
再看大模型Lora微调加速是否有效:Full-Parameter全参数微调与LoRA低秩微调的性能对比开源实验介绍...
来自:老刘说NLP进NLP群—>加入NLP交流群近年来,大型语言模型的指令微调是自然语言处理领域的一个重要研究领域。由于资源和成本的限制,一些研究人员采用了参数有效的调整技术,如LoRA,并取得了不错的结果。与全参数微调相比,基于LoRA的微调在训练成本方面表现出显著的优势。针对这类问题,本文介绍一篇关于全监督微调和lora微调的对比评估工作:该工作主要对比了全参数微调和Lora微调的对比,
进NLP群—>加入NLP交流群
近年来,大型语言模型的指令微调是自然语言处理领域的一个重要研究领域。
由于资源和成本的限制,一些研究人员采用了参数有效的调整技术,如LoRA,并取得了不错的结果。与全参数微调相比,基于LoRA的微调在训练成本方面表现出显著的优势。针对这类问题,本文介绍一篇关于全监督微调和lora微调的对比评估工作:

该工作主要对比了全参数微调和Lora微调的对比,这对后续SFT模型微调有一定的参考意义。具体地,该工作利用LLaMA作为基本模型,对全参数微调和基于LoRA的微调方法进行了实验比较,实验结果表明,基础模型的选择、训练数据集规模、可学习参数数量和模型训练成本都是重要因素。供大家一起参考。
一、工作背景
目前,有几个开源的大型语言模型已经对教学数据进行了微调,包括OPT(Zhang等人,2022)、BLOOM(Workshop等人,2022。这些模型在一系列语言任务中表现出了卓越的性能,从而强调了指令微调在提高语言模型性能方面的潜在好处。
在模型训练领域,两种广泛使用的方法是全参数微调和参数有效调整。
最近,研究人员进行了大量实验,以比较各种参数效率调谐方法的有效性,例如Adapters(Houlsby等人,2019年;Lin等人,2020年)、LoRA(Hu等人,2022年)和P调谐(Li和Liang,2021;Lester等人,2021;Liu等人,2021)与全参数微调(Ding等人,2023年)。
这些实验的结果表明,LoRA是一种很有前途的参数有效调整方法,并已在许多研究中应用,以微调大型语言模型,并取得了显著成功(Stanford,2023;Xu等人,2023)。
然而,LoRA用于微调指令对齐模型的有效性和效率尚未得到很好的探索。
该工作考察了两个因素的影响:基础模型和训练数据量,并从模型性能和训练效率的角度将LoRA与全参数微调进行了比较。
二、再谈LoRA
目前,随着模型大小的不断增加,微调所有参数变得更具挑战性,因为有必要保存所有参数的梯度和优化器状态。
因此,研究人员提出了参数有效微调,这是一种低资源、高效的调谐方法,只微调少量参数或引入额外的可训练参数。
例如:
前缀调整(Lester等人,2021;Li和Liang,2021;Liu等人,2021)添加了可训练的虚拟token嵌入并修复了整个模型。
