
Apache Spark—大数据计算引擎
在测试中,我们发现可以在低基维度的情况下,将整体聚合性能提升到原来的2倍。在SQL中,涉及到Spill的算子有Sort、Aggregation、Join,CH自带的Sort和Aggregation实现对Spill实现良好,但对于Join算子,CH高度优化的算法是全内存的Hash Join,该算法不支持Spill,其内置的支持Spill的Join算法有Grace Hash Join和merge Jo
本文将介绍BIGO大数据团队在Spark本地化计算引擎-Gluten方面的研发和应用在ETL批数据处理方面的工作。文章结构如下:
背景简介
Gluten架构和技术细节
Gluten在ETL批处理领域的挑战和研发
生产环境上线效果
未来工作简述
|背景简介
Apache Spark(下文简称Spark)是一种开源集群计算引擎,支持批/流计算、SQL分析、机器学习、图计算等计算范式,以其强大的容错能力、可扩展性、函数式API、多语言支持(SQL、Python、Java、Scala、R)等特性在大数据计算领域被广泛使用。
Databricks(Spark背后的商业公司)在2022年SIGMOD会议上发表论文《Photon: A Fast Query Engine for Lakehouse Systems》,其核心思想是使用C++、列式格式、向量化执行等技术来执行Spark物理计划,在客户工作负载上获得了平均3倍、最大10倍的性能提升,这证明Spark本地化是非常令人期待的方向。
随着SSD和万兆网卡普及,IO性能显著提升,基于Spark 的作业负载遇到越来越多的CPU计算瓶颈,而非传统认知中的IO瓶颈,我们的集群也验证了这点。基于 JVM 进行 CPU 指令的优化比较困难,因为 JVM 提供的 CPU 指令级的优化如 SIMD[4]要远远少于其他 Native 语言(如C/C++,Rust)。目前开源社区已有比较成熟的 Native Engine(如ClickHouse、Velox),具备了优秀的向量化执行(Vectorized Execution)能力,并被证明能够带来显著的性能优势。
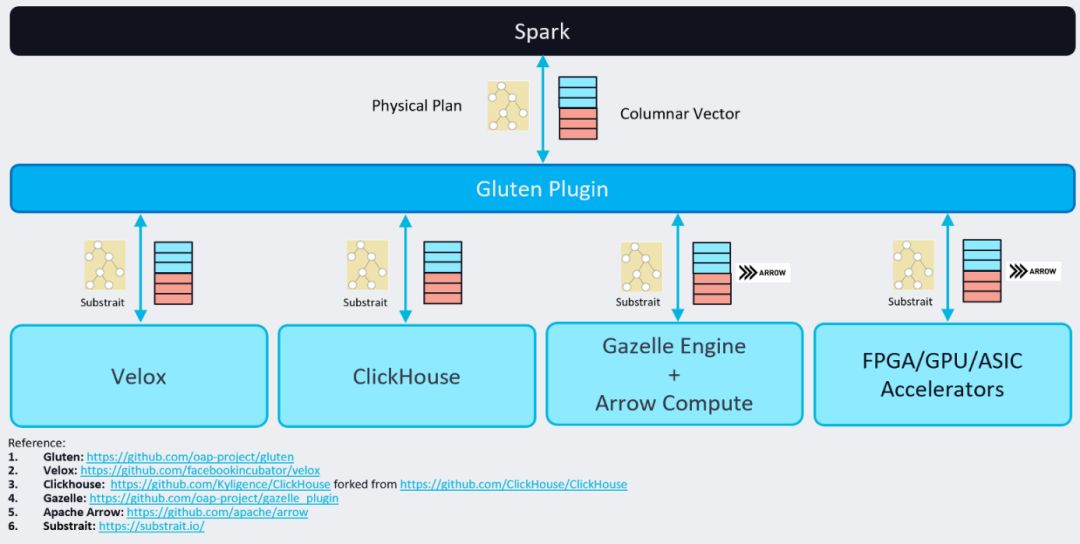
基于上述背景,Gluten项目诞生于2021年10月,由深耕于Spark加速的Intel OAP团队和Kyligence公司双方共建,其目的是通过开源社区来推进本地化Spark项目。BIGO大数据团队于2022年9月加入研发,为第三支核心研发团队。Gluten架构类似于Photon,两者都将本地Native运行时库实现为Spark插件,结合了Spark的可扩展性框架、优化器、容错能力和Native执行库的高性能,预期可以带来数倍的性能提升。其中Native Library目前支持Velox[6]和Clickhouse[7]:
Velox是Meta开源的本地执行库,其目标是构建统一的查询执行层,提供了数据类型、向量数据结构、Pipeline框架、算子、表达式计算、IO和资源管理等功能。当前Intel、美团、网易等公司专注在该方向上。
Clickhouse(下文简称CH)是2016年Yandex公司开源的是一个用于联机分析(OLAP)的列式数据库,以其高性能近年来备受关注,各大公司纷纷跟进大规模应用和改进(如字节跳动基于CH开源的云原生数仓ByConity),吸引全球超过1000余名开发者贡献代码。当前Kyligence和BIGO等公司专注在该方向上。
BIGO早在2018年引入CH作为OLAP服务于生产业务。当时考虑到CH更成熟以及我们对其代码更熟悉,所以在Gluten社区我们主要聚焦于Gluten+CH。经过协同社区近2年的研发,我们已经在生产环境逐步灰度Gluten(基于Spark 3.3),开始替换Spark的ETL工作负载,目前灰度SQL上获得了总体40%+的成本节省。
