
多模态模型总结
多模态预训练模型总结
BEiT-3
Image as a Foreign Language:BEiT Pretraining for ALL vision and Vision-language Tasks
提出背景:
在计算机视觉领域(CV)通常使用的是有监督的预训练,就是利用有标注的数据进行训练,但是随着视觉模型的不断扩大,标注数据难以满足模型需求,以往的无标注数据的自监督都是采用对比学习,但是对比学习对图像干扰操作过于依赖。当噪声太简单时,模型学不到有用的知识,而对图像改变过大,将会面目全非,模型无法进行有效学习,所以对比学习需要大批量的训练,对显存和工程实现要求很高,在此背景下,2021年推出了生成式自监督的视觉预训练模型BEiT,借助掩码图像建模(Masked Image Modeling ,MIM)方法完成预训练任务。
而BEiT-3(通用多模态基础模型)是在BEiT(生成式自监督视觉预训练模型)的基础上发展而来

BEiT-3在广泛的视觉,视觉-语言任务上都取得了最好的迁移性能
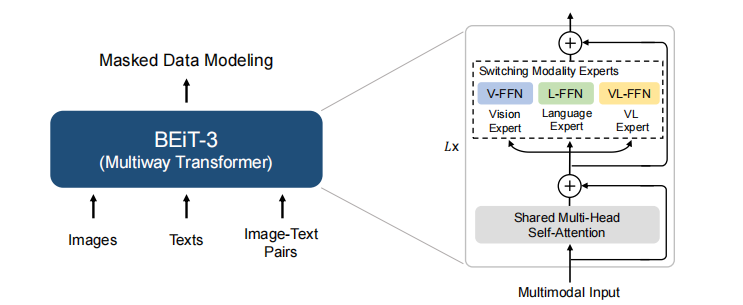
在BEiT-3 中主要从骨干网络,预训练方法和模型规模化三个方面推动视觉-语言与训练任务的融合
首先论文使用Multiway Transformer 作为骨干模型来编码不同的模态,每个Multiway Transformer 模块都由一个共享的自注意力模块和一组用于不同模态的前馈网络池(模态专家)组成,可以同时编码多种模态,此外论文采取模块化设计,统一的架构使得该模型可以适用于不同的视觉及视觉-语言下游任务。其中Multiway Transformer每一层都包括一个视觉专家和一个语言专家
BEiT-3由1408个隐藏神经元,6144个中间层神经元,16组注意力模块的40层Multiway Transformer骨干网络组成,模型包含大约19亿个参数,其中视觉6.92亿,语言6.92亿,VL0.52亿,共享自注意模块3.17亿,论文对模型进行了100万次的迭代,每个批量的训练数据包含6144个sample,其中包含2048text,2048image,和2048text-image。

