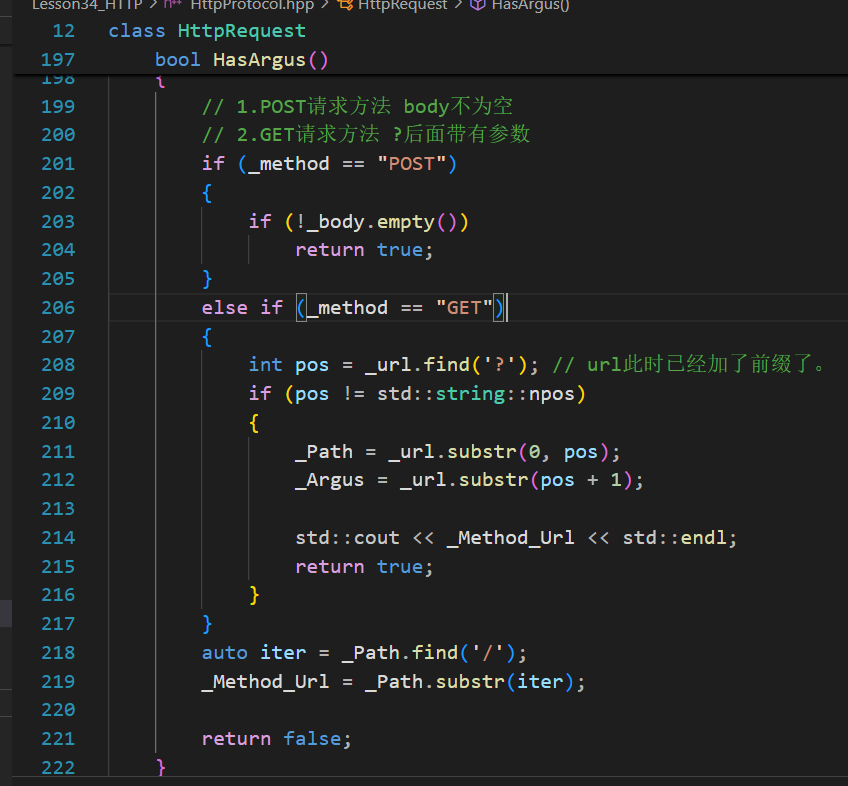
HasArgus的初步实现,再引入两个新变量_path和_argus,因为在GET方法下_url已经不再简单是个路径,还带有参数。
调用:

码间休息 tips
什么是favicon.ico
读者在自己尝试demo或者访问网站的时候,网站的左上角通常都有一个图标。
请求看到favicon.ico的时候表示浏览器正在请求这个小图标,只不过暂时还没有找到可以进行应答的资源。
测试:
POST方法: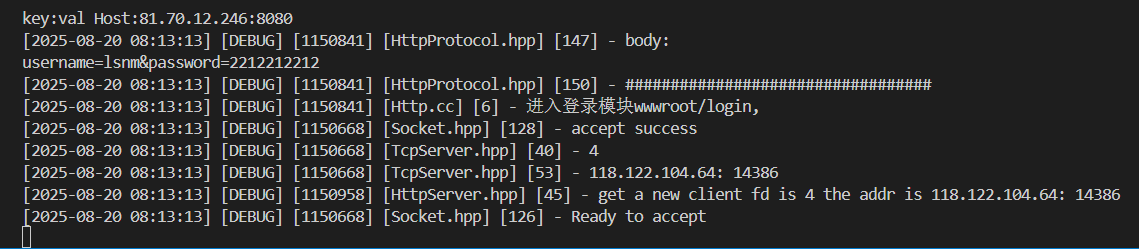
