手把手教你如何用Dify零成本搭建本地私有化部署知识库与agent
手把手教你如何用Dify零成本搭建本地私有化部署知识库与agent
1. Dify安装与部署(Linux系统使用Docker)
1.1 安装Docker
首先,确保你的Linux系统中已安装Docker。如果未安装,可以通过以下命令安装Docker:
# 更新apt索引
sudo apt-get update
# 安装Docker依赖
sudo apt-get install apt-transport-https ca-certificates curl software-properties-common
# 添加Docker的GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 添加Docker源
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 安装Docker CE(社区版)
sudo apt-get update
sudo apt-get install docker-ce
# 启动Docker并验证
sudo systemctl start docker
sudo systemctl enable docker
docker --version
1.2 安装Docker Compose(如果需要)
# 下载Docker Compose
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 授予执行权限
sudo chmod +x /usr/local/bin/docker-compose
# 检查安装是否成功
docker-compose --version
1.3 拉取Dify镜像并启动容器
# 拉取Dify镜像
docker pull dify/dify
# 启动Dify容器(你可以自定义端口等配置)
docker run -d -p 8000:8000 dify/dify
# 验证是否启动成功
docker ps
部署完dify,页面如下,有探索、工作室、知识库及工具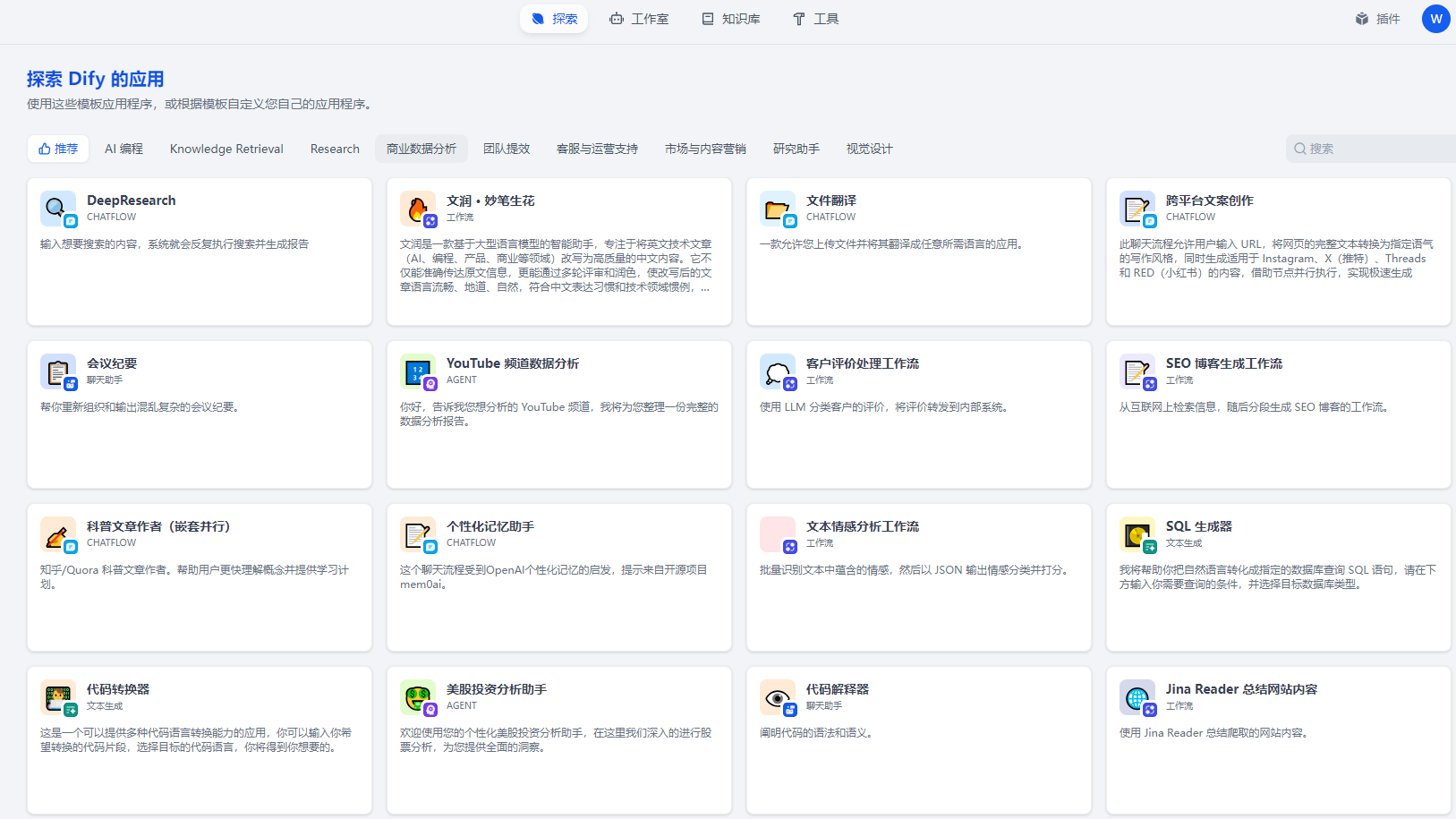
2. 搭建知识库
Dify支持多种格式的数据导入,尤其适用于结构化数据和非结构化数据。
2.1 上传与管理数据
你可以通过Dify的Web界面上传不同格式的文件,包括:
结构化数据:如Excel、CSV、数据库(MySQL、PostgreSQL等)。
非结构化数据:如PDF、PPT、Word文件、科学文献(Sci)、实验数据、文本资料等。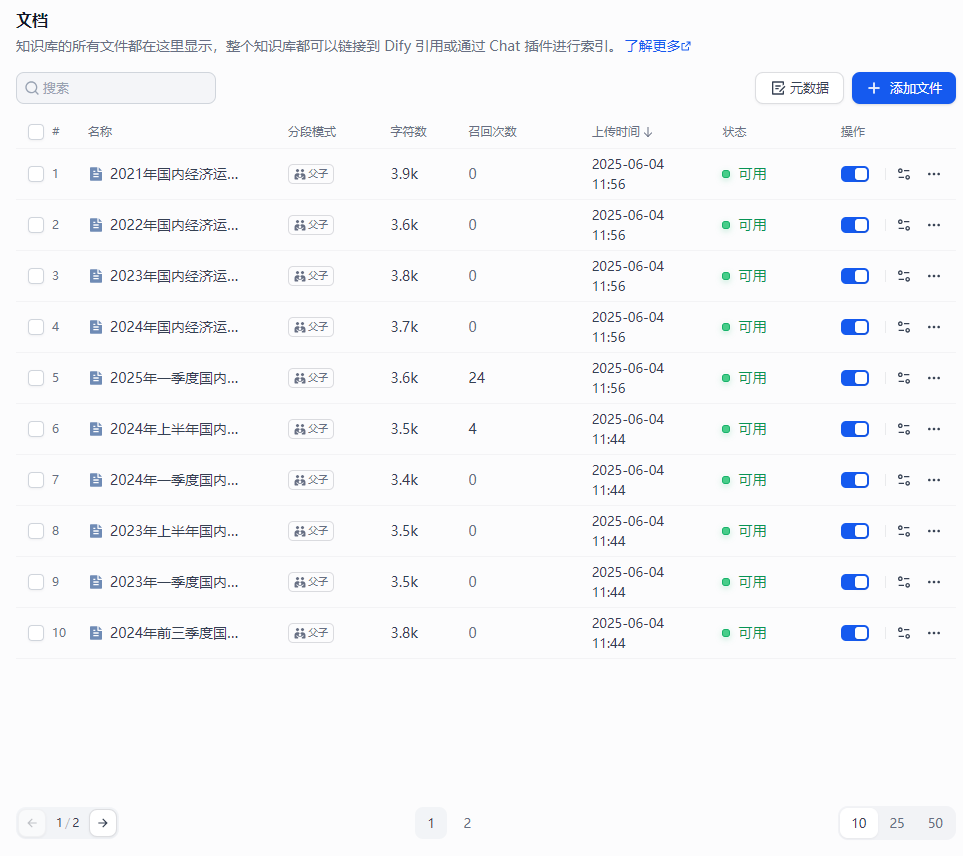
2.1.1 上传文件
在Dify的后台管理界面,进入知识库管理页面,选择“上传文件”,并选择你需要导入的文件(如PDF、PPT、Word等格式的文件)。系统将自动提取文本内容并将其结构化存储在数据库中。
2.1.2 处理结构化数据(Excel、CSV等)
通过Dify提供的数据导入工具,将Excel或CSV文件上传至系统,系统会自动识别并映射数据字段,将其保存为结构化数据,便于后续查询和分析。一般可以直接对文档进行拖拽拉取上传。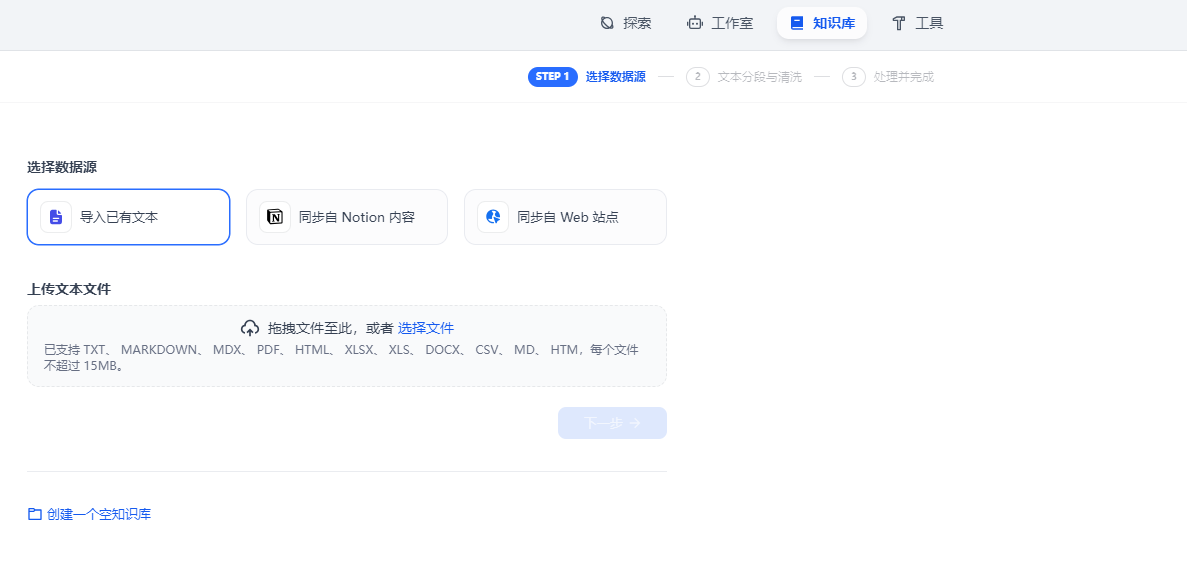