beit展望:未来的工作中,正在将致力于对多语言BEIT-3进行预培训,并在BEIT-3中包括更多的模式(如音频),以促进跨语言和跨模式的转移,并推进跨任务、语言和模式的大规模预培训的大规模融合
Vlmo:
对视觉语言的预训练主要分两类:CLIP和ALIGN,第一类利用双编码器分别对图像和文本进行编码,并使用余弦相似度或线性投影层来建模图像和文本[35,18]之间的交互。通常采用图像-文本对比学习的方法来优化模型。双编码器模型对于视觉语言检索任务是有效的。然而,简单的交互并不足以处理需要复杂推理的任务,如视觉推理和视觉问题回答;第二类使用具有跨模态注意的深度融合编码器对图像和文本的交互进行建模。图像-文本匹配、掩码语言建模、单词区域/补丁对齐、掩码区域分类和特征回归被广泛应用于训练基于融合编码器的模型。这些模型在视觉语言分类任务中取得了更好的性能,而所有图像-文本对的联合编码导致检索任务的推理速度较慢。Vlmo不同的是使用共享的MOME变压器进行统一的预训练,使模型能够对检索任务执行单独的编码,并联合编码图像-文本对,以捕获分类任务的更深层次的交互。
主要贡献:
1、提出了一个统一的视觉语言预训练模型VLMO,它可以用作分类任务的融合编码器,也可以作为检索任务的双编码器进行微调。
2、介绍了一种用于视觉语言任务的通用多模态转换器,即MOME转换器,以编码不同的模态。它由模态专家捕获特定于模态的信息,并通过跨模态共享的自我注意模块来对齐不同模态的内容。
3、论文表明,使用大量的仅图像和仅文本数据的阶段预训练极大地改进了我们的视觉语言预训练模型。
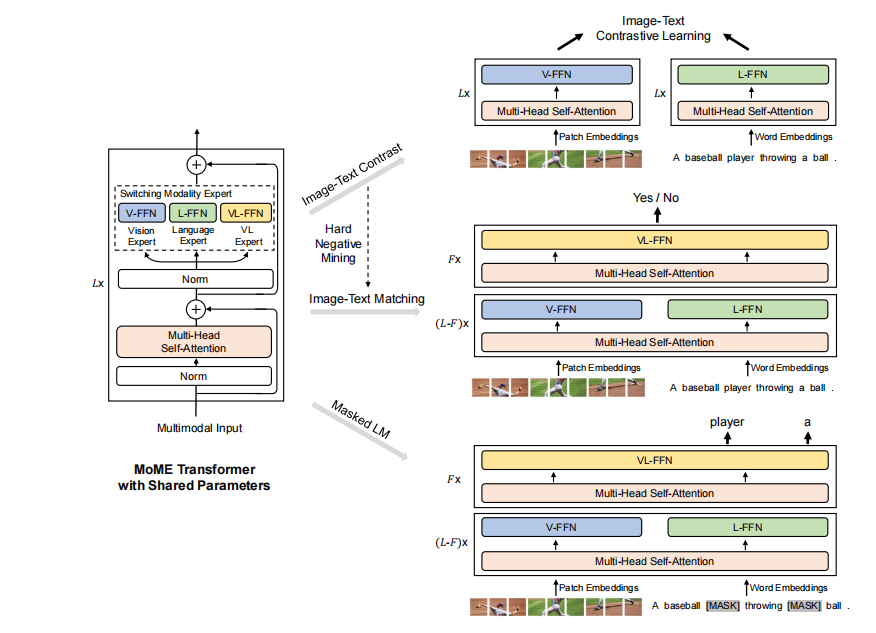
该模型参数在图像-文本对比学习、掩蔽语言建模和图像-文本匹配的训练前任务中共享。在微调过程中,灵活的建模使我们能够使用VLMO作为双编码器(即,分别将图像和文本编码用于检索任务)或融合编码器(即,联合编码图像-文本对,以更好地跨模式交互)。
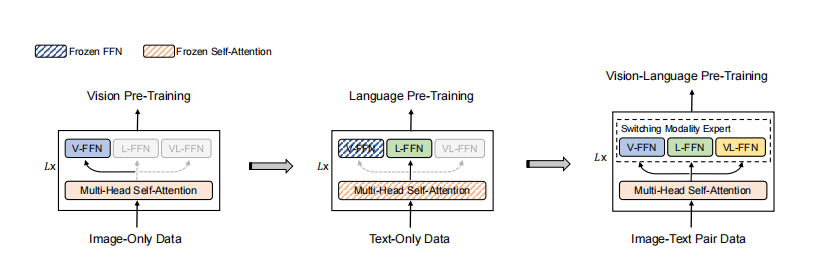
使用仅图像和仅文本语料库进行阶段性预训练。我们首先对视觉专家(V-FFN)和自我注意模块进行了大规模的仅图像数据的预训练,就像在BEIT [2]中一样。然后冻结视觉专家和自我注意模块的参数,通过对大量的纯文本数据进行掩码语言建模,训练语言专家(L-FFN)。最后,我们用视觉语言的预训练来训练整个模型。