|Gluten简介
Gluten总体架构如下:
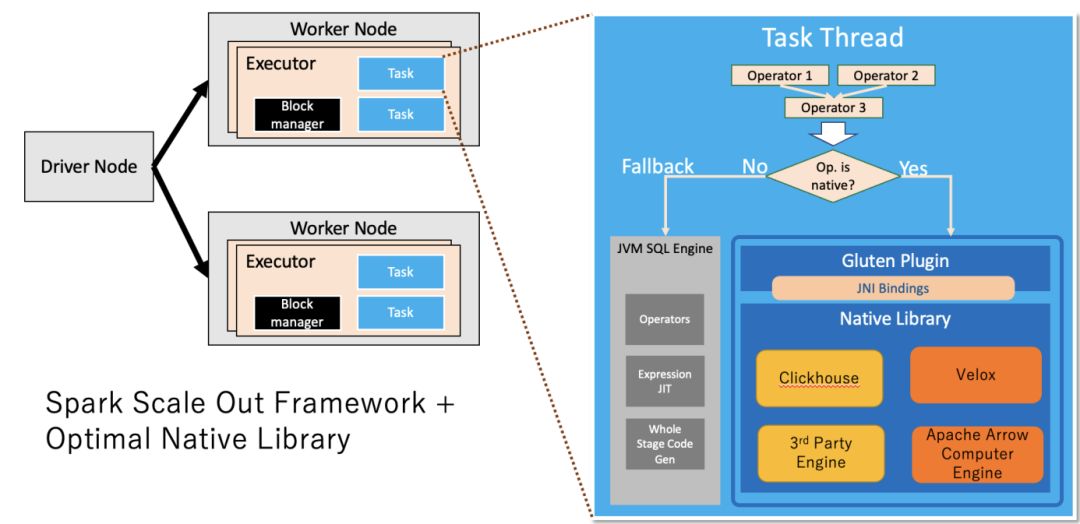
Gluten本质上是基于Spark插件接口开发的项目,不需要侵入Spark代码库,是一个大型的Spark插件库,该插件库使用更高效的指令来执行Spark的物理计划,对于物理计划之前的步骤则可延用Spark现有代码,这样既结合了Spark的框架能力又增强了执行器的性能。
总体而言,Gluten当前可以应用于生产环境,也通过了TPC-H[8]和TPC-DS[9]测试。目前支持的算子覆盖Spark生产环境常用算子,包括Scan、Filter、Project、Hash Aggregation、Sort、Join等,Aggregation、Sort和Join等算子也支持Spill,当内存不足时,可以溢写到外存。表达式方面,我们开发了目前生产环境使用的函数,绝大多数都已经支持,且解决了与Spark的语义上的diff(实际上,这块工作量很大,后文会展开叙述)。
Scan算子:数据源方面,支持Hive,S3。其中HDFS IO通过Libhdfs3[10](C++ native client)支持,我们贡献了Erasure Code[11](纠删码)支持,并引入Intel ISA-L库做了深度优化。数据格式方面,支持ORC[12],Parquet[13],CSV,Text等常用格式,ORC和Parquet都完整支持嵌套复杂类型、Decimal等。
Join算子:支持Broadcast Join和Grace Hash Join[14](GHJ),前者用于至少有一小表Join,后者实现了带Spill功能的Hash Join。经过我们优化,GHJ算法可以在内存充足的情况下性能打平全内存的Hash Join;当内存不足时,支持溢写到外存以避免OOM(out of memory)异常。在Join类型上,支持SQL标准Join类型。目前还不支持全不等值Join以及多不等值条件的ASOF Join[15]。
聚合算子:得益于CH对聚合算子的良好实现,支持Spill,但低基维度还有性能提升空间,目前BIGO正在优化该方向。
表达式:除支持生产常用的标量和聚合函数外,也支持window、lateral view explode、with cube、CTE等高级表达式。
写入支持:inset overwrite是在ETL中常见的范式,Gluten目前已经全面支持native write,格式包括Parquet和ORC,得益于native编解码的提升,写过程也有近2倍性能提升。
现在让我们深入Gluten架构,如下:
组件:
Gluten编译产出动态库,作为插件集成到Spark框架中,承担物理计划的执行功能。当一个SQL进来,会通过Spark的Catalyst 把SQL转成Spark 的物理计划,然后物理计划会传递给Gluten执行。
在Physical Plan交给Gluten Plugin的时候,会添加一些扩展的规则,然后把Physical Plan转换成语言无关的Substrait Plan。经过这个转换后再交由下面的各种Native向量化引擎去执行计算。各自的向量化引擎会根据Substrait Plan构建自己的Execution pipeline,然后读取Input数据去做计算,计算完后都会以列式方式返回给Spark。整个数据流转过程是基于 Spark原生Columnar batch和Columnar vector抽象,为Native向量化引擎做了一些具体的扩展和实现。
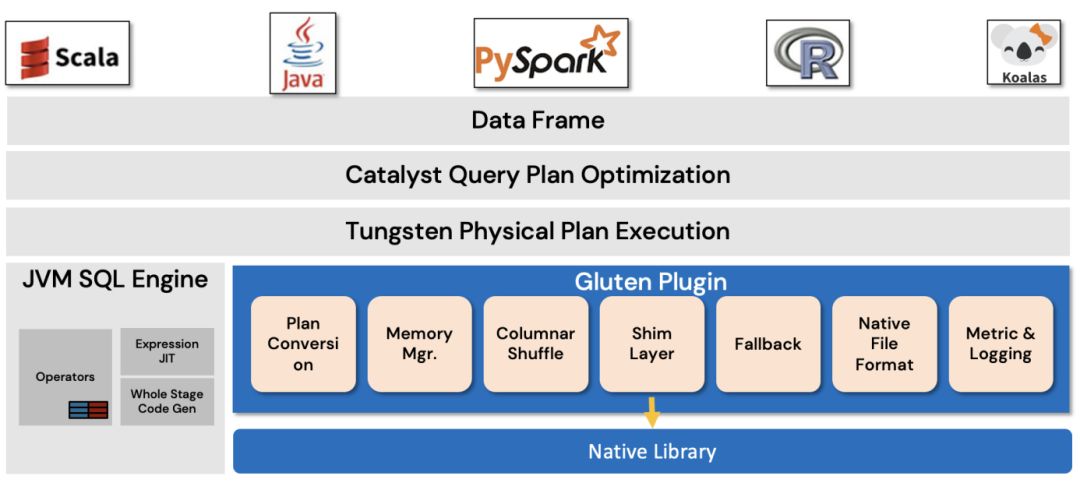
Gluten核心组件功能如下:
1. Plan Conversion组件,它把Spark Physical Plan通过Extension rule inject的方式转成Substrait Plan,然后再把Substrait Plan传递到底层的Native Engine执行。