导入文件后,会有一个配置选项,需要勾选下,使用默认的方式,上传是最快的,如果让其自动分段,可以先预览下,有些QA文档是AI自动截取的,非结构化数据按照一定的文字段落并会直接截取,导致语义不通,牛头不对马嘴。所以推荐,最好的方式是自己先对语料文档进行预处理,上传速度也会变快。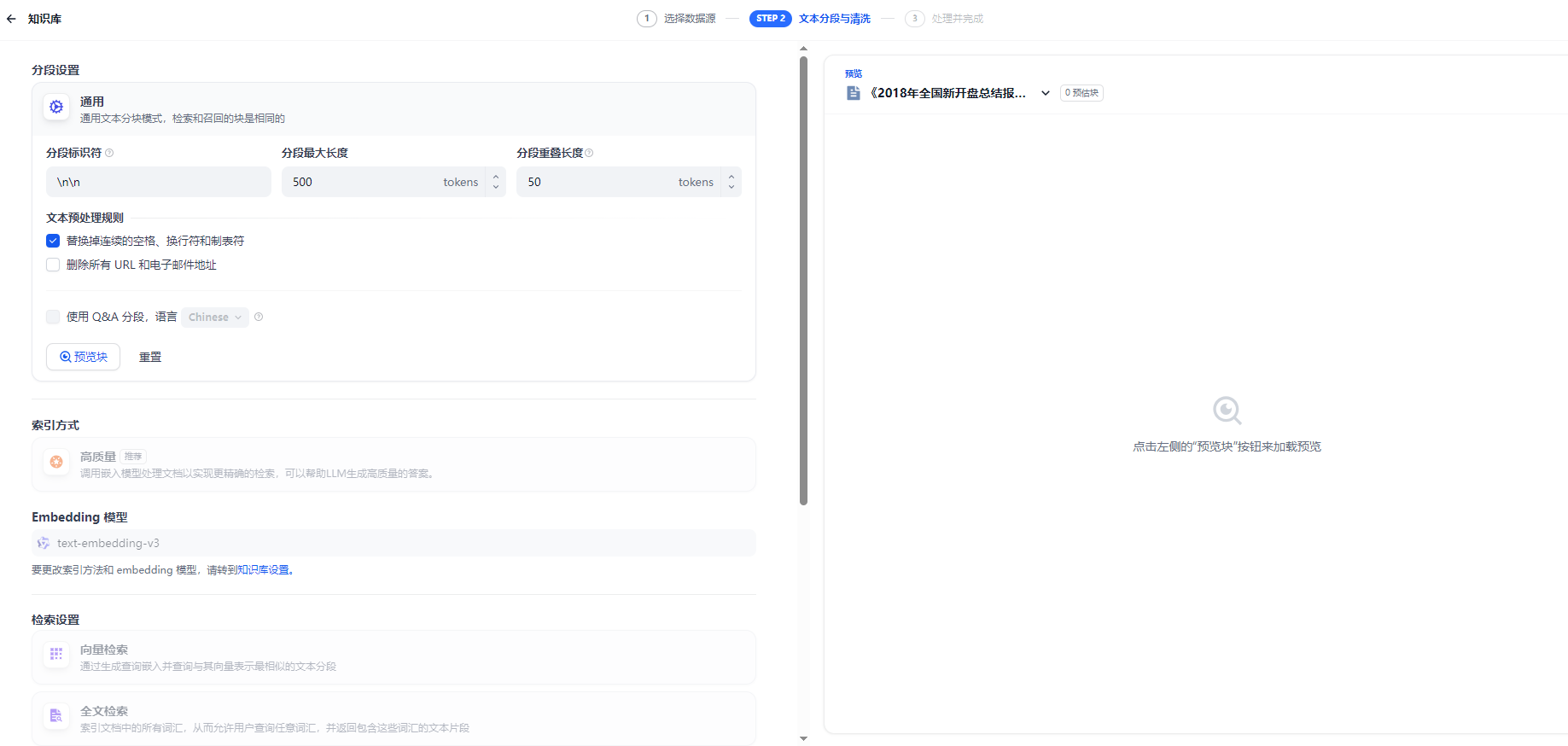
并且需要修改检索设置,一般选用混合检索、Rerank模型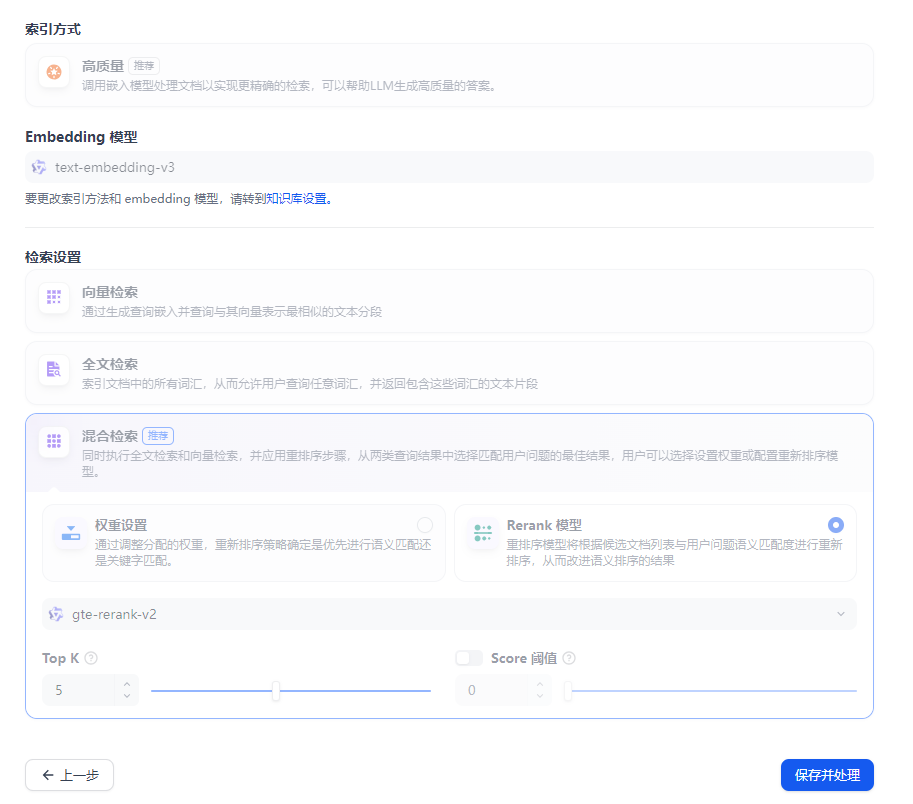 上传成功的话,可以点开看,每份文档的具体信息
上传成功的话,可以点开看,每份文档的具体信息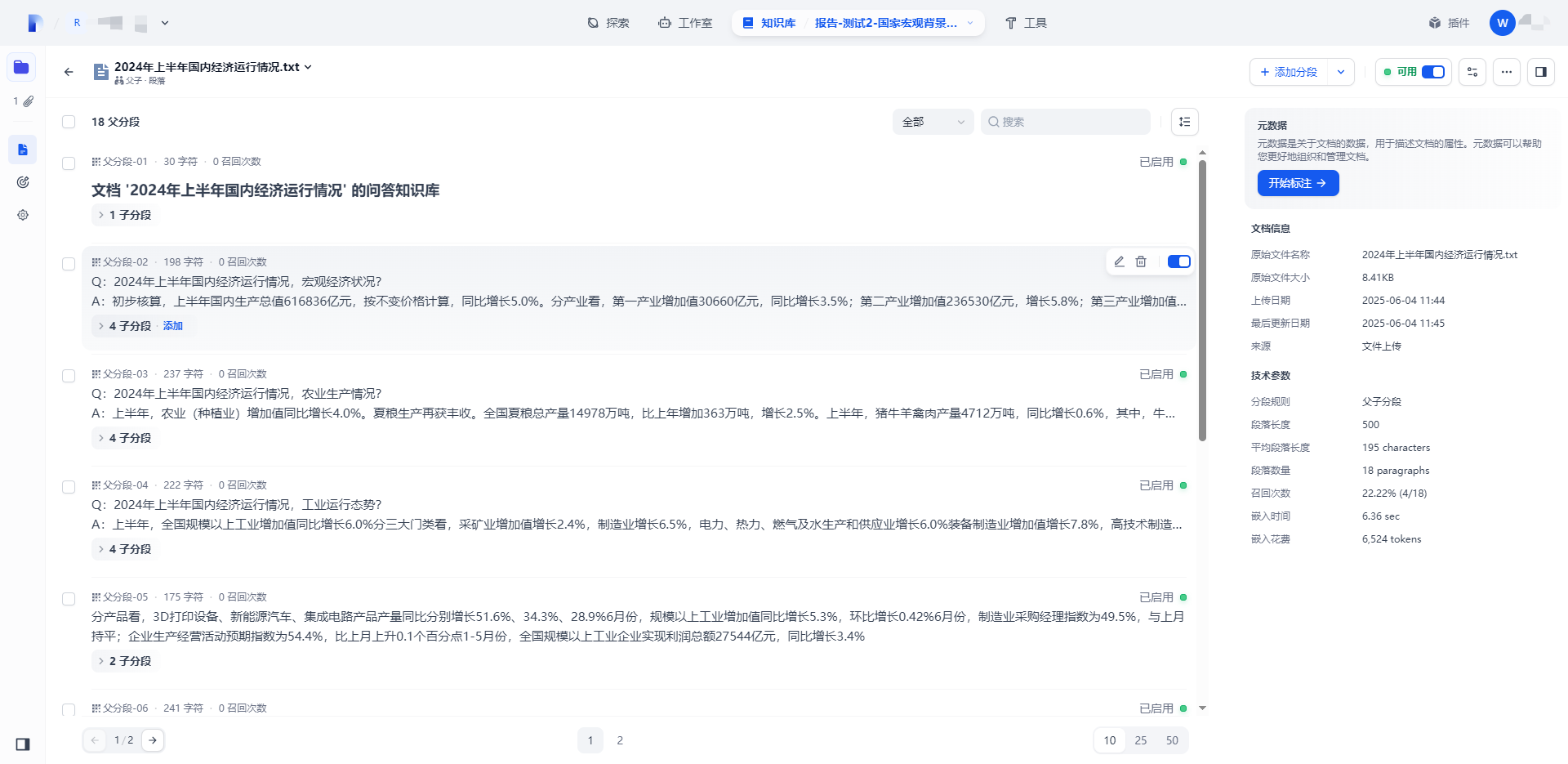
在知识库的构建过程中,分块和结构化的实现依赖于多个步骤,包括:
-
文本提取:通过Python中的PyPDF2、python-docx等库提取文档中的文本。
-
分块:通过NLP技术将文档按句子、段落或语义进行分块。
-
结构化:通过实体识别、关系抽取等技术提取关键信息,并存储到数据库或知识图谱中。
这种流程大多是通过编写代码实现的,结合了自然语言处理和数据库技术,使得文档中包含的知识可以转化为结构化的数据,方便后续的查询、分析和应用。
2.1.3 导入数据库数据
对于已有的数据库(如MySQL、PostgreSQL等),你可以配置数据库连接,Dify会定期同步并更新数据库中的数据,保持知识库内容的实时更新。
2.1.4 处理PDF、Word等非结构化数据
Dify通过内置的文档解析工具,将PDF、Word等文档中的文本内容提取并进行自然语言处理(NLP),以便将非结构化内容转化为结构化数据,便于查询。如考虑到内存问题,建议可以对文档进行预加工,变成.md或者.txt的格式进行上传。或转成QA对的形式,也可最大程度的保留语料的综合信息
class DocumentProcessor:
"""处理不同类型文档并提取文本内容"""
@staticmethod
def extract_from_pdf(file_path):
"""提取PDF文件内容,保留结构信息"""
try:
# 清理文件路径
clean_path = clean_filename(file_path)
logger.info(f"处理PDF文件: {clean_path}")
doc = fitz.open(file_path)
# 提取元数据
metadata = doc.metadata
metadata_text = "\n".join([f"{key}: {value}" for key, value in metadata.items() if value])
# 提取目录结构
toc = doc.get_toc()
toc_text = ""
if toc:
toc_text = "文档目录结构:\n" + "\n".join([f"{' ' * (level-1)}● {title} (页码: {page})" for level, title, page in toc])