适配器(Houlsby等人,2019;Lin等人,2020)在神经网络的现有层之间插入适配器层,并且只微调适配器网络的参数。(Aghajanyan等人,2020)表明,学习过的参数化模型实际上存在于较低的内在维度上。
(Hu et al,2022)受这项工作的启发,提出了LoRA方法,该方法建议在下游任务的模型自适应过程中更新权重也应具有较低的“内在秩”。
(Ding等人,2023)的实验结果表明,在各种参数有效的微调方法中,LoRA是一种相对有效的方法。它已被最近的许多开源项目所采用(斯坦福大学,2023;Xu等人,2023),用于训练大型语言模型,并取得了不错的结果。
不过,这些研究工作仅将LoRA视为一种训练模型的方法,并没有对影响基于LoRA的调整结果的因素进行深入分析。
关于lora的原理,我们已经讲过多次,这里再重复一下:
对于预先训练的权重矩阵W0∈Rd×k,其更新可以用低秩分解来表示:
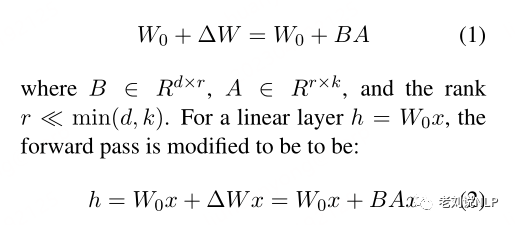
矩阵A将由随机高斯初始化,B将由零初始化,使得∆W=BA的初始值在训练开始时为零。
(Hu et al,2022)仅对下游任务的注意力权重进行了调整,并冻结了MLP模块,该工作参照了Baize(Xu et al,2023),Baize应用LoRA同时调整所有线性层。
三、具体实验
1、实验数据
该工作分别选择了0.6M、2M和4M的三个公开的Belle数据集,结合这三个数据集,旨在研究不同训练数据大小对基于LoRA的调优性能的影响。
为了验证在指令调优后对模型进行基于LoRA的调优是否可以进一步提高模型性能,还选择了math_0.25M数据集,这是一个专注于数学问题解决领域的数据集。
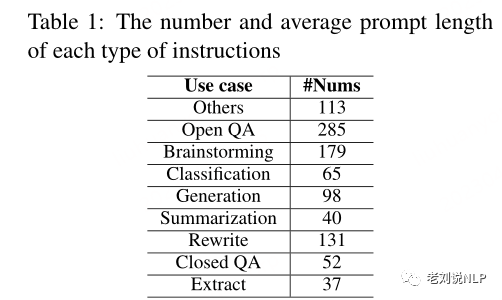 评估集由1000个严格手动筛选和处理的数据条目组成,涵盖九个类别,包括翻译、开放式QA、封闭式QA、生成和其他与实际应用密切相关的任务,具体数量如表1所示。
评估集由1000个严格手动筛选和处理的数据条目组成,涵盖九个类别,包括翻译、开放式QA、封闭式QA、生成和其他与实际应用密切相关的任务,具体数量如表1所示。
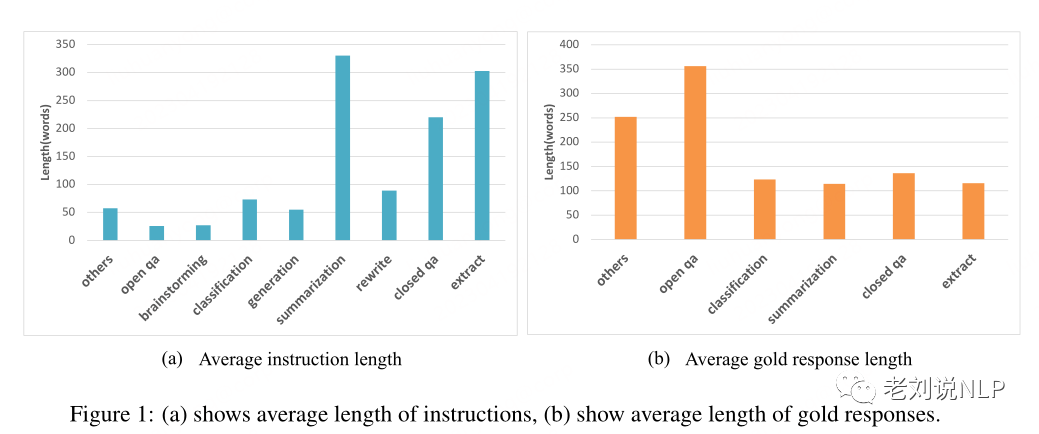
上图1显示了评估样本的长度。类别Other包含两种类型的数据:数学和代码,其中数学指的是解决数学应用程序问题,代码指的是代码生成。
2、实验模型与参数设置
首先,该工作选择LLaMA(Touvron等人,2023)作为基础实验模型。Meta AI发布的LLaMA是一个大型语言模型的集合,具有四个不同的参数尺度:7B、13B、33B和65B。