GET方法:
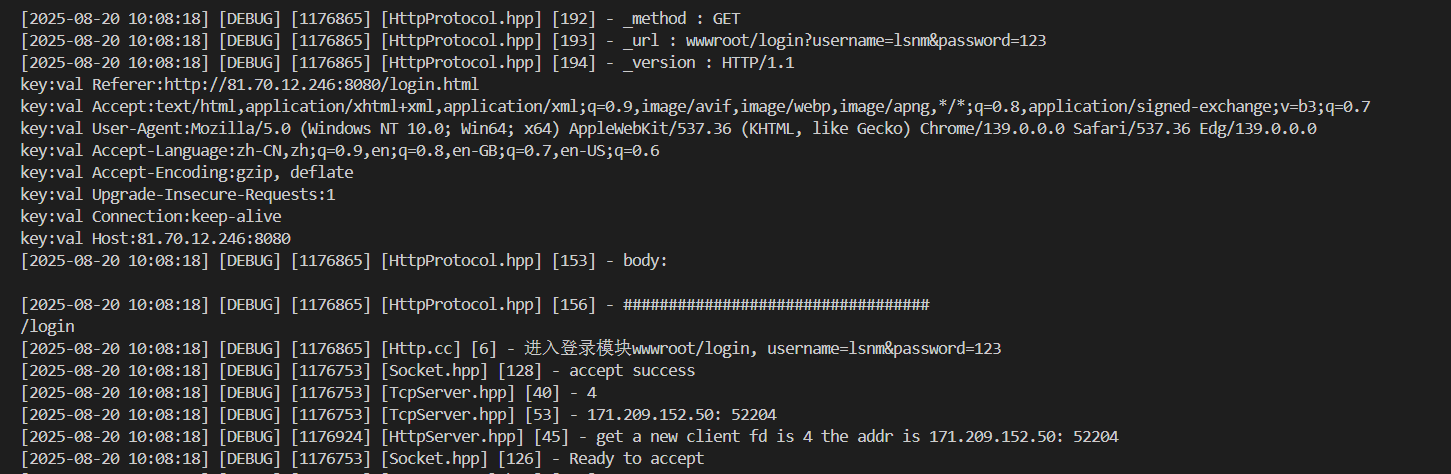
刚刚一直在做的,就是把整个URI给出的请求解析出来要调的函数、然后去调用。
现在就可以构建对应的Response,否则一直send回去的都是空的
处理返回的HttpResponse
鉴于现在的Build函数(现在更名为StaticBuild)不具备构造交互式Response的能力,所以需要我们自己去实现。
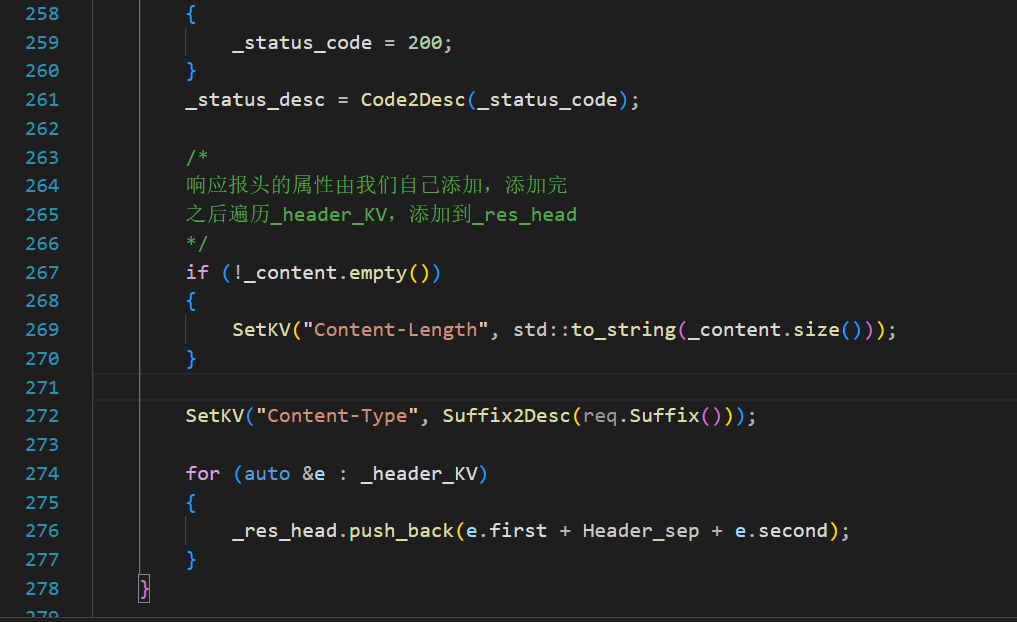
