OnePass 聚类算法讲解及python实战
算法流程核心一句话每次处理新的数据时,会决定将其分配到现有的一个Cluster中,或者创建一个new Cluster。这取决于数据点与现有簇的相似度(距离)。关键步骤初始化:开始时,簇是空的。开始遍历所有数据:遍历下一个点(最后一个点截止):判断是否存在cluster, 不存在则将第一个数据点作为new cluster的第一个数据点,之后返回1, 如果存在则开始3计算该数据点与现有的所有clust

算法流程
核心一句话
每次处理新的数据时,会决定将其分配到现有的一个Cluster中,或者创建一个new Cluster。这取决于数据点与现有簇的相似度(距离)。
关键步骤
初始化:开始时,簇是空的。
开始遍历所有数据:
遍历下一个点(最后一个点截止):
判断是否存在cluster, 不存在则将第一个数据点作为new cluster的第一个数据点,之后返回1, 如果存在则开始3
计算该数据点与现有的所有cluster之间的相似度(距离)。得到最小的距离,如果相似度低于阈值则将数据点分配到最相似的cluster中,并更新簇的中心(如簇的质心或平均值),之后开始1。如果大于阈值,则创建new cluster并将该数据点添加到cluster中。
简单实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_distances, euclidean_distances
def cal_distance(x, y, mod="euc"):
if mod == "cos":
distance = cosine_distances(X=x.reshape(1, -1),
Y=y.reshape(1, -1)) # 与簇的质心的最小距离
distance = distance[0][0]
return distance
elif mod == "euc":
distance = euclidean_distances(X=x.reshape(1, -1),
Y=y.reshape(1, -1))
distance = distance[0][0]
return distance
class OnePassClustering:
def __init__(self, threshold):
self.threshold = threshold # 相似性阈值
self.clusters = [] # 初始为空簇
def fit(self, data):
for point in data:
self._add_point_to_cluster(point)
def _add_point_to_cluster(self, point):
if not self.clusters:
self.clusters.append([point])
return
# 计算点到每个簇质心的距离
distances = [cal_distance(point, np.mean(cluster, axis=0)) for cluster in self.clusters]
# 找到最近的簇
min_distance = min(distances)
closest_cluster_index = distances.index(min_distance)
if min_distance < self.threshold:
self.clusters[closest_cluster_index].append(point)
else:
self.clusters.append([point])
def get_clusters(self):
return self.clusters
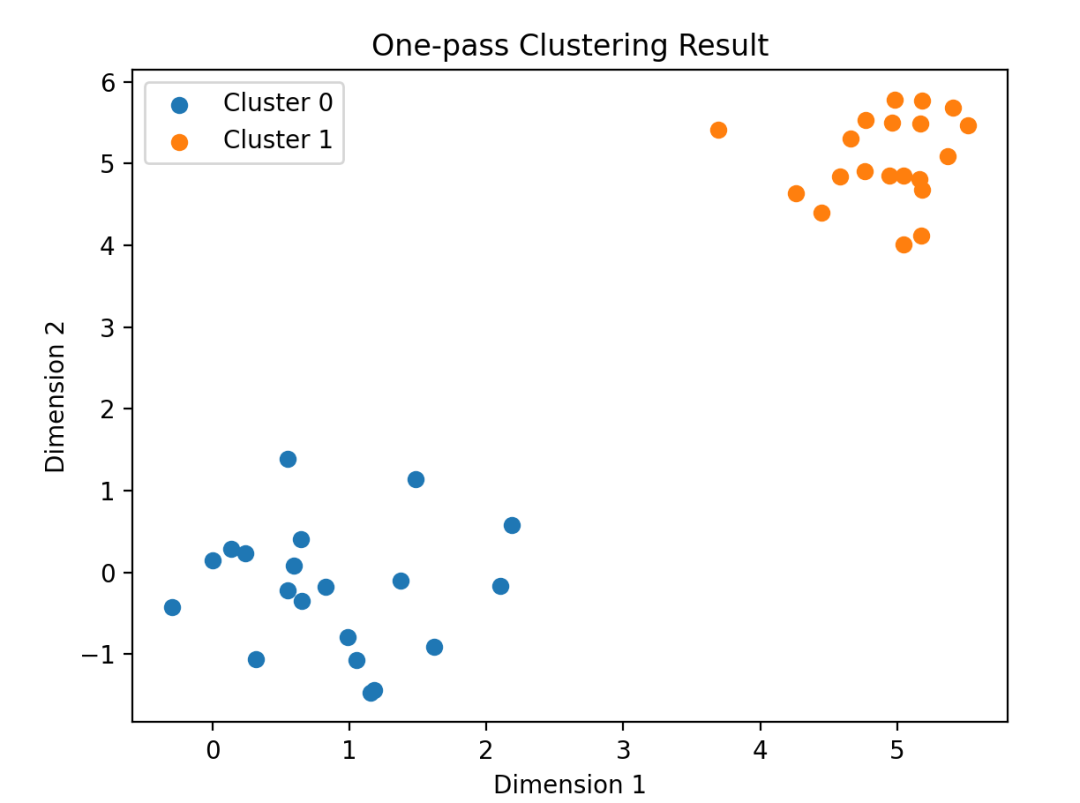
np.random.seed(42)
