
深度学习 卷积神经网络-Pytorch手写数字识别
一、前言 二、代码实现 2.1 引入依赖库 2.2 加载数据 2.3 数据分割 2.4 构造数据 2.5 迭代训练 三、测试数据 四、参考资料现在我们使用卷积神经网络来实现手写数字识别。网上大部分Pytorch案例用的是MNIST数据集,不过本文为了与之前文章的试验结果作对比,还是采用的sklearn数据集,并且构造了数据加载器以适用Pytorch。
·
一、前言
现在我们使用卷积神经网络来实现手写数字识别。网上大部分Pytorch案例用的是MNIST数据集,不过本文为了与之前文章《神经网络 逻辑回归多分类-Pytorch手写数字识别》的试验结果作对比,还是采用的sklearn数据集,并且构造了数据加载器以适用Pytorch。
二、代码实现
2.1 引入依赖库
from sklearn import datasets
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,TensorDataset
2.2 加载数据
从sklearn加载数据集
X,Y = datasets.load_digits(return_X_y=True)
2.3 数据分割
将数据分割为训练和验证数据,都有特征和预测目标值。分割基于随机数生成器。为random_state参数提供一个数值可以保证每次得到相同的分割。
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state = 0)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(1347, 64) (450, 64) (1347,) (450,)
2.4 构造数据
from torch.utils.data import DataLoader,TensorDataset
y_train_onehot= LabelBinarizer().fit_transform(y_train) #独热编码
y_train_onehot_ts=torch.tensor(y_train_onehot,dtype=torch.float32)
X_train_ts = torch.tensor(X_train,dtype=torch.float32)
X_train_ts = X_train_ts.reshape(X_train_ts.shape[0], 1, 8, 8) #(批次=1347,通道数=1,8x8像素)
batch_size = 100
#构造数据集
train_dataset = TensorDataset(X_train_ts, y_train_onehot_ts)
#构造加载器
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size)
2.5 迭代训练
#迭代次数
epochs=1000
#学习率
learning_rate=0.5
plt_epoch=[]
plt_loss=[]
model = nn.Sequential(
# 卷积核的尺寸是5*5,输入通道为1,卷积核(输出通道)个数是16,步长是1,padding=2
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), #Output Size([1, 16, 8, 8])
#归一化,防止训练过程中各网络层的输入落入饱和区导致梯度消失
nn.BatchNorm2d(16),
#激活函数
nn.ReLU(),
#Max池化
nn.MaxPool2d(kernel_size=2, stride=2),#Output Size([1, 16, 4, 4])
#展开
nn.Flatten(),
#全连接
nn.Linear(16*4*4, 10),
#激活函数
nn.Softmax()
)
#损失函数
cost=nn.BCELoss()
#迭代优化器
optmizer=torch.optim.SGD(model.parameters(),lr=learning_rate)
for epoch in range(epochs):
train_loss = 0
for i, (images, labels) in enumerate(train_loader):
#预测结果
predictions=model(images)
# print(labels.shape)
# print(predictions.shape)
#计算损失值
loss=cost(predictions,labels)
train_loss+=loss
#在反向传播前先把梯度清零
optmizer.zero_grad()
#反向传播,计算各参数对于损失loss的梯度
loss.backward()
#根据刚刚反向传播得到的梯度更新模型参数
optmizer.step()
# 取平均存入
plt_epoch.append(epoch+1)
plt_loss.append(train_loss.item() / len(train_loader))
#打印损失值
if (epoch+1)%100==0:
print('epoch:',epoch+1,'loss:',train_loss.item())
# 保存模型
torch.save(model, 'CNN_Digits.pt')
#绘制迭代次数与损失函数的关系
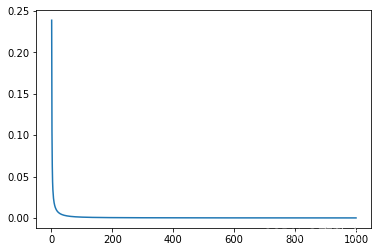
import matplotlib.pyplot as plt
plt.plot(plt_epoch,plt_loss)
epoch: 100 loss: 0.014173265546560287
epoch: 200 loss: 0.005723422393202782
epoch: 300 loss: 0.0034480015747249126
epoch: 400 loss: 0.0024207723326981068
epoch: 500 loss: 0.0018484062748029828
epoch: 600 loss: 0.0014838384231552482
epoch: 700 loss: 0.001234391937032342
epoch: 800 loss: 0.0010522184893488884
epoch: 900 loss: 0.0009145063813775778
epoch: 1000 loss: 0.0008075584773905575
三、测试数据
#加载模型
model=torch.load('CNN_Digits.pt')
y_test_onehot= LabelBinarizer().fit_transform(y_test)#标签二值化
x_t=torch.tensor(X_test,dtype=torch.float32)
y_t=torch.tensor(y_test,dtype=torch.float32)
y_t_onehot=torch.tensor(y_test_onehot,dtype=torch.float32)
x_t=x_t.reshape(x_t.shape[0], 1, 8, 8)
#预测结果
predictions=model(x_t)
#计算损失值
loss=cost(predictions,y_t_onehot)
print('loss:',loss.detach().item())
predictions=predictions.argmax(dim=1) #返回最大值的下标
print(f"预测准确率: {(torch.sum(predictions == y_t)/y_t.size()[0]) * 100}%")
loss: 0.008674271404743195
预测准确率: 98.66667175292969%
从测试数据的结果可以看出,CNN的准确率(98.67%)比单纯全连接神经网络的(95.78%)要高。
四、参考资料
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)