
Python大数据处理利器,PySpark的入门实战
Pandas的dataframe与PySpark的dataframe有许多相似之处,熟悉Pandas的同学可以很快适应它的API。目前可以粗浅地把PySpark理解为”分布式的Pandas“,不过,PySpark还有分布式机器学习的功能——Spark MLlib(可以理解为分布式的Sklearn、TensorFlow等),后续会给大家介绍。在集群中,它的dataframe可以分布在不同的机器上,以
PySpark极速入门
一:Pyspark简介与安装
什么是Pyspark?
PySpark是Spark的Python语言接口,通过它,可以使用Python API编写Spark应用程序,目前支持绝大多数Spark功能。目前Spark官方在其支持的所有语言中,将Python置于首位。

如何安装?
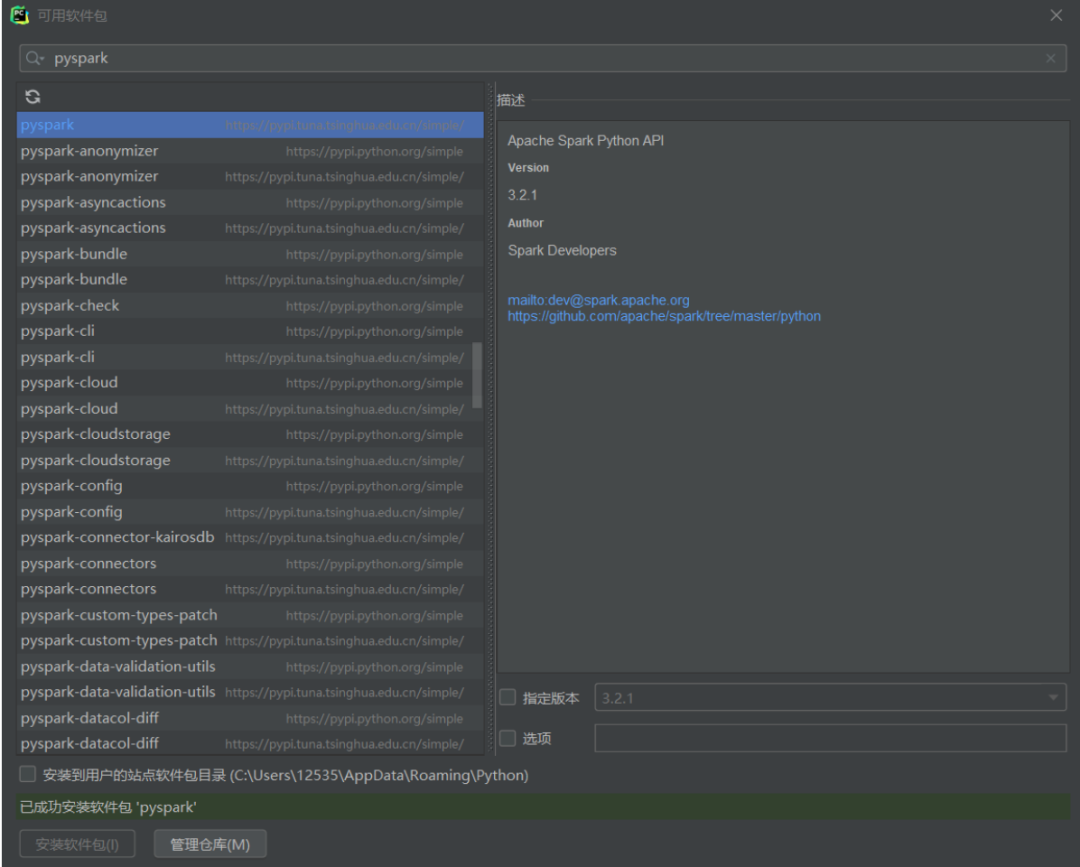
在终端输入
pip intsall pyspark

或者使用pycharm,在GUI界面安装

二:编程实践
加载、转换数据
# 导入pyspark
# 导入pandas, 稍后与pyspark中的数据结构做对比
import pyspark
import pandas as pd
在编写spark程序前,我们要创建一个SparkSession对象
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Spark极速入门").getOrCreate()
可以看到会话的一些信息:使用的Spark版本、运行模式、应用程序名字
演示环境用的是local本地模式, * 代表的是使用全部线程 如果想用集群模式的话,可以去查看集群搭建的相关教程 届时pyspark程序作为spark的客户端,设置连接集群,就是真正的分布式计算了 目前只是本地模式,用多线程去模拟分布式计算。
spark

