
毕业设计-基于机器学习的恶意域名检测系统
毕业设计-基于机器学习的恶意域名检测系统:僵尸网络广泛采用DGA(Domain Generation Algorithm)技术来逃避网络安全检测, DGA恶意域名的检测工作备受关注。域名系统(Domain Name System)为我国现代网络业务提供了方便,增加了用户的上网体验.与 此同时,域名系统解析也成为僵尸网络发动攻击的重要依托,为了逃避安全设施的检测,僵尸网络的攻 击也越来越复杂,其中一
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于机器学习的恶意域名检测系统
课题背景和意义
僵尸网络广泛采用DGA(Domain Generation Algorithm)技术来逃避网络安全检测, DGA恶意域名的检测工作备受关注。域名系统(Domain Name System)为我国现代网络业务提供了方便,增加了用户的上网体验.与 此同时,域名系统解析也成为僵尸网络发动攻击的重要依托,为了逃避安全设施的检测,僵尸网络的攻 击也越来越复杂,其中一个常见的技术就是在僵尸网络中使用DGA域名生成算法,使攻击服务器域名 快速变化.在该方式下,控制服务器与受控机器的通信节点是动态变化的,安全人员难以捕捉到控制服 务器的域名和IP地址,以至于无法切断联系,阻止攻击.僵尸网络利用DGA域名生成算法进行通信 的原理如下:攻击端和受控主机使用相同DGA算法,从生成的DGA域名中选取少量注册.由于通信节 点处域名不断变化,传统的黑名单防护手段在更新上无法做到及时性,并且开销较大.因此业界急需一 种有效的DGA恶意域名检测手段.
实现技术思路
一、相关研究
DGA算法通过输入随机种子,以伪随机化算法作为辅助,生成一系列的随机字符串域名.所以域名 表面上看似乎是随机的,但内部结构都是通过伪随机化算法生成的,其实是有迹可循的,比如对于算法 输入的随机种子的选择,往往会选择当前的时间、网络热词等. 当前学术界对于DGA域名的检测从未停止. 使用机器学习方法,基于语法特征基础上加入 了N-Gram模型特征,提高了算法的精确率;基于聚类和分类算法的恶意域名检测方法, 使用聚类算法分出DGA域名的类别,再使用分类算法筛选出恶意域名.将域名的语法特征细 化,提取出字母和数字的转换频率、连续字母的最大长度等特征.将隐马尔可夫模型应用于域名 检测,实验结果相较于随机森林模型效果更好.
在语法特征、N-Gram模型特征的基础上,加入了隐马尔可夫模型特征,并且出于计算复杂度 的考虑,并未将N-Gram本身出现的频率当做特征,而是选用了N-Gram平均排名.
二、恶意域名检测流程
使用机器学习工程进行域名检测流程主要包括收集数据、提取特征、模型的选择和训练、评价函数 和交叉验证4个部分
(1)收集数据.
本次实验的数据包括正常域名和DGA域名.采用Alexa网站中前1万的域名作为 正常域名,而实验中的DGA域名取自360安全网站,选取1.5万条DGA家族中的Conficker家族域 名.
(2)提取特征.
从域名数据集中提取出三类特征.一类是语法特征;一类是N-Gra 特征;最后本 文在此基础上加入隐马尔可夫特征.
(3)模型选择和训练.
选取SVM和决策树进行对比评估.
(4)评价函数和交叉验证.
使用精确率和召回率作为模型评价标准,将数据的4/5用于训练模 型,剩下的1/5用于模型预测,同时将数据多次洗牌做10次交叉验证.
三、特征分析
特征工程是恶意域名检测的关键,特征选择的好坏直接影响最后的实验结果.因此,本文对合法域 名和DGA域名特征进行深入了解,反复试验,最终得出特征集合.提取的特征有语法特征、N-Gram模 型特征、马尔可夫模型特征.N-Gram特征选取域名的unigram、bigram、trigram的平均排名;隐马尔可 夫模型特征选择的是域名从Ai到Ai+1转换的概率乘积.
语法特征
(1)域名长度.
域名最初就是为了使用户上网方便,因此合法域名长度不会太长,并且有些具有明确 的定义,而DGA域名是以伪随机算法作为辅助,生成的随机字符串,再加上域名数量日益增长,为了防 止与正常域名冲突,一般域名较长,并且没有任何含义.