微调在视觉语言检索和分类任务上的VLMO。该模型可以作为一个双编码器进行微调,以分别对图像和文本进行编码的检索任务。VLMO还可以作为一个融合编码器来处理分类任务中的图像-文本对的交互。
VLMO通过图像和文本表示的图像-文本对比学习、掩码语言建模和图像-文本对表示的图像-文本匹配进行联合预训练。
Image-Text Contrast:
给定一批N个图像-文本对,图像-文本对比学习的目标是预测N个×N个可能的图像-文本对的匹配对。在一个训练批中有N^2−N个负图像-文本对。利用图像到文本和文本到图像相似性的交叉熵损失来训练模型。
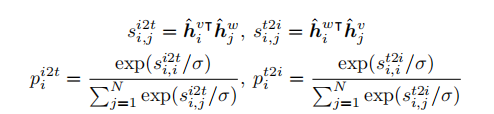
其中第一个s代表第i图像与第j文本对的相似度(图象对文本的相似度),第二个s代表文本对图象的相似度;h分别表示对图像和文本的归一化向量;p是softmax-normalized 相似度
Masked Language Modeling:
在文本序列中随机选择标记,并将它们替换为[MASK]标记。该模型被训练成从所有其他未掩蔽标记和视觉线索中预测这些掩蔽标记。然后使用15%的掩蔽概率作为BERT。掩码标记的最终输出向量被输入到整个文本词汇表上的分类器中。
Image-Text Matching:
图像-文本匹配的目的是预测图像和文本是否匹配。我们使用[T_CLS]标记的最终隐藏向量来表示图像-文本对,并将该向量输入具有交叉熵损失的分类器进行二值分类。这里采用全局hard-negative sample
mining,这样可以找到更多信息丰富的图像-文本对,并显著地改进了模型。
VLMO-Base由12层transformer块、768个隐藏神经元和12个注意头组成。VLMO-Large是一个24层的transformer网络,有1024个隐藏神经元和16个注意头。对于基本尺寸模型和大尺寸模型,前馈网络的中等尺寸分别为3072和4096。


分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐
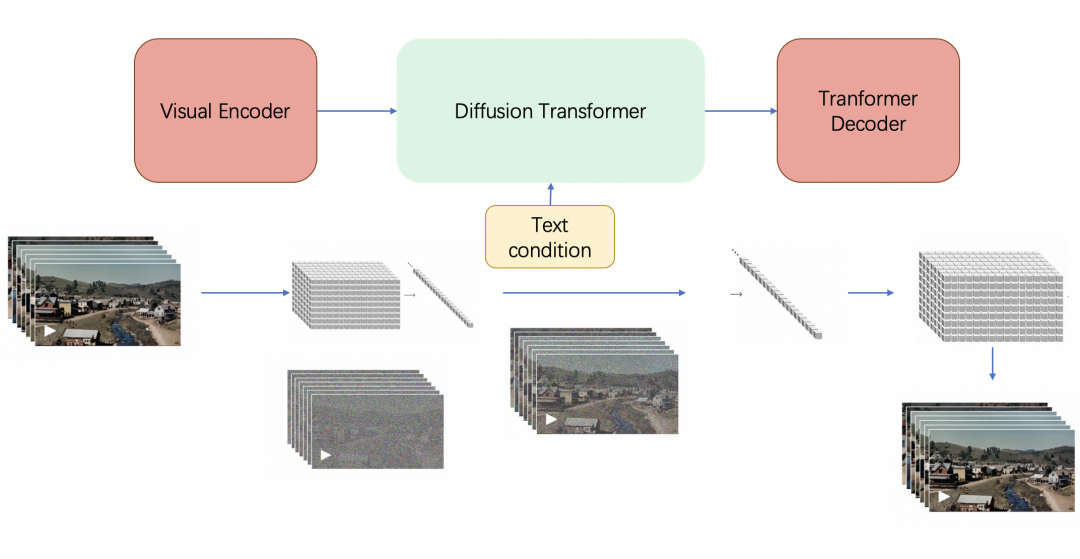

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)