data = np.random.randn(20, 2) * 0.75 + np.array([1, 0])
data = np.append(data, np.random.randn(20, 2) * 0.5 + np.array([5, 5]), axis=0)
one_pass_cluster = OnePassClustering(threshold=2)
one_pass_cluster.fit(data)
for i, cluster in enumerate(one_pass_cluster.clusters):
cluster = np.array(cluster)
plt.scatter(cluster[:, 0], cluster[:, 1], label=f"Cluster {i}")
plt.title("One-pass Clustering Result")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.legend()
plt.show()
更结构化的实现
import numpy as np
from typing import List
from matplotlib import pyplot as plt
from sklearn.metrics.pairwise import cosine_distances, euclidean_distances
def cal_distance(x, y, mod="euc"):
if mod == "cos":
distance = cosine_distances(X=x.reshape(1, -1),
Y=y.reshape(1, -1)) # 与簇的质心的最小距离
distance = distance[0][0]
return distance
elif mod == "euc":
distance = euclidean_distances(X=x.reshape(1, -1),
Y=y.reshape(1, -1))
distance = distance[0][0]
return distance
class ClusterUnit:
def __init__(self):
self.node_list: List[int] = [] # 该簇存在的节点列表
self.node_num = 0 # 该簇节点数
self.centroid = None # 该簇质心
def add_node(self, node_index, node_vec):
self.node_list.append(node_index)
if self.node_num == 0:
self.centroid = np.array(node_vec) * 1.0
else:
self.centroid = (self.node_num * self.centroid + node_vec) / (self.node_num + 1)
self.node_num += 1
class OnePassCluster:
def __init__(self, threshold):
self.threshold = threshold
self.vectors = None
self.cluster_list: List[ClusterUnit] = []
self.cluster_num = None
def fit(self, vector_list: List):
self.vectors = np.array(vector_list)
self.clustering()
self.cluster_num = len(self.cluster_list)
def clustering(self):
