
干货!通过异构子图神经网络进行分子表示学习
点击蓝字关注我们AI TIME欢迎每一位AI爱好者的加入!余兆宁:爱荷华州立大学博士生,导师为Hongyang Gao教授,主要研究方向为图深度学习,可解释性分析。主页:https://zhaoningyu1996.github.io/图神经网络已广泛用于分子图的特征表示学习。然而,大多数现有方法单独处理分子图,忽略分子图之间的关联,例如通过共有子图(motif)建立的关系。针对这个问题, 我们
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!


余兆宁:
爱荷华州立大学博士生,导师为Hongyang Gao教授,主要研究方向为图深度学习,可解释性分析。主页:https://zhaoningyu1996.github.io/
图神经网络已广泛用于分子图的特征表示学习。然而,大多数现有方法单独处理分子图,忽略分子图之间的关联,例如通过共有子图(motif)建立的关系。针对这个问题, 我们提出了一种基于构建异构子图的分子图表示学习方法。具体来说,我们构建了一个包含子图节点和分子节点的异构图。每个子图节点对应于从分子中提取的一个常见子图(motif)。然后,我们使用一个异构神经网络(HM-GNN)来学习异构图中每个节点的特征表示。实验表明我们模型所提取的分子和常见子图(motif)之间的信息传递能够帮助分子特征表示的学习。
这次我们讲的是如何利用基于Motif的异构图来帮助分子表示的学习。
1
What are motifs
Motifs-based Molecular Representation Learning
什么是motifs?维基百科中的解释是经常出现的统计学上非常重要的子图或子结构,也可能是一种模式。
下面我们给出例子,分子图通过一些分解手段来构造一些子结构,我们列出了4个例子。
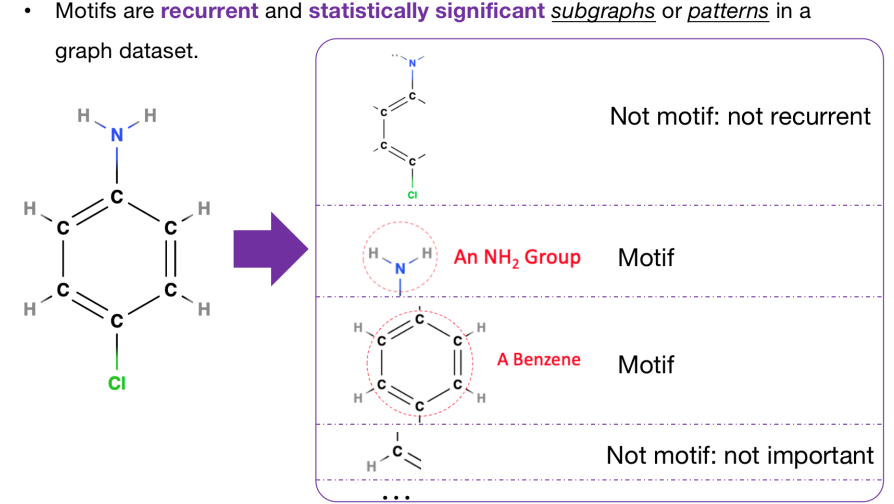
第一个子结构包含了绝大多数分子图中的点,也就是说本身这个子结构包含了很多非常有用的信息。但是由于这个结构非常特殊,我们很难在其他图中找到相同的子结构,所以我们就不把它当作motif。
第二个和第三个例子可以被当作motif,首先是因为他们都经常出现在各种分子图中。另一方面根据化学中的domain knowledge,我们可以知道这两个子结构具有特殊的性质。所以我们认为这两种子结构都可以被当作motif。
最后一个例子是一个碳氢结构,该结构也经常出现在图中。但是目前还很难知道它有什么特殊的性质,所以不把它作为motif。
Network Motif
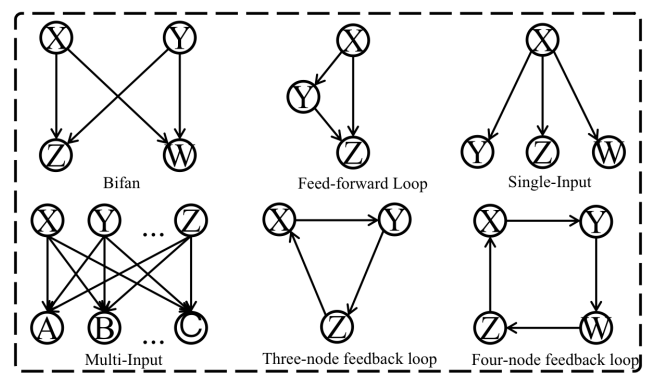
这个图中列了6种常见的网络中motif,这6种motif不仅出现在分子图中,社交网络等图中也会出现。有趣的现象是如果我们把它当作无向图来看待,除了第3种Single-Input,其他5种motif都可以看成是环结构的变换或组合。这也说明大多数motif都可以被看作是环结构的一种变形。
介绍完了什么是motif,我们就在思考为什么motif可以帮助我们进行分子图的表示学习呢?