void DynamicBuild(HttpRequest &req) { // body的build已经在上层完成了 if (_content.empty()) { _status_code = 302; SetKV("Location", "/wating.html"); } else { _status_code = 200; SetKV("Content-Length", std::to_string(_content.size())); SetKV("Content-Type", Suffix2Desc(req.Suffix())); } _status_desc = Code2Desc(_status_code); for (auto &e : _header_KV) { _res_head.push_back(e.first + Header_sep + e.second); } }
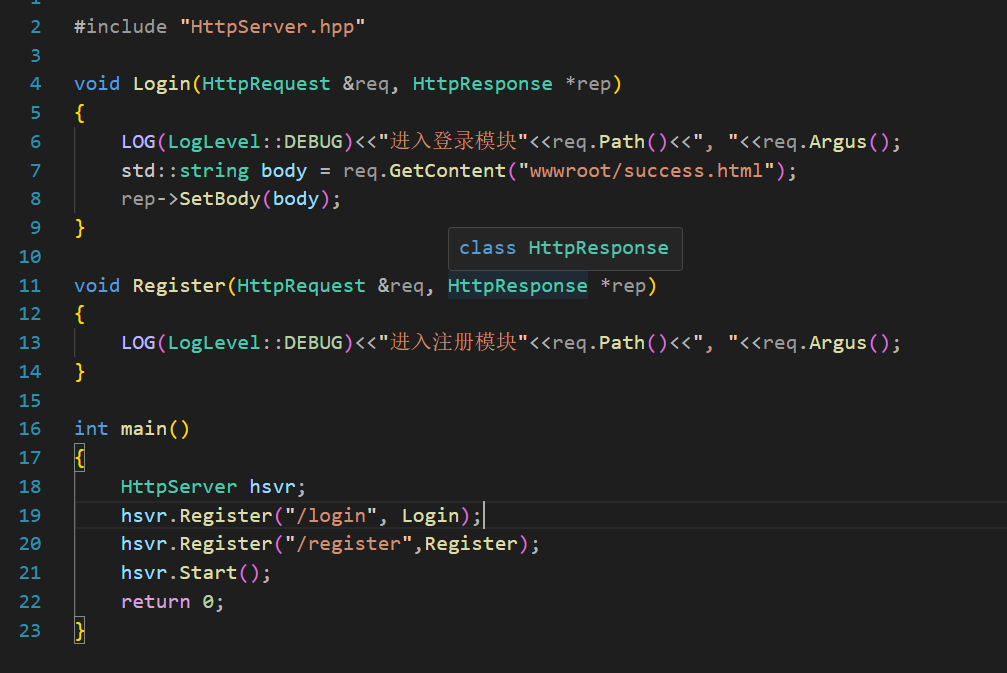
这里简单玩了一下,加入了一个注册功能,如果请求了这个动态资源,就返回一个还在建设中的页面,使用重定向完成
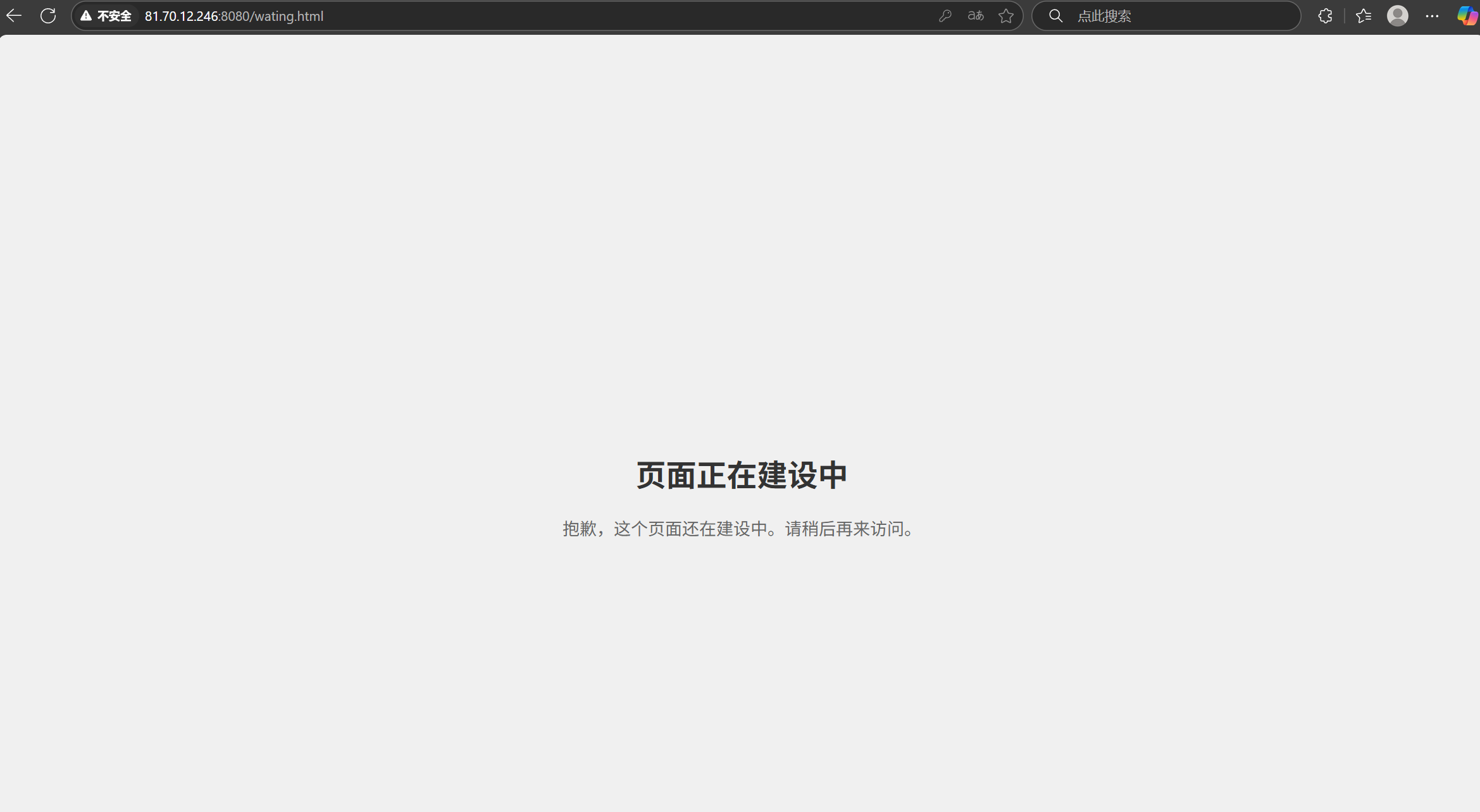
事实是,登录成功之后很多情况不会专门返回一个“登陆成功”,而是直接使用302跳转到对应的页面或者用前端代码完成这个功能。