在表中几个正常域名与DGA域名长度进行 了对比,可以看出正常域名长度一般在10左右,而DGA域名长度在20左右.

(2)域名熵值.
熵是衡量事物混乱程度的度 量指标.经过对大量数据的分析比对,正常域名 内部结构相对整齐有规律,混乱程度较低;而 DGA域名随机性强,分布混乱,熵值也会更大. 本文从数据集中选取1万条正常域名和1万条 DGA域名,如图所示,正常域名熵值在1.0 -2.0之间,而DGA域名大都集中在2.0- 2.5之间,因此,熵值可以作为很好的区别特征.
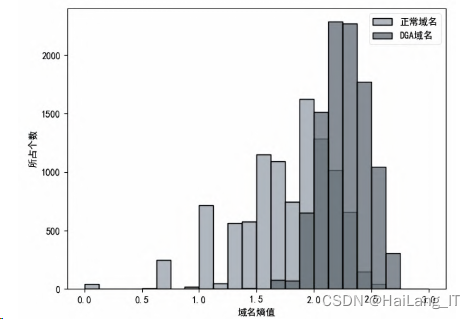
(3)元音字母比例.
正常域名为了让人读起来更加顺口会在辅音字母的基础上加入一些元音字母, 来增加域名的可读性;而DGA域名生成时未考虑这个因素,元音字母会相对较少,因此DGA域名可读 性差.从数据集中取1万正常域名和1万DGA域名,DGA域名元音占比在0.1-0.3,正常域名元音占 比在0.3-0.5.因此,元音字母比例可以作为区别特征.
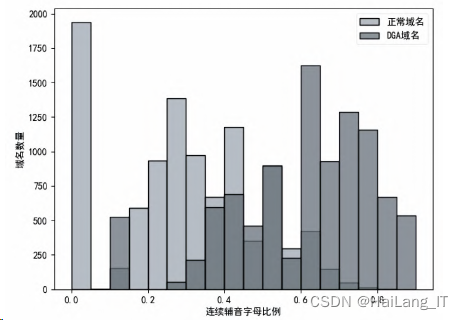
(4)连续辅音字母比例.
经过大量数据分析比对,DGA域名的连续辅音字母比例较高.如图可以 看出正常域名大多在0.2-0.4之间,而DGA域名在0.6-0.8之间的居多,尽管有少数正常域名和 DGA域名比例有重叠,但是整体来说连续辅音字母比例特征区分度很大.
(5)顶级域名.
正常域名的顶级域比较常见,例如.cn和.com等,而DGA恶意域名会选一些审核 不严的,不常见的域名如.ru和.ws等.本文选取正常域名常见三个顶级域,取1万条正常域名和1万 条DGA域名,分别统计正常和恶意域名中各类别的数量,正常域名中有2872条使用的是常见顶级域, DGA域名有0条.因此顶级域名对于域名检测的重要性比重很大.
N-Gram平均排名
N-Gram模型是自然语言处理常用的模型,常用于词语分析,语音识别,词语分类等.它的基本思想 是将文本内容进行固定大小的滑动窗口操作,对每个窗口进行频率统计,以此概率来推断下一组词.本 文提取正常域名和DGA域名的unigram(一个字符)、bigram(两个字符)和trigram(三个字符)特征,采 用N-Gram函数对域名字符进行统计,例如将www.goole.com放入unigram函数中会得到单个的字 符数组[c,e,g,l,m,o,w]以及字符出现的频率,一般来说,可以将域名字符频率直接当做特征,但是特 征维度会很大,会影响训练速度.换个角度思考,正常域名相比于DGA域名更加好念,因此它的频率排 名相对靠前,而DGA域名是随机生成的,频率相对靠后,所以本文选用N-Gram模型的平均排名作为 域名区别特征.
隐马尔可夫模型特征
隐马尔可夫模型是一种统计模型,大致思想是通过已知去预测未知,输入已知序列到转换矩阵,得 到未知序列出现的概率,用于词语分类、语言识别等自然语言处理领域.本文以1万正常域和1万DGA 域名来训练隐含马尔可夫链,计算从Ai到Ai+1转换的概率,这里所说的Ai为域名的当前字符,Ai+1为 下一个字符,例如baidu.com,如果Ai为d,那么Ai+1为u.以每个域名字符从Ai到Ai+1转换概率的乘积作为特征,为了防止下溢,对每个域名概率结果取对数.正常域名的隐马尔可夫模型数值大部分在- 15和-30之间,而DGA域名的隐马尔可夫模型数值在-35和-50之间,正常域名的值是高于DGA 域名的,所以隐马尔可夫模型特征可以作为区别特征.