2
Why motifs?
Motifs-based Molecular Representation Learning
第一个原因就是motif已经在图领域被广泛学习,而且已被证明可以对一些图表示学习起到帮助。第二个原因是motif作为统计学上较重要的子图,学习motif本身也就如同在学习图中的一个重要子结构。自然我们也可以学习到一些有用的信息来帮助分子图的表示学习。
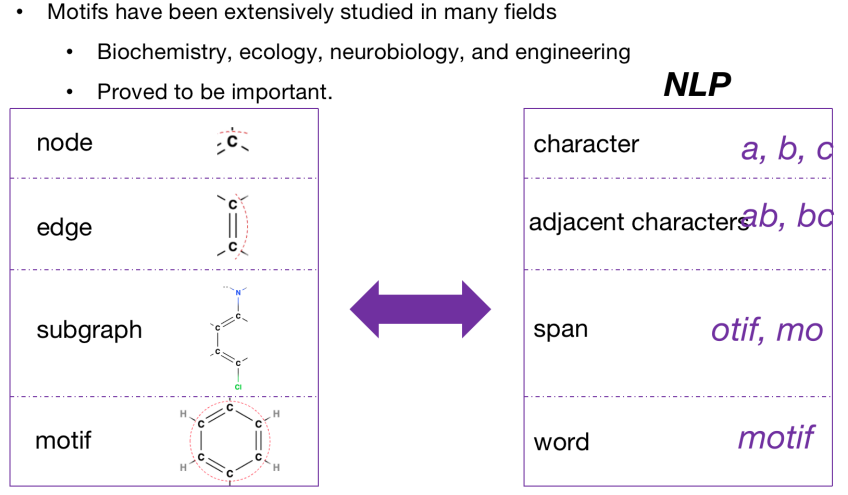
对比NLP和图领域,这两者有非常多的相似之处。我们在图中以node作为基本的单位,在NLP中把字母作为基本的单位。图中的edge这种两个node之间的关系可以看做NLP中两个相邻字母之间的关系。图中的子图在NLP中也可以用连续的字母作为相对应的关系。图中的motif在NLP中也可以被看作word,在NLP中word embedding的学习是非常重要的,无论是对于sentence还是document。类比过来,图中motif的学习对于graph的学习也是非常重要的。
3
How to effectively use motifs
如何有效的利用motif中的information呢?一个比较直接的想法就是从每一个分子图汲取一些motif的信息并加入到node feature或是graph feature中,再用加入了feature的分子图训练。这个方法的弊端就是没有考虑到不同分子图共享某些motif的话,这些分子图之间的联系或信息分享是什么。
如果一个分子既包含了postive的motif,又包含了negative的motif,那么model就没有考虑到这些不同属性motif之间的关联。所以我们提出了一个方法来解决这两点。

我们的方法主要包含三部分:第一部分是构建一个motif的字典,字典中包含所有从数据集中提取出来的motif;第二部分是根据这个字典构建一个基于motif的异构图,既包含了motif的信息,也包含了我们要预测的分子图信息。、;第三部分是用图神经网络学习我们这个异构图,从而得到一些motif level的graph embedding,来帮助最终的学习。