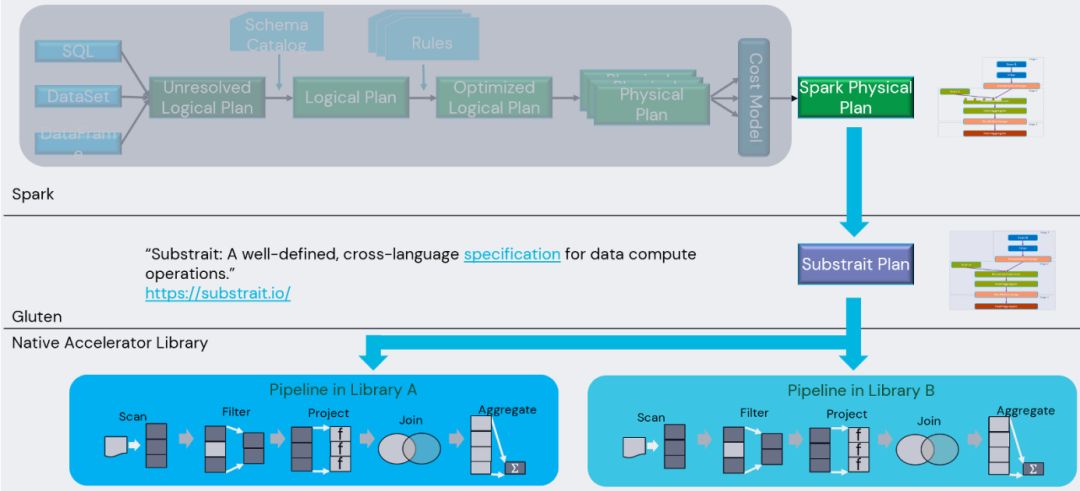
该过程使用 Substrait项目来作为Spark Physical Plan到Native向量化引擎传递的载体。Substrait与语言无关,使用google protobuf协议进行表达。在 Spark经过Catalyst解析,规则优化后会输出Physical Plan,通过Gluten一系列Extension Rules Inject方式插入规则,这些规则主要是对Spark Physical Plan逐一转换成Substrait Plan。转换过程会涉及到fallback 机制校验。转换后的pipeline会尽可能构造在一个whole stage内,然后一次性地调用Native Engine执行。Gluten使用Java方式去输出Substrait Plan后,底层Native向量化引擎,比如C++实现的引擎,会用 C++去解析这个Substrait Plan,解析完后根据这个Plan去构造各自的Execution pipeline,然后执行,执行完返回数据给Spark。
2. Memory管理。我们知道Native Engine完全是脱离JVM的,如果不把Native Engine的内存交给 Spark统一来管理的话,就很可能出现内存溢出或者直接打爆整台机器内存的情况,所以Memory管理也至关重要。
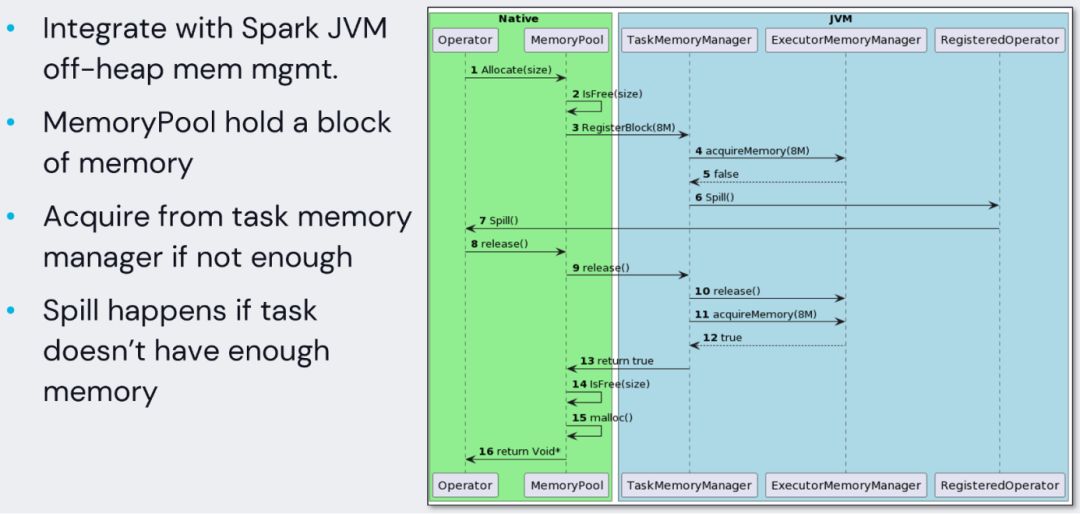
基于Spark原生的Unified Memory Manager机制,Gluten集成Spark Off-heap Memory Manager 对Native Engine所用的内存做管理。Spark的task执行时,会使用Task Memory Manager 对每个task的内存做申请释放管理。基于这套机制去实现了Native Engine的memory consumer,每个task在调用执行 Native Engine的时候,会通过这一套机制把Native Engine申请的内存上报到Task Memory Manager,于是在Spark侧就可以知道Native Engine使用了多少内存,Executor的内存存量是否满足要申请的内存大小。
为性能考虑,Native Engine侧都加了一个 memory pool。比如一次申请8M空间。那么在Native Engine使用的内存没达到8M时,是不会频繁地通过JNI的方式调用Spark的Memory Consumer往JVM上报。而ClickHouse backend的实现有些不同,它则是如果申请的内存在小于4M情况下,并不会向Spark申请内存。
不管是以哪种方式,都是为了尽可能的规避频繁通过JNI接口去回调Spark Memory Consumer来上报内存,减少对性能的影响。另外Spark在内存管理的时候,当Executor内存不足时,会去调用Spill方法让 Memory Consumer把自己管理的内存释放掉一部分,或者把一部分内存吐出到磁盘上面。
3. Shuffle,是整个执行过程中比较重的 Operator,而Spark原生的Shuffle是基于Row,因此Gluten扩展出了一个叫Columnar Shuffle Manager的对象,支持整个Shuffle过程当中的列式数据,避免数据行列转换带来的负面代价。Gluten社区与阿里云合作,引入了Apache Celeborn作为Remote Shuffle Service。Spark原生shuffle实现存在下面的缺陷:
(1)依赖大容量的本地盘或云盘存储Shuffle数据,数据需要驻留直至消费完成。这就限制了存算分离,因为存算分离架构下,计算节点通常不希望有大容量的本地盘,希望计算结束就可以释放节点。