四、实验与检测效果分析
实验中的正常域名数据取自www.Alexa.com网站,在实验中采用在Alexa网站中前排名前1万 条域名作为实验过程中的正常域名.而实验中的DGA域名取自网站data.netlab.360.com/dga/,该网 站每天也都会更新DGA域名,在实验中采用了1.5万个DGA域名来作为实验中的样本,并标注类别, 选取语法特征、N-Gram模型特征和隐马尔可夫模型特征作为区别特征,然后使用SVM算法和决策树 算法进行模型训练,为了实验的严谨性,进行10次交叉验证,选择4/5的数据用于训练模型,剩余1/5 进行预测,使用精确率、召回率作为评价指标.
算法概述
支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,广泛应用于统计分析、 回归和分类等.它的基本思想是使用核函数映射到高维空间,在高维空间中找到间隔最大的分类超平 面.作为一种新的机器学习方法,依据结构风险最小原理,支持向量机表现出独特的泛化和推广能力,已 逐渐成为国内外机器学习研究的热点.决策树是一种常用的分类算法,它是一种树形结构,基本思想是, 通过对数据集样本的学习建立决策树,内部节点代表特征的选择,最后的叶子节点代表分类的结果.
特征评估
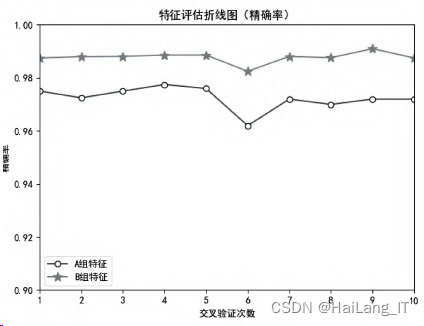
将两组特征组合进行评估,特征组合如下:A组为语法特征和N-Gram模型特征组合,B组为 语法特征、N-Gram模型特征和马尔可夫模型特征,为了使实验更加严谨,进行10次交叉验证,两种特 征组合下的精确率和召回率如图所示,实验发现:B组特征组合下的精确率在98%以上,而A组 特征组合下的精确率在97%左右.因此,说明分类模型在语法特征、N-Gram模型特征的基础上添加了 隐马尔可夫模型特征后分类效果有了一定的提高.
两种特征组合的精确率:
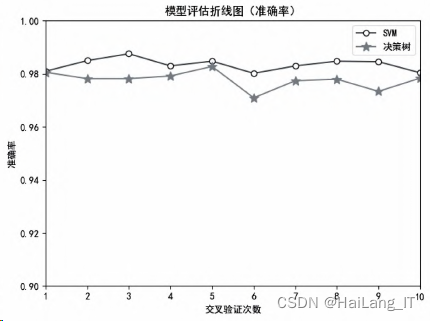
不同模型的准确率折线图:
模型评估
选取语法特征、N-Gram模型特征和隐马尔可夫模型特征作为区别特征,对比SVM算法和决策树 算法两种训练模型,如图所示,使用SVM训练模型准确率可以达到0.98以上,而使用决策树模型准确率在0.97左右,因此,可以得出结论:SVM模型相较于决策树模型分类效果更好.
五、总结
本文的目的是分析域名的语法特性,在语法特征、N-Gram模型特征基础上加入隐马尔可夫模型作 为区别特征,以提升DGA域名的检测率,对于N-Gram模型特征维度太大的问题,本文选取域名的N- Gram平均排名作为特征,减少了计算复杂度,通过两种特征组合的精确率、召回率对比,两种训练模型 准确率对比,印证了上面的结论.
但是选取的恶意域名数据是DGA家族中的Conficker域名数据, 可能最后训练出的模型对于其他种类的DGA域名检测率并不太理想,因此,下一步工作是选取的数据 集更加广泛化,找出更多区分特征,使训练模型精确率更高、适应性更强.
实现效果图样例
恶意域名检测系统:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)