Motif Vocabulary
构建motif的字典,我们首先给一个数据集选取一个提取motif的方法,然后遍历数据集中所有的分子图。我们再用这个方法去提取出一些子图。我们也可以进行筛选,选出一些重要的子图。当然也可以不做筛选,全部放在字典之中。这样肯定也不会遗漏信息。
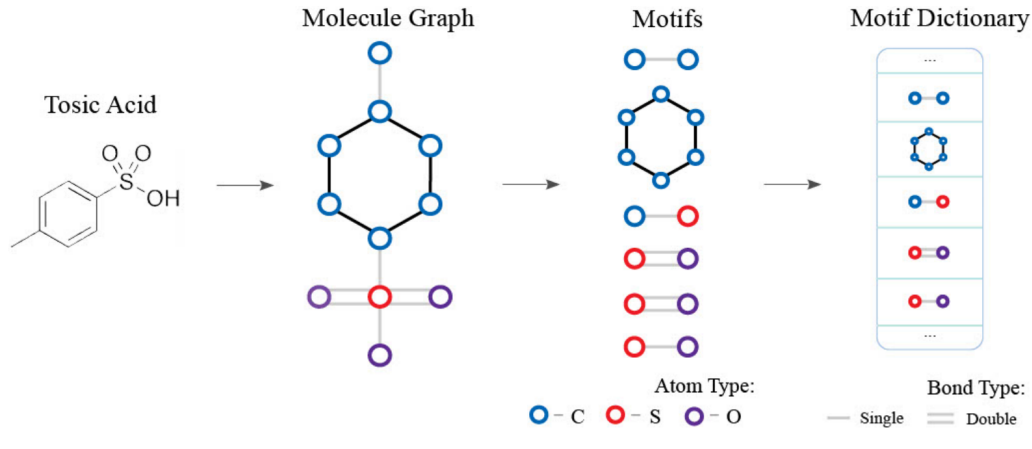
需要强调的是,提取motif方法的选择也很重要。我们可以用环来代表非常多的motif,本研究中的提取方法就是选取所有的环结构已经那些不在环结构上的边作为motif放入字典之中。其他一些分子中的成熟的decomposition方法例如RECAP和BRICS提取出来的motif相对较大,很难控制字典的大小,因为当motif过大的时候就不够基础,提取出的motif中数量就很难控制。只提取环和边的另一个好处是其时间复杂度不是很高,只有o(n2)。
Heterogeneous Motif Graph
下面我们也有实验进行论证:
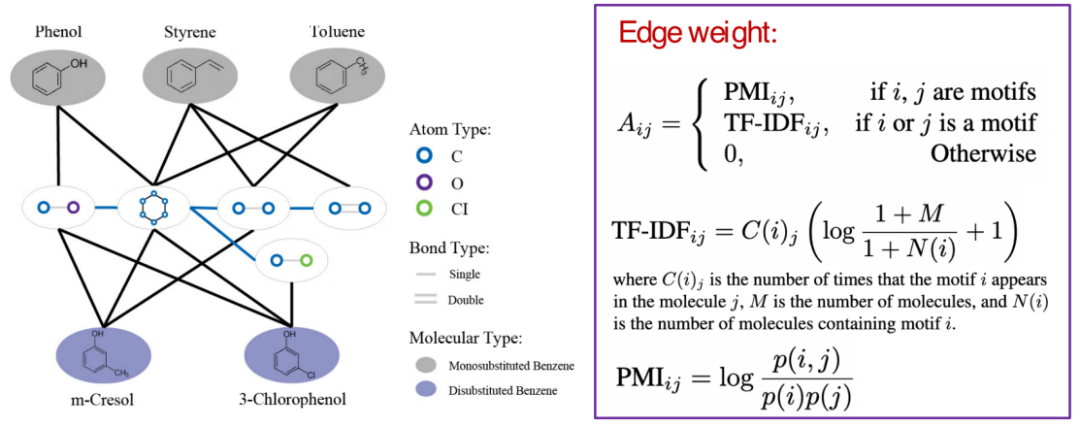
构建好字典之后,我们就可以创建异构图了。异构图中包含两种不同的node,第一种node是中间这些白底的node,即motif node,每一个motif node代表我们刚刚构建字典中的一个motif。另一种node是带有颜色的node,即分子的node。这些分子node代表着数据集中的分子图。
我们同时还可以看到异构图中有两种边,第一种边是motif node到motif node的边。如果两个motif在分子中共用一个原子,那么我们就把这两个motif相连。另一种边是motif node到分子node的边,如果这个motif是分子的某个组成部分,就把这个motif node和分子的node连接起来。因为有不同种类的边,不同的motif对分子的贡献也是不一样的。