
大数据系列——什么是hdfs?hdfs用来干什么的?
大数据系列——什么是hdfs?hdfs用来干什么的?
·
目录
一、什么是HDFS
- HDFS全称是Hadoop Distributed File System
- 是一种分布式文件系统(HDFS使用多台计算机存储文件,对外提供统一操作文件的接口)
- Hodoop使用HDFS(Hadoop Distributed File System)作为存储系统。
二、hdfs用来干什么的
用于大规模数据的分布式读写,特别是读多写少的场景
三、hdfs适用场景
- 具备高度容错特性,支持高吞吐量数据访问,可以在处理海量数据(TB或PB级别以上)的同时最大可能的降低成本。
- 读多写少的场景
a.存储非常大的文件并且对延时没有要求
b.一次写入,多次读取。数据集经常从数据源生成或者拷贝,然后做很多分析工作。
四、hdfs不适合的场景
a.对延时有要求;
b.多方读写
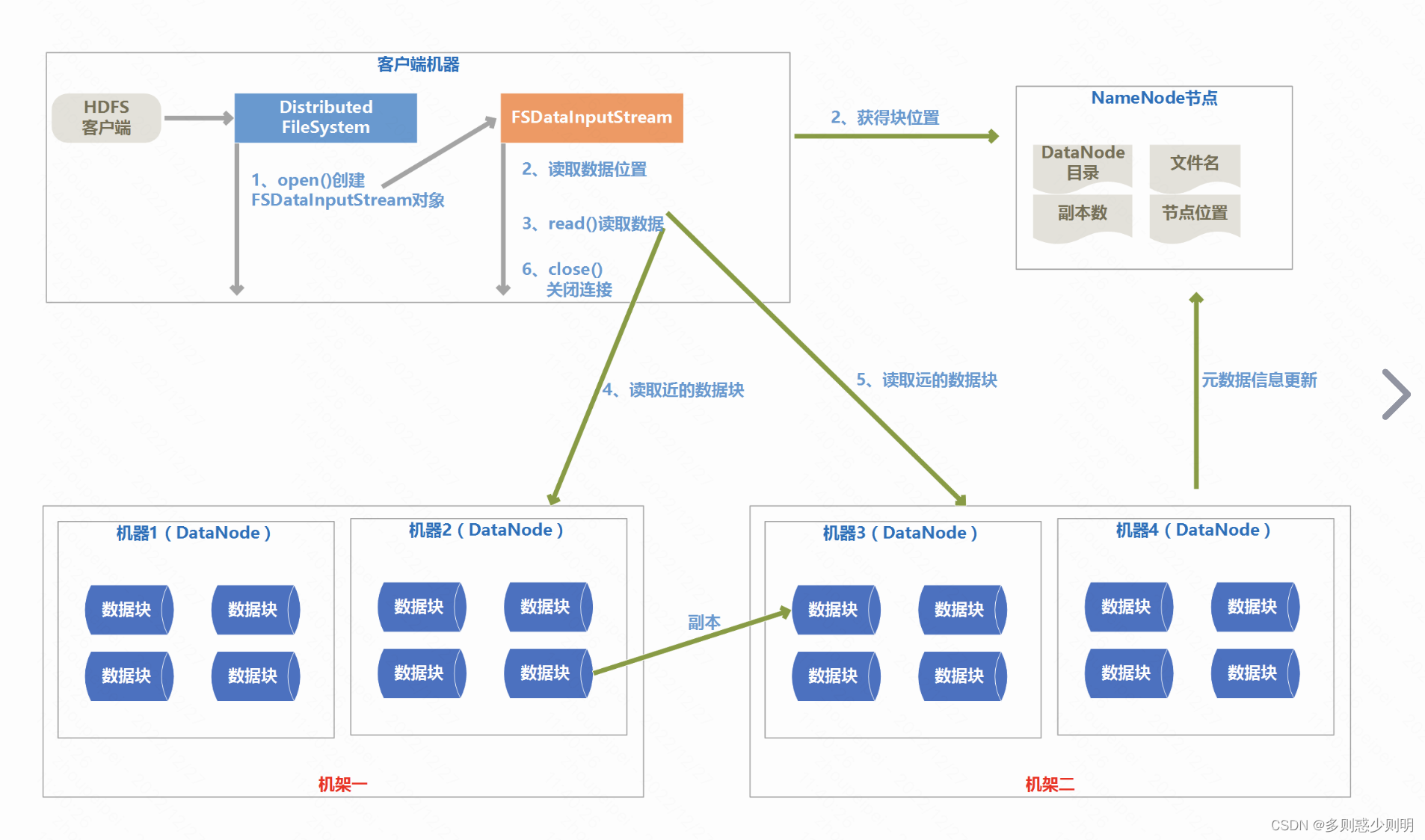
五、hdfs 架构
- HDFS是一个主/从体系结构(经典的Master和Slave架构)。 HDFS由四部分组成,HDFS Client,NameNode,DataNode和Secondary NameNode。
- 每一个HDFS集群包括一个NameNode和多个DataNode。
Client:客户端
a.文件切分,文件上传HDFS的时候,将文件切分成一个一个的数据块(Block)进行存储 。
b.与NameNode交互,获取文件的位置 。
c.与DataNode交互,读取或写入数据 。 存储实际的数据块 执行数据库的读/写操作
基本概念
| 名称 | 描述 |
|---|---|
| NameNode | 用于管理文件系统的命名空间、维护文件系统的目录结构树以及元数据信息,记录写入的每个数据块(Block)与其归属文件的对应关系。
此信息以命名空间镜像(FSImage)和编辑日志(EditsLog)两种形式持久化在本地磁盘中。 |
| DataNode | DataNode是文件的实际存放位置。
DataNode会根据NameNode或Client的指令来存储或者提供数据块,并且定期的向NameNode汇报该DataNode存储的数据块信息。 |
| Client | 通过Client来访问文件系统,然后由Client与NameNode和DataNode进行通信。Client对外作为文件系统的接口,类似于POSIX。 |
| Blocks | HDFS将文件拆分成128 MB大小的数据块进行存储,这些Block可能存储在不同的节点上。HDFS可以存储更大的单个文件,甚至超过任何一个磁盘所能容纳的大小。一个Block默认存储3个副本(EMR Core节点如果使用云盘,则为2副本),以Block为粒度将副本存储在多个节点上。此方式不仅提高了数据的安全性,而且对于分布式作业可以更好地利用本地的数据进行计算,减少网络传输。 |
| Secondary NameNode | 对于非高可用集群,默认会启动一个Secondary NameNode进程。Secondary NameNode的作用是消费EditsLog,定期地合并FsImage和EditsLog,生成新的FsImage文件,降低了NameNode的压力。 |