看看我们将用到的test1数据吧

使用read方法,用option设置是否读取csv的头,再指定路径就可以读取数据了
df_spark = spark.read.option("header", "true").csv("./data/test1.csv")
看看是什么类型
type(df_spark)
pyspark.sql.dataframe.DataFrame再看看用pandas读取是什么类型
type(pd.read_csv("./data/test1.csv"))
pandas.core.frame.DataFrame可以发现Spark读取这种结构化数据时,用的也是和pandas类似的dataframe结构 这也是Spark应用最广泛的数据结构
使用show方法打印数据
df_spark.show()
+---------+---+----------+------+
| Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
+---------+---+----------+------+使用printSchema方法打印元数据信息,发现明明是数值类型的,它却读取为了字符串类型
df_spark.printSchema()
root
|-- Name: string (nullable = true)
|-- age: string (nullable = true)
|-- Experience: string (nullable = true)
|-- Salary: string (nullable = true)在读取时,加上类型推断,发现此时已经能正确读取了
df_spark = spark.read.option("header", "true").csv("./data/test1.csv",inferSchema=True)
df_spark.printSchema()
root
|-- Name: string (nullable = true)
|-- age: integer (nullable = true)
|-- Experience: integer (nullable = true)
|-- Salary: integer (nullable = true)选择某些列, 可以发现不管选多列还是选单列,返回的都是dataframe 返回的也同样可以printSchema、show等dataframe使用的方法,做到了结构的统一
df_spark.select(["Name", "age"])
DataFrame[Name: string, age: int]df_spark.select("Name")
DataFrame[Name: string]df_spark.select(["Name", "age", "Salary"]).printSchema()
root
|-- Name: string (nullable = true)
|-- age: integer (nullable = true)
|-- Salary: integer (nullable = true)不用select,而用[]直接选取,就有点类似与pandas的series了
df_spark["Name"]
Column<'Name'>column就不能直接show了
df_spark["age"].show()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [15], in <cell line: 1>()
----> 1 df_spark["age"].show()
TypeError: 'Column' object is not callable用describe方法可以对dataframe做一些简单的统计
df_spark.describe().show()
+-------+------+------------------+-----------------+------------------+
|summary| Name| age| Experience| Salary|
+-------+------+------------------+-----------------+------------------+
| count| 6| 6| 6| 6|
| mean| null|26.333333333333332|4.666666666666667|21333.333333333332|
| stddev| null| 4.179314138308661|3.559026084010437| 5354.126134736337|
| min|Harsha| 21| 1| 15000|
| max| Sunny| 31| 10| 30000|
+-------+------+------------------+-----------------+------------------+用withColumn方法给dataframe加上一列
df_spark = df_spark.withColumn("Experience After 3 year", df_spark["Experience"] + 3)
df_spark.show()
+---------+---+----------+------+-----------------------+
| Name|age|Experience|Salary|Experience After 3 year|
+---------+---+----------+------+-----------------------+
| Krish| 31| 10| 30000| 13|
|Sudhanshu| 30| 8| 25000| 11|
| Sunny| 29| 4| 20000| 7|
| Paul| 24| 3| 20000| 6|
| Harsha| 21| 1| 15000| 4|
| Shubham| 23| 2| 18000| 5|
+---------+---+----------+------+-----------------------+用drop方法删除列
df_spark = df_spark.drop("Experience After 3 year")
df_spark.show()
+---------+---+----------+------+
| Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
+---------+---+----------+------+用withColumnRename方法重命名列
df_spark.withColumnRenamed("Name", "New Name").show()
+---------+---+----------+------+
| New Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
+---------+---+----------+------+处理缺失值
看看接下来要带缺失值的test2数据吧