我们由此计算了每个边的edge weight,如果这个边是motif node 到motif node的边,我们就用PMI算法计算其weight;如果这条边是motif node到分子node边的话,我们就用TF-IDF来计算weight。上述两个算法都是NLP中常用的算法。TF-IDF算法中的C(i)j指的是motif i出现在分子j中的次数,M指的是这个数据集包含的分子图个数。N(i)指的是有多少分子图包含motif i,PMij公式中的p(i,j)指的是motif i和motif j同时出现的概率。p(i)和p(j)分别指的是motif i和motif j出现的概率。
Heterogeneous Motif Graph Neural Networks
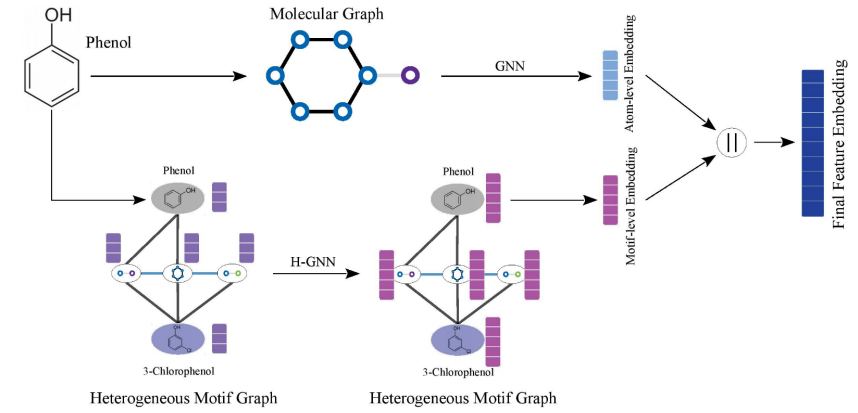
构建好异构图之后,我们就可以做分子的训练了。训练模型主要包括两部分,上面这一行是一个传统的学习分子图步骤;下面这一行就是训练我们刚刚构建好的异构图,我们用GNN去学习这个异构图得到了其中的node embedding。我们把这两部分的embedding连接在一起,就得到了最终的分子图feature embedding。这个embedding就可以应用到之后的任务之中。
Multi-Task Learning via Heterogeneous Motif Graph
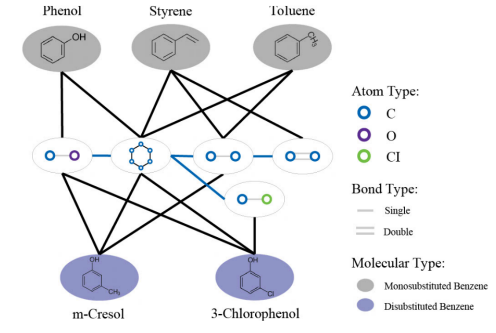
我们知道,分子领域之中有很多小的数据集,每个数据集中都只有几千甚至几百个的graph。这种情况下,我们用GNN训练是很容易出现overfit的现象。利用我们的heterogeneous graph,可以做到同时训练不同的数据集,通过共享的motifs 将他们组合成一个大的数据集来一起训练。这其实就相当于multi-task learning的训练模式。当然,这一训练的前提就是不同的数据集需要共用很多的motif,这样才能构建成一个比较大的异构图,