LLaMA模型的性能非常出色,经验证据表明,LLaMA13B仅具有1/10的参数规模,在大多数基准评估中优于GPT-3(175B)(Brown等人,2020),该工作实际选择LLaMA-7B和LLaMA-13B作为我们的基础实验模型。
其次,在实验参数上,对于全参数微调实验,表2列出了微调的超参数。
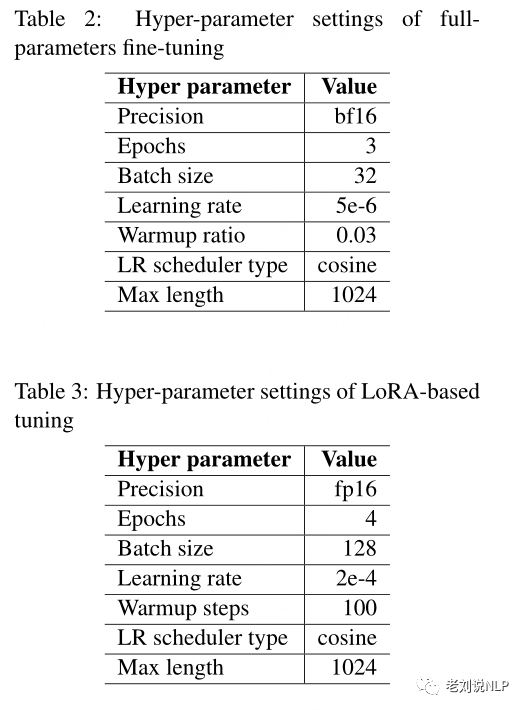
对于LoRA实验,采用了(Xu et al,2023)中的超参数,该超参数将LoRA中的秩设置为8,并应用LoRA来调整注意力权重和所有线性层。
最后,在硬件使用上,实验在8个NVIDIA A100-40GB GPU上进行。
3、评估方法
在评估上,利用ChatGPT来评估指令遵循模型生成的恢复。
对于所有指令,ChatGPT给出的分数在0到1之间,其中0分是最差的,1分是最好的。
为了减少随机性,将温度参数设置为0.001以生成模型,并限定为通过在2023年4月15日调用gpt-3.5-turbo API来实现评估。
通过计算每个任务类别的模型得分,并使用这些类别的宏观平均值得出其在评估集上的总体性能。
考虑到ChatGPT在评估数学和编码任务方面的局限性,计算包括所有类别的分数(表示为average_score)。
四、实验结论
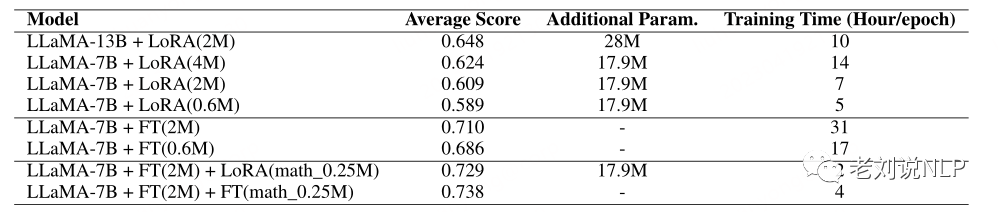 在上表中:
在上表中:
LLaMA-13B+LoRA(2M)表示使用LLaMA-13 B作为基本模型和LoRA训练方法在2M指令数据上训练的模型
LLaMA-7B+FT(2M)+LoRA(math_0.25M)表示在0.25M数学指令数据上使用LLaMA-72B+FT作为基本模型和LoRA训练方法训练的模型
LLaMA-77B+FT(2M)+FT(math_2.25M)代表使用增量全参数微调训练的模型。关于训练时间,所有这些实验都是在8个NVIDIA A100-40GB GPU上进行的。
在此基础上,可以得到比较结论:
1、LoRA调优的基本模型和数据集规模的比较
首先,该工作设计了一个实验来比较基于LoRA的指令调优在不同大小的指令数据集上的性能。
从结果中可以看出,与大多数学习任务类似,随着数据集大小的增加,基于LoRA的指令调整模型在指令理解方面表现出更好的性能。
其次,不同基础模型(LLaMA-7B和LLaMA13B)对性能的影响也不同。可以看出,具有更多参数的基础模型带来了性能的显著提高。使用LLaMA-7B+LoRA(2M)作为基础,从7B变为13B与从2M变为4M相比,性能有了更大的提高。
最后,在训练时间方面,还可以观察到LLaMA-13B+LoRA(2M)比LLaMA-7B+LoRA(4M)具有一定的优势。当使用这两个模型进行推理时,基于LLaMA7B的模型由于其较低数量的全局参数而在推理速度和成本方面具有优势。
2、全参数和基于LoRA的微调之间的比较