# 提取文本内容(按页处理)
pages_text = []
for page_num in range(len(doc)):
page = doc.load_page(page_num)
page_text = f"【第{page_num+1}页】\n"
# 尝试提取表格
try:
tables = page.find_tables()
if tables and hasattr(tables, 'tables') and len(tables.tables) > 0:
for table_num, table in enumerate(tables.tables):
page_text += f"【表格{table_num+1}】\n"
if hasattr(table, 'rows'):
for row in table.rows:
try:
row_items = []
for cell in row.cells:
cell_text = ""
if hasattr(cell, 'text'):
cell_text = cell.text.strip()
elif isinstance(cell, tuple) and len(cell) > 0:
cell_text = str(cell[0]).strip()
row_items.append(cell_text)
page_text += " | ".join(row_items) + "\n"
except Exception as e:
logger.warning(f"处理表格行时出错: {str(e)}")
else:
page_text += "表格内容无法正确解析,请查看原文档。\n"
page_text += "\n"
except Exception as e:
logger.warning(f"页面 {page_num+1} 提取表格失败: {str(e)}")
# 添加页面文本
page_text += page.get_text()
pages_text.append(page_text)
# 合并所有内容
full_text = "\n".join(filter(None, [metadata_text, toc_text, "\n".join(pages_text)]))
doc.close()
return full_text
except Exception as e:
logger.error(f"PDF处理错误: {str(e)}")
import traceback
logger.error(traceback.format_exc())
return ""
@staticmethod
def extract_from_docx(file_path):
"""提取Word文件内容,保留结构信息"""
try:
logger.info(f"处理Word文件: {file_path}")
doc = docx.Document(file_path)
# 提取元数据
properties = doc.core_properties
props = ['author', 'category', 'comments', 'content_status',