(2)Mapper做排序会占用较大内存,甚至触发堆外排序,引入额外的磁盘IO。
(3)Shuffle Read有大量的网络连接,逻辑连接数是number_Mapper×number_Reducer。
(4)存在大量的随机读盘。假设一个Mapper的Shuffle数据是128M,Reducer的并发是2000,那么每个文件将会被读2000次,每次只随机读64k,这就很容易达到磁盘IOPS的瓶颈。
(5)数据单副本,容错性不高。
以上五点缺陷最终导致不够高效、不够稳定以及不够弹性,阿里云的Apache Celeborn解决了上面的问题,这里不展开叙述
4. Fallback组件,这是一个当前比较重要的组件。Spark经过这么多年的发展,目前支持的Operator和Expression很多,而Gluten在发展初期,不可能把所有的Operator或Expression都支持。当遇到Native Engine不支持的情况时,会先通过fallback机制做验证,验证完之后如果不支持,就会回退到Spark原生JVM引擎去执行。
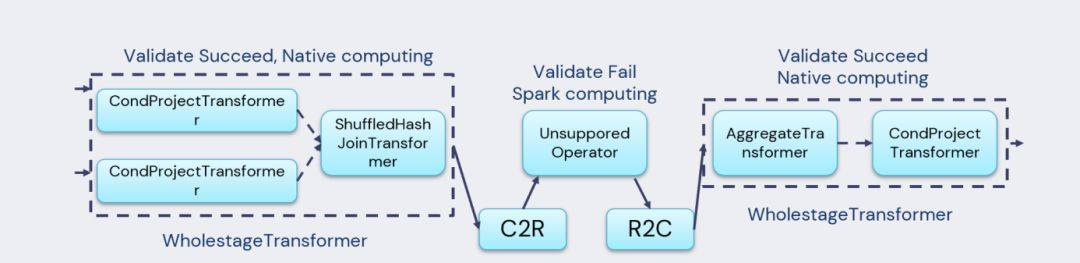
注意,C2R是Column2Row,R2C代表Row2Column操作,这两个操作代价不能忽略,因此在生产环境中应尽量避免发生fallback。
5. Shim Layer组件,类似在Spark通过Shim Layer支持Hive,Gluten的Shim Layer也是为了让 Gluten能支持多个版本的Spark。因为Spark对外公开的接口,在版本之间变化不会那么大,但内部接口变化还是比较大。所以如果要支持多版本Spark的话,就需要通过Shim Layer来适配多版本。
6. Metrics,它把Native Engine执行过程中的指标统计上报给Gluten Plugin,然后再由Plugin上报给Spark的Metrics System做展示、Debug、API调用。
|挑战和困难
下面重点阐述我们在将Gluten应用到ETL批处理领域遇到的一些挑战以及研发工作。
当前Native引擎主要应用在OLAP领域,该领域处理的数据量偏小,多数不会引发Spill,数据大都在内存内计算。对于ETL工作负载,这类SQL特征是普遍输入数据在TB以上级别,且伴有计算密集和IO操作。在开源业界尚无成熟的Native引擎应用ETL工作负载的经验,这个过程充满技术挑战。
出于成本考虑,我们基础设施层自建机房和自运维服务器方案,使用Apache Hive/HDFS+Yarn+Spark架构来支持业务进行批量数据分析和处理。对于当前流行的数据湖方案我们调研过暂无应用场景,且未看到在成本或性能方面有显著优势。
IO优化
在ETL类工作负载中,IO占比显著比OLAP高,大概10%甚至更高,因此IO优化是我们首先要解决的问题。优化IO大体思路是减少IO次数和数据量,以及使用更好的硬件。
Spark中IO来自下面3类:
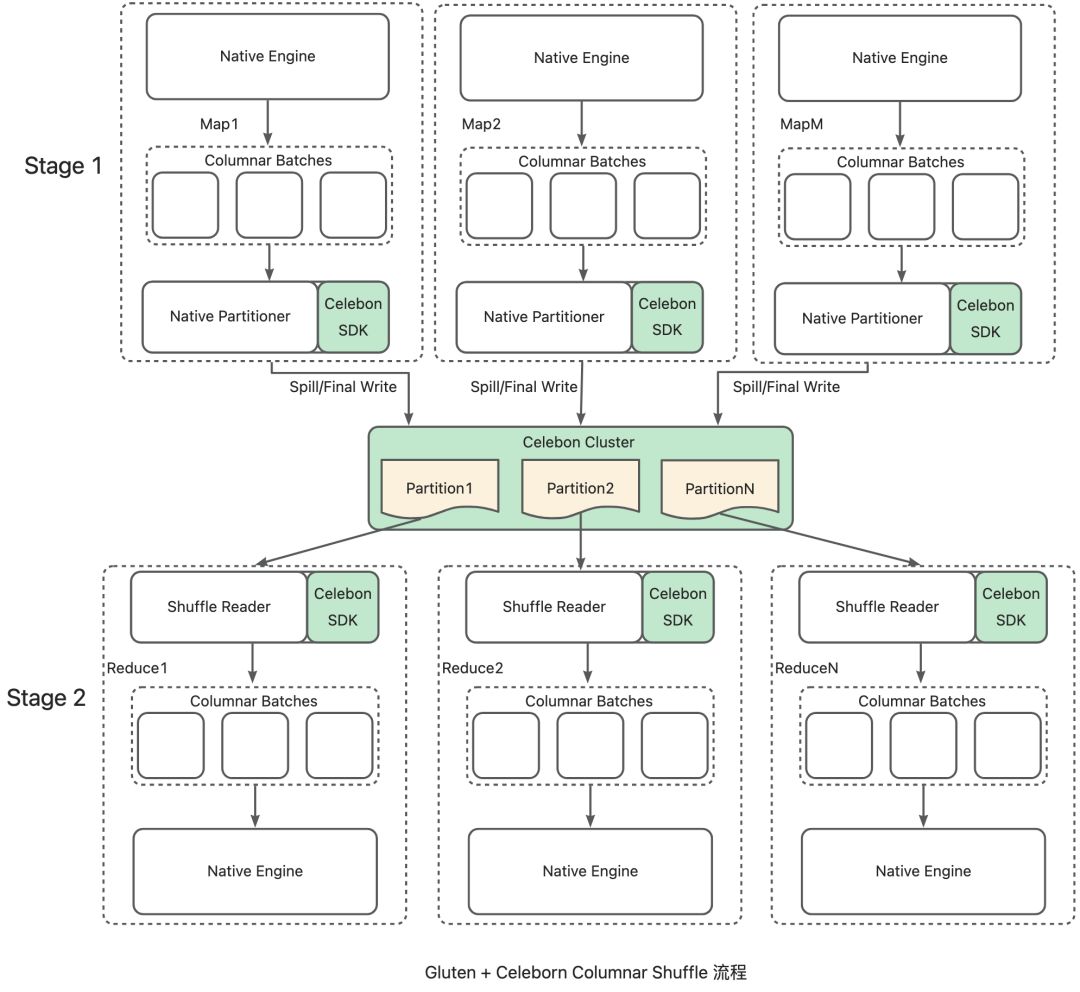
1. Shuffle,是影响Spark性能的重要一环,这里会引入多次序列化/反序列化、网络传输、磁盘IO。由于Native Engine采用列式(Columnar)数据结构暂存数据,如果简单的沿用Spark的基于行数据模型的Shuffle,则会在Shuffle Write阶段引入数据列转行的环节,在Shuffle Read阶段引入数据行转列的环节,才能使数据可以流畅周转。但是无论行转列,还是列转行的成本都不低。因此,Gluten必须提供完整的 Columnar Shuffle机制以避开这里的转化开销。具体到Columnar Shuffle实现层,主要分成shuffle数据写入和shuffle数据读取两块。在一个TPC-H Like Scale Factor 6TB的测试场景中,Columnar Shuffle Write 和原生Spark的row based shuffle相比,可以达到减少约12%的Shuffle Size的效果。
