【k8s】6.pod控制器(二):pod拓扑分布约束,优先级与抢占,pod驱逐
比如 kubelet 还来不及驱逐,Node 上的资源就被耗尽导致宕机,此时 control-plane 无法正常和该节点通信,拿不到节点上的 Pod 的状态,因此会做最坏的打算,认为这些 Pod 都挂了,因此会将该 Node 上的所有 Pod 都驱逐到其他节点重新跑起来,以保证高可用。node-eviction-rate: 驱赶 Node 的速率,由令牌桶流控算法实现,默认为 0.1,即每秒驱赶
目录
1. pod的拓扑分布约束
(1) 字段定义
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>- maxSkew:pod 分布不均的程度,是任意两个拓扑域中匹配的 pod 之间的最大允许差值
- topologyKey:节点标签的key,如果两个节点有相同的key和value,认为两节点处于同一拓扑域
- whenUnsatisfiable:如果 pod 不满足分布约束时如何处理,有两个取值:
- DoNotSchedule(默认):不满足分布约束时不调度
- ScheduleAnyway:不满足分布约束时仍调度,但会尽量将偏差最小化
- labelSelector:查找匹配的 pod,只有标签匹配的 pod 才会被统计
(2) 拓扑定义示例
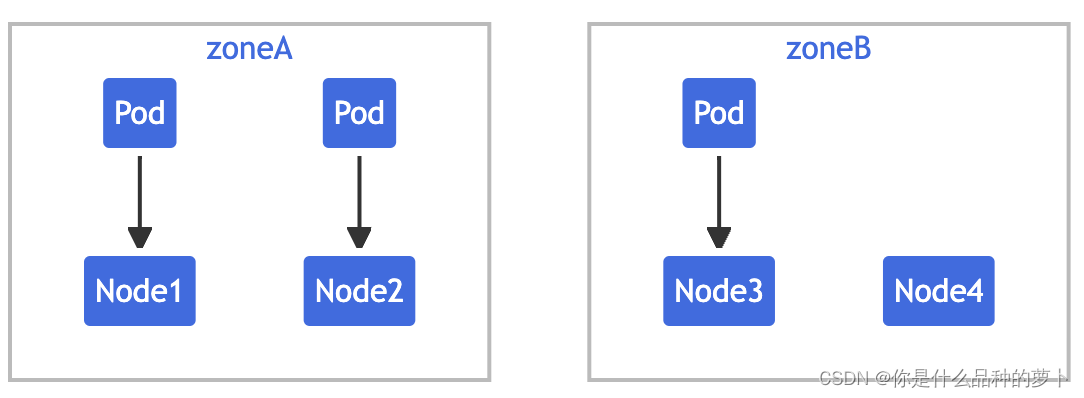
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB同时有 label 为 foo: bar 的 3 个 Pod 分别位于 node1、node2 和 node3 中。那么,从逻辑上看集群如下:

kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- maxSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: pause
image: registry.k8s.io/pause:3.1那么在pod调度时:
-
为满足zone偏差值不超过1,mypod只能放入zoneB中
-
为满足node偏差值不超过1,mypod只能放在node4上
当定义了多个约束,容易发生冲突,若出现冲突,pod 会一直 Pending
2. pod优先级与抢占
(1) 定义PriorityClass
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"-
value:值越大,优先级越高
-
preemptionPolicy:是否抢占,有两个取值:
-
PreemptLowerPriority(默认):允许抢占低优先级的pod
-
Never:不能抢占其他pod
-
-
globalDefault:是否应用于没有设置priorityClassName的pod
(2) 设置pod优先级
apiVersion: v1
kind: Pod
spec:
containers:
- name: nginx
image: nginx
priorityClassName: high-priority那么,pod 的调度策略:
-
调度器会按优先级对悬决 pod 进行排序, 高优先级 pod 会比低优先级 pod 更早调度
-
当调度某一个 pod 时,若未找到满足其要求的节点,触发对悬决 pod 的抢占逻辑,抢占逻辑会在该节点中驱逐一个或多个低优先级的 pod,将此高优先级 pod 调度到该节点上
(3) pod 的抢占策略与 pod 间亲和性冲突时会怎样
-
高优先级 pod 未找到合适的调度节点,需要抢占低优先级 pod
-
高优先级 pod 与此节点上的其他 pod 具有 pod 间亲和性
-
如果将低优先级 pod 删除,会违背亲和性原则,导致高优先级 pod 无法被调度
3. pod的驱逐
-
API调用 :如节点维护时,用户调用
-
Kubelet周期性检查 :检查本节点资源,当资源不足时,按优先级驱逐部分 pod
-
Controller Manager周期性检查 :检查所有节点,当节点处于 NotReady 一段时间,驱逐该节点上所有 Pod
-
Scheduler抢占式调度 :抢占式调度时可能会驱逐低优先级 Pod 给高优先级 Pod 腾出空间