self.cluster_list.append(ClusterUnit()) # 初始新建一个簇
self.cluster_list[0].add_node(0, self.vectors[0]) # 将读入的第一个节点归于该簇
for index in range(1, len(self.vectors)):
min_distance = cal_distance(x=self.vectors[index],
y=self.cluster_list[0].centroid) # 与簇的质心的最小距离
min_cluster_index = 0 # 最小距离的簇的索引
for cluster_index, cluster in enumerate(self.cluster_list[1:]):
# 寻找距离最小的簇,记录下距离和对应的簇的索引
distance = cal_distance(x=self.vectors[index],
y=cluster.centroid)
if distance < min_distance:
min_distance = distance
min_cluster_index = cluster_index + 1
if min_distance < self.threshold: # 最小距离小于阀值,则归于该簇
self.cluster_list[min_cluster_index].add_node(index, self.vectors[index])
else: # 否则新建一个簇
new_cluster = ClusterUnit()
new_cluster.add_node(index, self.vectors[index])
self.cluster_list.append(new_cluster)
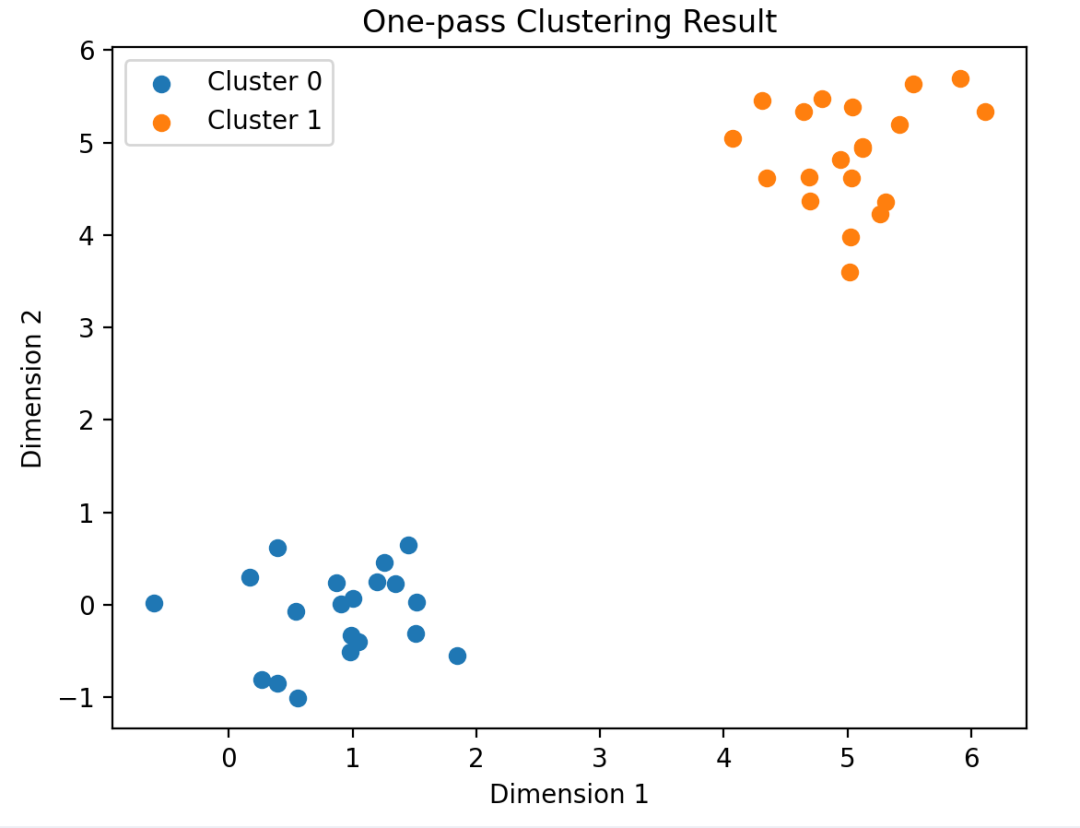
if __name__ == '__main__':
data = np.random.randn(20, 2) * 0.75 + np.array([1, 0])
data = np.append(data, np.random.randn(20, 2) * 0.5 + np.array([5, 5]), axis=0)
one_pass = OnePassCluster(threshold=2)
one_pass.fit(data.tolist())
for i, cluster in enumerate(one_pass.cluster_list):
cluster = np.array([data[node_id] for node_id in cluster.node_list])
plt.scatter(cluster[:, 0], cluster[:, 1], label=f"Cluster {i}")
plt.title("One-pass Clustering Result")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.legend()
plt.show()
算法的优缺点
优点
计算效率高,只遍历一次数据即可。
可以online update
缺点
依赖于阈值的选择(需要实验)
对噪声敏感
参考
https://blog.csdn.net/Totoro1745/article/details/78681329
https://www.cnblogs.com/little-horse/p/11688801.html
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 3
3 0
0- 0


 已为社区贡献13条内容
已为社区贡献13条内容










 服务器0元试用
服务器0元试用
所有评论(0)