上图描述了Gluten+Celeborn Columnar Shuffle 的整体设计:Shuffle Writer复用Native Partitioner,拦截本地IO并改为推向Celeborn集群;Celeborn集群做数据重组(聚合相同Partition的数据)和多备份;Shuffle Reader从特定Celeborn Worker上顺序读取数据并反序列化为Column Batch。这个设计不仅保留了Gluten Columnar Shuffle的高性能设计,又充分利用了Celeborn远端存储、数据重组和多副本的能力。
原生Spark实现中,本地Shuffle的Reducer从多个文件读取数据,而Celeborn Reducer只需从一个Worker上读取,随机读转换成了顺序读,网络的连接数也从乘数关系变成了线性关系,从而提升了Shuffle Read的性能。详细内容参考:
Gluten + Celeborn: 让 Native Spark拥抱Cloud Native-阿里云开发者社区 https://developer.aliyun.com/article/1266372
我们联合Kyligence与Celeborn社区紧密合作,解决了多个稳定性问题,成功在CH后端实现Column shuffle+Celeborn对接,在大SQL上可取得5%-20%的性能提升,内存占用更稳定,整体运行过程也更稳定。
2. Scan,也就是针对数据源的扫描,主要有以下优化:
(1)Filter pushdown(或Predicate Pushdown,谓词下推),是指就是将尽可能多的谓词更贴近数据源,以使查询时能跳过无关的数据,减少后续计算数据量,该优化非常基础且重要。我们主要数据格式是Parquet和ORC。得益于CH社区,Parquet格式支持了row group级别过滤,但目前还不支持page级别的pushdown,这也是未来优化方向之一。关于ORC格式,我们研发支持了File/Stripe/Row group级别过滤,相对完备。
(2)Column pruning(列裁剪),基本思想在于:对于算子中实际用不上的列,在Scan的时候可以直接跳过,减少 I/O 资源占用,并为后续的优化带来便利,Gluten已经支持该优化。
(3)Subfield pruning(子列裁剪),现代数据仓库中广泛使用map、array、struct等复杂类型结构,为了提高CPU效率,需要在不读取整个复杂对象的情况下有效提取子字段。对于Parquet和ORC格式,我们开发支持了子字段剪枝,向reader发送所需的复杂对象的索引或key的信号,以减少IO数据量。
(4)Dynamic filter recordering,其原理是有些filter能在更少的CPU cycle中过滤更多的行,使选择性更强的filter排在前面。我们在CH后端开发支持了该特性,在运行时,filter中的函数顺序会根据其选择性和平均CPU周期的乘积进行动态重排序,减少处理数据量。
3. Write,大部分ETL作业,数据经过变换加工后,最终需要写入到Hive表或者HDFS路径中,Gluten社区由Kyligence团队首先实现了Parquet格式写入,我们贡献了ORC格式的写入支持,同时支持复杂类型,这使得Gluten补齐了在ETL领域最后一块拼图。得益于Native编解码实现,在复杂类型写入上,纯IO可获得2倍的性能提升。
