
在k8s中部署hadoop后的使用,包括服务端及客户端(客户端的安装及与k8s服务的对接)
在和这两篇文章中,说明了如何通过helm和k8s部署hadoop,接下来就看怎么在部署好的集群中使用hadoop了。
(作者:陈玓玏)
在https://blog.csdn.net/weixin_39750084/article/details/136744772?spm=1001.2014.3001.5502和https://blog.csdn.net/weixin_39750084/article/details/136750613?spm=1001.2014.3001.5502这两篇文章中,说明了如何通过helm和k8s部署hadoop,接下来就看怎么在部署好的集群中使用hadoop了。
一、在服务端使用hadoop
在k8s集群中使用hadoop和hdfs,不能直接使用hadoop和hdfs命令,需要借助kubectl。
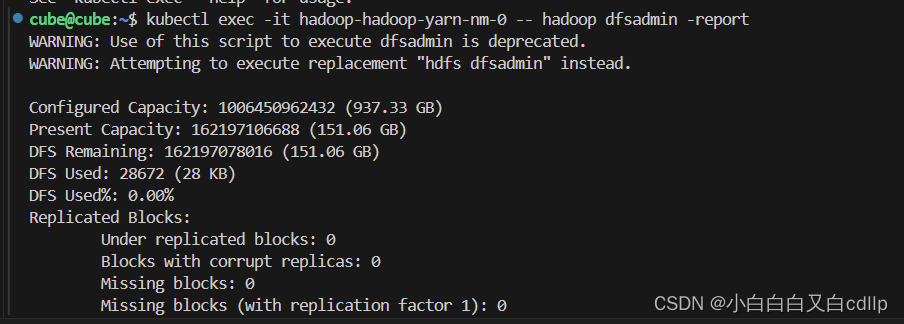
比如查看集群状态,可以通过kubectl exec -it hadoop-hadoop-yarn-nm-0 -- hadoop dfsadmin -report;
比如创建文件,可以通过kubectl exec -it hadoop-hadoop-yarn-nm-0 -- hadoop fs -mkdir /t;
比如查看文件,可以通过kubectl exec -it hadoop-hadoop-yarn-nm-0 -- hadoop fs -ls /;

命令中的hadoop-hadoop-yarn-nm-0是我部署的hadoop集群的master所对应的pod的名称,这个可以在k8sdashboard上查看。
其实在k8s集群上使用hadoop的shell命令,其实就是前面加一串固定的kubectl的命令就可以了。
二、在客户端使用hadoop
如果需要在客户端中使用hadoop和hdfs,需要先安装hadoop客户端。
先查看服务端的jdk和hadoop版本。
kubectl exec -it hadoop-hadoop-yarn-nm-0 -- hadoop version

再查看master所在的pod中的环境变量,找到其中java的环境变量,找到java的版本。
kubectl exec -it hadoop-hadoop-yarn-nm-0 -- bash -c 'echo $JAVA_HOME'

知道版本之后,我们可以开始安装客户端了。
1. 安装jdk:
sudo apt update
sudo apt install openjdk-8-jre-headless
如果失败了,先apt-get update试试。
如果之前安装的jdk版本太高,可能会有问题,需要先卸载当前的jdk,可以通过以下命令:
sudo apt-get --purge remove -y *jdk*
sudo apt autoremove
卸载之后再装新的jdk,就没问题了。
2. 安装hadoop:
下载hadoop,链接是https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz,下二进制版本,下载之后解压,tar -zxvf hadoop-3.3.6.tar.gz。
下载速度想要更快可以用这个网址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
tar -zxvf hadoop-3.3.6.tar.gz
解压后,配置环境变量。
打开~/.bashrc(也可以是/etc/profile,后者更持久化)文件,把下面两行加到末尾。
export HADOOP_HOME=/mnt/admin/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
执行以下命令让环境变量生效:
source ~/.bashrc
执行完之后尝试执行hadoop version命令,报错ERROR: JAVA_HOME is not set and could not be found。
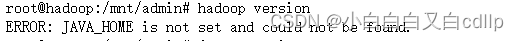
解决这个问题需要先看一下jdk是否安装好,java -version看一下。

java已经安装好了。
再输export看一下java的环境变量是否设置好了,我这边确实是没设置,那就在环境变量中再设置一下。
whereis java
ls -l /usr/bin/java
ls -l /etc/alternatives/java
通过以上三行命令找到java位置,注意两个ls后面的路径都是基于前一条命令的结果,要根据自己的结果来。在~/.bashrc后面把第三条命令的结果设置为JAVA_HOME,注意路径不要写到java那层,写到jre层就可以了。再尝试重新让环境变量生效。