3.1 API驱逐
3.2 Kubelet发起的驱逐
(1) 节点状态获取
-
memory.available
-
nodefs.available
-
nodefs.inodesFree
-
imagefs.available
-
imagefs.inodesFree
-
pid.available
(2) 驱逐条件
kubelet 使用 [eviction-signal][operator][quantity] 格式定义驱逐条件,比如 memory.available<10
根据紧急程度驱逐条件又分为软驱逐和硬驱逐:
-
软驱逐 eviction-soft(非紧急,可设置宽限期)
-
eviction-soft驱逐条件:如memory.available<1.5Gi
-
eviction-soft-grace-period宽限期:达到驱逐条件多久之后开始出发驱逐pod
-
eviction-max-pod-grace-period最大 Pod 宽限期:给 pod 优雅终止的时间
-
-
硬驱逐 eviction-hard(紧急,没有容忍时间,立即kill pod)
-
k8s的默认硬驱逐条件:memory.available<100Mi,nodefs.available<10%,imagefs.available<15%,nodefs.inodesFree<5% (Linux nodes)
-
同时,为了提升稳定性,减少 pod 驱逐次数,kubelet 在执行驱逐前会进行一次垃圾回收。如果本地垃圾回收后资源充足了就不再驱逐:
-
磁盘资源回收:回收死亡 pod 和容器,删除未使用的镜像
-
cpu/内存资源回收:只能通过驱逐 pod 方式
(3) 给节点打标记
kubelet 把获取的节点指标(内存、磁盘、pid状态),写入到节点对象的 status.condition 里
condition常见取值:
-
Ready(就绪):节点正常运行
-
NodeReady(未就绪):kubelet存在通信等问题
-
OutOfDisk(磁盘空间不足):节点磁盘空间不足,无法继续运行工作负载。
-
MemoryPressure(内存压力):pod驱逐时
-
DiskPressure(磁盘压力):pod驱逐时
-
PIDPressure(PID压力):节点PID不足,pod驱逐时
-
NetworkUnavailable(网络不可用)
(4) 驱逐目标的选择策略
-
pod 的优先级:priorityClass定义的优先级
-
pod 使用的内存资源是否超过请求值(即request中的limit值)
-
Pod 使用的内存资源相对于请求值的百分比:百分比越高则越容易别驱逐
-
磁盘消耗大的 pod 会优先驱逐
(5) 最少资源回收
kubelet 每次只会驱逐一个 Pod,驱逐后就会判断一次资源是否充足。
这样可能导致该节点资源一直处于驱逐阈值,反复达到驱逐条件从而触发多次驱逐。
kubelet 也提供了参数 --eviction-minimum-reclaim 来指定每次驱逐最低回收资源,从而减少触发驱逐的次数。
(6) Linux内核的OOM killer
OOM Killer 内核进程会监控系统里的所有进程,并根据公式有效 oom_score = oom_score + oom_score_adj 计算出每个进程的的 OOM 得分,随后内存不足时直接 Kill 掉得分最高的进程。
oom_score_adj 是提供给用户的灵活设置,k8s就是根据 Pod 的 QoS 为 Pod 中的容器进程设置了不同的 oom_score_adj 来调整优先级。
当进程被 OOM Killer Kill 掉之后,会生成内核事件,然后 kubelet 会识别该事件并将对应 Pod 设置为 OOMKilled 状态:
State: Running
Started: Thu, 10 Oct 2019 11:14:13 +0200
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
注意:与 Pod 驱逐不同,如果容器被 OOM 杀死, kubelet 可以根据其 restartPolicy 重新启动它。
-
OOM Killer是操作系统层面的应急响应机制,它在没有其他机制能有效管理资源时介入,以保护系统稳定性