CSeoe.png
df_spark = spark.read.csv("./data/test2.csv", header=True, inferSchema=True)
df_spark.show()
+---------+----+----------+------+
| Name| age|Experience|Salary|
+---------+----+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
| Mahesh|null| null| 40000|
| null| 34| 10| 38000|
| null| 36| null| null|
+---------+----+----------+------+用na.drop删除缺失值 how参数设置策略,any意思是只要一行里有缺失值,那就删了 any也是how的默认参数
df_spark.na.drop(how="any").show()
+---------+---+----------+------+
| Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
+---------+---+----------+------+可以通过thresh参数设置阈值,代表超过一行中缺失值的数量超过这个值,才会被删除
df_spark.na.drop(how="any", thresh=2).show()
+---------+----+----------+------+
| Name| age|Experience|Salary|
+---------+----+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
| Mahesh|null| null| 40000|
| null| 34| 10| 38000|
+---------+----+----------+------+也可以用subset参数设置关注的列 下面代码意思是,在Experience列中,只要有缺失值就删掉
df_spark.na.drop(how="any", subset=["Experience"]).show()
+---------+---+----------+------+
| Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
| null| 34| 10| 38000|
+---------+---+----------+------+用fillna填充缺失值, 可以用字典对各列的填充值进行设置
df_spark.fillna({'Name': 'unknown', 'age': 18, 'Experience': 0, 'Salary': 0}).show()
+---------+---+----------+------+
| Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
| Mahesh| 18| 0| 40000|
| unknown| 34| 10| 38000|
| unknown| 36| 0| 0|
+---------+---+----------+------+还可以调用机器学习模块的相关方法, 通过设置策略,可以用平均数、众数等方式填充
from pyspark.ml.feature import Imputer
imputer = Imputer(
inputCols = ['age', 'Experience', 'Salary'],
outputCols = [f"{c}_imputed" for c in ['age', 'Experience', 'Salary']]
).setStrategy("mean")
imputer.fit(df_spark).transform(df_spark).show()
+---------+----+----------+------+-----------+------------------+--------------+
| Name| age|Experience|Salary|age_imputed|Experience_imputed|Salary_imputed|
+---------+----+----------+------+-----------+------------------+--------------+
| Krish| 31| 10| 30000| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000| 30| 8| 25000|
| Sunny| 29| 4| 20000| 29| 4| 20000|
| Paul| 24| 3| 20000| 24| 3| 20000|
| Harsha| 21| 1| 15000| 21| 1| 15000|
| Shubham| 23| 2| 18000| 23| 2| 18000|
| Mahesh|null| null| 40000| 28| 5| 40000|
| null| 34| 10| 38000| 34| 10| 38000|
| null| 36| null| null| 36| 5| 25750|
+---------+----+----------+------+-----------+------------------+--------------+过滤操作
还是切换到test1数据
df_spark = spark.read.csv("./data/test1.csv", header=True, inferSchema=True)
df_spark.show()
+---------+---+----------+------+
| Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
+---------+---+----------+------+可以使用filter方法对数据进行过滤操作,类似于SQL中的where 可以使用字符串的方式,也可以利用column方式去传递条件
df_spark.filter("Salary <= 20000").show()
+-------+---+----------+------+
| Name|age|Experience|Salary|
+-------+---+----------+------+
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
|Shubham| 23| 2| 18000|
+-------+---+----------+------+df_spark.filter(df_spark["Salary"]<=20000).show()
+-------+---+----------+------+
| Name|age|Experience|Salary|
+-------+---+----------+------+
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
|Shubham| 23| 2| 18000|
+-------+---+----------+------+如果是字符串,用 and 表示同时满足多个条件 如果是用column,用( & ) 连接多个条件
df_spark.filter("Salary <= 20000 and age <= 24").show()
+-------+---+----------+------+
| Name|age|Experience|Salary|
+-------+---+----------+------+
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
|Shubham| 23| 2| 18000|
+-------+---+----------+------+df_spark.filter(
(df_spark["Salary"]<=20000)
& (df_spark["age"]<=24)
).show()
+-------+---+----------+------+
| Name|age|Experience|Salary|
+-------+---+----------+------+
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
|Shubham| 23| 2| 18000|
+-------+---+----------+------+column中,用|表示或, ~表示取反
df_spark.filter(
(df_spark["Salary"]<=20000)
| (df_spark["age"]<=24)
).show()
+-------+---+----------+------+
| Name|age|Experience|Salary|
+-------+---+----------+------+
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
|Shubham| 23| 2| 18000|
+-------+---+----------+------+df_spark.filter(
(df_spark["Salary"]<=20000)
| ~(df_spark["age"]<=24)
).show()
+---------+---+----------+------+
| Name|age|Experience|Salary|
+---------+---+----------+------+
| Krish| 31| 10| 30000|
|Sudhanshu| 30| 8| 25000|
| Sunny| 29| 4| 20000|
| Paul| 24| 3| 20000|
| Harsha| 21| 1| 15000|
| Shubham| 23| 2| 18000|
+---------+---+----------+------+分组聚合
换一个数据集test3

df_spark = spark.read.csv("./data/test3.csv", header=True, inferSchema=True)
df_spark.show()
+---------+------------+------+
| Name| Departments|salary|
+---------+------------+------+
| Krish|Data Science| 10000|
| Krish| IOT| 5000|
| Mahesh| Big Data| 4000|
| Krish| Big Data| 4000|
| Mahesh|Data Science| 3000|
|Sudhanshu|Data Science| 20000|
|Sudhanshu| IOT| 10000|
|Sudhanshu| Big Data| 5000|
| Sunny|Data Science| 10000|
| Sunny| Big Data| 2000|
+---------+------------+------+使用groupby方法对dataframe某些列进行分组
df_spark.groupBy("Name")
<pyspark.sql.group.GroupedData at 0x227454d4be0>可以看到分组的结果是GroupedData对象,它不能使用show等方法打印 GroupedData对象需要进行聚合操作,才能重新转换为dataframe 聚合函数有sum、count、avg、max、min等
df_spark.groupBy("Departments").sum().show()
+------------+-----------+
| Departments|sum(salary)|
+------------+-----------+
| IOT| 15000|
| Big Data| 15000|
|Data Science| 43000|
+------------+-----------+三:总结
Pandas的dataframe与PySpark的dataframe有许多相似之处,熟悉Pandas的同学可以很快适应它的API。目前可以粗浅地把PySpark理解为”分布式的Pandas“,不过,PySpark还有分布式机器学习的功能——Spark MLlib(可以理解为分布式的Sklearn、TensorFlow等),后续会给大家介绍。在集群中,它的dataframe可以分布在不同的机器上,以此处理海量数据。有兴趣的小伙伴可以通过虚拟机搭建一个Spark集群,进一步学习Spark。
Apache Spark™ - 用于大规模数据分析的统一引擎
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)