再次理解什么是百度中的/s
s就是一个被百度工程师注册进来的名字(就像我们的register和login),浏览器把搜索框表单中的参数采用GET方法直接在URL中带参传递,解析出来/s和?后面的内容,找到/s对应的方法,就可以去执行对应的搜索逻辑了。
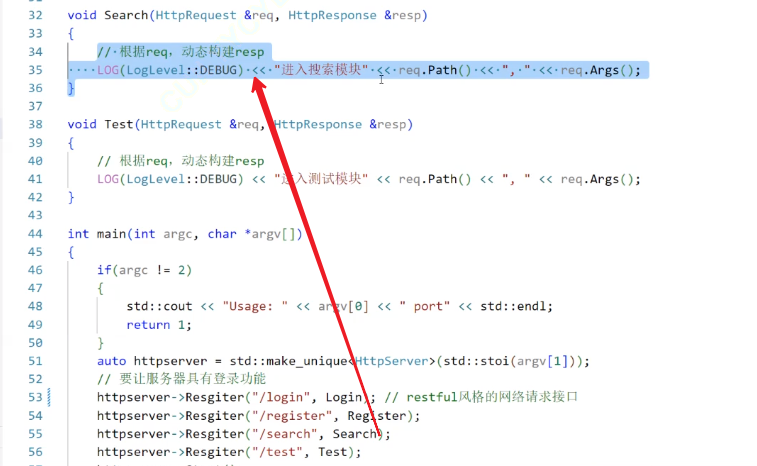
6. 整体文件
搭建的简单电商城http服务器 · 6771069 · lsnmjp/code of cpp Linux 算法 - Gitee.com
更新:
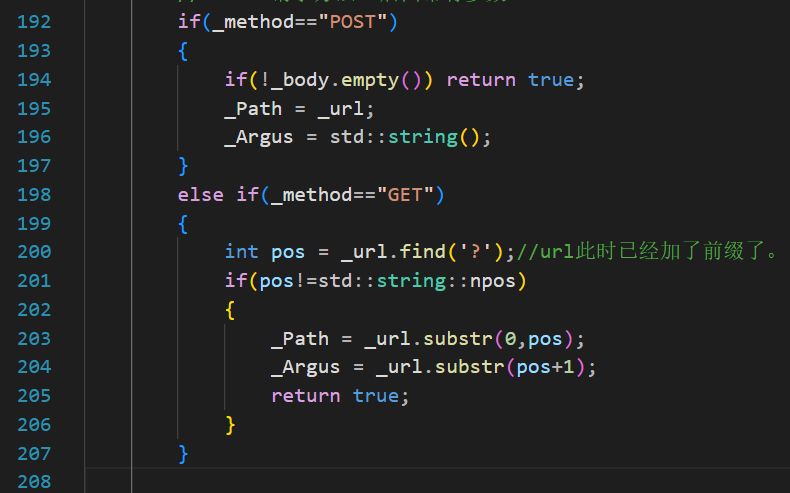