该工作还基于LoRA模型的性能与全参数微调进行了比较,对0.6M和2M的指令训练数据进行了全参数微调,训练了两个模型。
可以看出,全参数微调带来了更好的结果。
我们可以看到机理分析:
一种直观的理解或分析是,经过训练生成下一个单词的预训练大型语言模型需要更复杂的学习任务才能切换到指导以下内容。LoRA的学习方法只能改变相对较少的参数,与改变所有参数相比,这更具挑战性。
但在训练时间上,与LoRA微调相比,使用全参数微调需要大约3-5倍的时间成本来完成训练。
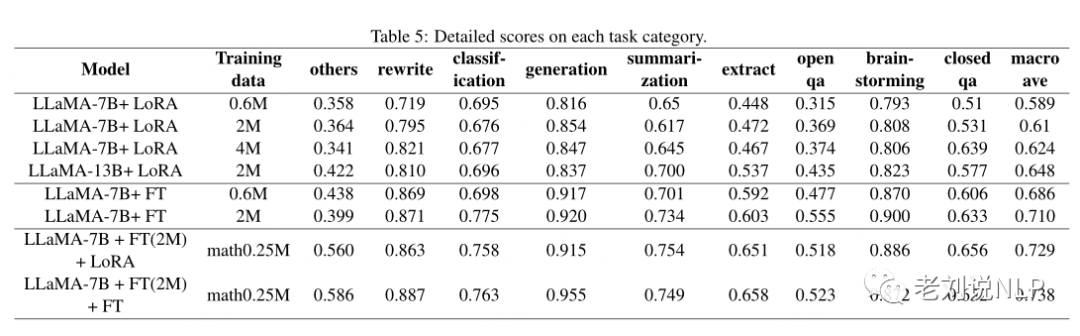
3、对指定任务执行LoRA微调
类别Other包含两种类型的数据:数学和代码,其中数学指的是解决数学应用程序问题,代码指的是代码生成,可以看到,模型在数学任务上表现不佳,分数大多低于0.5。
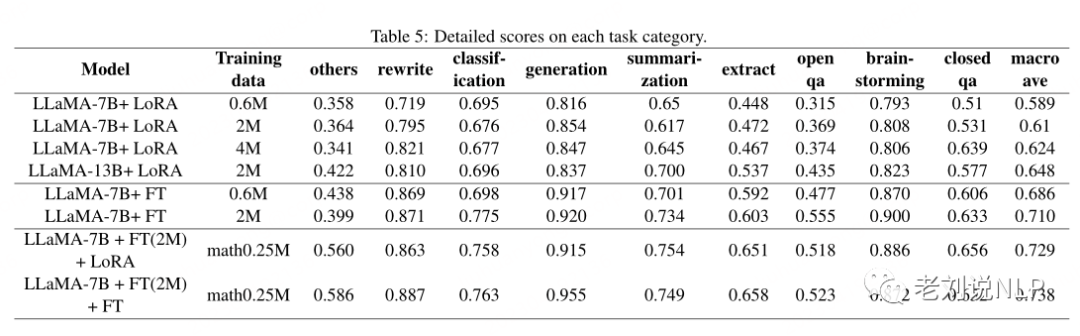
为了验证LoRA在特定任务上的适应能力,该工作使用增量0.25M数学数据集(math_0.25M)来适应指令微调的大型语言模型(选择LLaMA-7B+FT(2M)作为基本模型)。
作为比较,使用了学习率为5e-7的增量微调,并训练了2个epoch,得到了两个模型,一个是LLaMA-7B+FT(2M)+LoRA(math_0.25M),另一个是LLaMA-7B+FT(2M)+FT(math_2.25M)。
从实验结果可以看到:
其一,增量微调仍然表现出更好的性能,但需要更长的训练时间。
其二,LoRA和增量微调都提高了模型的整体性能,不过,值得注意的是,LoRA和增量微调都显示出数学任务的显著改进,而其他任务的性能略有下降。这其实就是典型的遗忘问题。
五、总结
该工作使用LLaMA作为基本模型,对全参数微调和基于LoRA的微调方法进行了实验比较,并探讨了不同数量的训练数据和模型参数对基于LoRA的调整有效性的影响。从实验结果的比较中,可以观察到一些有趣的结论:
1、基础模型的选择对基于LoRA的调谐的有效性有显著影响。这表明基础模型的选择对基于LoRA的微调方法的有效性至关重要。
2、增加训练数据的数量可以不断提高模型的有效性。
3、基于LoRA的调整得益于模型参数的数量。
当前,在实际的业务工作中,需要具体业务具体分析。
参考文献
1、https://github.com/LianjiaTech/BELLE/blob/main/docs/关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。
【免责声明:老刘说NLP所有文章,所有内容均由老刘个人总结,调研阅读及探索所得,与任何机构、公司无关,仅代表个人观点】
进NLP群—>加入NLP交流群

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)