Heterogeneous Motif Graph
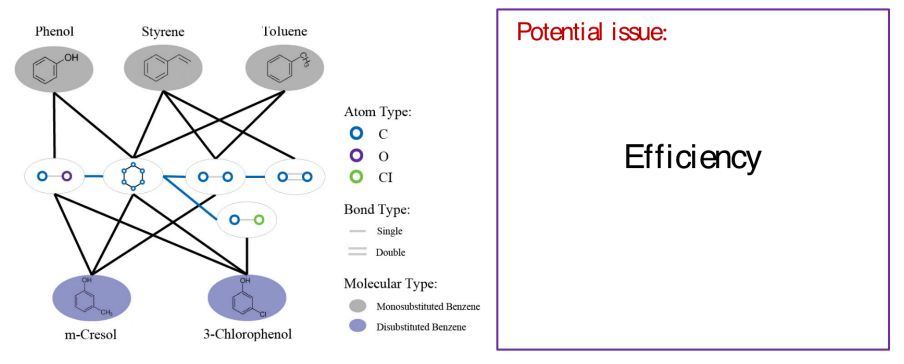
我们构建的异构图有一个问题,就是图的大小其实是关联于数据集大小的。如果数据集非常大,那么异构图也会非常大,这就存在效率的问题。比如说很难把异构图放在模型中并同时训练图上的点,这时就有sampling的方法去sample一个子图去进行训练。根据我们异构图的特点,即异构图上既存在motif node,也有我们要预测的分子node。所以我们构建了一个edge sampling的方法。
Efficient Training via Edge Sampling

以上图为例,我们选择一些需要预测的点,即分子node。在图中就是红色的s点,从这里开始在每一层选择一些边到sampling的子图中。因为在第一个hop中,所有的边都是需要预测的分子点到motif node的边。为了不让信息产生丢失,我们在第一个hop中就选取所有的边到子图中,从第二个hop开始只选择motif到motif的边,这样就尽可能减少子图中不需要求loss的node。
Experiment Results
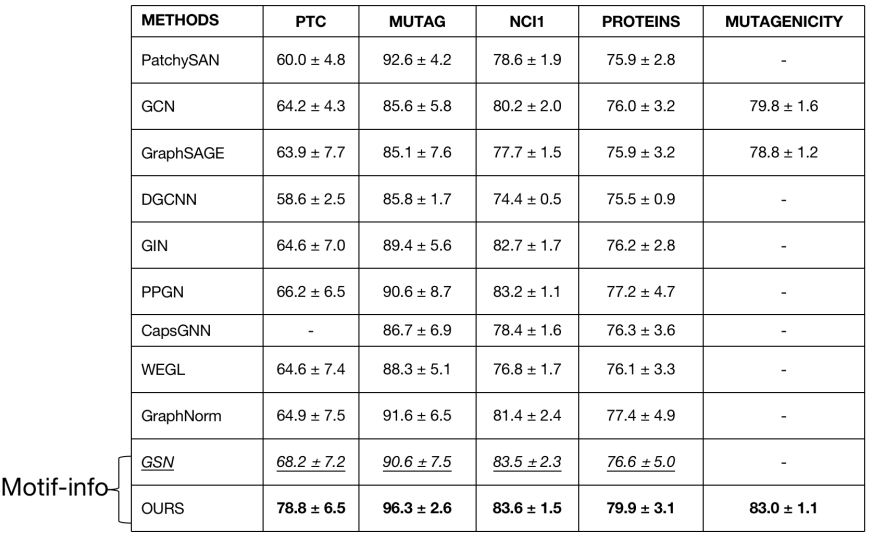
如上图实验结果所示,我们的模型和其他baseline在一些数据集上的对比,发现还是取得了一些效果上的提高。需要强调的是,GSN这个模型也是引入了一些motif information,但是并没有考虑到motif和motif之间的信息交流和分子与分子之间的信息交流,所以结果也可以看到我们的模型还是取得了不错提高的。
Ablation Studies on Motif-Motif Interaction
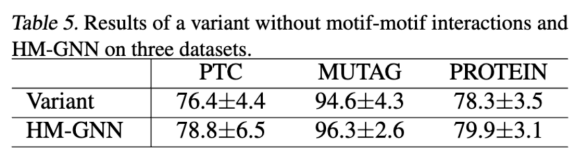
这个ablation study创建了一个variant,就是在异构图中去掉motif和motif的边来看performance。我们发现performance大概有着1%的下降,这就证明了异构图中motif和motif之间的信息交流也是十分重要的。