_Method_Url的解析应该对POST和GET都有效(如下),原代码存在POST请求总是404的问题。
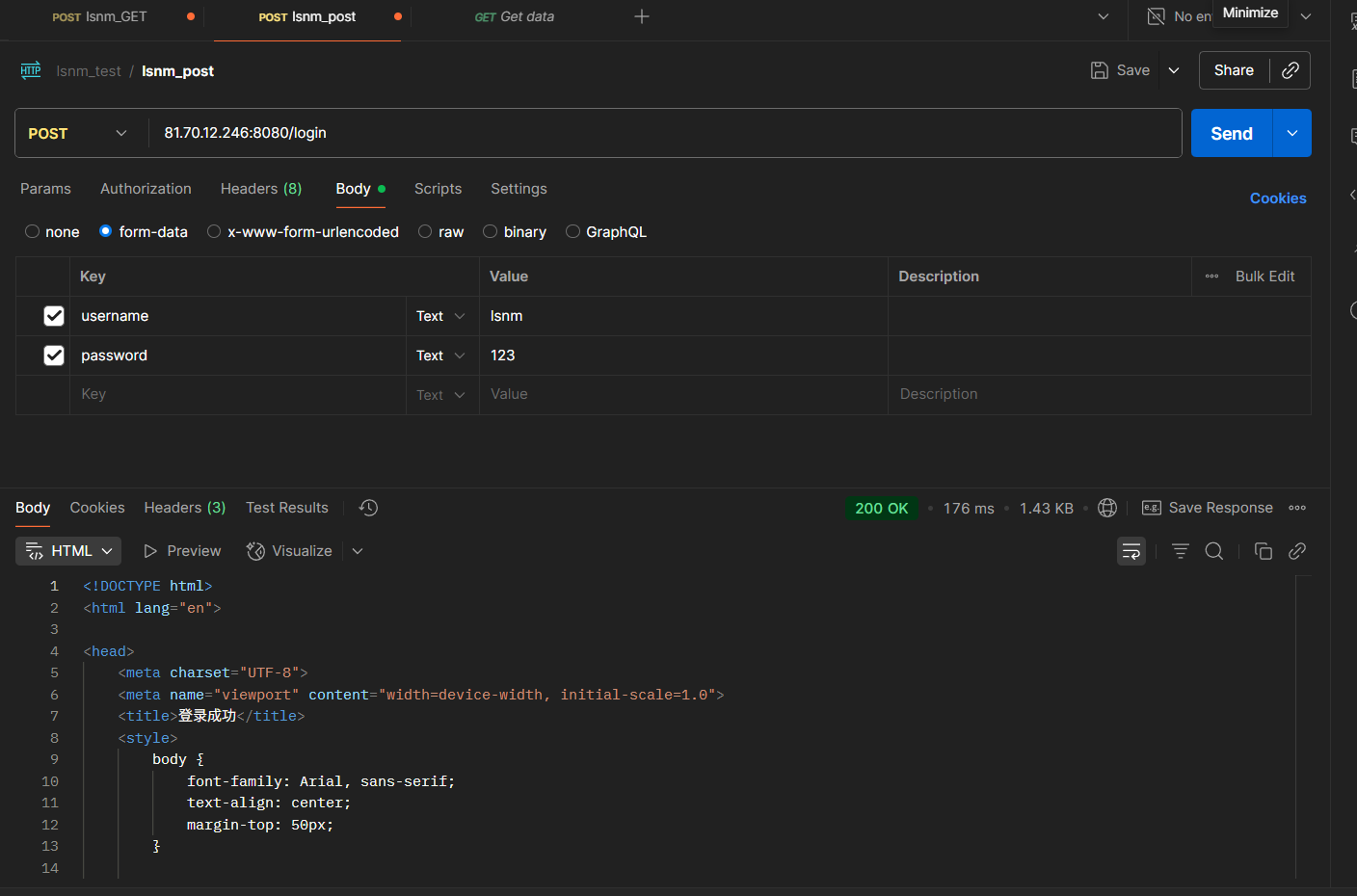
不过要注意,这个demo代码我们没有做完整性的检查,有时候请求失败是正常的。
另外,这个地方也需要调整:
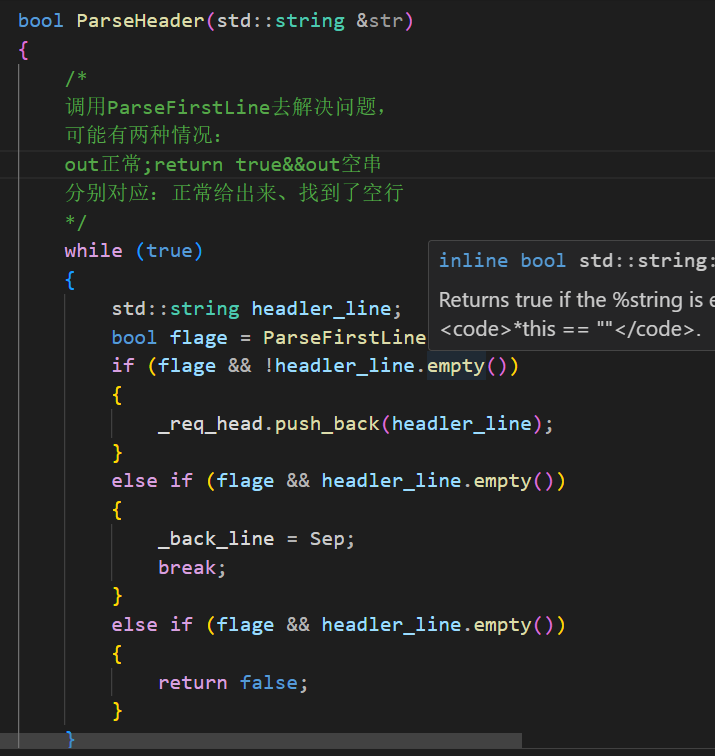
没有三种情况,只有两种情况。原来的第三种情况是给完整性检测用的。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)