'created', 'identifier', 'keywords', 'language',
'last_modified_by', 'last_printed', 'modified',
'revision', 'subject', 'title', 'version']
metadata_text = "\n".join([f"{prop}: {getattr(properties, prop, None)}"
for prop in props if getattr(properties, prop, None)])
# 提取文档结构(标题和内容)
content_text = ""
heading_texts = []
current_headings = [None] * 10 # 假设最大标题层级为9
for paragraph in doc.paragraphs:
if paragraph.style.name.startswith('Heading'):
level = int(paragraph.style.name.replace('Heading ', ''))
# 更新当前标题层级
current_headings[level-1] = paragraph.text
for i in range(level, 10):
current_headings[i] = None
# 构建完整标题路径
heading_path = [h for h in current_headings[:level] if h]
# 添加到标题文本列表
heading_prefix = ">" * level
heading_texts.append(f"{heading_prefix} {paragraph.text}")
# 添加段落内容
if paragraph.text.strip():
if paragraph.style.name.startswith('Heading'):
content_text += f"\n{paragraph.text}\n"
else:
content_text += f"{paragraph.text}\n"
# 提取表格
tables_text = ""
for i, table in enumerate(doc.tables):
tables_text += f"\n【表格{i+1}】\n"
for row in table.rows:
row_text = " | ".join([cell.text.strip() for cell in row.cells])
tables_text += f"{row_text}\n"
# 合并所有内容
heading_structure = "\n".join(heading_texts)
full_text = "\n\n".join(filter(None, [
metadata_text,
"文档结构:\n" + heading_structure if heading_structure else "",
"内容:\n" + content_text if content_text else "",
tables_text
]))