4. HDFS作为数据底层存储,其IO性能会直接影响整体计算能力。根据追求成本和性能的最佳实践,我们使用分层存储结构来存储业务数据:最近几天的热数据存储在SSD介质以提高读写性能,随着时间的推移热数据自动转温,温数据被自动转储到SATA HDD,近3个月的数据存储在SATA HDD,3个月之前数据视为冷数据,将自动通过EC编码存储在SATA HDD构建的冷备集群中。HDFS默认的3副本策略,在存储空间和网络带宽上有200%的开销,因而副本策略是昂贵的。但是对于具有相对较低I/O的冷数据集,一种有效的改进措施是使用纠删码来替换副本策略。EC6+3提供了比三副本更强的容错能力,但使用更少的存储空间,存储成本节约50%。
为了支持EC编码数据读写,我们在Libhdfs3上实现了EC编解码支持并贡献给了社区,使得该库功能更完备。在EC编解码过程中,存在大量的矩阵运算成为性能瓶颈,所以我们引入Intel ISA-L库对该部分做了深度优化[17],该库底层使用SIMD指令集和汇编来优化计算密集型的矩阵运算,被广泛应用在Ceph,SPDK,Hadoop等项目,对比基线实现,性能提升70%。
最后经过我们优化,在三副本模式下,Libhdfs3对比Java client在15MB小数据写性能提升38%,读性能提升23%;在1GB大尺寸数据上写性能基本持平,读性能提升17%;在EC模式下,Libhdfs3对比Java client在15MB小数据写性能提升45%,非解码读性能提升20%,解码读性能提升14%;在1GB大尺寸数据上写性能提升26%,非解码读性能提升30%,解码读性能提升22%。
我们还优化了HDFS seek操作以减少IO数据量,在CI流水线性能对比获得了端到端18%的显著性能提升。
在数千台以上的HDFS集群中,慢节点是常见现象,我们已经做了一系列慢IO优化的措施,并上线到了HDFS集群和Java client侧应用比如Spark,我们也移植了相关的优化到Libhdfs3。慢节点优化详见:
另外,我们还贡献了local data cache,这对于存算分离的云上架构来说可以极大提升数据本地性,减少远程IO的数据量。
内存优化
我们这里讲内存包括几个内容,一是内存管理,上文简单介绍了Gluten内存管理机制,其大体思想是把native库的内存分配与释放对接到Spark的统一内存管理机制上,这样可以在内存不足的时候发生Spill,从而使任务继续运算下去而不至于因为OOM被kill。这是在框架层面的机制,具体算子的Spill实现是在native library里,我们在应用过程中,碰到诸多问题需要解决。其二是我们发现部分算子在实现的过程中对内存使用有较大优化空间,针对这些算子我们做了深度的内存优化,使内存使用更合理。其三,讲下在应对内存问题方面的工具和方法。
1. 算子Spill支持和优化
在SQL中,涉及到Spill的算子有Sort、Aggregation、Join,CH自带的Sort和Aggregation实现对Spill实现良好,但对于Join算子,CH高度优化的算法是全内存的Hash Join,该算法不支持Spill,其内置的支持Spill的Join算法有Grace Hash Join和merge Join,而Merge Join因存在IO问题,所以我们决定在社区的Grace Hash Join算法上进行优化。CH Grace Hash Join存在问题:
(1)性能较差,无论是否发生Spill的情况下。
(2)不支持right和full Join,限制了该算法的应用范围。
因此,为支持大数量Join,我们决定基于已有的Grace Hash Join算法进行优化。
我们使用了为Hash table预分配空间、减少文件读写的锁保护范围、优化scatter等手段,最终实现了:当内存充足时,性能打平全内存Hash Join,当有Spill发生时,处理速度提升5倍。同时,也扩展了Grace Hash Join的语义,支持right Join和full Join。
2. 算子和表达式的内存占用优化