Ablation Studies on Motif-Motif Interaction
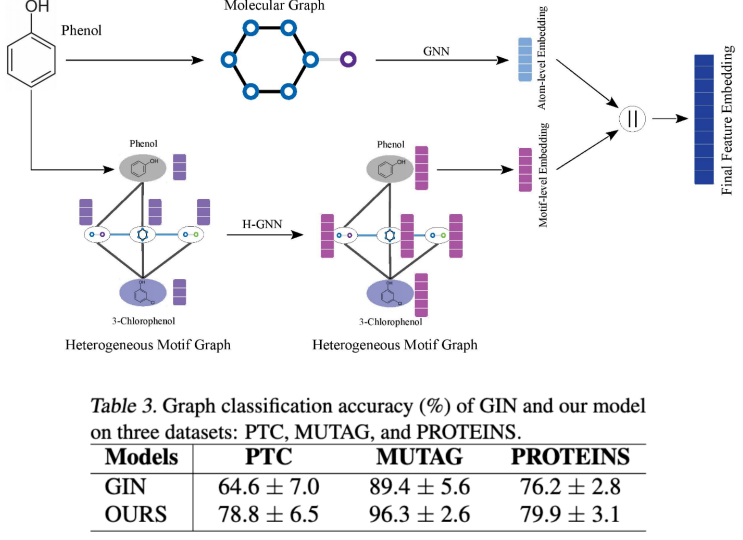
上图展示了异构图和传统的对分子图学习的区别。第一行就是传统的学习分子表示的一个方法,下面一行就是加上异构图之后的学习方法。实验结果表明,异构图还是给到这些传统的GNN等方法不错提高的。
Ablation Studies on Motif-Motif Interaction
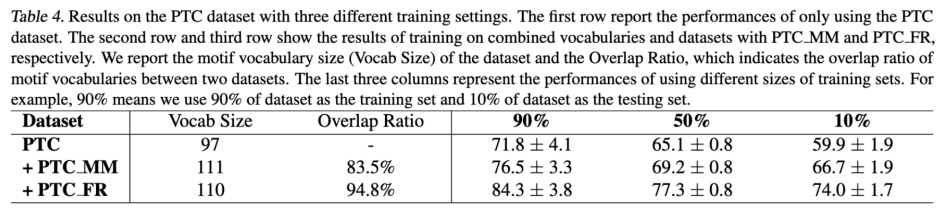
这里的实验结果就是我们的异构图在一个小数据集上做multi-task learning的一个应用。这里我们选取了3种PDC datasets,每个datasets只有几百个graph。在左面的vocubalary表明了这3个dataset共享非常多的motif,比如说前两个motif共享了83.5%的motif,第一个和第三个motif共享了94.8%的motif。右边的三个结果指的是我们选择多少的datasets作为training datasets。
我们可以看到如果两个数据集共享更多的motif,performance的提高就会更多,而且在10%这个setting下,即便我们只用10%的datasets做training依然可以得到一个非常棒的performance,而且超出绝大多数的baseline。因此,我们认为这种应用在小数据集上的multi-task learning模式可以帮助很多小数据集做training,可以解决许多如overfitting的问题。
整理:林 则
作者:余兆宁
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了800多位海内外讲者,举办了逾350场活动,超300万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)