return full_text
except Exception as e:
logger.error(f"Word处理错误: {str(e)}")
return ""
@staticmethod
def extract_from_pptx(file_path):
"""提取PowerPoint文件内容,保留结构信息"""
try:
logger.info(f"处理PowerPoint文件: {file_path}")
prs = Presentation(file_path)
# 提取元数据
core_properties = prs.core_properties
props = ['author', 'category', 'comments', 'content_status',
'created', 'identifier', 'keywords', 'language',
'last_modified_by', 'last_printed', 'modified',
'revision', 'subject', 'title', 'version']
metadata_text = "\n".join([f"{prop}: {getattr(core_properties, prop, None)}"
for prop in props if getattr(core_properties, prop, None)])
# 提取幻灯片内容
slides_text = []
for slide_num, slide in enumerate(prs.slides):
slide_text = [f"【幻灯片 {slide_num+1}】"]
# 提取幻灯片标题
if slide.shapes.title:
slide_text.append(f"标题: {slide.shapes.title.text}")
# 提取幻灯片内容
for shape in slide.shapes:
if hasattr(shape, "text") and shape.text.strip() and shape != slide.shapes.title:
# 检查是否为表格
if shape.has_table:
slide_text.append("【表格】")
table = shape.table
for row in range(len(table.rows)):
row_data = []
for col in range(len(table.columns)):
cell = table.cell(row, col)
row_data.append(cell.text.strip())
slide_text.append(" | ".join(row_data))
else:
slide_text.append(shape.text)
slides_text.append("\n".join(slide_text))
# 合并所有内容
full_text = "\n\n".join(filter(None, [metadata_text, "\n\n".join(slides_text)]))
return full_text