-
Pod驱逐则是k8s的资源管理功能,提供了更高级的策略和控制,可以进行优雅处理
-
一般来说k8s的Pod驱逐策略应该足够有效,以避免频繁触发OOM Killer
3.3 Controller Manager发起的驱逐
当节点处于 NotReady 状态,并超出 podEvictionTimeout 时间后,controller manager 就会把该节点上的 pod 全部驱逐到其它节点。
场景:
比如 kubelet 还来不及驱逐,Node 上的资源就被耗尽导致宕机,此时 control-plane 无法正常和该节点通信,拿不到节点上的 Pod 的状态,因此会做最坏的打算,认为这些 Pod 都挂了,因此会将该 Node 上的所有 Pod 都驱逐到其他节点重新跑起来,以保证高可用。
参数:
-
pod-eviction-timeout:节点宕机多久后开始驱逐,默认 5m
-
node-eviction-rate: 驱赶 Node 的速率,由令牌桶流控算法实现,默认为 0.1,即每秒驱赶 0.1 个节点(注意这里不是驱赶 Pod 的速率,而是驱赶节点的速率,相当于每隔 10s,清空一个节点)
-
secondary-node-eviction-rate: 二级驱赶速率,当集群中宕机节点过多时,相应的驱赶速率也降低,默认为 0.01
-
unhealthy-zone-threshold:不健康 zone 阈值,会影响什么时候开启二级驱赶速率,默认为 0.55,即当该 zone 中节点宕机数目超过 55%,而认为该 zone 不健康
-
large-cluster-size-threshold:大集群阈值,当该 zone 的节点多于该阈值时,则认为该 zone 是一个大集群。大集群节点宕机数目超过 55% 时,则将驱赶速率降为 0.0.1,假如是小集群,则将速率直接降为 0
3.4 Scheduler调度抢占驱逐
即上述 [第2节:pod的优先级和抢占] 场景。
priorityClass 的 preemptionPolicy 字段控制抢占策略,默认为 PreemptLowerPriority,即允许抢占低优先级 Pod,如果不希望抢占则可以配置为 Never。
-
Pod 创建后就会进入等待调度队列,Scheduler 从队列中取出 Pod 并尝试将其调度到一个合适的节点上。
-
如果没有找到一个满足 Pod 所有条件的节点,就会触发抢占逻辑。
-
假设等待调度的 Pod 为 P,抢占逻辑试图找到一个节点, 在该节点中删除一个或多个优先级低于 P 的 Pod,则可以将 P 调度到该节点上。
-
如果找到这样的节点,一个或多个优先级较低的 Pod 会被从节点中驱逐。 被驱逐的 Pod 消失后,P 可以被调度到该节点上。
3.5 总结
|
驱逐场景
|
驱逐目的
|
驱逐对象
| |
|
API-initiated 驱逐
|
节点下线维护
|
提前将 pod 驱逐到其他节点,避免节点突然下线导致所有 Pod 挂掉,对业务造成影响
|
目标节点上的所有 Pod,其中 DaemonSet、使用 LocalStorage 的 Pod 以及没有被 controller(deploy、StatefulSet 等)管理的,单独启动的 Pod 这些比较特殊,默认不会驱逐。
|
|
Kubelet 节点压力驱逐
|
节点资源不足时
|
驱逐 Pod 到其他节点以释放资源,保证当前节点不会因为资源耗尽而宕机
|
按照规则排序,内存资源不足时一般按照 QoS 等级驱逐,inodes 和 pid 资源不足时则按照资源占用量进行驱逐(忽略 Pod QoS)
|
|
kube-controller-manager 节点离线驱逐
|
节点处于 NotReady 状态超过一定时间
|
将 Pod 从 NotReady 节点驱逐到其他正常节点,保证 Pod 能够正常运行
|
NotReady 节点上的所有 Pod
|
|
kube-scheduler 调度抢占驱逐
|
抢占式高可用 Pod 无法调度时
|
驱逐低优先级 Pod 给高优先级抢占式 Pod 腾出空间,使其能够正常调度
|
低优先级 Pod(注:这里的优先级不是 QoS 而是 priorityClass)。
|

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)