Gluten中lateral view explode算子(将一行数据拆分成多行数据)的底层实现依赖CH的array Join算子,但社区实现存在内存暴涨问题,其输入是1个Block,但经过array Join后可能导致Block数据膨胀数十倍甚至更多,从而导致内存不足,我们使用迭代器模式将其改造为了流式输出,解决了lateral view explode场景下内存不足的问题。
此外,针对Gluten内部的expand算子、生产上常用的json函数get_json_objects中间结果占用内存过多导致内存不足的问题,我们也进行了深度优化,解决了其带来的作业内存不足问题。
Gluten中还存在当Scan算子中的input partition 相当多的情况下driver oom问题,这是因为每个input partition都包含substrait执行计划转换成的PB对象。在我们遇到的一个线上SQL case中,132785个这样的 input partition占用了超过30G内存。针对这个问题,我们优化了input partition, 只存储PB对象的序列化字节,大大减少了内存占用。经过优化后,132785个这样的input partition只占用了1G多内存,从而避免 driver oom问题。
3. 内存问题追查工具
Gluten部分使用C++开发,使用C++ 20的智能指针可以规避大部分内存问题。不过因为代码量大,不可避免地会引入bug导致内存问题,CH使用的工具链clang自带address sanitizer和memory sanitizer可以协助解决内存问题,gperftools可以极大帮助我们发现问题。我们可以在单机启动thrift server加载Gluten,下载生产环境的数据,运行生产环境的SQL来模拟生产环境运行过程,通过产生的perf文件我们可以快速定位到内存泄露、内存占用过多等问题。
计算性能优化
针对线上的实际应用情况以及参考其他产品的性能效果,我们也做了部分针对性的性能优化:
1. JSON 和 Map 类函数的性能优化
JSON 格式数据广泛存在线上数据中。我们更高效的内存拷贝实现方法[18]以及复用对象方法[19],将 get_json_object函数的性能提升到了原来的3倍左右。线上环境的SQL,存在大量解析同一个JSON文本获取多个不同字段内容的情况,而解析JSON数据的开销是大头。对此我们通过构建JSON数据结构的中间结果,达到一次解析多处复用的效果,大大减少了计算量。
Map类型数据同样是常见类型,我们针对线上数据的实际情况,实现了键值位置预测和内存空间开辟的优化,整体性能提升了60% 左右。
2. 低基维度聚合优化
CH的聚合使用的Hash Table已经相对高效,但在低基维度数据上,表现仍有提升空间。主要问题在于多聚合键值的情况下,CH存在大量数据序列化和内存拷贝的开销。我们通过为低基维度数据进行字典编码,避免了对数据进行序列化和内存拷贝,这样同时也提高了 Hash Table键值的比较效率。同样我们近一步探索了SIMD指令加速的可能。在测试中,我们发现可以在低基维度的情况下,将整体聚合性能提升到原来的2倍。而且我们实现了动态策略转换。在Hash Table一开始构建时,我们先假设数据是低基维度的。随着插入数据增多,键值数量超过一定阀值时,我们能自动切换回高基维度的Hash Table构建策略。
语义对齐
因为CH本身使用其发明的SQL方言,与Spark使用的SQL并非一套语法,所以Spark和CH的类型、算子、函数都需要通过Gluten进行对齐,补全功能并消除diff。语义对齐对Gluten的性能具有重要意义,因为任何不支持的类型、表达式或函数都有可能造成计划片段的fallback,由此带来的Spark Row到CH Column互转的代价高昂,会拖慢整体的性能。
1. 类型支持