except Exception as e:
logger.error(f"PowerPoint处理错误: {str(e)}")
return ""
@staticmethod
def extract_from_xlsx(file_path):
"""提取Excel文件内容,保留结构信息"""
try:
logger.info(f"处理Excel文件: {file_path}")
import pandas as pd
# 读取Excel文件的所有工作表
xl = pd.ExcelFile(file_path)
sheet_names = xl.sheet_names
# 提取元数据(如果有)
metadata_text = ""
try:
from openpyxl import load_workbook
wb = load_workbook(filename=file_path, read_only=True)
properties = wb.properties
props = ['creator', 'lastModifiedBy', 'created', 'modified',
'title', 'subject', 'description', 'keywords', 'category']
metadata_text = "\n".join([f"{prop}: {getattr(properties, prop, None)}"
for prop in props if getattr(properties, prop, None)])
except Exception as e:
logger.warning(f"无法读取Excel元数据: {str(e)}")
# 提取每个工作表的内容
sheets_content = []
for sheet_name in sheet_names:
df = pd.read_excel(file_path, sheet_name=sheet_name)
# 获取工作表基本信息
sheet_info = [
f"\n【工作表: {sheet_name}】",
f"行数: {len(df)}, 列数: {len(df.columns)}",
f"列名: {', '.join(str(col) for col in df.columns)}"
]
# 尝试智能分析工作表结构
structure_info = []
# 检查是否有日期列
date_cols = [str(col) for col in df.columns if pd.api.types.is_datetime64_any_dtype(df[col])]
if date_cols:
structure_info.append(f"日期列: {', '.join(date_cols)}")
# 检查是否有数值列
numeric_cols = [str(col) for col in df.columns
if pd.api.types.is_numeric_dtype(df[col]) and not pd.api.types.is_bool_dtype(df[col])]
if numeric_cols:
structure_info.append(f"数值列: {', '.join(numeric_cols)}")
# 添加工作表数据
try:
# 先尝试将DataFrame转换为格式化的字符串表格
table_str = df.to_string(index=False)
sheet_content = "\n".join(sheet_info + structure_info + [table_str])
except Exception as e:
logger.warning(f"无法将工作表 {sheet_name} 转换为字符串表格: {str(e)}")
# 如果失败,则改用更基本的方法
basic_content = sheet_info + structure_info
# 添加列名和数据
cols_str = " | ".join([str(col) for col in df.columns])
basic_content.append(cols_str)
basic_content.append("-" * len(cols_str))
# 添加行数据
for _, row in df.iterrows():
basic_content.append(" | ".join([str(val) for val in row.values]))
sheet_content = "\n".join(basic_content)
sheets_content.append(sheet_content)
# 合并所有工作表内容
full_text = "\n\n".join(filter(None, [
metadata_text,
f"工作表数量: {len(sheet_names)}",
"\n\n".join(sheets_content)
]))
return full_text
except Exception as e:
logger.error(f"Excel处理错误: {str(e)}")
import traceback
logger.error(traceback.format_exc())
return ""
@staticmethod
def process_file(file_path):
"""根据文件类型选择合适的处理方法"""
file_ext = os.path.splitext(file_path)[1].lower()
file_type_handlers = {
'.pdf': DocumentProcessor.extract_from_pdf,
'.docx': DocumentProcessor.extract_from_docx,
'.pptx': DocumentProcessor.extract_from_pptx,
'.xlsx': DocumentProcessor.extract_from_xlsx,
'.xls': DocumentProcessor.extract_from_xlsx,
}
if file_ext in file_type_handlers:
return file_type_handlers[file_ext](file_path)