再尝试hadoop version命令就可以了。

3. 配置hadoop
cd /mnt/admin/hadoop-3.3.6/etc/hadoop
vi hadoop-env.sh
确保hadoop-env文件里的JAVA_HOME那行被注释掉。
然后找到core-site.xml文件,添加以下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.43.44.243:9000</value>
</property>
</configuration>
这里的ip加端口是hadoop集群上namenode的ip及端口。在k8sdashboard上发现nm的service没有ip,所以复制了namenode的service,删除clusterIP为None的设置,生成一个新的service,把新的ip和端口写上。或者不用ip加端口,直接用域名加端口也是可以的,这样就不需要再复制一个service出来。
域名方式配置如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-hadoop-hdfs-nn.default:9000</value>
</property>
</configuration>
再找到hdfs-site.xml文件,添加以下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml:
这里需要resourcemanager的ip地址,k8s集群上的没有,所以也需要再复制一个rm,把clusterIP删了,再把type改为NodePort,把ip填到xml中。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.43.4.198</value>
</property>
</configuration>
同理可直接使用域名的方式,无需再生成一个NodePort的service,设置如下,注意yarn的service需要在域名前加上对应的pod名:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-hadoop-yarn-rm-0.hadoop-hadoop-yarn-rm.default</value>
</property>
</configuration>
4. 测试使用hadoop及hdfs
配置完之后,回到hadoop-3.3.6的上层目录,就可以在客户端直接通过hadoop命令及hdfs命令操作集群啦。
尝试先查询文件,再新建,再查询。
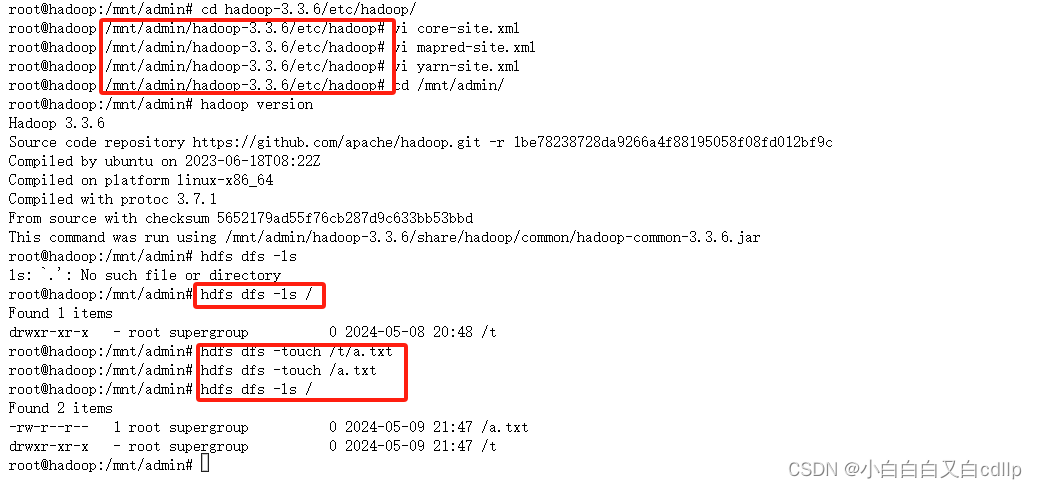
成功了,这样比在服务端直接使用更方便,不用通过kubectl来执行命令啦。
参考链接:
https://www.cnblogs.com/zhangyinhua/p/7678704.html#_label0
https://blog.51cto.com/u_16175434/7148403

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)