早期Gluten支持的类型有限,不符合我们生产环境的实际需要。我们在此基础上新增了Byte/Short/Binary/Timestamp/Decimal/Array/Struct/Map等生产常用类型的支持,并支持这些类型在Spark Row和CH Column之间高效地进行转换。
同时我们发现Spark和CH中类型系统最大的diff在于NULL语义。在Spark实现中,nullable仅是不同类型的属性,默认所有类型都是nullable的,而在CH实现中,nullable是一个独立的类型,除非显式指定,否则所有类型都是非nullable的。而且由于历史原因,CH中复杂类型(Array/Struct/Map)不支持nullable=true。因此,我们在Gluten和CH中做了大量扩展来弥补NULL语义带来的diff。
2.算子支持
早期Gluten支持的算子同样有限。我们在此基础上支持了Sort、Limit、Union、Lateral View、Window、Range Partitioning Shuffle、Expand、ORC Scan、ORC Write等算子。
3. 函数支持
虽然CH也是分析数据库,但其内置函数语义并不与Spark/Hive看齐,对比Spark差异主要来自以下几个方面:
(1)CH中无对标函数。
(2)函数实现略有差异,存在corner case。
针对第一点,我们根据需要在CH中开发了对标Spark的内置函数,涵盖了常用的数学、字符串、时间、哈希、JSON、复杂类型和聚合等相关函数。针对第二点,我们引入了Function Parser框架,将不同的Spark函数转化成多个CH函数组合起来的表达式,从而能够最大限度的复用CH内置函数,减少开发CH新函数的时间成本。
在最初应用Gluten的时候,函数diff率有18%,后面经过团队的不懈努力,这些diff最终被消除,共计标量函数120+,聚合函数20+。
以上所有代码我们均贡献到了Gluten、CH、Celeborn社区,截止到文章发表时间,我们在Gluten社区提交270+的PR,CH社区提交110+PR,Celeborn社区提交20+PR,覆盖到了框架、算子、函数、IO、单测等几乎所有模块。
|上线效果
出于成本考虑,我们使用动态executor调度机制以最大化利用集群的资源,Gluten和Spark的运行参数整体一致,总体内存4GB,Gluten 3GB offheap, 1GB onheap,Spark反之;executor CPU core=2。成本计算采用所有executor执行时长乘以其占用的内存加和。
统计当前已同时双跑的SQL(总体占比约1%),对比vanila Spark,Gluten使用约56%的资源,同时任务有14%性能提升,单SQL最大处理数据135TB。
|未来工作
Gluten已经具备运行部分生产ETL SQL的能力,我们除了继续推进灰度工作之外,未来还有不少工作值得去做。
在功能方面,需要支持:
1. 在复杂SQL下比如grouping sets较多或者推测执行场景下仍有内存问题需要修复。
2. 多不等值Join或者全不等值Join类型支持,生产环境中有极少数此类SQL。
3. 通用高性能UDF机制,当前UDF比较少,我们采用内置函数方式重新实现,开发成本尚可接受,但Gluten作为通用的框架,需要探索高性能的UDF机制。
在性能方面:
1. Parquet支持page级别filter pushdown。不同于v1版本把page统计信息分散在page头部,新版本放在文件尾部,因此可以支持page级别过滤以减少IO和计算代价。
2. 算子和表达仍有可提升空间,比如Spill优化、应用JIT优化expression evaluation过程等。
3. 探索业务排序pattern来增加local sort,提升row group过滤成功率,可极大减少IO。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)