else:
logger.error(f"不支持的文件类型: {file_ext}")
return ""
3. 搭建Agent
3.1 配置Agent
Dify的Agent是用于自动化与知识库的交互的工具,能够帮助用户通过API调用和知识库进行交互。你可以根据需求创建多个Agent,并为其指定特定的功能和权限。
3.1.1 创建Agent
通过Dify的管理界面,选择“Agent”模块,点击“创建Agent”。你可以为Agent指定一个名称、角色、权限以及关联的知识库。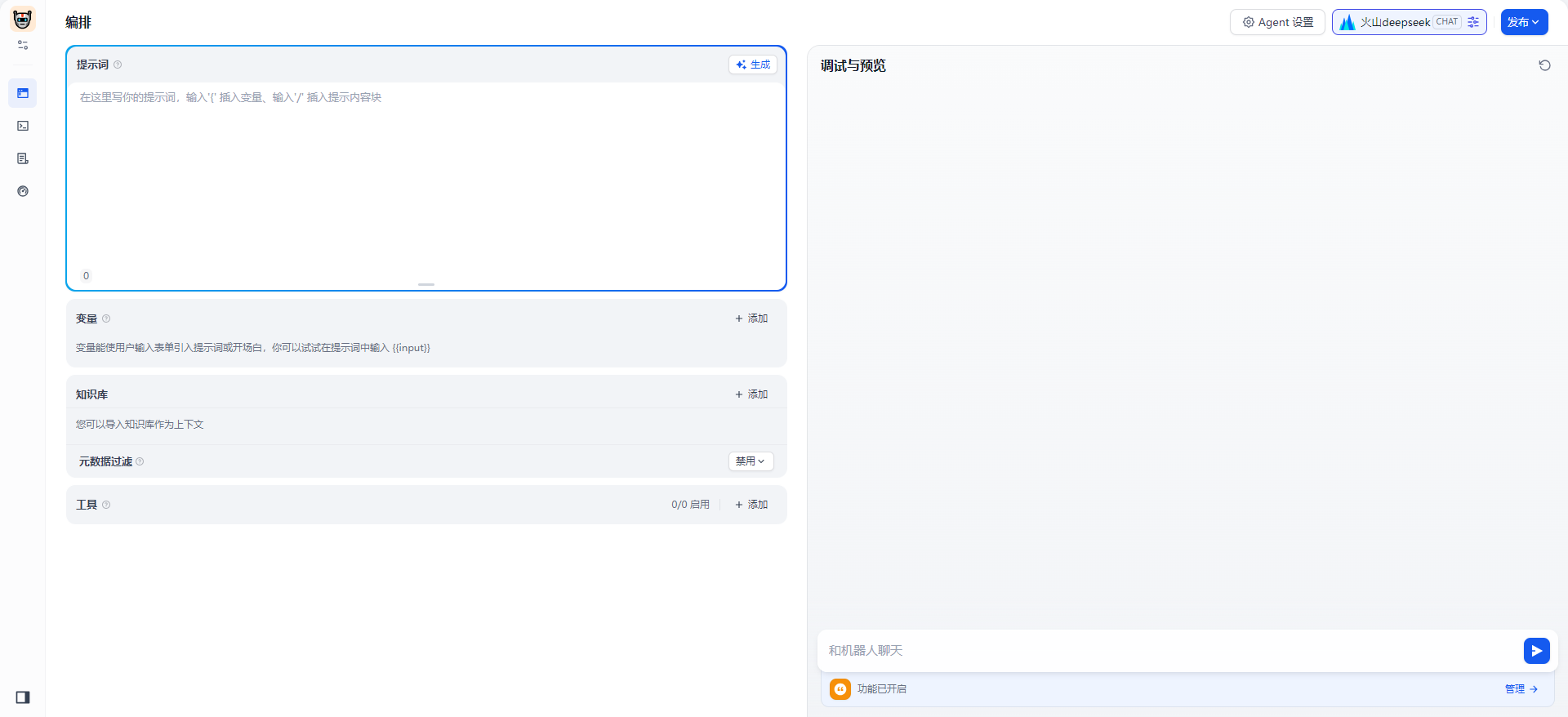
3.1.2 配置Agent的API调用
创建Agent后,可以通过API与它进行交互。具体的API文档可以在Dify的开发者文档中找到,你可以使用REST API与Agent进行通信。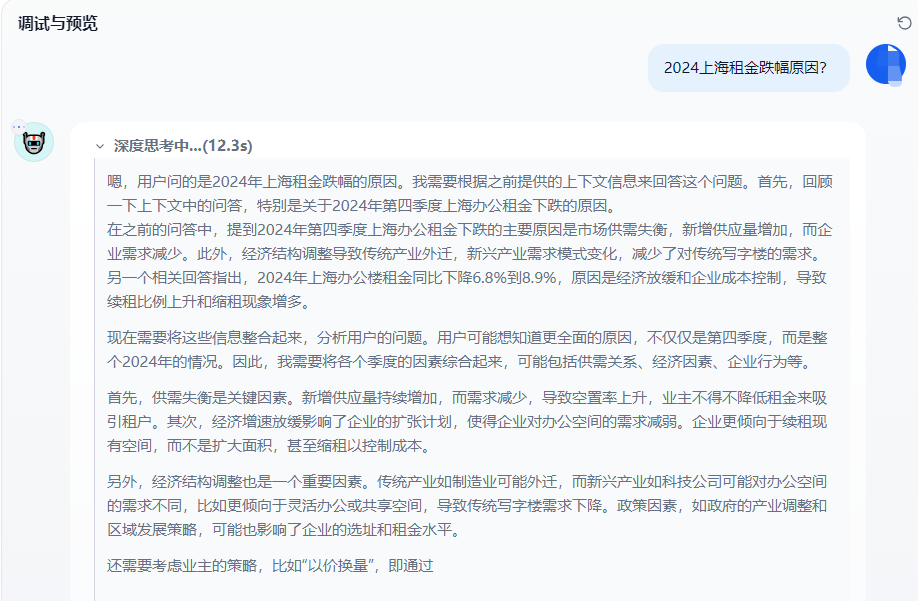
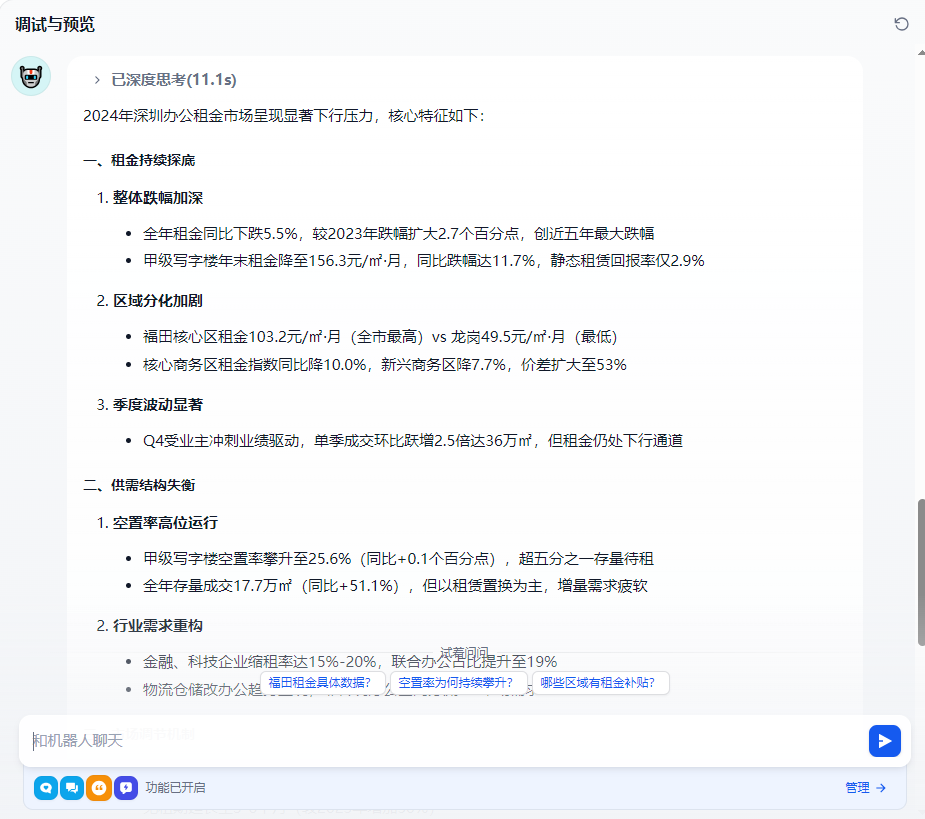
3.2 连接API与Token
3.2.1 获取Token
在Dify后台,选择“API管理”模块,生成一个新的API Token。这个Token用于认证你的API请求。
3.2.2 使用Token进行API调用
通过获取到的Token,你可以与Dify的API进行交互,例如上传数据、查询数据、启动Agent等。
# 示例API请求(使用curl工具)
curl -X POST "http://<your_server_ip>:8000/api/v1/query" \
-H "Authorization: Bearer <Your_API_Token>" \
-d '{"query": "生物医药科研"}'
4. 将知识库应用于生物医药科研
在生物医药科研领域,Dify的知识库可以通过以下几种方式来优化和提升工作效率:
4.1 导入科学文献与课本知识
你可以通过上传大量的科研论文、课本资料、实验数据等,构建一个全面的生物医药知识库。Dify可以自动将这些非结构化数据(如PDF、PPT、Word文件)转换为可查询的结构化数据,便于在研究中快速查询和获取信息。
4.2 知识图谱与数据分析
通过Dify的知识图谱功能,可以将不同领域的知识(如药物、疾病、基因等)进行关联分析。通过自然语言处理(NLP)技术,Dify能够自动提取文献中的关键词和关联性,为科研人员提供更深层次的研究洞察。
4.3 数据挖掘与信息提取
你可以通过Dify的API和Agent,定期从知识库中提取最新的科研成果或临床数据。将这些信息整合到生物医药领域的科研流程中,帮助科研人员更快地获取最新的文献和实验数据。
4.4 与其他科研工具集成
Dify还支持与其他科研工具(如R、Python、Jupyter等)进行集成,便于进行高级的数据分析和建模。例如,你可以将Dify中的数据导入到R中进行统计分析,或者使用Python进行机器学习建模。
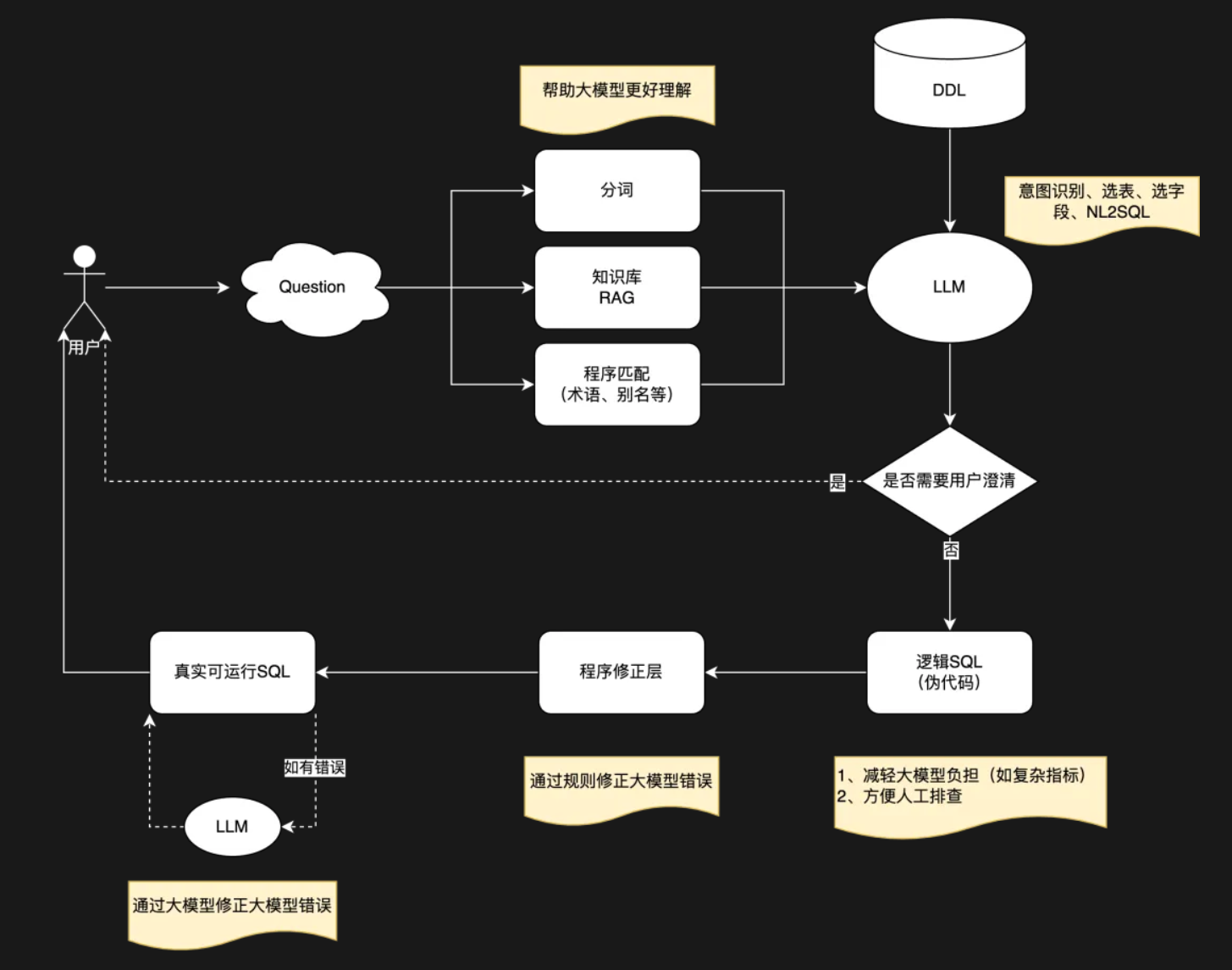
5. 搭建Dify AI 数据查询助手思路

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)