| 高可用 | 对于高可用集群,默认会启动两个NameNode,一个是Active NameNode,另一个是Standby NameNode,两个NameNode承担不同角色。
Active NameNode负责处理DataNode和Client的请求,Standby NameNode跟Active NameNode一样拥有最新的元数据信息,随时准备在Active NameNode出现异常时接管其服务。如果Active NameNode异常,Standby NameNode会感知到并切换成Active NameNode的角色处理DataNode和Client请求。 |
六、HDFS基础命令
(hdfs 命令最常用的就是: hdfs dfs -[linux的命令])
1、 ls: 列出根目录下文件列表 hdfs dfs -ls /
使用-ls -R: 整个目录下递归运行ls ,如 hdfs dfs -lsr /
2、 mkdir: hdfs dfs mkdir <paths>
hdfs dfs -mkdir tmp # 在hdfs文件系统中/user/test 目录下创建tmp目录
hdfs dfs -mkdir /tmp # 在hdfs文件系统的根目录下创建一个tmp目录
3、 hdfs dfs -rm -r -f
hdfs dfs -rm -r -f /test # 删除根目录下的test目录
hdfs dfs -rmdir /test # 删除目录:只能删除空目录
4、put :将本地文件/文件夹拷贝到HDFS内.
例如 将a.txt上传到根目录下, hdfs dfs -put a.txt /
5、get :将HDFS中的文件拷贝到本地.
例如 将HDFS中根目录下a.txt文件拷贝到本地当前目录 hdfs dfs -get /a.txt ./
6、mv:将HDFS的文件移动到目标路径(HDFS内部的文件移动).
例如 hdfs dfs -mv /a.txt /test
7、rm:删除文件或目录
8、cp:将文件拷贝到目标路径
9、cat :显示文件内容.
例如 hdfs dfs -cat /test/a.txt; hdfs dfs -cat ./tmp/exception.log
10、hdfs dfs -text. # 查看文件内容,支持压缩文件的查看而不会乱码
hdfs dfs -text ./tmp/exception.log
11、# 从根目录下精确搜索exception.log文件
hdfs dfs -find / -name exception.log
12、hdfs dfs -count /user/test # 对/user/test 目录进行统计
13、chmod:改变文件权限
14、chown :改变文件所属用户和用户组
15、appendToFile :合并本地文件拷贝至HDFS
hdfs dfs -appendToFile ./exp.log ./tmp/exception.log
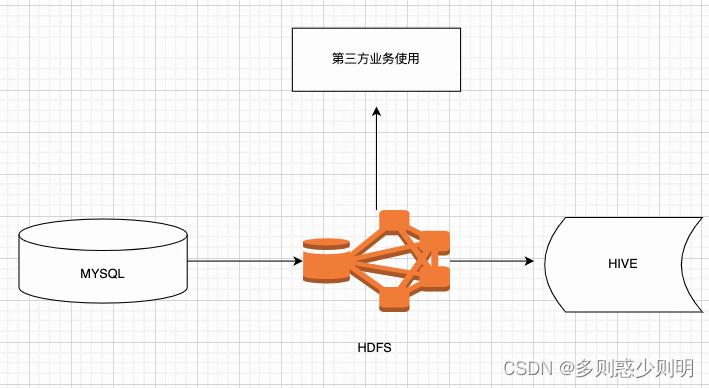
七、hdfs业务中应用
实际业务中,会全量输入写入hdfs文件供第三方业务线读取,或者同步到hive表供后续业务继续加工。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)