[NLP]LLM--transformer模型的参数量
最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量为1750亿,训练数据量达到了570GB。进而,训练大规模语言模型面临两个主要挑战:显存效率和计算效率。
1. 前言
最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量为1750亿,训练数据量达到了570GB。进而,训练大规模语言模型面临两个主要挑战:显存效率和计算效率。
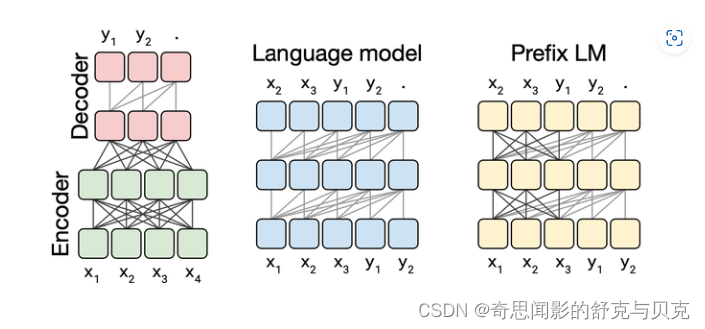
现在业界的大语言模型都是基于transformer模型的,模型结构主要有两大类:encoder-decoder(代表模型是T5)和decoder-only,具体的,decoder-only结构又可以分为Causal LM(代表模型是GPT系列)和Prefix LM(代表模型是GLM)。归因于GPT系列取得的巨大成功,大多数的主流大语言模型都采用Causal LM结构。因此,针对decoder-only框架,为了更好地理解训练训练大语言模型的显存效率和计算效率.
完整的Transformer模型包括encoder和decoder,而GPT只使用了decoder部分,且因为少了encoder,所以和原始的Transformer decoder相比,不再需要encoder-decoder attention层,对比图如下:
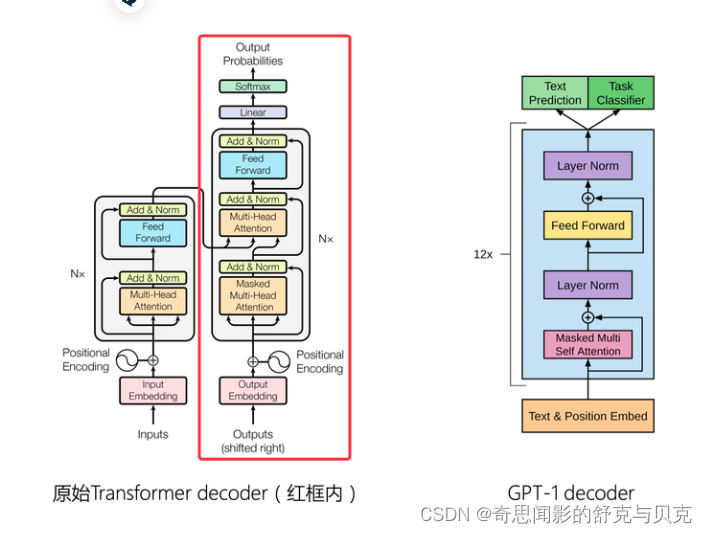
本文分析采用decoder-only框架transformer模型的模型参数量、计算量、中间激活值、KV cache。
`
为了方便分析,先定义好一些数学符号。记transformer模型的层数为 L ,隐藏层维度为 h ,注意力头数为 a。词表大小为 V,训练数据的批次大小为 b ,序列长度为 s。
2. 模型参数量
可以参考:[NLP] BERT模型参数量_奇思闻影的舒克与贝克的博客-CSDN博客
基本方法一样
transformer模型由 L个相同的层组成,每个层分为两部分:self-attention块和MLP块。
Self-attention模块参数包含Q, K V 的权重矩阵Wq, Wk, Wv 输出及偏置Bias,4个权重矩阵形状为[h, h],4个偏置形状为[h], Self-attention参数量为4 + 4h
MLP块由2个线性层组成,一般地,第一个线性层是先将维度从 h 映射到 4h ,第二个线性层再将维度从4h映射到h。第一个线性层的权重矩阵 W1 的形状为 [h,4h] ,偏置的形状为 [4h] 。第二个线性层权重矩阵 W2 的形状为 [4h,h] ,偏置形状为 [h] 。MLP块的参数量为 8 + 5h
self-attention块和MLP块各有一个layer normalization,包含了2个可训练模型参数:缩放参数 gaama和平移参数 beta ,形状都是 [h] 。2个layer normalization的参数量为 4h 。
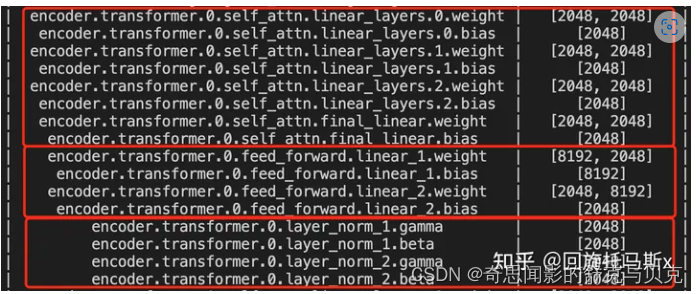
总的,每个transformer层的参数量为12 + 13h
除此之外,词嵌入矩阵的参数量也较多,词向量维度通常等于隐藏层维度 h ,词嵌入矩阵的参数量为 Vh 。最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的。
关于位置编码,如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如RoPE和ALiBi,则不包含可训练的模型参数。我们忽略这部分参数。
综上, L层transformer模型的可训练模型参数量为 L(12 + 13h)+Vh 。当隐藏维度 h 较大时,可以忽略一次项,模型参数量近似为 12L
接下来,我们估计不同版本LLaMA模型的参数量。
| 实际参数量 | 隐藏维度h | 层数l | 12L |
|---|---|---|---|
| 6.7B | 4096 | 32 | 6,442,450,944 |
| 13.0B | 5120 | 40 | 12,582,912,000 |
| 32.5B | 6656 | 60 | 31,897,681,920 |
| 65.2B | 8192 | 80 | 64,424,509,440 |
特此声明,此文主体参考知乎文章https://zhuanlan.zhihu.com/p/624740065(在此感该作者“回旋托马斯x”的辛苦付出)
参考
[1] https://arxiv.org/pdf/1706.03762.pdf
[2] https://arxiv.org/pdf/2302.13971.pdf
[3] https://arxiv.org/pdf/2104.04473.pdf
[4] https://zhuanlan.zhihu.com/p/624740065

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)